+和上一个问题一样,curl 测试。知识库索引没有进度/索引很慢 link 先看日志报错信息。有以下几种情况:
可以对话,但是索引没有进度:没有配置向量模型(vectorModels) 不能对话,也不能索引:API调用失败。可能是没连上OneAPI或OpenAI 有进度,但是非常慢:api key不行,OpenAI的免费号,一分钟只有3次还是60次。一天上限200次。 Connection error link 网络异常。国内服务器无法请求OpenAI,自行检查与AI模型的连接是否正常。
或者是FastGPT请求不到 OneAPI(没放同一个网络)
修改了 vectorModels 但是没有生效 link 重启容器,确保模型配置已经加载(可以在日志或者新建知识库时候看到新模型) 记得刷新一次浏览器。 如果是已经创建的知识库,需要删除重建。向量模型是创建时候绑定的,不会动态更新。 三、常见的 OneAPI 错误 link 带有 requestId 的都是 OneAPI 的报错。
insufficient_user_quota user quota is not enough link OneAPI 账号的余额不足,默认 root 用户只有 200 刀,可以手动修改。
路径:打开OneAPI -> 用户 -> root用户右边的编辑 -> 剩余余额调大
xxx渠道找不到 link FastGPT 模型配置文件中的 model 必须与 OneAPI 渠道中的模型对应上,否则就会提示这个错误。可检查下面内容:
OneAPI 中没有配置该模型渠道,或者被禁用了。 FastGPT 配置文件有 OneAPI 没有配置的模型。如果 OneAPI 没有配置对应模型的,配置文件中也不要写。 使用旧的向量模型创建了知识库,后又更新了向量模型。这时候需要删除以前的知识库,重建。 如果OneAPI中,没有配置对应的模型,config.json中也不要配置,否则容易报错。
点击模型测试失败 link OneAPI 只会测试渠道的第一个模型,并且只会测试对话模型,向量模型无法自动测试,需要手动发起请求进行测试。查看测试模型命令示例
get request url failed: Post “https://xxx dial tcp: xxxx link OneAPI 与模型网络不通,需要检查网络配置。
Incorrect API key provided: sk-xxxx.You can find your api Key at xxx link OneAPI 的 API Key 配置错误,需要修改OPENAI_API_KEY环境变量,并重启容器(先 docker-compose down 然后再 docker-compose up -d 运行一次)。
可以exec进入容器,env查看环境变量是否生效。
bad_response_status_code bad response status code 503 link 模型服务不可用 模型接口参数异常(温度、max token等可能不适配) …. Tiktoken 下载失败 link 由于 OneAPI 会在启动时从网络下载一个 tiktoken 的依赖,如果网络异常,就会导致启动失败。可以参考OneAPI 离线部署 解决。
四、常见模型问题 link 如何检查模型可用性问题 link 私有部署模型,先确认部署的模型是否正常。 通过 CURL 请求,直接测试上游模型是否正常运行(云端模型或私有模型均进行测试) 通过 CURL 请求,请求 OneAPI 去测试模型是否正常。 在 FastGPT 中使用该模型进行测试。 下面是几个测试 CURL 示例:
curl https://api.openai.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
@@ -57,7 +57,7 @@ Table of Contents
curl https://api.openai.com/v1/embeddings \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-H "Content-Type: application/json" \
@@ -66,7 +66,7 @@ Table of Contents
curl --location --request POST 'https://xxxx.com/api/v1/rerank' \
--header 'Authorization: Bearer {{ACCESS_TOKEN}}' \
--header 'Content-Type: application/json' \
@@ -77,7 +77,7 @@ Table of Contents
curl https://api.openai.com/v1/audio/speech \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-H "Content-Type: application/json" \
@@ -87,7 +87,7 @@ Table of Contents
curl https://api.openai.com/v1/audio/transcriptions \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-H "Content-Type: multipart/form-data" \
diff --git a/docs/development/openapi/chat/index.html b/docs/development/openapi/chat/index.html
index 870bb5b72..f1ffb2b2f 100644
--- a/docs/development/openapi/chat/index.html
+++ b/docs/development/openapi/chat/index.html
@@ -34,9 +34,9 @@ FAQ
-Table of Contents
chat
对话接口 FastGPT OpenAPI 对话接口
如何获取 AppId link 可在应用详情的路径里获取 AppId。
该接口的 API Key 需使用应用特定的 key,否则会报错。 请求简易应用和工作流 link v1对话接口兼容GPT的接口!如果你的项目使用的是标准的GPT官方接口,可以直接通过修改BaseUrl和 Authorization来访问 FastGpt 应用,不过需要注意下面几个规则:
chat
对话接口 FastGPT OpenAPI 对话接口
如何获取 AppId link 可在应用详情的路径里获取 AppId。
该接口的 API Key 需使用应用特定的 key,否则会报错。 请求简易应用和工作流 link v1对话接口兼容GPT的接口!如果你的项目使用的是标准的GPT官方接口,可以直接通过修改BaseUrl和 Authorization来访问 FastGpt 应用,不过需要注意下面几个规则:
curl --location --request POST 'http://localhost:3000/api/v1/chat/completions' \
--header 'Authorization: Bearer fastgpt-xxxxxx' \
--header 'Content-Type: application/json' \
@@ -56,7 +56,7 @@ Table of Contents 仅messages有部分区别,其他参数一致。 目前不支持上传文件,需上传到自己的对象存储中,获取对应的文件链接。 仅messages有部分区别,其他参数一致。 目前不支持上传文件,需上传到自己的对象存储中,获取对应的文件链接。
curl --location --request POST 'http://localhost:3000/api/v1/chat/completions' \
--header 'Authorization: Bearer fastgpt-xxxxxx' \
--header 'Content-Type: application/json' \
@@ -86,11 +86,11 @@ Table of Contents info
headers.Authorization: Bearer {{apikey}} chatId: string | undefined 。为 undefined 时(不传入),不使用 FastGpt 提供的上下文功能,完全通过传入的 messages 构建上下文。 为非空字符串时,意味着使用 chatId 进行对话,自动从 FastGpt 数据库取历史记录,并使用 messages 数组最后一个内容作为用户问题,其余 message 会被忽略。请自行确保 chatId 唯一,长度小于250,通常可以是自己系统的对话框ID。 messages: 结构与 GPT接口 chat模式一致。 responseChatItemId: string | undefined 。如果传入,则会将该值作为本次对话的响应消息的 ID,FastGPT 会自动将该 ID 存入数据库。请确保,在当前chatId下,responseChatItemId是唯一的。 detail: 是否返回中间值(模块状态,响应的完整结果等),stream模式下会通过event进行区分,非stream模式结果保存在responseData中。 variables: 模块变量,一个对象,会替换模块中,输入框内容里的{{key}} info
headers.Authorization: Bearer {{apikey}} chatId: string | undefined 。为 undefined 时(不传入),不使用 FastGpt 提供的上下文功能,完全通过传入的 messages 构建上下文。 为非空字符串时,意味着使用 chatId 进行对话,自动从 FastGpt 数据库取历史记录,并使用 messages 数组最后一个内容作为用户问题,其余 message 会被忽略。请自行确保 chatId 唯一,长度小于250,通常可以是自己系统的对话框ID。 messages: 结构与 GPT接口 chat模式一致。 responseChatItemId: string | undefined 。如果传入,则会将该值作为本次对话的响应消息的 ID,FastGPT 会自动将该 ID 存入数据库。请确保,在当前chatId下,responseChatItemId是唯一的。 detail: 是否返回中间值(模块状态,响应的完整结果等),stream模式下会通过event进行区分,非stream模式结果保存在responseData中。 variables: 模块变量,一个对象,会替换模块中,输入框内容里的{{key}}
{
"id": "adsfasf",
"model": "",
@@ -110,7 +110,7 @@ Table of Contents
data: {"id":"","object":"","created":0,"choices":[{"delta":{"content":""},"index":0,"finish_reason":null}]}
data: {"id":"","object":"","created":0,"choices":[{"delta":{"content":"电"},"index":0,"finish_reason":null}]}
@@ -118,7 +118,7 @@ data: {"id":"","object":"","created":0,&
data: {"id":"","object":"","created":0,"choices":[{"delta":{"content":"影"},"index":0,"finish_reason":null}]}
data: {"id":"","object":"","created":0,"choices":[{"delta":{"content":"《"},"index":0,"finish_reason":null}]}
-
{
"responseData": [ // 不同模块的响应值, 不同版本具体值可能有差异,可先 log 自行查看最新值。
{
@@ -202,7 +202,7 @@ data: {"id":"","object":"","created":0,&
}
]
}
-
event: flowNodeStatus
data: {"status":"running","name":"知识库搜索"}
@@ -232,8 +232,8 @@ data: [DONE]
event: flowResponses
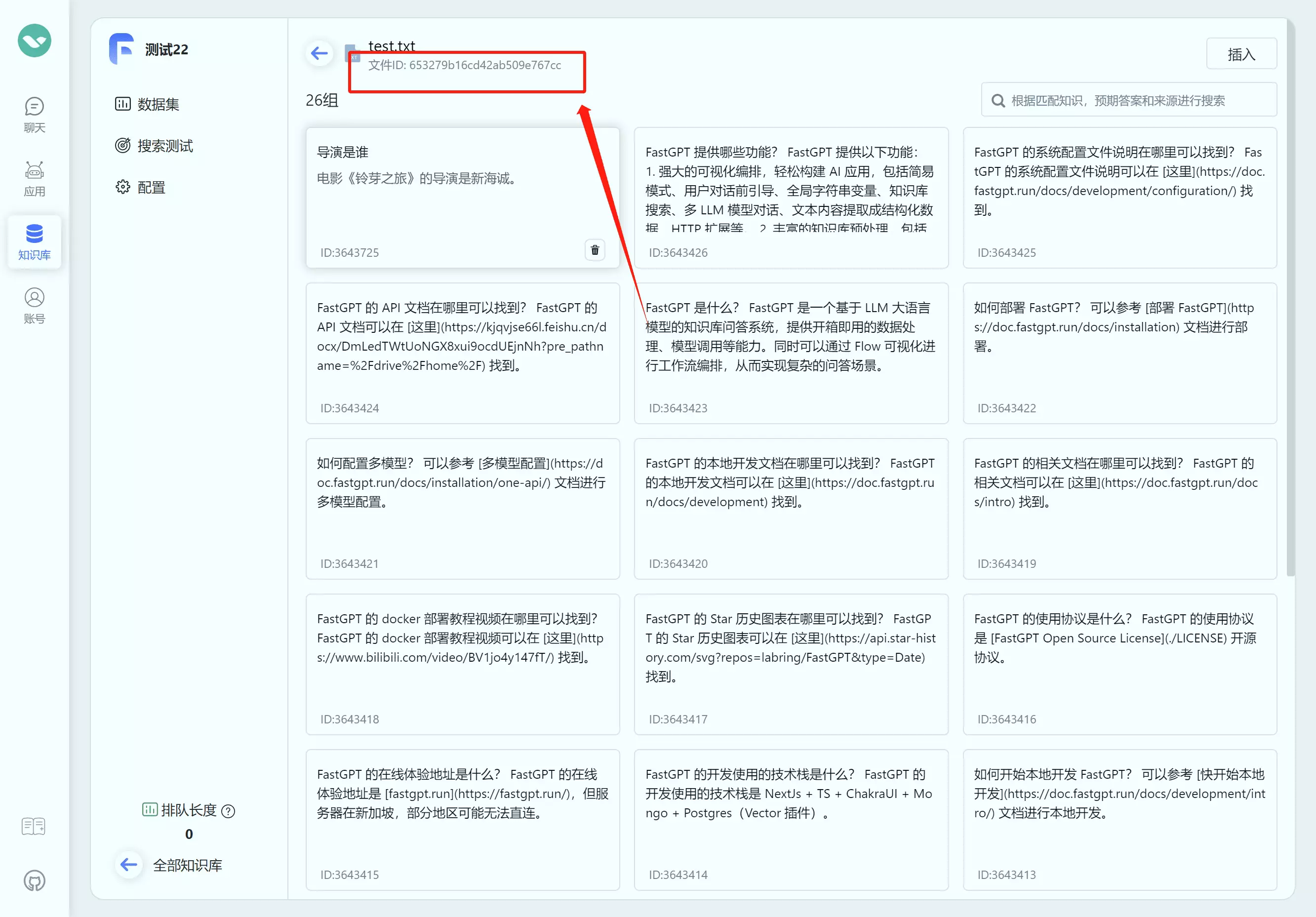
data: [{"moduleName":"知识库搜索","moduleType":"datasetSearchNode","runningTime":1.78},{"question":"导演是谁","quoteList":[{"id":"654f2e49b64caef1d9431e8b","q":"电影《铃芽之旅》的导演是谁?","a":"电影《铃芽之旅》的导演是新海诚!","indexes":[{"type":"qa","dataId":"3515487","text":"电影《铃芽之旅》的导演是谁?","_id":"654f2e49b64caef1d9431e8c","defaultIndex":true}],"datasetId":"646627f4f7b896cfd8910e38","collectionId":"653279b16cd42ab509e766e8","sourceName":"data (81).csv","sourceId":"64fd3b6423aa1307b65896f6","score":0.8935586214065552},{"id":"6552e14c50f4a2a8e632af11","q":"导演是谁?","a":"电影《铃芽之旅》的导演是新海诚。","indexes":[{"defaultIndex":true,"type":"qa","dataId":"3644565","text":"导演是谁?\n电影《铃芽之旅》的导演是新海诚。","_id":"6552e14dde5cc7ba3954e417"}],"datasetId":"646627f4f7b896cfd8910e38","collectionId":"653279b16cd42ab509e766e8","sourceName":"data (81).csv","sourceId":"64fd3b6423aa1307b65896f6","score":0.8890955448150635},{"id":"654f34a0b64caef1d946337e","q":"本作的主人公是谁?","a":"本作的主人公是名叫铃芽的少女。","indexes":[{"type":"qa","dataId":"3515541","text":"本作的主人公是谁?","_id":"654f34a0b64caef1d946337f","defaultIndex":true}],"datasetId":"646627f4f7b896cfd8910e38","collectionId":"653279b16cd42ab509e766e8","sourceName":"data (81).csv","sourceId":"64fd3b6423aa1307b65896f6","score":0.8738770484924316},{"id":"654f3002b64caef1d944207a","q":"电影《铃芽之旅》男主角是谁?","a":"电影《铃芽之旅》男主角是宗像草太,由松村北斗配音。","indexes":[{"type":"qa","dataId":"3515538","text":"电影《铃芽之旅》男主角是谁?","_id":"654f3002b64caef1d944207b","defaultIndex":true}],"datasetId":"646627f4f7b896cfd8910e38","collectionId":"653279b16cd42ab509e766e8","sourceName":"data (81).csv","sourceId":"64fd3b6423aa1307b65896f6","score":0.8607980012893677},{"id":"654f2fc8b64caef1d943fd46","q":"电影《铃芽之旅》的编剧是谁?","a":"新海诚是本片的编剧。","indexes":[{"defaultIndex":true,"type":"qa","dataId":"3515550","text":"电影《铃芽之旅》的编剧是谁?22","_id":"654f2fc8b64caef1d943fd47"}],"datasetId":"646627f4f7b896cfd8910e38","collectionId":"653279b16cd42ab509e766e8","sourceName":"data (81).csv","sourceId":"64fd3b6423aa1307b65896f6","score":0.8468944430351257}],"moduleName":"AI 对话","moduleType":"chatNode","runningTime":1.86}]
- event取值:
answer: 返回给客户端的文本(最终会算作回答) fastAnswer: 指定回复返回给客户端的文本(最终会算作回答) toolCall: 执行工具 toolParams: 工具参数 toolResponse: 工具返回 flowNodeStatus: 运行到的节点状态 flowResponses: 节点完整响应 updateVariables: 更新变量 error: 报错 如果工作流中包含交互节点,依然是调用该 API 接口,需要设置detail=true,并可以从event=interactive的数据中获取交互节点的配置信息。如果是stream=false,则可以从 choice 中获取type=interactive的元素,获取交互节点的选择信息。
当你调用一个带交互节点的工作流时,如果工作流遇到了交互节点,那么会直接返回,你可以得到下面的信息:
event取值:
answer: 返回给客户端的文本(最终会算作回答) fastAnswer: 指定回复返回给客户端的文本(最终会算作回答) toolCall: 执行工具 toolParams: 工具参数 toolResponse: 工具返回 flowNodeStatus: 运行到的节点状态 flowResponses: 节点完整响应 updateVariables: 更新变量 error: 报错 如果工作流中包含交互节点,依然是调用该 API 接口,需要设置detail=true,并可以从event=interactive的数据中获取交互节点的配置信息。如果是stream=false,则可以从 choice 中获取type=interactive的元素,获取交互节点的选择信息。
当你调用一个带交互节点的工作流时,如果工作流遇到了交互节点,那么会直接返回,你可以得到下面的信息:
{
"interactive": {
"type": "userSelect",
@@ -252,7 +252,7 @@ data: [{"moduleName":"知识库搜索","moduleType":"
}
}
}
-
{
"interactive": {
"type": "userInput",
@@ -295,8 +295,8 @@ data: [{"moduleName":"知识库搜索","moduleType":"
}
}
}
- 交互节点继续运行 link 紧接着上一节,当你接收到交互节点信息后,可以根据这些数据进行 UI 渲染,引导用户输入或选择相关信息。然后需要再次发起对话,来继续工作流。调用的接口与仍是该接口,你需要按以下格式来发起请求:
对于用户选择,你只需要直接传递一个选择的结果给 messages 即可。
交互节点继续运行 link 紧接着上一节,当你接收到交互节点信息后,可以根据这些数据进行 UI 渲染,引导用户输入或选择相关信息。然后需要再次发起对话,来继续工作流。调用的接口与仍是该接口,你需要按以下格式来发起请求:
对于用户选择,你只需要直接传递一个选择的结果给 messages 即可。
curl --location --request POST 'https://api.fastgpt.in/api/v1/chat/completions' \
--header 'Authorization: Bearer fastgpt-xxx' \
--header 'Content-Type: application/json' \
@@ -311,7 +311,7 @@ data: [{"moduleName":"知识库搜索","moduleType":"
}
]
}'
- 表单输入稍微麻烦一点,需要将输入的内容,以对象形式并序列化成字符串,作为messages的值。对象的 key 对应表单的 key,value 为用户输入的值。务必确保chatId是一致的。
表单输入稍微麻烦一点,需要将输入的内容,以对象形式并序列化成字符串,作为messages的值。对象的 key 对应表单的 key,value 为用户输入的值。务必确保chatId是一致的。
curl --location --request POST 'https://api.fastgpt.in/api/v1/chat/completions' \
--header 'Authorization: Bearer fastgpt-xxxx' \
--header 'Content-Type: application/json' \
@@ -337,9 +337,9 @@ data: [{"moduleName":"知识库搜索","moduleType":"
"query":"你好" # 我的插件输入有一个参数,变量名叫 query
}
}'
- 插件的输出可以通过查找responseData中, moduleType=pluginOutput的元素,其pluginOutput是插件的输出。 流输出,仍可以通过choices进行获取。 插件的输出可以通过查找responseData中, moduleType=pluginOutput的元素,其pluginOutput是插件的输出。 流输出,仍可以通过choices进行获取。
{
"responseData": [
{
@@ -396,7 +396,7 @@ data: [{"moduleName":"知识库搜索","moduleType":"
}
]
}
- 插件的输出可以通过获取event=flowResponses中的字符串,并将其反序列化后得到一个数组。同样的,查找 moduleType=pluginOutput的元素,其pluginOutput是插件的输出。 流输出,仍和对话接口一样获取。 插件的输出可以通过获取event=flowResponses中的字符串,并将其反序列化后得到一个数组。同样的,查找 moduleType=pluginOutput的元素,其pluginOutput是插件的输出。 流输出,仍和对话接口一样获取。
event: flowNodeStatus
data: {"status":"running","name":"AI 对话"}
@@ -453,9 +453,9 @@ data: [DONE]
event: flowResponses
data: [{"nodeId":"fdDgXQ6SYn8v","moduleName":"AI 对话","moduleType":"chatNode","totalPoints":0.033,"model":"FastAI-3.5","tokens":33,"query":"你好","maxToken":2000,"historyPreview":[{"obj":"Human","value":"你好"},{"obj":"AI","value":"你好!有什么可以帮助你的吗?"}],"contextTotalLen":2,"runningTime":1.42},{"nodeId":"pluginOutput","moduleName":"插件输出","moduleType":"pluginOutput","totalPoints":0,"pluginOutput":{"result":"你好!有什么可以帮助你的吗?"},"runningTime":0}]
- event取值:
answer: 返回给客户端的文本(最终会算作回答) fastAnswer: 指定回复返回给客户端的文本(最终会算作回答) toolCall: 执行工具 toolParams: 工具参数 toolResponse: 工具返回 flowNodeStatus: 运行到的节点状态 flowResponses: 节点完整响应 updateVariables: 更新变量 error: 报错 以下接口可使用任意API Key调用。
4.8.12 以上版本才能使用
重要字段
chatId - 指一个应用下,某一个对话窗口的 ID dataId - 指一个对话窗口下,某一个对话记录的 ID 获取某个应用历史记录 link event取值:
answer: 返回给客户端的文本(最终会算作回答) fastAnswer: 指定回复返回给客户端的文本(最终会算作回答) toolCall: 执行工具 toolParams: 工具参数 toolResponse: 工具返回 flowNodeStatus: 运行到的节点状态 flowResponses: 节点完整响应 updateVariables: 更新变量 error: 报错 以下接口可使用任意API Key调用。
4.8.12 以上版本才能使用
重要字段
chatId - 指一个应用下,某一个对话窗口的 ID dataId - 指一个对话窗口下,某一个对话记录的 ID 获取某个应用历史记录 link
curl --location --request POST 'http://localhost:3000/api/core/chat/getHistories' \
--header 'Authorization: Bearer {{apikey}}' \
--header 'Content-Type: application/json' \
@@ -465,7 +465,7 @@ data: [{"nodeId":"fdDgXQ6SYn8v","moduleName":"AI 对
"pageSize": 20,
"source": "api"
}'
-
appId - 应用 Id offset - 偏移量,即从第几条数据开始取 pageSize - 记录数量 source - 对话源。source=api,表示获取通过 API 创建的对话(不会获取到页面上的对话记录)
appId - 应用 Id offset - 偏移量,即从第几条数据开始取 pageSize - 记录数量 source - 对话源。source=api,表示获取通过 API 创建的对话(不会获取到页面上的对话记录)
{
"code": 200,
"statusText": "",
@@ -492,9 +492,9 @@ data: [{"nodeId":"fdDgXQ6SYn8v","moduleName":"AI 对
"total": 2
}
}
- 修改某个对话的标题 link 修改某个对话的标题 link
curl --location --request POST 'http://localhost:3000/api/core/chat/updateHistory' \
--header 'Authorization: Bearer {{apikey}}' \
--header 'Content-Type: application/json' \
@@ -503,16 +503,16 @@ data: [{"nodeId":"fdDgXQ6SYn8v","moduleName":"AI 对
"chatId": "chatId",
"customTitle": "自定义标题"
}'
-
appId - 应用 Id chatId - 历史记录 Id customTitle - 自定义对话名
appId - 应用 Id chatId - 历史记录 Id customTitle - 自定义对话名
{
"code": 200,
"statusText": "",
"message": "",
"data": null
}
- 置顶 / 取消置顶 link 置顶 / 取消置顶 link
curl --location --request POST 'http://localhost:3000/api/core/chat/updateHistory' \
--header 'Authorization: Bearer {{apikey}}' \
--header 'Content-Type: application/json' \
@@ -521,43 +521,43 @@ data: [{"nodeId":"fdDgXQ6SYn8v","moduleName":"AI 对
"chatId": "chatId",
"top": true
}'
-
appId - 应用Id chatId - 历史记录 Id top - 是否置顶,ture 置顶,false 取消置顶
appId - 应用Id chatId - 历史记录 Id top - 是否置顶,ture 置顶,false 取消置顶
{
"code": 200,
"statusText": "",
"message": "",
"data": null
}
- 删除某个历史记录 link 删除某个历史记录 link
curl --location --request DELETE 'http://localhost:3000/api/core/chat/delHistory?chatId={{chatId}}&appId={{appId}}' \
--header 'Authorization: Bearer {{apikey}}'
-
appId - 应用 Id chatId - 历史记录 Id
appId - 应用 Id chatId - 历史记录 Id
{
"code": 200,
"statusText": "",
"message": "",
"data": null
}
- 清空所有历史记录 link 仅会情况通过 API Key 创建的对话历史记录,不会清空在线使用、分享链接等其他来源的对话历史记录。
清空所有历史记录 link 仅会情况通过 API Key 创建的对话历史记录,不会清空在线使用、分享链接等其他来源的对话历史记录。
curl --location --request DELETE 'http://localhost:3000/api/core/chat/clearHistories?appId={{appId}}' \
--header 'Authorization: Bearer {{apikey}}'
-
{
"code": 200,
"statusText": "",
"message": "",
"data": null
}
- 指的是某个 chatId 下的对话记录操作。
获取单个对话初始化信息 link 指的是某个 chatId 下的对话记录操作。
获取单个对话初始化信息 link
curl --location --request GET 'http://localhost:3000/api/core/chat/init?appId={{appId}}&chatId={{chatId}}' \
--header 'Authorization: Bearer {{apikey}}'
-
appId - 应用 Id chatId - 历史记录 Id
appId - 应用 Id chatId - 历史记录 Id
{
"code": 200,
"statusText": "",
@@ -611,9 +611,9 @@ data: [{"nodeId":"fdDgXQ6SYn8v","moduleName":"AI 对
}
}
}
- 获取对话记录列表 link 获取对话记录列表 link
curl --location --request POST 'http://localhost:3000/api/core/chat/getPaginationRecords' \
--header 'Authorization: Bearer {{apikey}}' \
--header 'Content-Type: application/json' \
@@ -624,7 +624,7 @@ data: [{"nodeId":"fdDgXQ6SYn8v","moduleName":"AI 对
"pageSize": 10,
"loadCustomFeedbacks": true
}'
-
appId - 应用 Id chatId - 历史记录 Id offset - 偏移量 pageSize - 记录数量 loadCustomFeedbacks - 是否读取自定义反馈(可选)
appId - 应用 Id chatId - 历史记录 Id offset - 偏移量 pageSize - 记录数量 loadCustomFeedbacks - 是否读取自定义反馈(可选)
{
"code": 200,
"statusText": "",
@@ -673,12 +673,12 @@ data: [{"nodeId":"fdDgXQ6SYn8v","moduleName":"AI 对
"total": 2
}
}
- 获取单个对话记录运行详情 link 获取单个对话记录运行详情 link
curl --location --request GET 'http://localhost:3000/api/core/chat/getResData?appId={{appId}}&chatId={{chatId}}&dataId={{dataId}}' \
--header 'Authorization: Bearer {{apikey}}'
-
appId - 应用 Id chatId - 对话 Id dataId - 对话记录 Id
appId - 应用 Id chatId - 对话 Id dataId - 对话记录 Id
{
"code": 200,
"statusText": "",
@@ -724,21 +724,21 @@ data: [{"nodeId":"fdDgXQ6SYn8v","moduleName":"AI 对
}
]
}
-
curl --location --request DELETE 'http://localhost:3000/api/core/chat/item/delete?contentId={{contentId}}&chatId={{chatId}}&appId={{appId}}' \
--header 'Authorization: Bearer {{apikey}}'
-
appId - 应用 Id chatId - 历史记录 Id contentId - 对话记录 Id
appId - 应用 Id chatId - 历史记录 Id contentId - 对话记录 Id
{
"code": 200,
"statusText": "",
"message": "",
"data": null
}
- 点赞 / 取消点赞 link 点赞 / 取消点赞 link
curl --location --request POST 'http://localhost:3000/api/core/chat/feedback/updateUserFeedback' \
--header 'Authorization: Bearer {{apikey}}' \
--header 'Content-Type: application/json' \
@@ -748,16 +748,16 @@ data: [{"nodeId":"fdDgXQ6SYn8v","moduleName":"AI 对
"dataId": "dataId",
"userGoodFeedback": "yes"
}'
-
appId - 应用 Id chatId - 历史记录 Id dataId - 对话记录 Id userGoodFeedback - 用户点赞时的信息(可选),取消点赞时不填此参数即可
appId - 应用 Id chatId - 历史记录 Id dataId - 对话记录 Id userGoodFeedback - 用户点赞时的信息(可选),取消点赞时不填此参数即可
{
"code": 200,
"statusText": "",
"message": "",
"data": null
}
- 点踩 / 取消点踩 link 点踩 / 取消点踩 link
curl --location --request POST 'http://localhost:3000/api/core/chat/feedback/updateUserFeedback' \
--header 'Authorization: Bearer {{apikey}}' \
--header 'Content-Type: application/json' \
@@ -767,16 +767,16 @@ data: [{"nodeId":"fdDgXQ6SYn8v","moduleName":"AI 对
"dataId": "dataId",
"userBadFeedback": "yes"
}'
-
appId - 应用 Id chatId - 历史记录 Id dataId - 对话记录 Id userBadFeedback - 用户点踩时的信息(可选),取消点踩时不填此参数即可
appId - 应用 Id chatId - 历史记录 Id dataId - 对话记录 Id userBadFeedback - 用户点踩时的信息(可选),取消点踩时不填此参数即可
{
"code": 200,
"statusText": "",
"message": "",
"data": null
}
- 4.8.16 后新版接口
新版猜你想问,必须包含 appId 和 chatId 的参数才可以进行使用。会自动根据 chatId 去拉取最近 6 轮对话记录作为上下文来引导回答。
4.8.16 后新版接口
新版猜你想问,必须包含 appId 和 chatId 的参数才可以进行使用。会自动根据 chatId 去拉取最近 6 轮对话记录作为上下文来引导回答。
curl --location --request POST 'http://localhost:3000/api/core/ai/agent/v2/createQuestionGuide' \
--header 'Authorization: Bearer {{apikey}}' \
--header 'Content-Type: application/json' \
@@ -789,7 +789,7 @@ data: [{"nodeId":"fdDgXQ6SYn8v","moduleName":"AI 对
"customPrompt": "你是一个智能助手,请根据用户的问题生成猜你想问。"
}
}'
-
参数名 类型 必填 说明 appId string ✅ 应用 Id chatId string ✅ 对话 Id questionGuide object 自定义配置,不传的话,则会根据 appId,取最新发布版本的配置
参数名 类型 必填 说明 appId string ✅ 应用 Id chatId string ✅ 对话 Id questionGuide object 自定义配置,不传的话,则会根据 appId,取最新发布版本的配置
type CreateQuestionGuideParams = OutLinkChatAuthProps & {
appId: string;
chatId: string;
@@ -799,7 +799,7 @@ data: [{"nodeId":"fdDgXQ6SYn8v","moduleName":"AI 对
customPrompt?: string;
};
};
-
{
"code": 200,
"statusText": "",
@@ -810,9 +810,9 @@ data: [{"nodeId":"fdDgXQ6SYn8v","moduleName":"AI 对
"你希望AI能做什么?"
]
}
- 4.8.16 前旧版接口:
4.8.16 前旧版接口:
curl --location --request POST 'http://localhost:3000/api/core/ai/agent/createQuestionGuide' \
--header 'Authorization: Bearer {{apikey}}' \
--header 'Content-Type: application/json' \
@@ -828,7 +828,7 @@ data: [{"nodeId":"fdDgXQ6SYn8v","moduleName":"AI 对
}
]
}'
-
messages - 对话消息,提供给 AI 的消息记录
messages - 对话消息,提供给 AI 的消息记录
{
"code": 200,
"statusText": "",
diff --git a/docs/development/openapi/dataset/index.html b/docs/development/openapi/dataset/index.html
index 198d6308c..507c41efc 100644
--- a/docs/development/openapi/dataset/index.html
+++ b/docs/development/openapi/dataset/index.html
@@ -34,8 +34,8 @@ FAQ
-Table of Contents
dataset
知识库接口 FastGPT OpenAPI 知识库接口
如何获取知识库ID(datasetId) 如何获取文件集合ID(collection_id)
新例子
dataset
知识库接口 FastGPT OpenAPI 知识库接口
如何获取知识库ID(datasetId) 如何获取文件集合ID(collection_id)
新例子
curl --location --request POST 'http://localhost:3000/api/support/wallet/usage/createTrainingUsage' \
--header 'Authorization: Bearer {{apikey}}' \
--header 'Content-Type: application/json' \
@@ -43,16 +43,16 @@ Table of Contents data 为 billId,可用于添加知识库数据时进行账单聚合。
data 为 billId,可用于添加知识库数据时进行账单聚合。
{
"code": 200,
"statusText": "",
"message": "",
"data": "65112ab717c32018f4156361"
}
-
curl --location --request POST 'http://localhost:3000/api/core/dataset/create' \
--header 'Authorization: Bearer {{authorization}}' \
--header 'Content-Type: application/json' \
@@ -65,23 +65,23 @@ Table of Contents
parentId - 父级ID,用于构建目录结构。通常可以为 null 或者直接不传。 type - dataset或者folder,代表普通知识库和文件夹。不传则代表创建普通知识库。 name - 知识库名(必填) intro - 介绍(可选) avatar - 头像地址(可选) vectorModel - 向量模型(建议传空,用系统默认的) agentModel - 文本处理模型(建议传空,用系统默认的)
parentId - 父级ID,用于构建目录结构。通常可以为 null 或者直接不传。 type - dataset或者folder,代表普通知识库和文件夹。不传则代表创建普通知识库。 name - 知识库名(必填) intro - 介绍(可选) avatar - 头像地址(可选) vectorModel - 向量模型(建议传空,用系统默认的) agentModel - 文本处理模型(建议传空,用系统默认的)
{
"code": 200,
"statusText": "",
"message": "",
"data": "65abc9bd9d1448617cba5e6c"
}
-
curl --location --request POST 'http://localhost:3000/api/core/dataset/list?parentId=' \
--header 'Authorization: Bearer xxxx' \
--header 'Content-Type: application/json' \
--data-raw '{
"parentId":""
}'
-
parentId - 父级ID,传空字符串或者null,代表获取根目录下的知识库
parentId - 父级ID,传空字符串或者null,代表获取根目录下的知识库
{
"code": 200,
"statusText": "",
@@ -108,12 +108,12 @@ Table of Contents
curl --location --request GET 'http://localhost:3000/api/core/dataset/detail?id=6593e137231a2be9c5603ba7' \
--header 'Authorization: Bearer {{authorization}}' \
-
{
"code": 200,
"statusText": "",
@@ -149,21 +149,21 @@ Table of Contents
curl --location --request DELETE 'http://localhost:3000/api/core/dataset/delete?id=65abc8729d1448617cba5df6' \
--header 'Authorization: Bearer {{authorization}}' \
-
{
"code": 200,
"statusText": "",
"message": "",
"data": null
}
- 通用创建参数说明(必看) link 入参
参数 说明 必填 datasetId 知识库ID ✅ parentId: 父级ID,不填则默认为根目录 trainingType 数据处理方式。chunk: 按文本长度进行分割;qa: 问答对提取 ✅ customPdfParse PDF增强解析。true: 开启PDF增强解析;不填则默认为false autoIndexes 是否自动生成索引(仅商业版支持) imageIndex 是否自动生成图片索引(仅商业版支持) chunkSettingMode 分块参数模式。auto: 系统默认参数; custom: 手动指定参数 chunkSplitMode 分块拆分模式。size: 按长度拆分; char: 按字符拆分。chunkSettingMode=auto时不生效。 chunkSize 分块大小,默认 1500。chunkSettingMode=auto时不生效。 indexSize 索引大小,默认 512,必须小于索引模型最大token。chunkSettingMode=auto时不生效。 chunkSplitter 自定义最高优先分割符号,除非超出文件处理最大上下文,否则不会进行进一步拆分。chunkSettingMode=auto时不生效。 qaPrompt qa拆分提示词 tags 集合标签(字符串数组) createTime 文件创建时间(Date / String)
出参
collectionId - 新建的集合ID insertLen:插入的块数量 创建一个空的集合 link 通用创建参数说明(必看) link 入参
参数 说明 必填 datasetId 知识库ID ✅ parentId: 父级ID,不填则默认为根目录 trainingType 数据处理方式。chunk: 按文本长度进行分割;qa: 问答对提取 ✅ customPdfParse PDF增强解析。true: 开启PDF增强解析;不填则默认为false autoIndexes 是否自动生成索引(仅商业版支持) imageIndex 是否自动生成图片索引(仅商业版支持) chunkSettingMode 分块参数模式。auto: 系统默认参数; custom: 手动指定参数 chunkSplitMode 分块拆分模式。size: 按长度拆分; char: 按字符拆分。chunkSettingMode=auto时不生效。 chunkSize 分块大小,默认 1500。chunkSettingMode=auto时不生效。 indexSize 索引大小,默认 512,必须小于索引模型最大token。chunkSettingMode=auto时不生效。 chunkSplitter 自定义最高优先分割符号,除非超出文件处理最大上下文,否则不会进行进一步拆分。chunkSettingMode=auto时不生效。 qaPrompt qa拆分提示词 tags 集合标签(字符串数组) createTime 文件创建时间(Date / String)
出参
collectionId - 新建的集合ID insertLen:插入的块数量 创建一个空的集合 link
curl --location --request POST 'http://localhost:3000/api/core/dataset/collection/create' \
--header 'Authorization: Bearer {{authorization}}' \
--header 'Content-Type: application/json' \
@@ -176,16 +176,16 @@ Table of Contents
datasetId: 知识库的ID(必填) parentId: 父级ID,不填则默认为根目录 name: 集合名称(必填) type:folder:文件夹 virtual:虚拟集合(手动集合) metadata: 元数据(暂时没啥用)
datasetId: 知识库的ID(必填) parentId: 父级ID,不填则默认为根目录 name: 集合名称(必填) type:folder:文件夹 virtual:虚拟集合(手动集合) metadata: 元数据(暂时没啥用) data 为集合的 ID。
{
"code": 200,
"statusText": "",
"message": "",
"data": "65abcd009d1448617cba5ee1"
}
- 创建一个纯文本集合 link 传入一段文字,创建一个集合,会根据传入的文字进行分割。
创建一个纯文本集合 link 传入一段文字,创建一个集合,会根据传入的文字进行分割。
curl --location --request POST 'http://localhost:3000/api/core/dataset/collection/create/text' \
--header 'Authorization: Bearer {{authorization}}' \
--header 'Content-Type: application/json' \
@@ -201,7 +201,7 @@ Table of Contents
text: 原文本 datasetId: 知识库的ID(必填) parentId: 父级ID,不填则默认为根目录 name: 集合名称(必填) metadata: 元数据(暂时没啥用)
text: 原文本 datasetId: 知识库的ID(必填) parentId: 父级ID,不填则默认为根目录 name: 集合名称(必填) metadata: 元数据(暂时没啥用) data 为集合的 ID。
{
"code": 200,
"statusText": "",
@@ -216,9 +216,9 @@ Table of Contents 创建一个链接集合 link 传入一个网络链接,创建一个集合,会先去对应网页抓取内容,再抓取的文字进行分割。
创建一个链接集合 link 传入一个网络链接,创建一个集合,会先去对应网页抓取内容,再抓取的文字进行分割。
curl --location --request POST 'http://localhost:3000/api/core/dataset/collection/create/link' \
--header 'Authorization: Bearer {{authorization}}' \
--header 'Content-Type: application/json' \
@@ -235,7 +235,7 @@ Table of Contents
link: 网络链接 datasetId: 知识库的ID(必填) parentId: 父级ID,不填则默认为根目录 metadata.webPageSelector: 网页选择器,用于指定网页中的哪个元素作为文本(可选)
link: 网络链接 datasetId: 知识库的ID(必填) parentId: 父级ID,不填则默认为根目录 metadata.webPageSelector: 网页选择器,用于指定网页中的哪个元素作为文本(可选) data 为集合的 ID。
{
"code": 200,
"statusText": "",
@@ -250,14 +250,14 @@ Table of Contents 创建一个文件集合 link 传入一个文件,创建一个集合,会读取文件内容进行分割。目前支持:pdf, docx, md, txt, html, csv。
使用代码上传时,请注意中文 filename 需要进行 encode 处理,否则容易乱码。
创建一个文件集合 link 传入一个文件,创建一个集合,会读取文件内容进行分割。目前支持:pdf, docx, md, txt, html, csv。
使用代码上传时,请注意中文 filename 需要进行 encode 处理,否则容易乱码。
curl --location --request POST 'http://localhost:3000/api/core/dataset/collection/create/localFile' \
--header 'Authorization: Bearer {{authorization}}' \
--form 'file=@"C:\\Users\\user\\Desktop\\fastgpt测试文件\\index.html"' \
--form 'data="{\"datasetId\":\"6593e137231a2be9c5603ba7\",\"parentId\":null,\"trainingType\":\"chunk\",\"chunkSize\":512,\"chunkSplitter\":\"\",\"qaPrompt\":\"\",\"metadata\":{}}"'
- 需要使用 POST form-data 的格式上传。包含 file 和 data 两个字段。
file: 文件 data: 知识库相关信息(json序列化后传入),参数说明见上方“通用创建参数说明” 需要使用 POST form-data 的格式上传。包含 file 和 data 两个字段。
file: 文件 data: 知识库相关信息(json序列化后传入),参数说明见上方“通用创建参数说明” data 为集合的 ID。
{
"code": 200,
"statusText": "",
@@ -272,9 +272,9 @@ Table of Contents 创建一个API集合 link 传入一个文件的 id,创建一个集合,会读取文件内容进行分割。目前支持:pdf, docx, md, txt, html, csv。
使用代码上传时,请注意中文 filename 需要进行 encode 处理,否则容易乱码。
创建一个API集合 link 传入一个文件的 id,创建一个集合,会读取文件内容进行分割。目前支持:pdf, docx, md, txt, html, csv。
使用代码上传时,请注意中文 filename 需要进行 encode 处理,否则容易乱码。
curl --location --request POST 'http://localhost:3000/api/core/dataset/collection/create/apiCollection' \
--header 'Authorization: Bearer fastgpt-xxx' \
--header 'Content-Type: application/json' \
@@ -290,7 +290,7 @@ Table of Contents 需要使用 POST form-data 的格式上传。包含 file 和 data 两个字段。
name: 集合名,建议就用文件名,必填。 apiFileId: 文件的ID,必填。 datasetId: 知识库的ID(必填) parentId: 父级ID,不填则默认为根目录 trainingType:训练模式(必填) chunkSize: 每个 chunk 的长度(可选). chunk模式:100~3000; qa模式: 4000~模型最大token(16k模型通常建议不超过10000) chunkSplitter: 自定义最高优先分割符号(可选) qaPrompt: qa拆分自定义提示词(可选) 需要使用 POST form-data 的格式上传。包含 file 和 data 两个字段。
name: 集合名,建议就用文件名,必填。 apiFileId: 文件的ID,必填。 datasetId: 知识库的ID(必填) parentId: 父级ID,不填则默认为根目录 trainingType:训练模式(必填) chunkSize: 每个 chunk 的长度(可选). chunk模式:100~3000; qa模式: 4000~模型最大token(16k模型通常建议不超过10000) chunkSplitter: 自定义最高优先分割符号(可选) qaPrompt: qa拆分自定义提示词(可选) data 为集合的 ID。
{
"code": 200,
"statusText": "",
@@ -305,9 +305,9 @@ Table of Contents 创建一个外部文件库集合(商业版) link 创建一个外部文件库集合(商业版) link
curl --location --request POST 'http://localhost:3000/api/proApi/core/dataset/collection/create/externalFileUrl' \
--header 'Authorization: Bearer {{authorization}}' \
--header 'User-Agent: Apifox/1.0.0 (https://apifox.com)' \
@@ -326,7 +326,7 @@ Table of Contents 参数 说明 必填 externalFileUrl 文件访问链接(可以是临时链接) ✅ externalFileId 外部文件ID filename 自定义文件名,需要带后缀 createTime 文件创建时间(Date ISO 字符串都 ok)
参数 说明 必填 externalFileUrl 文件访问链接(可以是临时链接) ✅ externalFileId 外部文件ID filename 自定义文件名,需要带后缀 createTime 文件创建时间(Date ISO 字符串都 ok)
data 为集合的 ID。
{
"code": 200,
"statusText": "",
@@ -341,9 +341,9 @@ Table of Contents 4.8.19+
curl --location --request POST 'http://localhost:3000/api/core/dataset/collection/listV2' \
--header 'Authorization: Bearer {{authorization}}' \
--header 'Content-Type: application/json' \
@@ -365,7 +365,7 @@ Table of Contents
offset: 偏移量 pageSize: 每页数量,最大30(选填) datasetId: 知识库的ID(必填) parentId: 父级Id(选填) searchText: 模糊搜索文本(选填)
offset: 偏移量 pageSize: 每页数量,最大30(选填) datasetId: 知识库的ID(必填) parentId: 父级Id(选填) searchText: 模糊搜索文本(选填)
{
"code": 200,
"statusText": "",
@@ -425,12 +425,12 @@ Table of Contents
curl --location --request GET 'http://localhost:3000/api/core/dataset/collection/detail?id=65abcfab9d1448617cba5f0d' \
--header 'Authorization: Bearer {{authorization}}' \
-
{
"code": 200,
"statusText": "",
@@ -469,9 +469,9 @@ Table of Contents 通过集合 ID 修改集合信息
curl --location --request PUT 'http://localhost:3000/api/core/dataset/collection/update' \
--header 'Authorization: Bearer {{authorization}}' \
--header 'Content-Type: application/json' \
@@ -496,29 +496,29 @@ Table of Contents
id: 集合的ID parentId: 修改父级ID(可选) name: 修改集合名称(可选) tags: 修改集合标签(可选) forbid: 修改集合禁用状态(可选) createTime: 修改集合创建时间(可选)
id: 集合的ID parentId: 修改父级ID(可选) name: 修改集合名称(可选) tags: 修改集合标签(可选) forbid: 修改集合禁用状态(可选) createTime: 修改集合创建时间(可选)
{
"code": 200,
"statusText": "",
"message": "",
"data": null
}
-
curl --location --request DELETE 'http://localhost:3000/api/core/dataset/collection/delete?id=65aa2a64e6cb9b8ccdc00de8' \
--header 'Authorization: Bearer {{authorization}}' \
-
{
"code": 200,
"statusText": "",
"message": "",
"data": null
}
- Data结构
字段 类型 说明 必填 teamId String 团队ID ✅ tmbId String 成员ID ✅ datasetId String 知识库ID ✅ collectionId String 集合ID ✅ q String 主要数据 ✅ a String 辅助数据 ✖ fullTextToken String 分词 ✖ indexes Index[] 向量索引 ✅ updateTime Date 更新时间 ✅ chunkIndex Number 分块下表 ✖
Index结构
每组数据的自定义索引最多5个
字段 类型 说明 必填 type String 可选索引类型:default-默认索引; custom-自定义索引; summary-总结索引; question-问题索引; image-图片索引 dataId String 关联的向量ID,变更数据时候传入该 ID,会进行差量更新,而不是全量更新 text String 文本内容 ✅
type 不填则默认为 custom 索引,还会基于 q/a 组成一个默认索引。如果传入了默认索引,则不会额外创建。
为集合批量添加添加数据 link 注意,每次最多推送 200 组数据。
Data结构
字段 类型 说明 必填 teamId String 团队ID ✅ tmbId String 成员ID ✅ datasetId String 知识库ID ✅ collectionId String 集合ID ✅ q String 主要数据 ✅ a String 辅助数据 ✖ fullTextToken String 分词 ✖ indexes Index[] 向量索引 ✅ updateTime Date 更新时间 ✅ chunkIndex Number 分块下表 ✖
Index结构
每组数据的自定义索引最多5个
字段 类型 说明 必填 type String 可选索引类型:default-默认索引; custom-自定义索引; summary-总结索引; question-问题索引; image-图片索引 dataId String 关联的向量ID,变更数据时候传入该 ID,会进行差量更新,而不是全量更新 text String 文本内容 ✅
type 不填则默认为 custom 索引,还会基于 q/a 组成一个默认索引。如果传入了默认索引,则不会额外创建。
为集合批量添加添加数据 link 注意,每次最多推送 200 组数据。
curl --location --request POST 'https://api.fastgpt.in/api/core/dataset/data/pushData' \
--header 'Authorization: Bearer apikey' \
--header 'Content-Type: application/json' \
@@ -546,7 +546,7 @@ Table of Contents
collectionId: 集合ID(必填) trainingType:训练模式(必填) prompt: 自定义 QA 拆分提示词,需严格按照模板,建议不要传入。(选填) data:(具体数据)q: 主要数据(必填) a: 辅助数据(选填) indexes: 自定义索引(选填)。可以不传或者传空数组,默认都会使用q和a组成一个索引。
collectionId: 集合ID(必填) trainingType:训练模式(必填) prompt: 自定义 QA 拆分提示词,需严格按照模板,建议不要传入。(选填) data:(具体数据)q: 主要数据(必填) a: 辅助数据(选填) indexes: 自定义索引(选填)。可以不传或者传空数组,默认都会使用q和a组成一个索引。
{
"code": 200,
"statusText": "",
@@ -557,7 +557,7 @@ Table of Contents {{theme}} 里的内容可以换成数据的主题。默认为:它们可能包含多个主题内容
{{theme}} 里的内容可以换成数据的主题。默认为:它们可能包含多个主题内容
我会给你一段文本,{{theme}},学习它们,并整理学习成果,要求为:
1. 提出最多 25 个问题。
2. 给出每个问题的答案。
@@ -571,9 +571,9 @@ A2:
……
我的文本:"""{{text}}"""
- 获取集合的数据列表 link 获取集合的数据列表 link 4.8.11+
curl --location --request POST 'http://localhost:3000/api/core/dataset/data/v2/list' \
--header 'Authorization: Bearer {{authorization}}' \
--header 'Content-Type: application/json' \
@@ -593,7 +593,7 @@ A2:
"collectionId":"65abd4ac9d1448617cba6171",
"searchText":""
}'
-
offset: 偏移量(选填) pageSize: 每页数量,最大30(选填) collectionId: 集合的ID(必填) searchText: 模糊搜索词(选填)
offset: 偏移量(选填) pageSize: 每页数量,最大30(选填) collectionId: 集合的ID(必填) searchText: 模糊搜索词(选填)
{
"code": 200,
"statusText": "",
@@ -620,12 +620,12 @@ A2:
"total": 63
}
}
- 获取单条数据详情 link 获取单条数据详情 link
curl --location --request GET 'http://localhost:3000/api/core/dataset/data/detail?id=65abd4b29d1448617cba61db' \
--header 'Authorization: Bearer {{authorization}}' \
-
{
"code": 200,
"statusText": "",
@@ -651,9 +651,9 @@ A2:
"canWrite": true
}
}
-
curl --location --request PUT 'http://localhost:3000/api/core/dataset/data/update' \
--header 'Authorization: Bearer {{authorization}}' \
--header 'Content-Type: application/json' \
@@ -678,28 +678,28 @@ A2:
}
]
}'
-
dataId: 数据的id q: 主要数据(选填) a: 辅助数据(选填) indexes: 自定义索引(选填),类型参考为集合批量添加添加数据。如果创建时候有自定义索引,
dataId: 数据的id q: 主要数据(选填) a: 辅助数据(选填) indexes: 自定义索引(选填),类型参考为集合批量添加添加数据。如果创建时候有自定义索引,
{
"code": 200,
"statusText": "",
"message": "",
"data": null
}
-
curl --location --request DELETE 'http://localhost:3000/api/core/dataset/data/delete?id=65abd4b39d1448617cba624d' \
--header 'Authorization: Bearer {{authorization}}' \
-
{
"code": 200,
"statusText": "",
"message": "",
"data": "success"
}
-
curl --location --request POST 'https://api.fastgpt.in/api/core/dataset/searchTest' \
--header 'Authorization: Bearer fastgpt-xxxxx' \
--header 'Content-Type: application/json' \
@@ -715,7 +715,7 @@ A2:
"datasetSearchExtensionModel": "gpt-4o-mini",
"datasetSearchExtensionBg": ""
}'
-
datasetId - 知识库ID text - 需要测试的文本 limit - 最大 tokens 数量 similarity - 最低相关度(0~1,可选) searchMode - 搜索模式:embedding | fullTextRecall | mixedRecall usingReRank - 使用重排 datasetSearchUsingExtensionQuery - 使用问题优化 datasetSearchExtensionModel - 问题优化模型 datasetSearchExtensionBg - 问题优化背景描述 返回 top k 结果, limit 为最大 Tokens 数量,最多 20000 tokens。
datasetId - 知识库ID text - 需要测试的文本 limit - 最大 tokens 数量 similarity - 最低相关度(0~1,可选) searchMode - 搜索模式:embedding | fullTextRecall | mixedRecall usingReRank - 使用重排 datasetSearchUsingExtensionQuery - 使用问题优化 datasetSearchExtensionModel - 问题优化模型 datasetSearchExtensionBg - 问题优化背景描述 返回 top k 结果, limit 为最大 Tokens 数量,最多 20000 tokens。
{
"code": 200,
"statusText": "",
diff --git a/docs/development/openapi/share/index.html b/docs/development/openapi/share/index.html
index d98a9fbf7..aec1fd36e 100644
--- a/docs/development/openapi/share/index.html
+++ b/docs/development/openapi/share/index.html
@@ -43,43 +43,43 @@ Table of Contents FastGPT 将会判断success是否为true决定是允许用户继续操作。message与msg是等同的,你可以选择返回其中一个,当success不为true时,将会提示这个错误。
uid是用户的唯一凭证,将会用于拉取对话记录以及保存对话记录。可参考下方实践案例。
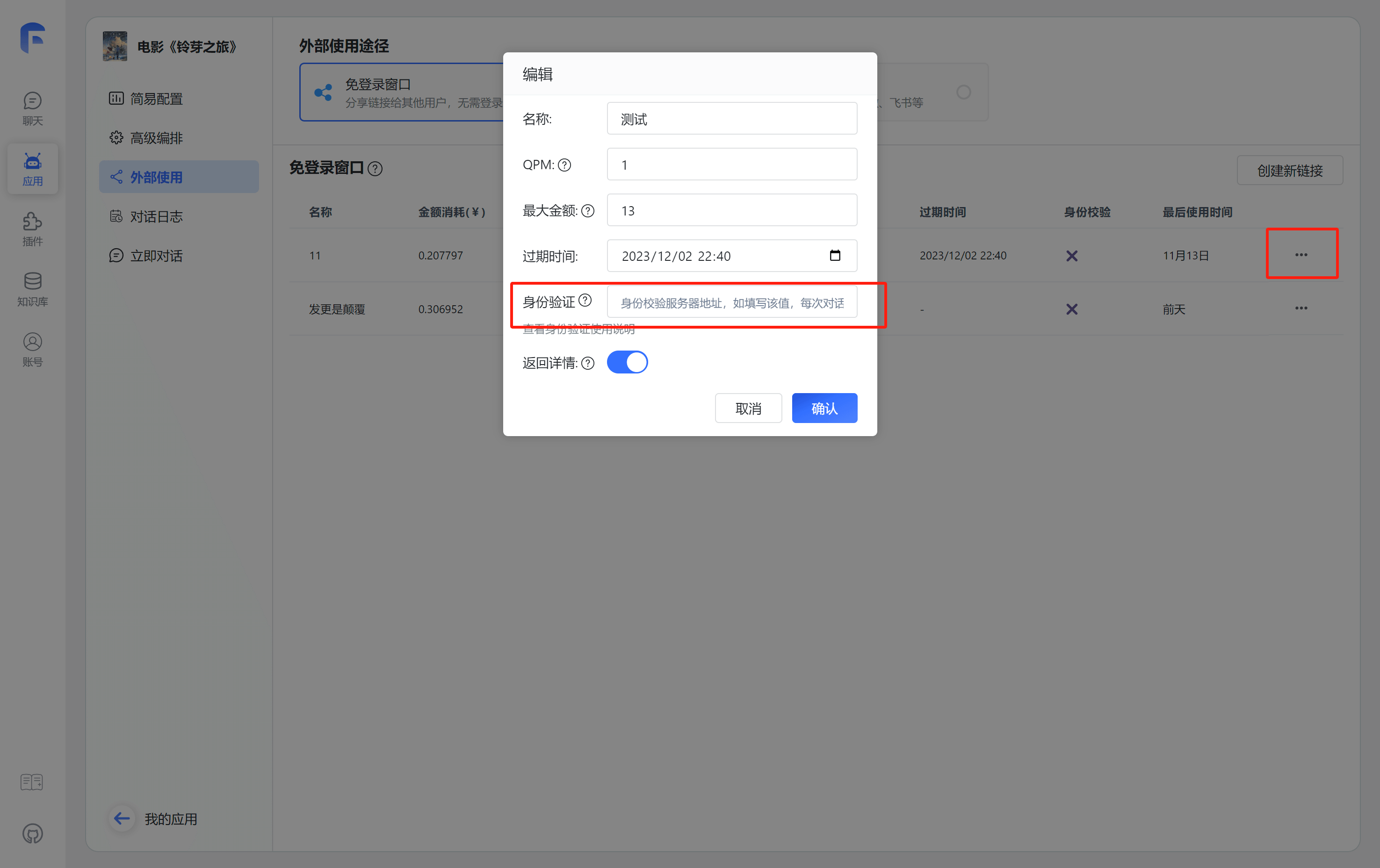
1. 配置身份校验地址 link
配置校验地址后,在每次分享链接使用时,都会向对应的地址发起校验和上报请求。
2. 分享链接中增加额外 query link 在分享链接的地址中,增加一个额外的参数: authToken。例如:
原始的链接:https://share.tryfastgpt.ai/chat/share?shareId=648aaf5ae121349a16d62192
完整链接: https://share.tryfastgpt.ai/chat/share?shareId=648aaf5ae121349a16d62192&authToken=userid12345
这个authToken通常是你系统生成的用户唯一凭证(Token之类的)。FastGPT 会在鉴权接口的body中携带 token={{authToken}} 的参数。
3. 编写聊天初始化校验接口 link FastGPT 将会判断success是否为true决定是允许用户继续操作。message与msg是等同的,你可以选择返回其中一个,当success不为true时,将会提示这个错误。
uid是用户的唯一凭证,将会用于拉取对话记录以及保存对话记录。可参考下方实践案例。
1. 配置身份校验地址 link
配置校验地址后,在每次分享链接使用时,都会向对应的地址发起校验和上报请求。
2. 分享链接中增加额外 query link 在分享链接的地址中,增加一个额外的参数: authToken。例如:
原始的链接:https://share.tryfastgpt.ai/chat/share?shareId=648aaf5ae121349a16d62192
完整链接: https://share.tryfastgpt.ai/chat/share?shareId=648aaf5ae121349a16d62192&authToken=userid12345
这个authToken通常是你系统生成的用户唯一凭证(Token之类的)。FastGPT 会在鉴权接口的body中携带 token={{authToken}} 的参数。
3. 编写聊天初始化校验接口 link
curl --location --request POST '{{host}}/shareAuth/init' \
--header 'Content-Type: application/json' \
--data-raw '{
"token": "{{authToken}}"
}'
-
{
"success": true,
"data": {
"uid": "用户唯一凭证"
}
}
- 系统会拉取该分享链接下,uid 为 username123 的对话记录。
系统会拉取该分享链接下,uid 为 username123 的对话记录。
{
"success": false,
"message": "身份错误",
}
- 4. 编写对话前校验接口 link 4. 编写对话前校验接口 link
curl --location --request POST '{{host}}/shareAuth/start' \
--header 'Content-Type: application/json' \
--data-raw '{
"token": "{{authToken}}",
"question": "用户问题",
}'
-
{
"success": true,
"data": {
"uid": "用户唯一凭证"
}
}
-
{
"success": false,
"message": "身份验证失败",
@@ -202,9 +202,9 @@ Table of Contents 我们以Laf作为服务器为例 ,简单展示这 3 个接口的使用方式。
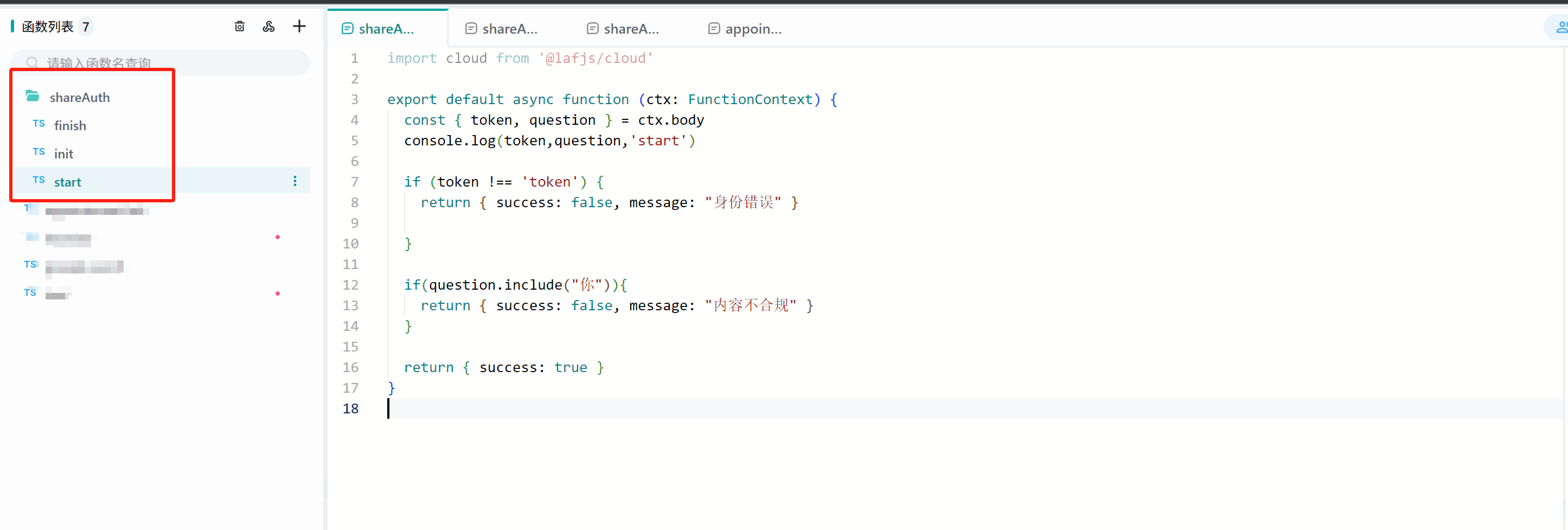
1. 创建3个Laf接口 link
这个接口中,我们设置了token必须等于fastgpt才能通过校验。(实际生产中不建议固定写死)
我们以Laf作为服务器为例 ,简单展示这 3 个接口的使用方式。
1. 创建3个Laf接口 link
这个接口中,我们设置了token必须等于fastgpt才能通过校验。(实际生产中不建议固定写死)
import cloud from '@lafjs/cloud'
export default async function (ctx: FunctionContext) {
@@ -217,7 +217,7 @@ export default async function (ctx: FunctionContext) {
return { success: false,message:"身份错误" }
}
- 这个接口中,我们设置了token必须等于fastgpt才能通过校验。并且如果问题中包含了你字,则会报错,用于模拟敏感校验。
这个接口中,我们设置了token必须等于fastgpt才能通过校验。并且如果问题中包含了你字,则会报错,用于模拟敏感校验。
import cloud from '@lafjs/cloud'
export default async function (ctx: FunctionContext) {
@@ -235,7 +235,7 @@ export default async function (ctx: FunctionContext) {
return { success: true, data: { uid: "user1" } }
}
- 结果上报接口可自行进行逻辑处理。
import cloud from '@lafjs/cloud'
export default async function (ctx: FunctionContext) {
diff --git a/docs/guide/admin/sso/index.html b/docs/guide/admin/sso/index.html
index ea3a6b14c..270236991 100644
--- a/docs/guide/admin/sso/index.html
+++ b/docs/guide/admin/sso/index.html
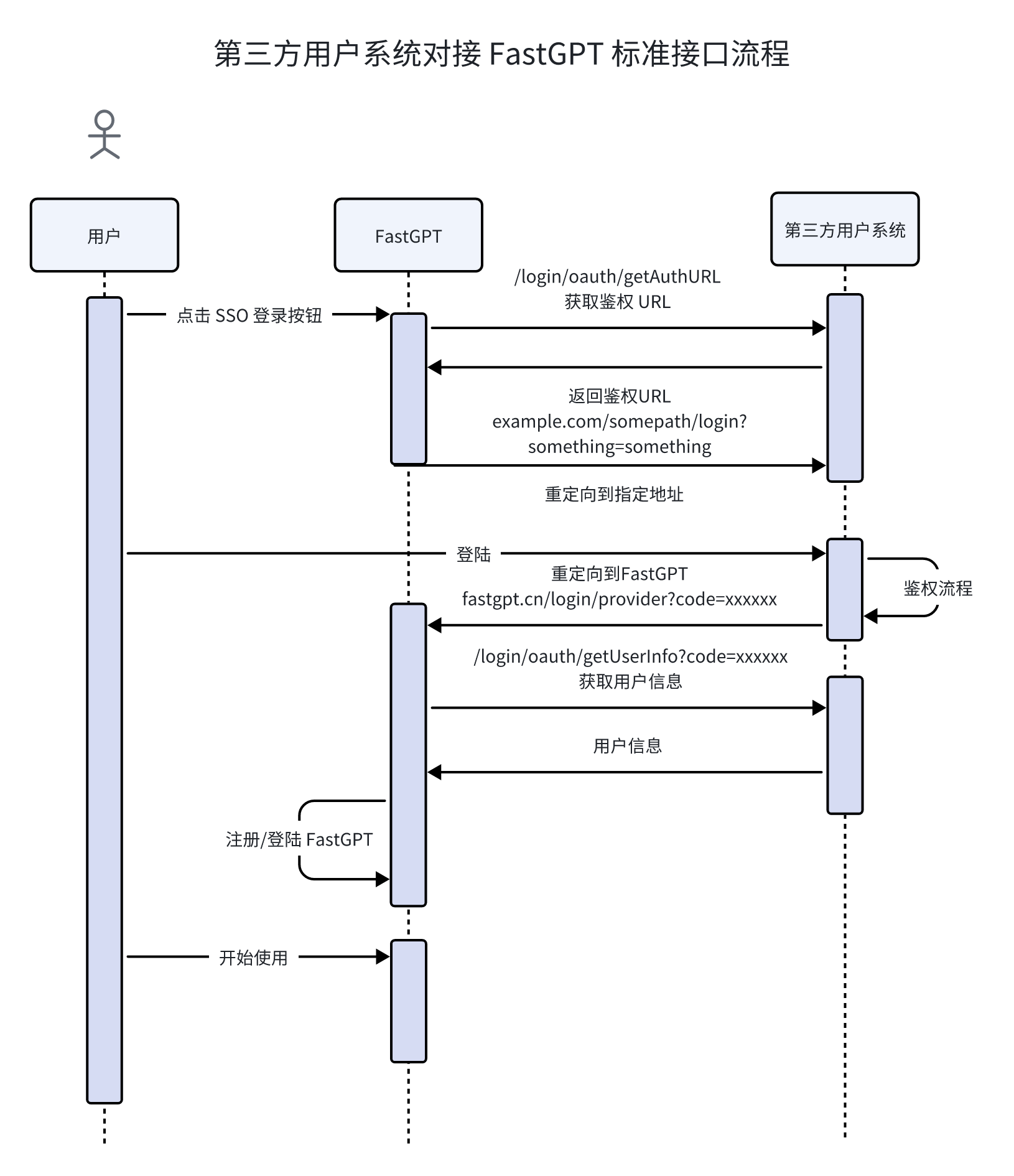
@@ -176,12 +176,12 @@ Table of Contents 以下是 FastGPT-pro 中,SSO 和成员同步的标准接口文档,如果需要对接非标准系统,可以参考该章节进行开发。
FastGPT 提供如下标准接口支持:
https://example.com/login/oauth/getAuthURL 获取鉴权重定向地址https://example.com/login/oauth/getUserInfo?code=xxxxx 消费 code,换取用户信息https://example.com/org/list 获取组织列表https://example.com/user/list 获取成员列表获取 SSO 登录重定向地址 link 返回一个重定向登录地址,fastgpt 会自动重定向到该地址。redirect_uri 会自动拼接到该地址的 query中。
以下是 FastGPT-pro 中,SSO 和成员同步的标准接口文档,如果需要对接非标准系统,可以参考该章节进行开发。
FastGPT 提供如下标准接口支持:
https://example.com/login/oauth/getAuthURL 获取鉴权重定向地址https://example.com/login/oauth/getUserInfo?code=xxxxx 消费 code,换取用户信息https://example.com/org/list 获取组织列表https://example.com/user/list 获取成员列表获取 SSO 登录重定向地址 link 返回一个重定向登录地址,fastgpt 会自动重定向到该地址。redirect_uri 会自动拼接到该地址的 query中。
curl -X GET "https://redict.example/login/oauth/getAuthURL?redirect_uri=xxx&state=xxxx" \
-H "Authorization: Bearer your_token_here" \
-H "Content-Type: application/json"
- 成功:
{
"success": true,
"message": "",
@@ -193,12 +193,12 @@ Table of Contents SSO 获取用户信息 link 该接口接受一个 code 参数作为鉴权,消费 code 返回用户信息。
SSO 获取用户信息 link 该接口接受一个 code 参数作为鉴权,消费 code 返回用户信息。
curl -X GET "https://oauth.example/login/oauth/getUserInfo?code=xxxxxx" \
-H "Authorization: Bearer your_token_here" \
-H "Content-Type: application/json"
- 成功:
{
"success": true,
"message": "",
@@ -215,12 +215,12 @@ Table of Contents
curl -X GET "https://example.com/org/list" \
-H "Authorization: Bearer your_token_here" \
-H "Content-Type: application/json"
- ⚠️注意:只能存在一个根部门。如果你的系统中存在多个根部门,需要先进行处理,加一个虚拟的根部门。返回值类型:
⚠️注意:只能存在一个根部门。如果你的系统中存在多个根部门,需要先进行处理,加一个虚拟的根部门。返回值类型:
type OrgListResponseType = {
message?: string; // 报错信息
success: boolean;
@@ -247,12 +247,12 @@ Table of Contents
curl -X GET "https://example.com/user/list" \
-H "Authorization: Bearer your_token_here" \
-H "Content-Type: application/json"
- 返回值类型:
type UserListResponseListType = {
message?: string; // 报错信息
success: boolean;
diff --git a/docs/guide/dashboard/workflow/http/index.html b/docs/guide/dashboard/workflow/http/index.html
index faa7784f0..c59b149ee 100644
--- a/docs/guide/dashboard/workflow/http/index.html
+++ b/docs/guide/dashboard/workflow/http/index.html
@@ -34,9 +34,9 @@ FAQ
-Table of Contents
http
HTTP 请求 FastGPT HTTP 模块介绍
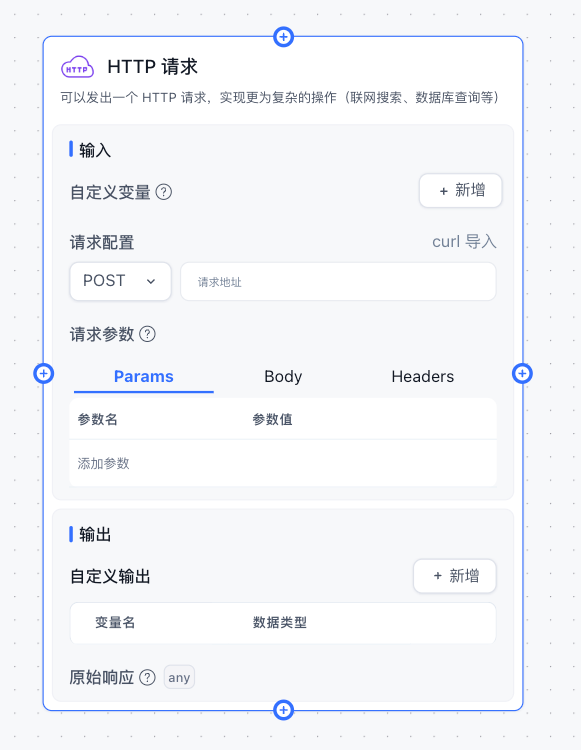
HTTP 模块会向对应的地址发送一个 HTTP 请求,实际操作与 Postman 和 ApiFox 这类直流工具使用差不多。
Params 为路径请求参数,GET请求中用的居多。 Body 为请求体,POST/PUT请求中用的居多。 Headers 为请求头,用于传递一些特殊的信息。 自定义变量中可以接收前方节点的输出作为变量 3 种数据中均可以通过 {{}} 来引用变量。 url 也可以通过 {{}} 来引用变量。 变量来自于全局变量、系统变量、前方节点输出 你可以将鼠标放置在请求参数旁边的问号中,里面会提示你可用的变量。
appId: 应用的ID chatId: 当前对话的ID,测试模式下不存在。 responseChatItemId: 当前对话中,响应的消息ID,测试模式下不存在。 variables: 当前对话的全局变量。 cTime: 当前时间。 histories: 历史记录(默认最多取10条,无法修改长度) 不多描述,使用方法和Postman, ApiFox 基本一致。
可通过 {{key}} 来引入变量。例如:
key value appId {{appId}} Authorization Bearer {{token}}
只有特定请求类型下会生效。
可以写一个自定义的 Json,并通过 {{key}} 来引入变量。例如:
http
HTTP 请求 FastGPT HTTP 模块介绍
HTTP 模块会向对应的地址发送一个 HTTP 请求,实际操作与 Postman 和 ApiFox 这类直流工具使用差不多。
Params 为路径请求参数,GET请求中用的居多。 Body 为请求体,POST/PUT请求中用的居多。 Headers 为请求头,用于传递一些特殊的信息。 自定义变量中可以接收前方节点的输出作为变量 3 种数据中均可以通过 {{}} 来引用变量。 url 也可以通过 {{}} 来引用变量。 变量来自于全局变量、系统变量、前方节点输出 你可以将鼠标放置在请求参数旁边的问号中,里面会提示你可用的变量。
appId: 应用的ID chatId: 当前对话的ID,测试模式下不存在。 responseChatItemId: 当前对话中,响应的消息ID,测试模式下不存在。 variables: 当前对话的全局变量。 cTime: 当前时间。 histories: 历史记录(默认最多取10条,无法修改长度) 不多描述,使用方法和Postman, ApiFox 基本一致。
可通过 {{key}} 来引入变量。例如:
key value appId {{appId}} Authorization Bearer {{token}}
只有特定请求类型下会生效。
可以写一个自定义的 Json,并通过 {{key}} 来引入变量。例如:
{
"string": "字符串",
"number": 123,
@@ -47,7 +47,7 @@ Table of Contents 注意,在 Body 中,你如果引用字符串,则需要加上"",例如:"{{string}}"。
注意,在 Body 中,你如果引用字符串,则需要加上"",例如:"{{string}}"。
{
"string": "{{string}}",
"token": "Bearer {{string}}",
@@ -57,7 +57,7 @@ Table of Contents
{
"string": "字符串",
"token": "Bearer 字符串",
@@ -70,8 +70,8 @@ Table of Contents 从图中可以看出,FastGPT可以添加多个返回值,这个返回值并不代表接口的返回值,而是代表如何解析接口返回值,可以通过 JSON path 的语法,来提取接口响应的值。
语法可以参考: https://github.com/JSONPath-Plus/JSONPath?tab=readme-ov-file
从图中可以看出,FastGPT可以添加多个返回值,这个返回值并不代表接口的返回值,而是代表如何解析接口返回值,可以通过 JSON path 的语法,来提取接口响应的值。
语法可以参考: https://github.com/JSONPath-Plus/JSONPath?tab=readme-ov-file
{
"message": "测试",
"data":{
@@ -89,7 +89,7 @@ Table of Contents
{
"$.message": "测试",
"$.data.user": { "name": "xxx", "age": 12 },
diff --git a/docs/guide/knowledge_base/api_dataset/index.html b/docs/guide/knowledge_base/api_dataset/index.html
index 6d102d793..14d522d43 100644
--- a/docs/guide/knowledge_base/api_dataset/index.html
+++ b/docs/guide/knowledge_base/api_dataset/index.html
@@ -50,8 +50,8 @@ type FileListItem = {
updateTime: Date;
createTime: Date;
}
- 1. 获取文件树 link
parentId - 父级 id,可选,或者 null。 searchKey - 检索词,可选 1. 获取文件树 link
parentId - 父级 id,可选,或者 null。 searchKey - 检索词,可选
curl --location --request POST '{{baseURL}}/v1/file/list' \
--header 'Authorization: Bearer {{authorization}}' \
--header 'Content-Type: application/json' \
@@ -59,7 +59,7 @@ type FileListItem = {
"parentId": null,
"searchKey": ""
}'
-
{
"code": 200,
"success": true,
@@ -75,12 +75,12 @@ type FileListItem = {
}
]
}
- 2. 获取单个文件内容(文本内容或访问链接) link 2. 获取单个文件内容(文本内容或访问链接) link
curl --location --request GET '{{baseURL}}/v1/file/content?id=xx' \
--header 'Authorization: Bearer {{authorization}}'
-
{
"code": 200,
"success": true,
@@ -91,11 +91,11 @@ type FileListItem = {
"previewUrl": "xxxx"
}
}
-
title - 文件标题。 content - 文件内容,直接拿来用。 previewUrl - 文件链接,系统会请求该地址获取文件内容。 content和previewUrl二选一返回,如果同时返回则 content 优先级更高,返回 previewUrl时,则会访问该链接进行文档内容读取。
3. 获取文件阅读链接(用于查看原文) link id 为文件的 id。
title - 文件标题。 content - 文件内容,直接拿来用。 previewUrl - 文件链接,系统会请求该地址获取文件内容。 content和previewUrl二选一返回,如果同时返回则 content 优先级更高,返回 previewUrl时,则会访问该链接进行文档内容读取。
3. 获取文件阅读链接(用于查看原文) link id 为文件的 id。
curl --location --request GET '{{baseURL}}/v1/file/read?id=xx' \
--header 'Authorization: Bearer {{authorization}}'
-
{
"code": 200,
"success": true,
diff --git a/docs/use-cases/external-integration/official_account/index.html b/docs/use-cases/external-integration/official_account/index.html
index 265be4965..0c03f0b45 100644
--- a/docs/use-cases/external-integration/official_account/index.html
+++ b/docs/use-cases/external-integration/official_account/index.html
@@ -33,8 +33,8 @@ FAQ
-Table of Contents
description
接入微信公众号教程 FastGPT 接入微信公众号教程
从 4.8.10 版本起,FastGPT 商业版支持直接接入微信公众号,无需额外的 API。
注意⚠️: 目前只支持通过验证的公众号(服务号和订阅号都可以)
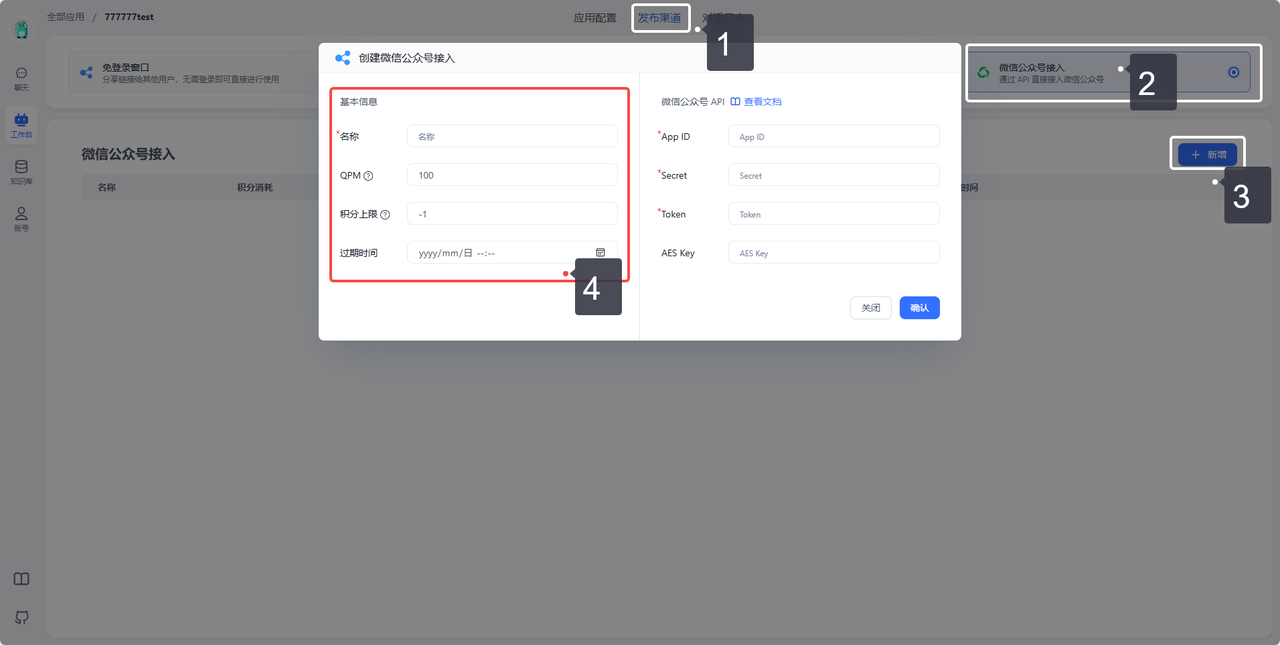
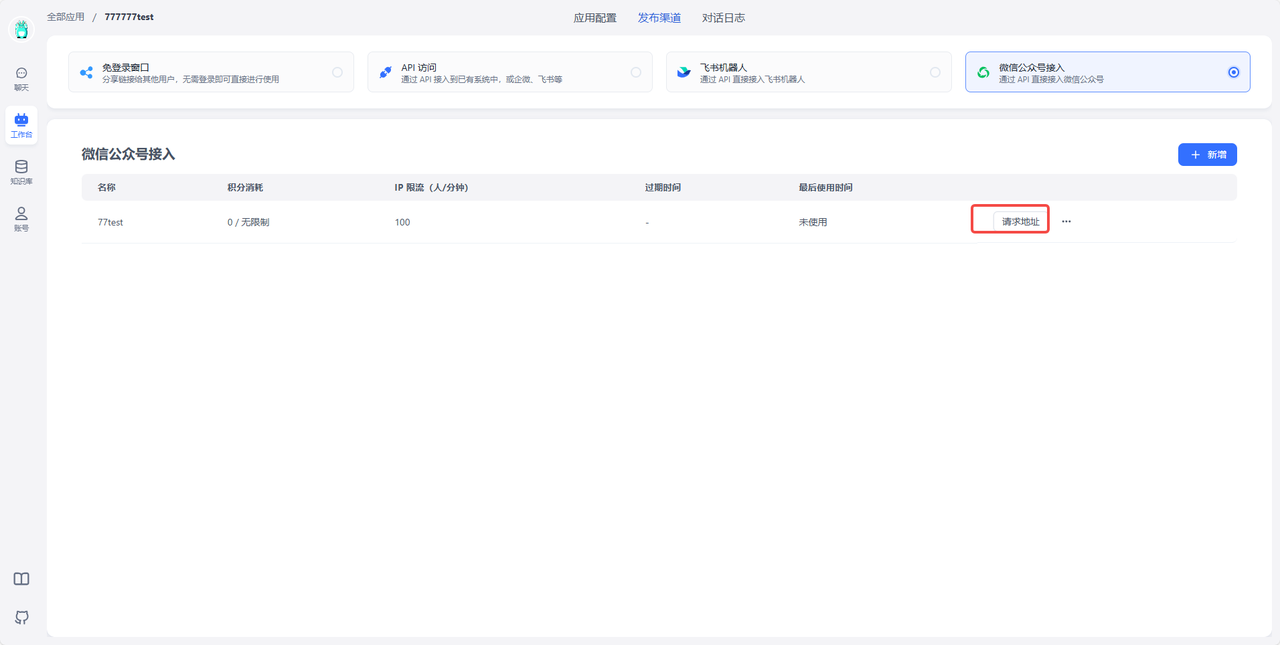
1. 在 FastGPT 新建发布渠道 link 在 FastGPT 中选择想要接入的应用,在 发布渠道 页面,新建一个接入微信公众号的发布渠道,填写好基础信息。
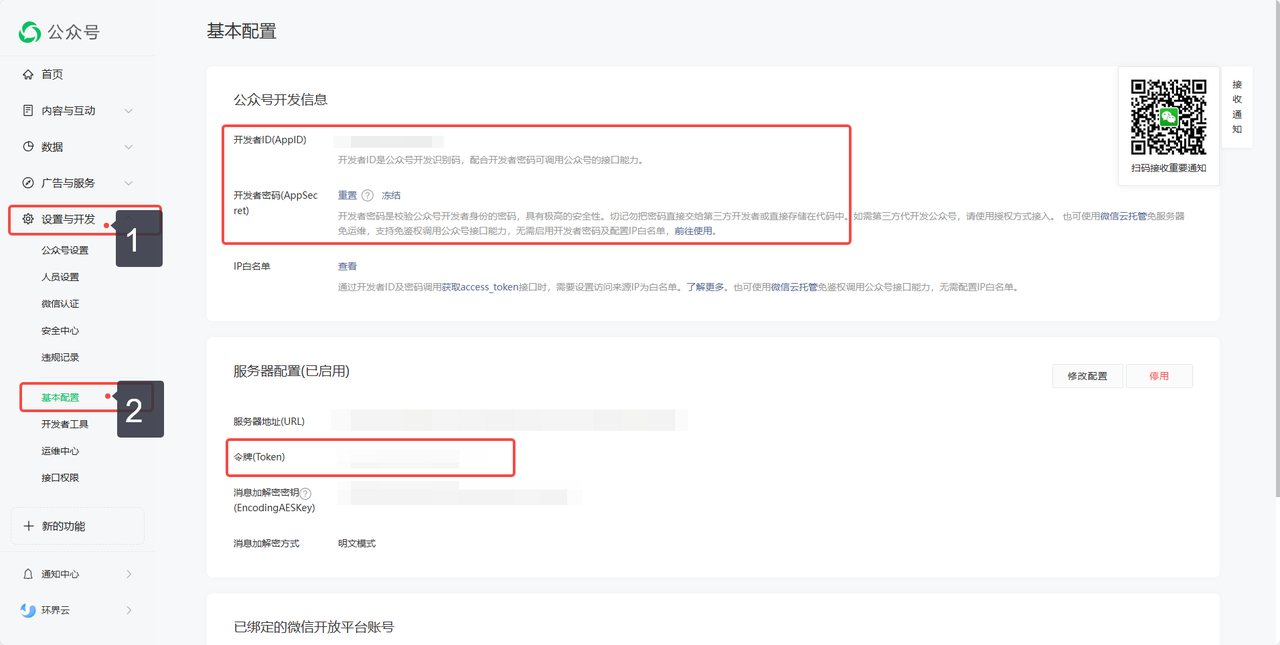
2. 获取 AppID 、 Secret和Token link 1. 登录微信公众平台,选择您的公众号。 link 打开微信公众号官网:https://mp.weixin.qq.com
只支持通过验证的公众号,未通过验证的公众号暂不支持。
开发者可以从这个链接申请微信公众号的测试号进行测试,测试号可以正常使用,但不能配置 AES Key
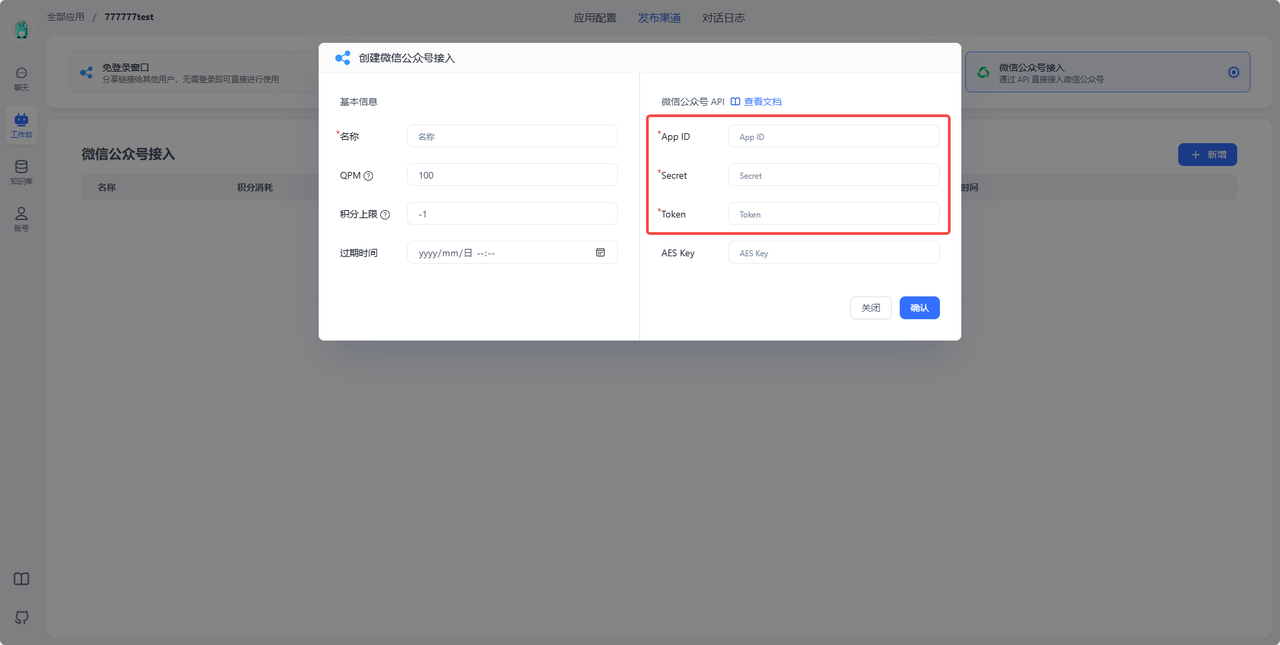
2. 把3个参数填入 FastGPT 配置弹窗中。 link
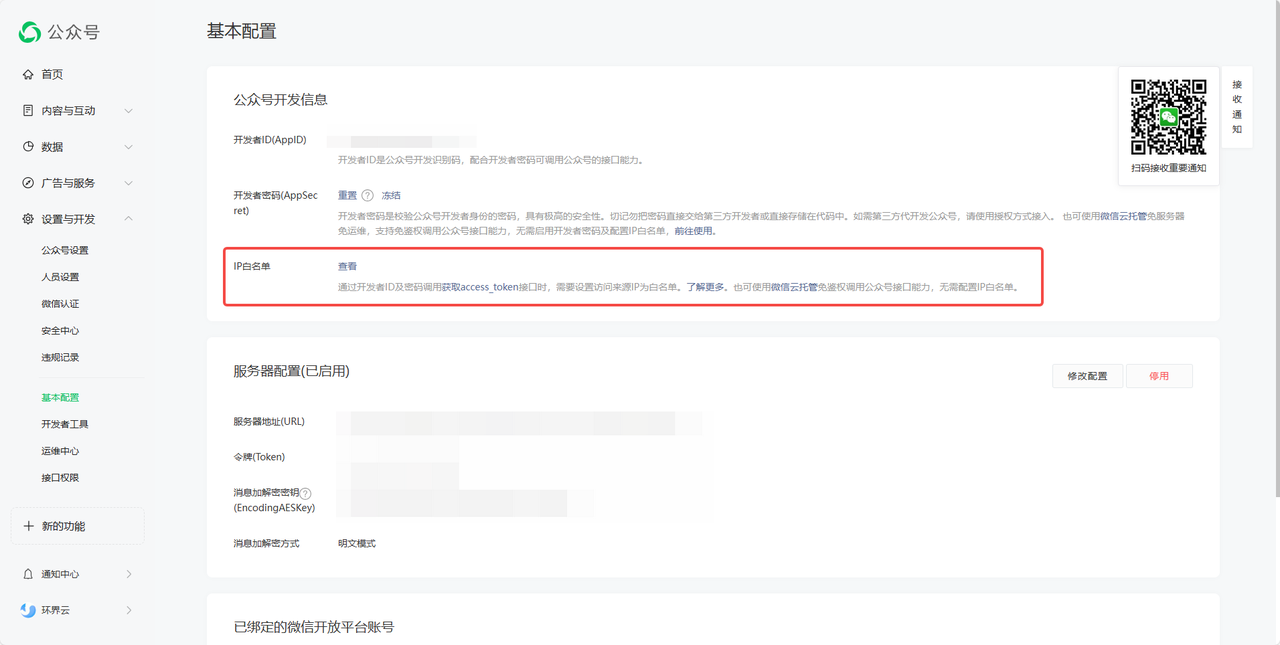
3. 在 IP 白名单中加入 FastGPT 的 IP link
私有部署的用户可自行查阅自己的 IP 地址。
海外版用户(cloud.tryfastgpt.ai)可以填写下面的 IP 白名单:
+Table of Contents
description
接入微信公众号教程 FastGPT 接入微信公众号教程
从 4.8.10 版本起,FastGPT 商业版支持直接接入微信公众号,无需额外的 API。
注意⚠️: 目前只支持通过验证的公众号(服务号和订阅号都可以)
1. 在 FastGPT 新建发布渠道 link 在 FastGPT 中选择想要接入的应用,在 发布渠道 页面,新建一个接入微信公众号的发布渠道,填写好基础信息。
2. 获取 AppID 、 Secret和Token link 1. 登录微信公众平台,选择您的公众号。 link 打开微信公众号官网:https://mp.weixin.qq.com
只支持通过验证的公众号,未通过验证的公众号暂不支持。
开发者可以从这个链接申请微信公众号的测试号进行测试,测试号可以正常使用,但不能配置 AES Key
2. 把3个参数填入 FastGPT 配置弹窗中。 link
3. 在 IP 白名单中加入 FastGPT 的 IP link
私有部署的用户可自行查阅自己的 IP 地址。
海外版用户(cloud.tryfastgpt.ai)可以填写下面的 IP 白名单:
35.240.227.100
34.124.237.188
34.143.240.160
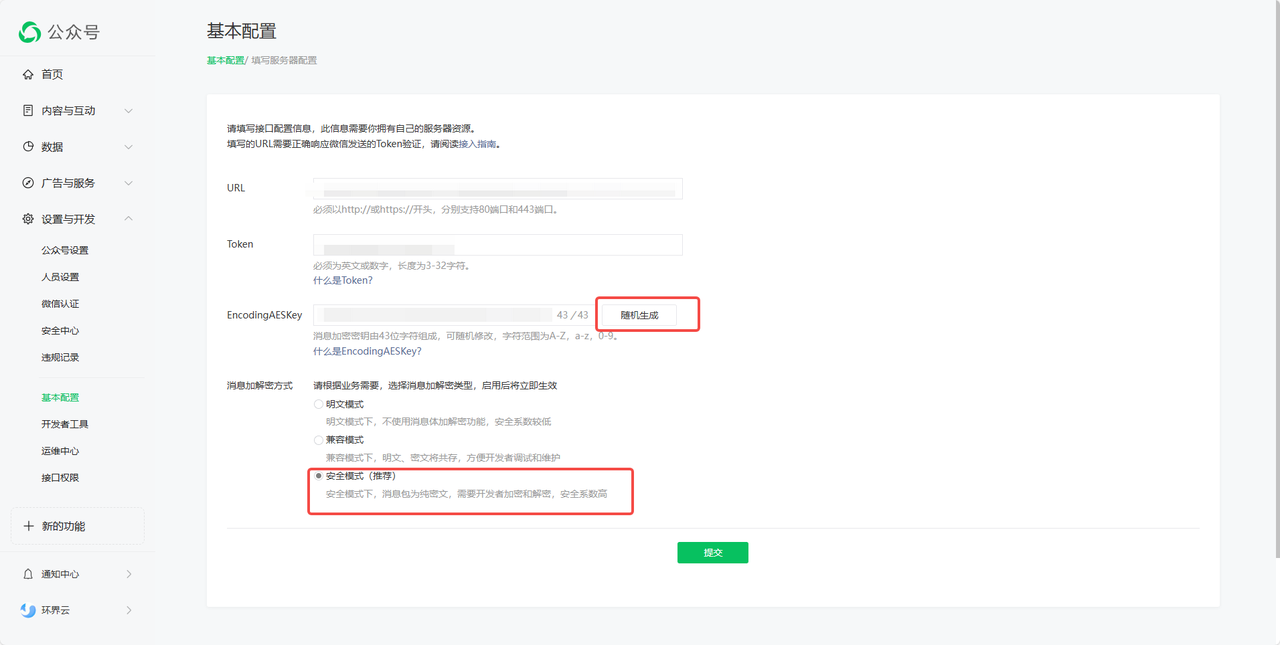
@@ -89,7 +89,8 @@ Table of Contents 4. 获取AES Key,选择加密方式 link
随机生成AESKey,填入 FastGPT 配置弹窗中。
选择加密方式为安全模式。
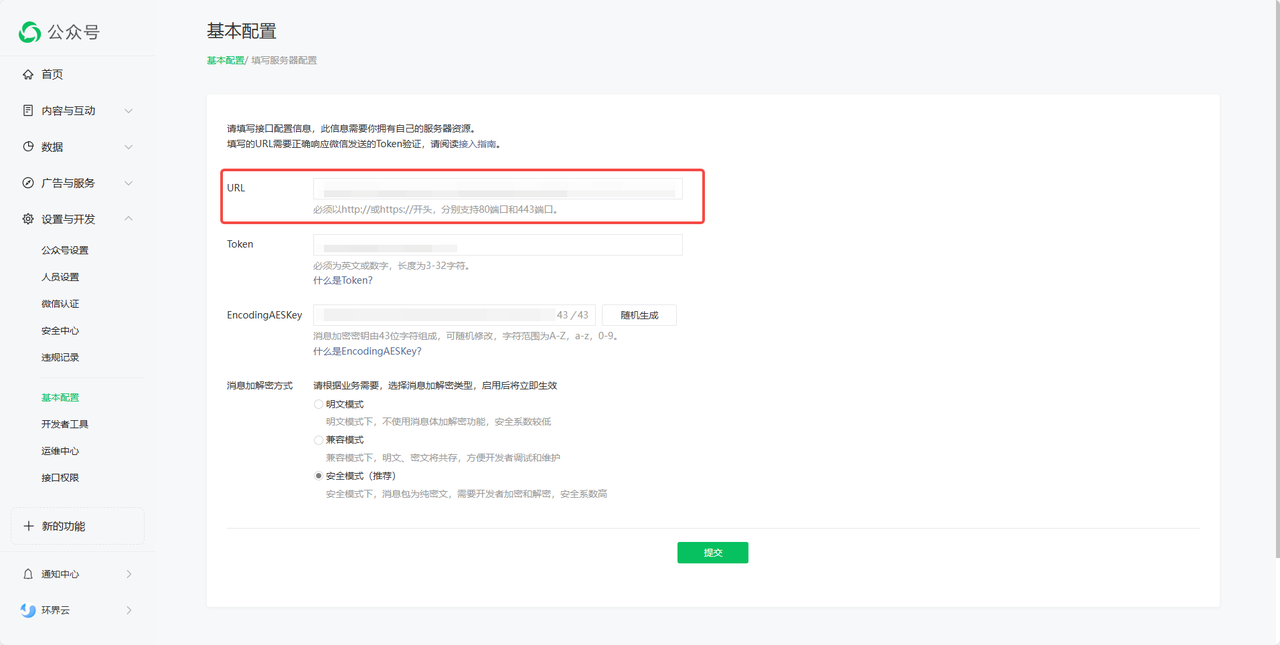
5. 获取 URL link 在FastGPT确认创建,获取URL。
填入微信公众平台的 URL 处,然后提交保存
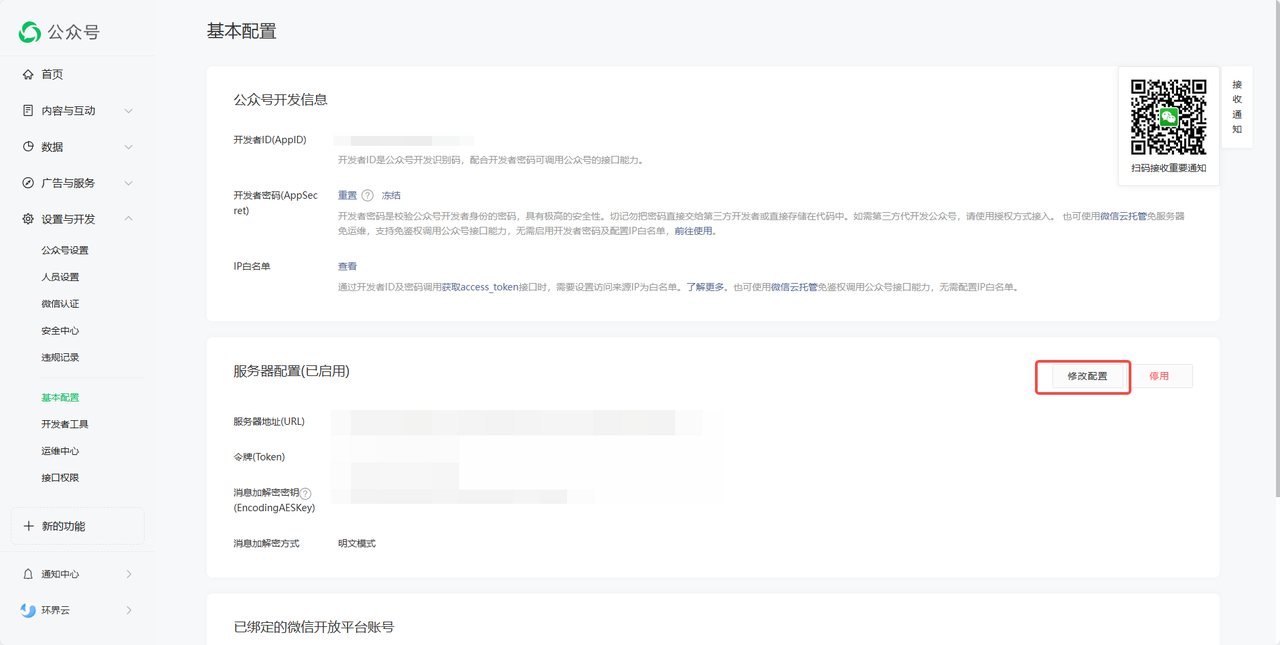
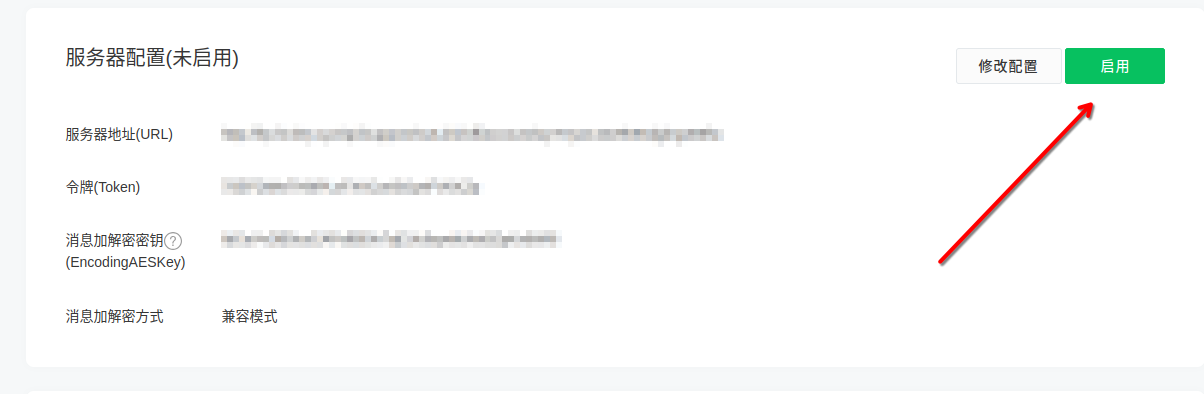
- 6. 启用服务器配置(如已自动启用,请忽略) link
现在用户向公众号发消息,消息则会被转发到 FastGPT,通过公众号返回对话结果。
如何新开一个聊天记录 link 如果你想重置你的聊天记录,可以给机器人发送 Reset 消息(注意大小写),机器人会新开一个聊天记录。
© 2025 the FastGPT Authors.
云操作系统 Sealos
6. 启用服务器配置(如已自动启用,请忽略) link
现在用户向公众号发消息,消息则会被转发到 FastGPT,通过公众号返回对话结果。
检查应用对话日志,如果有对话日志,但是微信公众号无响应,则是白名单 IP未成功。
+添加白名单IP 后,通常需要等待几分钟微信更新。
如何新开一个聊天记录 link 如果你想重置你的聊天记录,可以给机器人发送 Reset 消息(注意大小写),机器人会新开一个聊天记录。
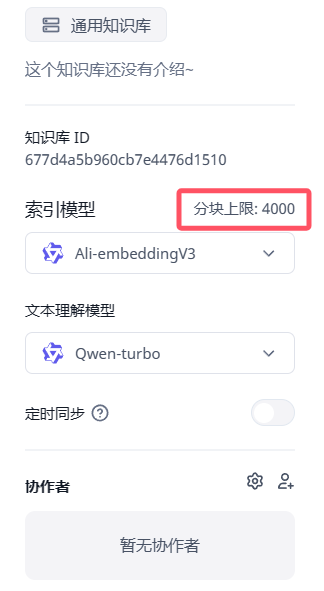 这是索引模型的长度限制,通过任何方式部署都一样的,但不同索引模型的配置不一样,可以在后台修改参数。
这是索引模型的长度限制,通过任何方式部署都一样的,但不同索引模型的配置不一样,可以在后台修改参数。