前置知识
- 基础的网络知识:端口,防火墙……
- Docker 和 Docker Compose 基础知识
- 大模型相关接口和参数
- RAG 相关知识:向量模型,向量数据库,向量检索
部署架构图
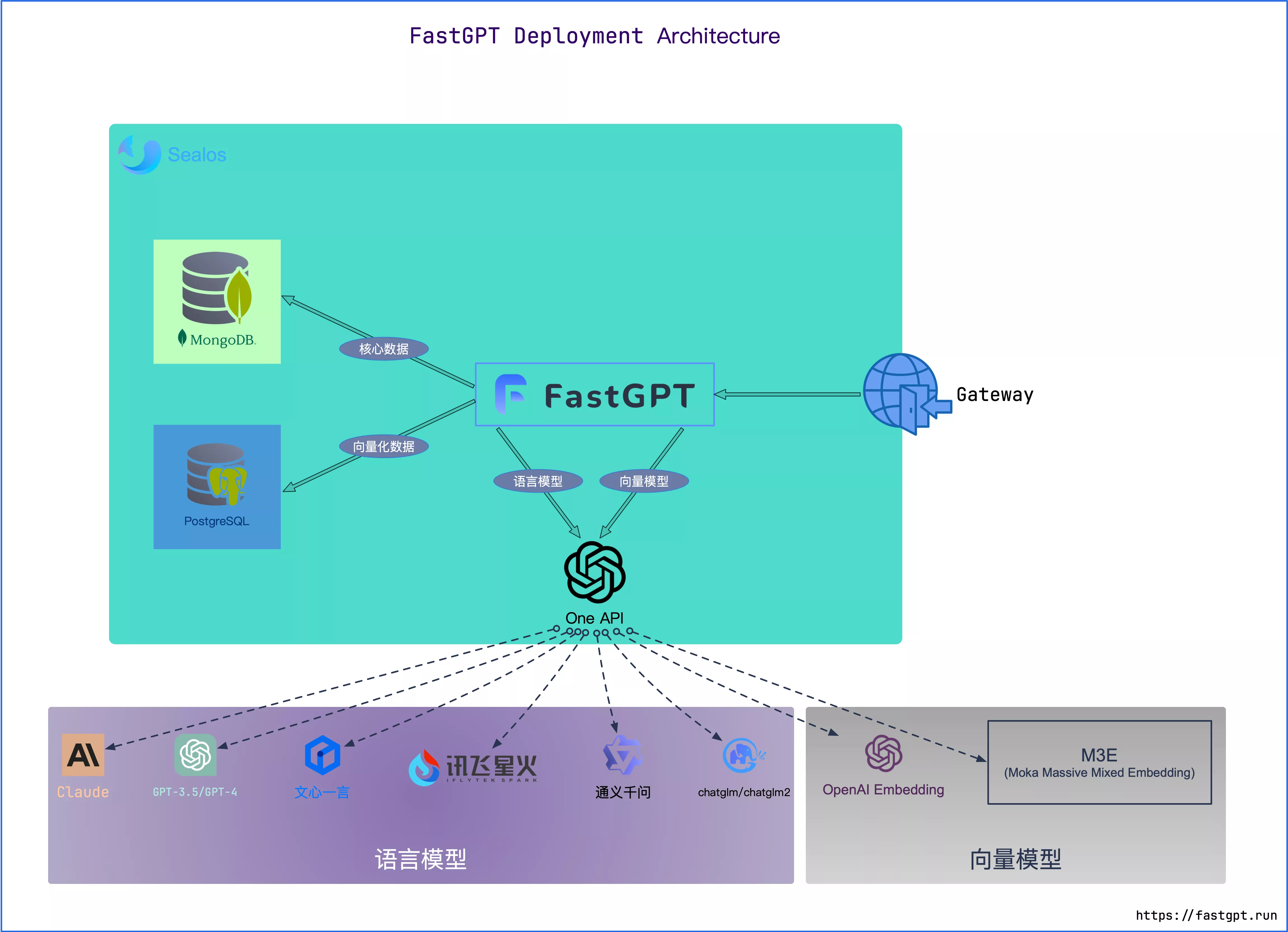
MongoDB:用于存储除了向量外的各类数据
PostgreSQL/Milvus:存储向量数据
OneAPI: 聚合各类 AI API,支持多模型调用 (任何模型问题,先自行通过 OneAPI 测试校验)
推荐配置
PgVector版本
非常轻量,适合知识库索引量在 5000 万以下。
| 环境 | 最低配置(单节点) | 推荐配置 |
|---|---|---|
| 测试(可以把计算进程设置少一些) | 2c4g | 2c8g |
| 100w 组向量 | 4c8g 50GB | 4c16g 50GB |
| 500w 组向量 | 8c32g 200GB | 16c64g 200GB |
Milvus版本
对于亿级以上向量性能更优秀。
| 环境 | 最低配置(单节点) | 推荐配置 |
|---|---|---|
| 测试 | 2c8g | 4c16g |
| 100w 组向量 | 未测试 | |
| 500w 组向量 |
zilliz cloud版本
Zilliz Cloud 由 Milvus 原厂打造,是全托管的 SaaS 向量数据库服务,性能优于 Milvus 并提供 SLA,点击使用 Zilliz Cloud。
由于向量库使用了 Cloud,无需占用本地资源,无需太关注。
前置工作
1. 确保网络环境
如果使用OpenAI等国外模型接口,请确保可以正常访问,否则会报错:Connection error 等。 方案可以参考:代理方案
2. 准备 Docker 环境
+Table of Contents
Docker Compose 快速部署
使用 Docker Compose 快速部署 FastGPT
前置知识
- 基础的网络知识:端口,防火墙……
- Docker 和 Docker Compose 基础知识
- 大模型相关接口和参数
- RAG 相关知识:向量模型,向量数据库,向量检索
部署架构图
MongoDB:用于存储除了向量外的各类数据
PostgreSQL/Milvus:存储向量数据
OneAPI: 聚合各类 AI API,支持多模型调用 (任何模型问题,先自行通过 OneAPI 测试校验)
推荐配置
PgVector版本
非常轻量,适合知识库索引量在 5000 万以下。
| 环境 | 最低配置(单节点) | 推荐配置 |
|---|---|---|
| 测试(可以把计算进程设置少一些) | 2c4g | 2c8g |
| 100w 组向量 | 4c8g 50GB | 4c16g 50GB |
| 500w 组向量 | 8c32g 200GB | 16c64g 200GB |
Milvus版本
对于亿级以上向量性能更优秀。
| 环境 | 最低配置(单节点) | 推荐配置 |
|---|---|---|
| 测试 | 2c8g | 4c16g |
| 100w 组向量 | 未测试 | |
| 500w 组向量 |
zilliz cloud版本
Zilliz Cloud 由 Milvus 原厂打造,是全托管的 SaaS 向量数据库服务,性能优于 Milvus 并提供 SLA,点击使用 Zilliz Cloud。
由于向量库使用了 Cloud,无需占用本地资源,无需太关注。
前置工作
1. 确保网络环境
如果使用OpenAI等国外模型接口,请确保可以正常访问,否则会报错:Connection error 等。 方案可以参考:代理方案
2. 准备 Docker 环境
开始部署
1. 下载 docker-compose.yml
非 Linux 环境或无法访问外网环境,可手动创建一个目录,并下载配置文件和对应版本的docker-compose.yml,在这个文件夹中依据下载的配置文件运行docker,若作为本地开发使用推荐docker-compose-pgvector版本,并且自行拉取并运行sandbox和fastgpt,并在docker配置文件中注释掉sandbox和fastgpt的部分
- config.json
- docker-compose.yml (注意,不同向量库版本的文件不一样)
所有 docker-compose.yml 配置文件中 MongoDB 为 5.x,需要用到AVX指令集,部分 CPU 不支持,需手动更改其镜像版本为 4.4.24**(需要自己在docker hub下载,阿里云镜像没做备份)
Linux 快速脚本
+
或者直接下载安装包进行安装。
我们建议将源代码和其他数据绑定到 Linux 容器中时,将其存储在 Linux 文件系统中,而不是 Windows 文件系统中。
可以选择直接使用 WSL 2 后端在 Windows 中安装 Docker Desktop。
也可以直接在 WSL 2 中安装命令行版本的 Docker。
开始部署
1. 下载 docker-compose.yml
非 Linux 环境或无法访问外网环境,可手动创建一个目录,并下载配置文件和对应版本的docker-compose.yml,在这个文件夹中依据下载的配置文件运行docker,若作为本地开发使用推荐docker-compose-pgvector版本,并且自行拉取并运行sandbox和fastgpt,并在docker配置文件中注释掉sandbox和fastgpt的部分
- config.json
- docker-compose.yml (注意,不同向量库版本的文件不一样)
所有 docker-compose.yml 配置文件中 MongoDB 为 5.x,需要用到AVX指令集,部分 CPU 不支持,需手动更改其镜像版本为 4.4.24**(需要自己在docker hub下载,阿里云镜像没做备份)
Linux 快速脚本
mkdir fastgpt
cd fastgpt
curl -O https://raw.githubusercontent.com/labring/FastGPT/main/projects/app/data/config.json
@@ -63,9 +63,9 @@ curl -o docker-compose.yml https://raw.githubusercontent.com/labring/FastGPT/mai
# curl -o docker-compose.yml https://raw.githubusercontent.com/labring/FastGPT/main/deploy/docker/docker-compose-milvus.yml
# zilliz 版本
# curl -o docker-compose.yml https://raw.githubusercontent.com/labring/FastGPT/main/deploy/docker/docker-compose-zilliz.yml
- 2. 修改环境变量
找到 yml 文件中,fastgpt 容器的环境变量进行下面操作:
打开 Zilliz Cloud, 创建实例并获取相关秘钥。
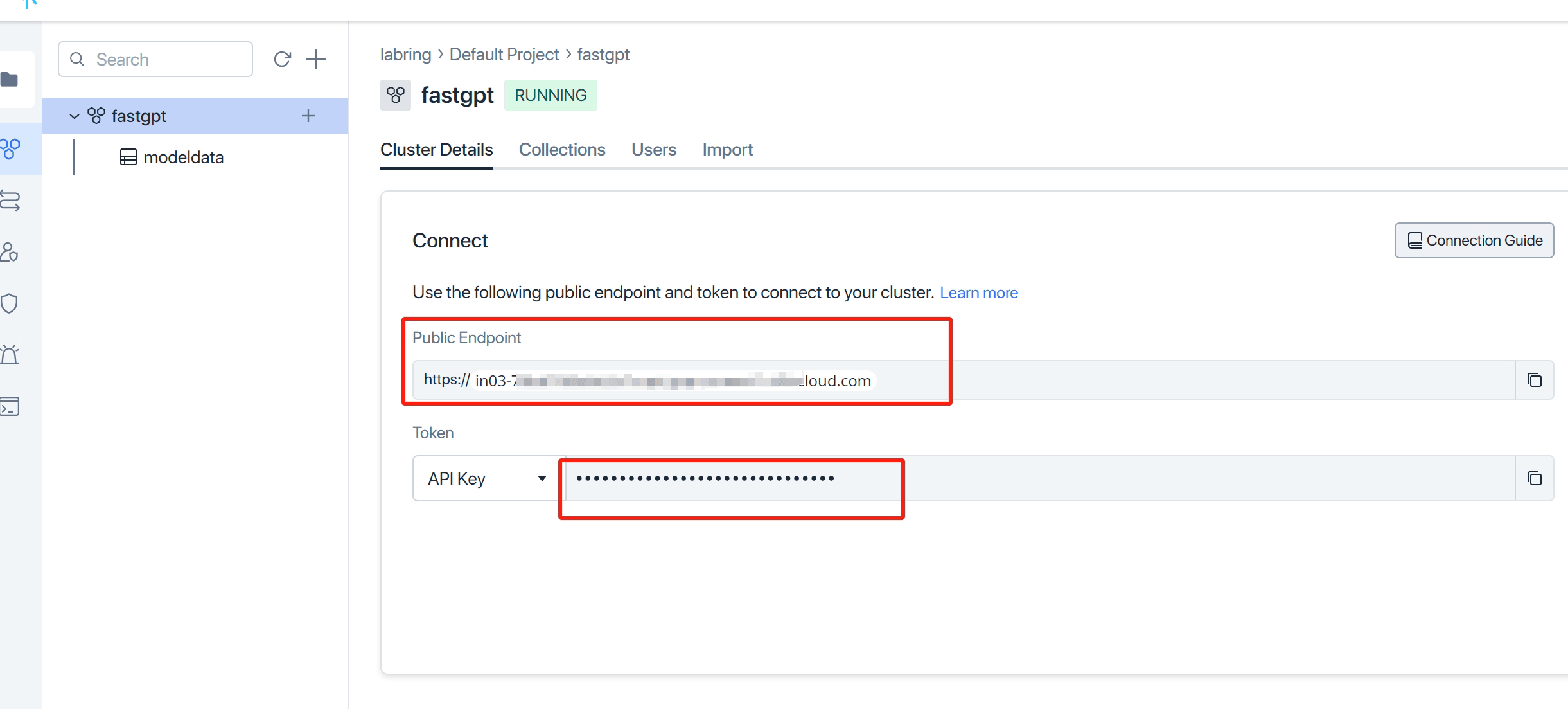
- 修改
MILVUS_ADDRESS和MILVUS_TOKEN链接参数,分别对应zilliz的Public Endpoint和Api key,记得把自己ip加入白名单。
3. 修改 config.json 配置文件
修改config.json文件中的mcpServerProxyEndpoint值,设置成mcp server的公网可访问地址,yml 文件中默认给出了映射到 3005 端口,如通过 IP 访问,则可能是:120.172.2.10:3005。
4. 启动容器
在 docker-compose.yml 同级目录下执行。请确保docker-compose版本最好在2.17以上,否则可能无法执行自动化命令。
+
2. 修改环境变量
找到 yml 文件中,fastgpt 容器的环境变量进行下面操作:
打开 Zilliz Cloud, 创建实例并获取相关秘钥。
- 修改
MILVUS_ADDRESS和MILVUS_TOKEN链接参数,分别对应zilliz的Public Endpoint和Api key,记得把自己ip加入白名单。
3. 修改 config.json 配置文件
修改config.json文件中的mcpServerProxyEndpoint值,设置成mcp server的公网可访问地址,yml 文件中默认给出了映射到 3005 端口,如通过 IP 访问,则可能是:120.172.2.10:3005。
4. 启动容器
在 docker-compose.yml 同级目录下执行。请确保docker-compose版本最好在2.17以上,否则可能无法执行自动化命令。
# 启动容器
docker-compose up -d
5. 访问 FastGPT
目前可以通过 ip:3000 直接访问(注意开放防火墙)。登录用户名为 root,密码为docker-compose.yml环境变量里设置的 DEFAULT_ROOT_PSW。
如果需要域名访问,请自行安装并配置 Nginx。
首次运行,会自动初始化 root 用户,密码为 1234(与环境变量中的DEFAULT_ROOT_PSW一致),日志可能会提示一次MongoServerError: Unable to read from a snapshot due to pending collection catalog changes;可忽略。
6. 配置模型
- 首次登录FastGPT后,系统会提示未配置
语言模型和索引模型,并自动跳转模型配置页面。系统必须至少有这两类模型才能正常使用。 - 如果系统未正常跳转,可以在
账号-模型提供商页面,进行模型配置。点击查看相关教程 - 目前已知可能问题:首次进入系统后,整个浏览器 tab 无法响应。此时需要删除该tab,重新打开一次即可。
FAQ
登录系统后,浏览器无法响应
无法点击任何内容,刷新也无效。此时需要删除该tab,重新打开一次即可。
Mongo 副本集自动初始化失败
最新的 docker-compose 示例优化 Mongo 副本集初始化,实现了全自动。目前在 unbuntu20,22 centos7, wsl2, mac, window 均通过测试。仍无法正常启动,大部分是因为 cpu 不支持 AVX 指令集,可以切换 Mongo4.x 版本。
如果是由于,无法自动初始化副本集合,可以手动初始化副本集:
- 终端中执行下面命令,创建mongo密钥:
diff --git a/docs/development/faq/index.html b/docs/development/faq/index.html index a2f55bde0..005a2100e 100644 --- a/docs/development/faq/index.html +++ b/docs/development/faq/index.html @@ -36,11 +36,11 @@ FAQ
私有部署常见问题
FastGPT 私有部署常见问题
一、错误排查方式
可以先找找Issue,或新提 Issue,私有部署错误,务必提供详细的操作步骤、日志、截图,否则很难排查。
获取后端错误
docker ps -a查看所有容器运行状态,检查是否全部 running,如有异常,尝试docker logs 容器名查看对应日志。- 容器都运行正常的,
docker logs 容器名查看报错日志
前端错误
前端报错时,页面会出现崩溃,并提示检查控制台日志。可以打开浏览器控制台,并查看console中的 log 日志。还可以点击对应 log 的超链接,会提示到具体错误文件,可以把这些详细错误信息提供,方便排查。
OneAPI 错误
带有requestId的,都是 OneAPI 提示错误,大部分都是因为模型接口报错。可以参考 OneAPI 常见错误
二、通用问题
前端页面崩溃
- 90% 情况是模型配置不正确:确保每类模型都至少有一个启用;检查模型中一些
对象参数是否异常(数组和对象),如果为空,可以尝试给个空数组或空对象。 - 少部分是由于浏览器兼容问题,由于项目中包含一些高阶语法,可能低版本浏览器不兼容,可以将具体操作步骤和控制台中错误信息提供 issue。
- 关闭浏览器翻译功能,如果浏览器开启了翻译,可能会导致页面崩溃。
通过sealos部署的话,是否没有本地部署的一些限制?
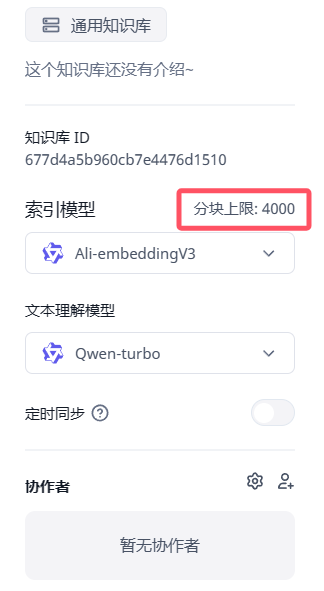 这是索引模型的长度限制,通过任何方式部署都一样的,但不同索引模型的配置不一样,可以在后台修改参数。
这是索引模型的长度限制,通过任何方式部署都一样的,但不同索引模型的配置不一样,可以在后台修改参数。
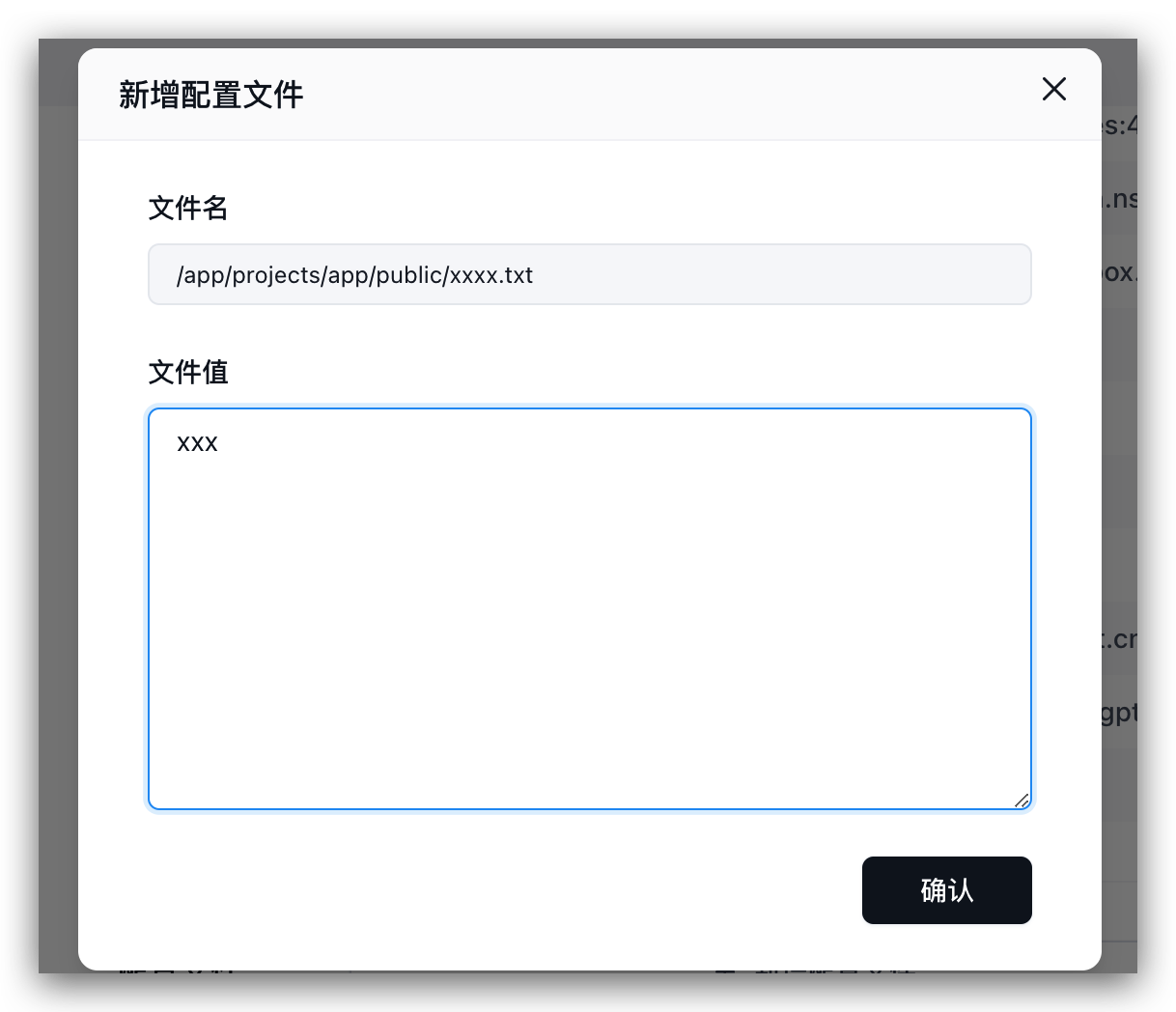
怎么挂载小程序配置文件
将验证文件,挂载到指定位置:/app/projects/app/public/xxxx.txt
然后重启。例如:
数据库3306端口被占用了,启动服务失败
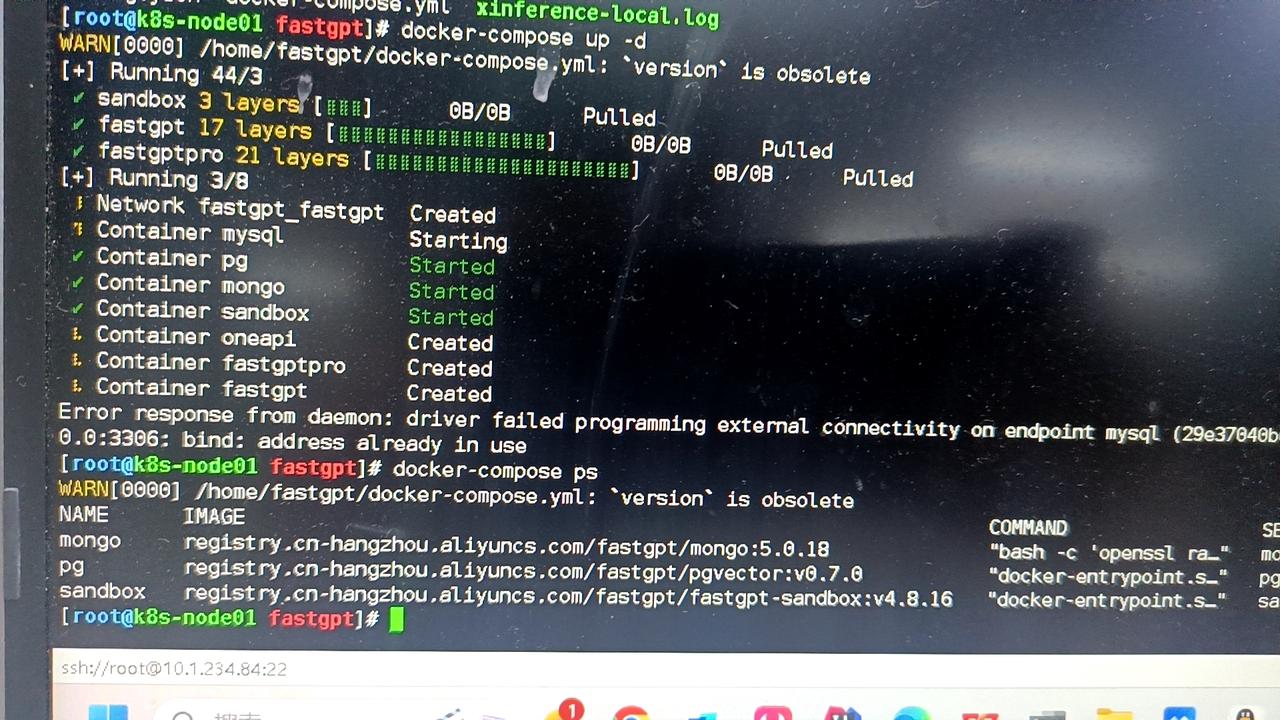
把端口映射改成 3307 之类的,例如 3307:3306。
本地部署的限制
具体内容参考https://fael3z0zfze.feishu.cn/wiki/OFpAw8XzAi36Guk8dfucrCKUnjg。
能否纯本地运行
可以。需要准备好向量模型和LLM模型。
其他模型没法进行问题分类/内容提取
- 看日志。如果提示 JSON invalid,not support tool 之类的,说明该模型不支持工具调用或函数调用,需要设置
toolChoice=false和functionCall=false,就会默认走提示词模式。目前内置提示词仅针对了商业模型API进行测试。问题分类基本可用,内容提取不太行。 - 如果已经配置正常,并且没有错误日志,则说明可能提示词不太适合该模型,可以通过修改
customCQPrompt来自定义提示词。
页面崩溃
- 关闭翻译
- 检查配置文件是否正常加载,如果没有正常加载会导致缺失系统信息,在某些操作下会导致空指针。
- 95%情况是配置文件不对。会提示 xxx undefined
- 提示
URI malformed,请 Issue 反馈具体操作和页面,这是由于特殊字符串编码解析报错。
- 某些api不兼容问题(较少)
开启内容补全后,响应速度变慢
- 问题补全需要经过一轮AI生成。
- 会进行3~5轮的查询,如果数据库性能不足,会有明显影响。
页面中可以正常回复,API 报错
页面中是用 stream=true 模式,所以API也需要设置 stream=true 来进行测试。部分模型接口(国产居多)非 Stream 的兼容有点垃圾。 -和上一个问题一样,curl 测试。
知识库索引没有进度/索引很慢
先看日志报错信息。有以下几种情况:
- 可以对话,但是索引没有进度:没有配置向量模型(vectorModels)
- 不能对话,也不能索引:API调用失败。可能是没连上OneAPI或OpenAI
- 有进度,但是非常慢:api key不行,OpenAI的免费号,一分钟只有3次还是60次。一天上限200次。
Connection error
网络异常。国内服务器无法请求OpenAI,自行检查与AI模型的连接是否正常。
或者是FastGPT请求不到 OneAPI(没放同一个网络)
修改了 vectorModels 但是没有生效
- 重启容器,确保模型配置已经加载(可以在日志或者新建知识库时候看到新模型)
- 记得刷新一次浏览器。
- 如果是已经创建的知识库,需要删除重建。向量模型是创建时候绑定的,不会动态更新。
三、常见的 OneAPI 错误
带有 requestId 的都是 OneAPI 的报错。
insufficient_user_quota user quota is not enough
OneAPI 账号的余额不足,默认 root 用户只有 200 刀,可以手动修改。
路径:打开OneAPI -> 用户 -> root用户右边的编辑 -> 剩余余额调大
xxx渠道找不到
FastGPT 模型配置文件中的 model 必须与 OneAPI 渠道中的模型对应上,否则就会提示这个错误。可检查下面内容:
- OneAPI 中没有配置该模型渠道,或者被禁用了。
- FastGPT 配置文件有 OneAPI 没有配置的模型。如果 OneAPI 没有配置对应模型的,配置文件中也不要写。
- 使用旧的向量模型创建了知识库,后又更新了向量模型。这时候需要删除以前的知识库,重建。
如果OneAPI中,没有配置对应的模型,config.json中也不要配置,否则容易报错。
点击模型测试失败
OneAPI 只会测试渠道的第一个模型,并且只会测试对话模型,向量模型无法自动测试,需要手动发起请求进行测试。查看测试模型命令示例
get request url failed: Post “https://xxx dial tcp: xxxx
OneAPI 与模型网络不通,需要检查网络配置。
Incorrect API key provided: sk-xxxx.You can find your api Key at xxx
OneAPI 的 API Key 配置错误,需要修改OPENAI_API_KEY环境变量,并重启容器(先 docker-compose down 然后再 docker-compose up -d 运行一次)。
可以exec进入容器,env查看环境变量是否生效。
bad_response_status_code bad response status code 503
- 模型服务不可用
- 模型接口参数异常(温度、max token等可能不适配)
- ….
Tiktoken 下载失败
由于 OneAPI 会在启动时从网络下载一个 tiktoken 的依赖,如果网络异常,就会导致启动失败。可以参考OneAPI 离线部署解决。
四、常见模型问题
如何检查模型可用性问题
- 私有部署模型,先确认部署的模型是否正常。
- 通过 CURL 请求,直接测试上游模型是否正常运行(云端模型或私有模型均进行测试)
- 通过 CURL 请求,请求 OneAPI 去测试模型是否正常。
- 在 FastGPT 中使用该模型进行测试。
下面是几个测试 CURL 示例:
+和上一个问题一样,curl 测试。知识库索引没有进度/索引很慢
先看日志报错信息。有以下几种情况:
- 可以对话,但是索引没有进度:没有配置向量模型(vectorModels)
- 不能对话,也不能索引:API调用失败。可能是没连上OneAPI或OpenAI
- 有进度,但是非常慢:api key不行,OpenAI的免费号,一分钟只有3次还是60次。一天上限200次。
Connection error
网络异常。国内服务器无法请求OpenAI,自行检查与AI模型的连接是否正常。
或者是FastGPT请求不到 OneAPI(没放同一个网络)
修改了 vectorModels 但是没有生效
- 重启容器,确保模型配置已经加载(可以在日志或者新建知识库时候看到新模型)
- 记得刷新一次浏览器。
- 如果是已经创建的知识库,需要删除重建。向量模型是创建时候绑定的,不会动态更新。
三、常见的 OneAPI 错误
带有 requestId 的都是 OneAPI 的报错。
insufficient_user_quota user quota is not enough
OneAPI 账号的余额不足,默认 root 用户只有 200 刀,可以手动修改。
路径:打开OneAPI -> 用户 -> root用户右边的编辑 -> 剩余余额调大
xxx渠道找不到
FastGPT 模型配置文件中的 model 必须与 OneAPI 渠道中的模型对应上,否则就会提示这个错误。可检查下面内容:
- OneAPI 中没有配置该模型渠道,或者被禁用了。
- FastGPT 配置文件有 OneAPI 没有配置的模型。如果 OneAPI 没有配置对应模型的,配置文件中也不要写。
- 使用旧的向量模型创建了知识库,后又更新了向量模型。这时候需要删除以前的知识库,重建。
如果OneAPI中,没有配置对应的模型,
config.json中也不要配置,否则容易报错。点击模型测试失败
OneAPI 只会测试渠道的第一个模型,并且只会测试对话模型,向量模型无法自动测试,需要手动发起请求进行测试。查看测试模型命令示例
get request url failed: Post “https://xxx dial tcp: xxxx
OneAPI 与模型网络不通,需要检查网络配置。
Incorrect API key provided: sk-xxxx.You can find your api Key at xxx
OneAPI 的 API Key 配置错误,需要修改
OPENAI_API_KEY环境变量,并重启容器(先 docker-compose down 然后再 docker-compose up -d 运行一次)。可以
exec进入容器,env查看环境变量是否生效。bad_response_status_code bad response status code 503
- 模型服务不可用
- 模型接口参数异常(温度、max token等可能不适配)
- ….
Tiktoken 下载失败
由于 OneAPI 会在启动时从网络下载一个 tiktoken 的依赖,如果网络异常,就会导致启动失败。可以参考OneAPI 离线部署解决。
四、常见模型问题
如何检查模型可用性问题
- 私有部署模型,先确认部署的模型是否正常。
- 通过 CURL 请求,直接测试上游模型是否正常运行(云端模型或私有模型均进行测试)
- 通过 CURL 请求,请求 OneAPI 去测试模型是否正常。
- 在 FastGPT 中使用该模型进行测试。
下面是几个测试 CURL 示例:
curl https://api.openai.com/v1/chat/completions \ -H "Content-Type: application/json" \ -H "Authorization: Bearer $OPENAI_API_KEY" \ @@ -57,7 +57,7 @@ Table of Contents+curl https://api.openai.com/v1/embeddings \ -H "Authorization: Bearer $OPENAI_API_KEY" \ -H "Content-Type: application/json" \ @@ -66,7 +66,7 @@ Table of Contents+curl --location --request POST 'https://xxxx.com/api/v1/rerank' \ --header 'Authorization: Bearer {{ACCESS_TOKEN}}' \ --header 'Content-Type: application/json' \ @@ -77,7 +77,7 @@ Table of Contents+curl https://api.openai.com/v1/audio/speech \ -H "Authorization: Bearer $OPENAI_API_KEY" \ -H "Content-Type: application/json" \ @@ -87,7 +87,7 @@ Table of Contents+curl https://api.openai.com/v1/audio/transcriptions \ -H "Authorization: Bearer $OPENAI_API_KEY" \ -H "Content-Type: multipart/form-data" \ diff --git a/docs/development/openapi/chat/index.html b/docs/development/openapi/chat/index.html index ff441ebd9..21207bff2 100644 --- a/docs/development/openapi/chat/index.html +++ b/docs/development/openapi/chat/index.html @@ -34,9 +34,9 @@ FAQ对话接口
FastGPT OpenAPI 对话接口
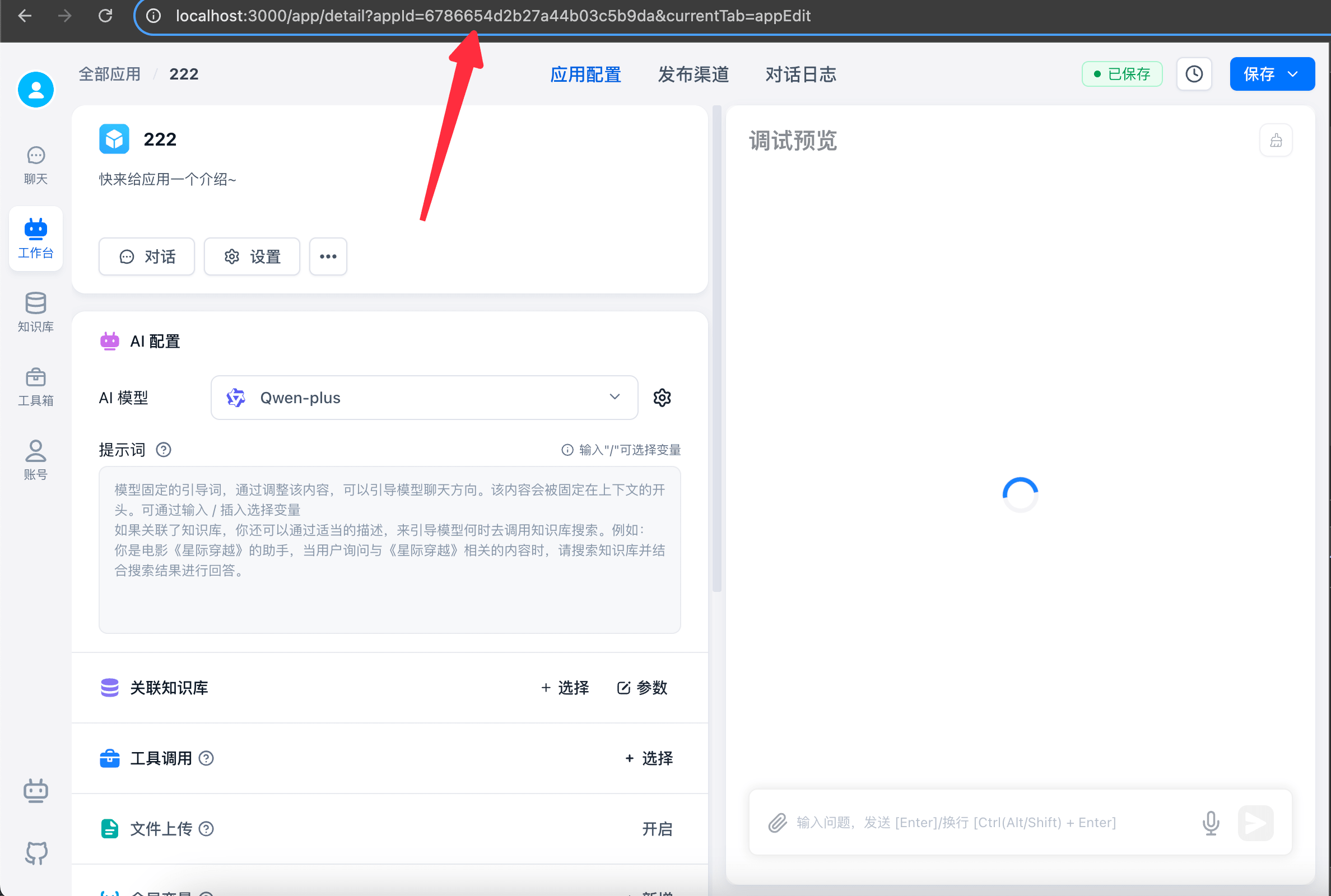
如何获取 AppId
可在应用详情的路径里获取 AppId。
发起对话
- 该接口的 API Key 需使用
应用特定的 key,否则会报错。
有些包调用时,
BaseUrl需要添加v1路径,有些不需要,如果出现404情况,可补充v1重试。请求简易应用和工作流
v1对话接口兼容GPT的接口!如果你的项目使用的是标准的GPT官方接口,可以直接通过修改BaseUrl和Authorization来访问 FastGpt 应用,不过需要注意下面几个规则:
传入的
model,temperature等参数字段均无效,这些字段由编排决定,不会根据 API 参数改变。不会返回实际消耗
Token值,如果需要,可以设置detail=true,并手动计算responseData里的tokens值。请求
+Table of Contentschat对话接口
FastGPT OpenAPI 对话接口
如何获取 AppId
可在应用详情的路径里获取 AppId。
发起对话
- 该接口的 API Key 需使用
应用特定的 key,否则会报错。
有些包调用时,
BaseUrl需要添加v1路径,有些不需要,如果出现404情况,可补充v1重试。请求简易应用和工作流
v1对话接口兼容GPT的接口!如果你的项目使用的是标准的GPT官方接口,可以直接通过修改BaseUrl和Authorization来访问 FastGpt 应用,不过需要注意下面几个规则:
传入的
model,temperature等参数字段均无效,这些字段由编排决定,不会根据 API 参数改变。不会返回实际消耗
Token值,如果需要,可以设置detail=true,并手动计算responseData里的tokens值。请求
交互节点响应
如果工作流中包含交互节点,依然是调用该 API 接口,需要设置
detail=true,并可以从event=interactive的数据中获取交互节点的配置信息。如果是stream=false,则可以从 choice 中获取type=interactive的元素,获取交互节点的选择信息。当你调用一个带交互节点的工作流时,如果工作流遇到了交互节点,那么会直接返回,你可以得到下面的信息:
交互节点响应
如果工作流中包含交互节点,依然是调用该 API 接口,需要设置
detail=true,并可以从event=interactive的数据中获取交互节点的配置信息。如果是stream=false,则可以从 choice 中获取type=interactive的元素,获取交互节点的选择信息。当你调用一个带交互节点的工作流时,如果工作流遇到了交互节点,那么会直接返回,你可以得到下面的信息:
交互节点继续运行
紧接着上一节,当你接收到交互节点信息后,可以根据这些数据进行 UI 渲染,引导用户输入或选择相关信息。然后需要再次发起对话,来继续工作流。调用的接口与仍是该接口,你需要按以下格式来发起请求:
交互节点继续运行
紧接着上一节,当你接收到交互节点信息后,可以根据这些数据进行 UI 渲染,引导用户输入或选择相关信息。然后需要再次发起对话,来继续工作流。调用的接口与仍是该接口,你需要按以下格式来发起请求:
对于用户选择,你只需要直接传递一个选择的结果给 messages 即可。
curl --location --request POST 'https://api.fastgpt.in/api/v1/chat/completions' \ --header 'Authorization: Bearer fastgpt-xxx' \ --header 'Content-Type: application/json' \ @@ -311,7 +311,7 @@ data: [{"moduleName":"知识库搜索","moduleType":" } ] }'-表单输入稍微麻烦一点,需要将输入的内容,以对象形式并序列化成字符串,作为
messages的值。对象的 key 对应表单的 key,value 为用户输入的值。务必确保chatId是一致的。+表单输入稍微麻烦一点,需要将输入的内容,以对象形式并序列化成字符串,作为
messages的值。对象的 key 对应表单的 key,value 为用户输入的值。务必确保chatId是一致的。curl --location --request POST 'https://api.fastgpt.in/api/v1/chat/completions' \ --header 'Authorization: Bearer fastgpt-xxxx' \ --header 'Content-Type: application/json' \ @@ -337,9 +337,9 @@ data: [{"moduleName":"知识库搜索","moduleType":" "query":"你好" # 我的插件输入有一个参数,变量名叫 query } }'-响应示例
- 插件的输出可以通过查找
responseData中,moduleType=pluginOutput的元素,其pluginOutput是插件的输出。- 流输出,仍可以通过
choices进行获取。+响应示例
对话 CRUD
以下接口可使用任意
API Key调用。4.8.12 以上版本才能使用
重要字段
- chatId - 指一个应用下,某一个对话窗口的 ID
- dataId - 指一个对话窗口下,某一个对话记录的 ID
历史记录
获取某个应用历史记录
对话 CRUD
以下接口可使用任意
API Key调用。4.8.12 以上版本才能使用
重要字段
- chatId - 指一个应用下,某一个对话窗口的 ID
- dataId - 指一个对话窗口下,某一个对话记录的 ID
历史记录
获取某个应用历史记录
修改某个对话的标题
修改某个对话的标题
置顶 / 取消置顶
置顶 / 取消置顶
删除某个历史记录
删除某个历史记录
清空所有历史记录
仅会情况通过 API Key 创建的对话历史记录,不会清空在线使用、分享链接等其他来源的对话历史记录。
清空所有历史记录
仅会情况通过 API Key 创建的对话历史记录,不会清空在线使用、分享链接等其他来源的对话历史记录。
对话记录
指的是某个 chatId 下的对话记录操作。
获取单个对话初始化信息
对话记录
指的是某个 chatId 下的对话记录操作。
获取单个对话初始化信息
获取对话记录列表
获取对话记录列表
获取单个对话记录运行详情
获取单个对话记录运行详情
删除对话记录
删除对话记录
点赞 / 取消点赞
点赞 / 取消点赞
点踩 / 取消点踩
点踩 / 取消点踩
猜你想问
4.8.16 后新版接口
新版猜你想问,必须包含 appId 和 chatId 的参数才可以进行使用。会自动根据 chatId 去拉取最近 6 轮对话记录作为上下文来引导回答。
猜你想问
4.8.16 后新版接口
新版猜你想问,必须包含 appId 和 chatId 的参数才可以进行使用。会自动根据 chatId 去拉取最近 6 轮对话记录作为上下文来引导回答。
4.8.16 前旧版接口:
4.8.16 前旧版接口:
curl --location --request POST 'http://localhost:3000/api/core/ai/agent/createQuestionGuide' \ --header 'Authorization: Bearer {{apikey}}' \ --header 'Content-Type: application/json' \ @@ -828,7 +828,7 @@ data: [{"nodeId":"fdDgXQ6SYn8v","moduleName":"AI 对 } ] }'-
- messages - 对话消息,提供给 AI 的消息记录
+
- messages - 对话消息,提供给 AI 的消息记录
知识库接口
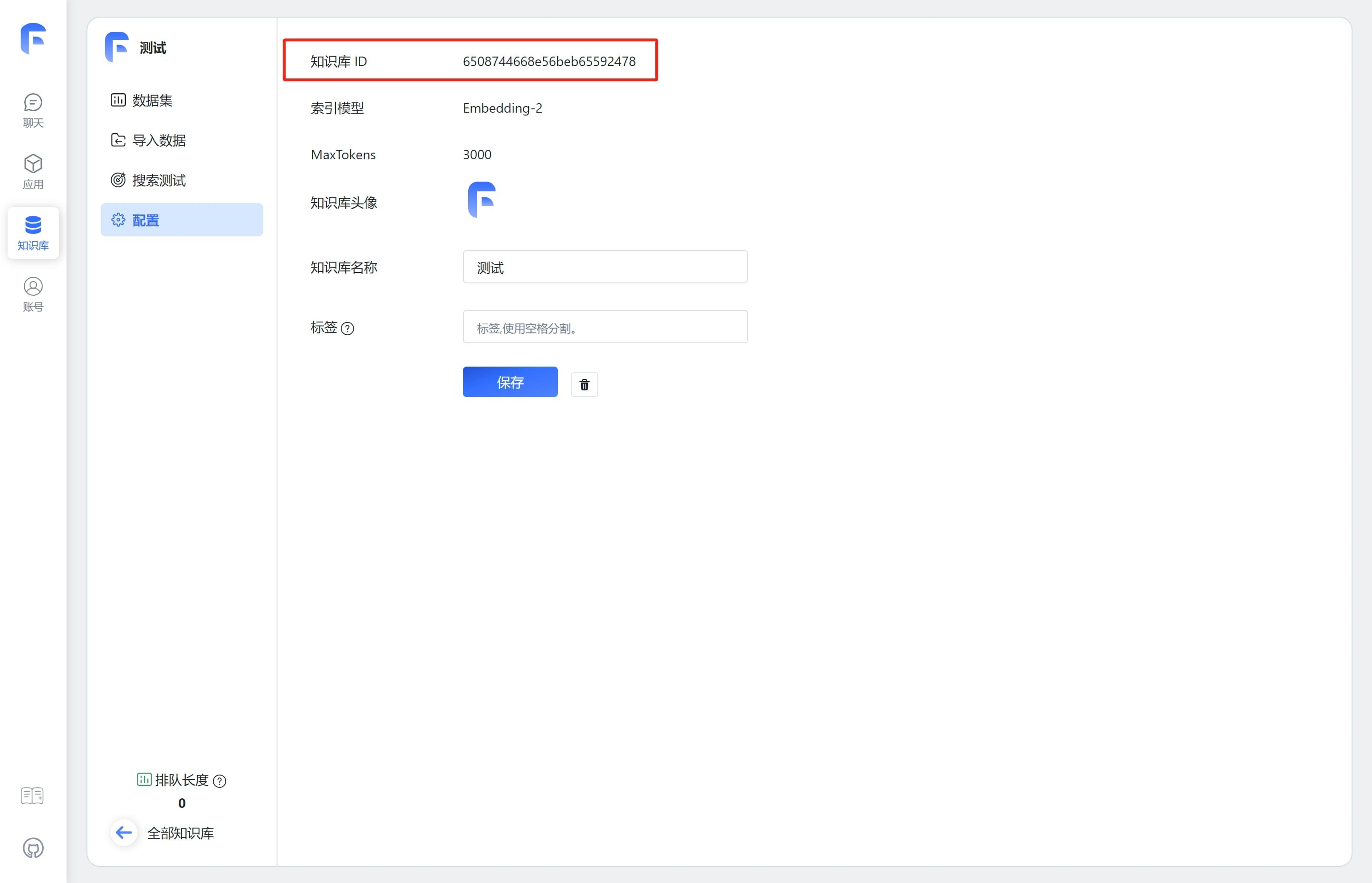
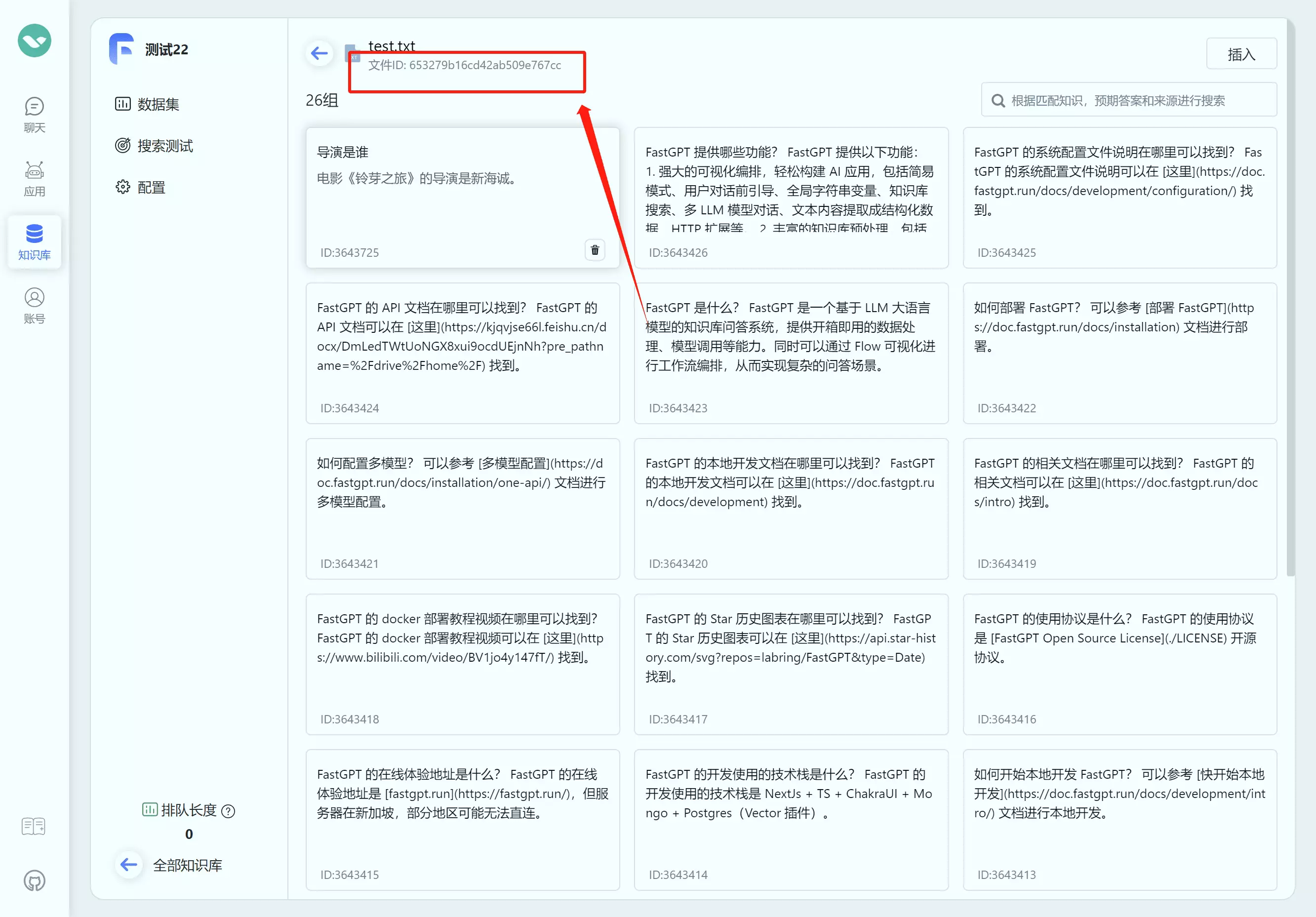
FastGPT OpenAPI 知识库接口
如何获取知识库ID(datasetId) 如何获取文件集合ID(collection_id) 创建训练订单
新例子
+Table of Contentsdataset知识库接口
FastGPT OpenAPI 知识库接口
如何获取知识库ID(datasetId) 如何获取文件集合ID(collection_id) 创建训练订单
知识库
创建一个知识库
知识库
创建一个知识库
获取知识库列表
获取知识库列表
获取知识库详情
获取知识库详情
删除一个知识库
删除一个知识库
集合
通用创建参数说明(必看)
入参
参数 说明 必填 datasetId 知识库ID ✅ parentId: 父级ID,不填则默认为根目录 trainingType 数据处理方式。chunk: 按文本长度进行分割;qa: 问答对提取 ✅ autoIndexes 是否自动生成索引(仅商业版支持) imageIndex 是否自动生成图片索引(仅商业版支持) chunkSettingMode 分块参数模式。auto: 系统默认参数; custom: 手动指定参数 chunkSplitMode 分块拆分模式。size: 按长度拆分; char: 按字符拆分。chunkSettingMode=auto时不生效。 chunkSize 分块大小,默认 1500。chunkSettingMode=auto时不生效。 indexSize 索引大小,默认 512,必须小于索引模型最大token。chunkSettingMode=auto时不生效。 chunkSplitter 自定义最高优先分割符号,除非超出文件处理最大上下文,否则不会进行进一步拆分。chunkSettingMode=auto时不生效。 qaPrompt qa拆分提示词 tags 集合标签(字符串数组) createTime 文件创建时间(Date / String) 出参
- collectionId - 新建的集合ID
- insertLen:插入的块数量
创建一个空的集合
集合
通用创建参数说明(必看)
入参
参数 说明 必填 datasetId 知识库ID ✅ parentId: 父级ID,不填则默认为根目录 trainingType 数据处理方式。chunk: 按文本长度进行分割;qa: 问答对提取 ✅ autoIndexes 是否自动生成索引(仅商业版支持) imageIndex 是否自动生成图片索引(仅商业版支持) chunkSettingMode 分块参数模式。auto: 系统默认参数; custom: 手动指定参数 chunkSplitMode 分块拆分模式。size: 按长度拆分; char: 按字符拆分。chunkSettingMode=auto时不生效。 chunkSize 分块大小,默认 1500。chunkSettingMode=auto时不生效。 indexSize 索引大小,默认 512,必须小于索引模型最大token。chunkSettingMode=auto时不生效。 chunkSplitter 自定义最高优先分割符号,除非超出文件处理最大上下文,否则不会进行进一步拆分。chunkSettingMode=auto时不生效。 qaPrompt qa拆分提示词 tags 集合标签(字符串数组) createTime 文件创建时间(Date / String) 出参
- collectionId - 新建的集合ID
- insertLen:插入的块数量
创建一个空的集合
创建一个纯文本集合
传入一段文字,创建一个集合,会根据传入的文字进行分割。
创建一个纯文本集合
传入一段文字,创建一个集合,会根据传入的文字进行分割。
创建一个链接集合
传入一个网络链接,创建一个集合,会先去对应网页抓取内容,再抓取的文字进行分割。
创建一个链接集合
传入一个网络链接,创建一个集合,会先去对应网页抓取内容,再抓取的文字进行分割。
创建一个文件集合
传入一个文件,创建一个集合,会读取文件内容进行分割。目前支持:pdf, docx, md, txt, html, csv。
创建一个文件集合
传入一个文件,创建一个集合,会读取文件内容进行分割。目前支持:pdf, docx, md, txt, html, csv。
创建一个API集合
传入一个文件的 id,创建一个集合,会读取文件内容进行分割。目前支持:pdf, docx, md, txt, html, csv。
创建一个API集合
传入一个文件的 id,创建一个集合,会读取文件内容进行分割。目前支持:pdf, docx, md, txt, html, csv。
创建一个外部文件库集合(商业版)
创建一个外部文件库集合(商业版)
获取集合列表
获取集合列表
获取集合详情
获取集合详情
修改集合信息
修改集合信息
删除一个集合
删除一个集合
数据
数据的结构
Data结构
字段 类型 说明 必填 teamId String 团队ID ✅ tmbId String 成员ID ✅ datasetId String 知识库ID ✅ collectionId String 集合ID ✅ q String 主要数据 ✅ a String 辅助数据 ✖ fullTextToken String 分词 ✖ indexes Index[] 向量索引 ✅ updateTime Date 更新时间 ✅ chunkIndex Number 分块下表 ✖ Index结构
每组数据的自定义索引最多5个
字段 类型 说明 必填 type String 可选索引类型:default-默认索引; custom-自定义索引; summary-总结索引; question-问题索引; image-图片索引 dataId String 关联的向量ID,变更数据时候传入该 ID,会进行差量更新,而不是全量更新 text String 文本内容 ✅
type不填则默认为custom索引,还会基于 q/a 组成一个默认索引。如果传入了默认索引,则不会额外创建。为集合批量添加添加数据
注意,每次最多推送 200 组数据。
数据
数据的结构
Data结构
字段 类型 说明 必填 teamId String 团队ID ✅ tmbId String 成员ID ✅ datasetId String 知识库ID ✅ collectionId String 集合ID ✅ q String 主要数据 ✅ a String 辅助数据 ✖ fullTextToken String 分词 ✖ indexes Index[] 向量索引 ✅ updateTime Date 更新时间 ✅ chunkIndex Number 分块下表 ✖ Index结构
每组数据的自定义索引最多5个
字段 类型 说明 必填 type String 可选索引类型:default-默认索引; custom-自定义索引; summary-总结索引; question-问题索引; image-图片索引 dataId String 关联的向量ID,变更数据时候传入该 ID,会进行差量更新,而不是全量更新 text String 文本内容 ✅
type不填则默认为custom索引,还会基于 q/a 组成一个默认索引。如果传入了默认索引,则不会额外创建。为集合批量添加添加数据
注意,每次最多推送 200 组数据。
获取集合的数据列表
获取集合的数据列表
获取单条数据详情
获取单条数据详情
修改单条数据
修改单条数据
删除单条数据
删除单条数据
搜索测试
搜索测试
curl --location --request POST 'https://api.fastgpt.in/api/core/dataset/searchTest' \ --header 'Authorization: Bearer fastgpt-xxxxx' \ --header 'Content-Type: application/json' \ @@ -715,7 +715,7 @@ A2: "datasetSearchExtensionModel": "gpt-4o-mini", "datasetSearchExtensionBg": "" }'-
- datasetId - 知识库ID
- text - 需要测试的文本
- limit - 最大 tokens 数量
- similarity - 最低相关度(0~1,可选)
- searchMode - 搜索模式:embedding | fullTextRecall | mixedRecall
- usingReRank - 使用重排
- datasetSearchUsingExtensionQuery - 使用问题优化
- datasetSearchExtensionModel - 问题优化模型
- datasetSearchExtensionBg - 问题优化背景描述
返回 top k 结果, limit 为最大 Tokens 数量,最多 20000 tokens。
+
- datasetId - 知识库ID
- text - 需要测试的文本
- limit - 最大 tokens 数量
- similarity - 最低相关度(0~1,可选)
- searchMode - 搜索模式:embedding | fullTextRecall | mixedRecall
- usingReRank - 使用重排
- datasetSearchUsingExtensionQuery - 使用问题优化
- datasetSearchExtensionModel - 问题优化模型
- datasetSearchExtensionBg - 问题优化背景描述
返回 top k 结果, limit 为最大 Tokens 数量,最多 20000 tokens。
{ "code": 200, "statusText": "", diff --git a/docs/development/openapi/share/index.html b/docs/development/openapi/share/index.html index 73f0af1c5..104380003 100644 --- a/docs/development/openapi/share/index.html +++ b/docs/development/openapi/share/index.html @@ -43,43 +43,43 @@ Table of Contents
FastGPT将会判断success是否为true决定是允许用户继续操作。message与msg是等同的,你可以选择返回其中一个,当success不为true时,将会提示这个错误。
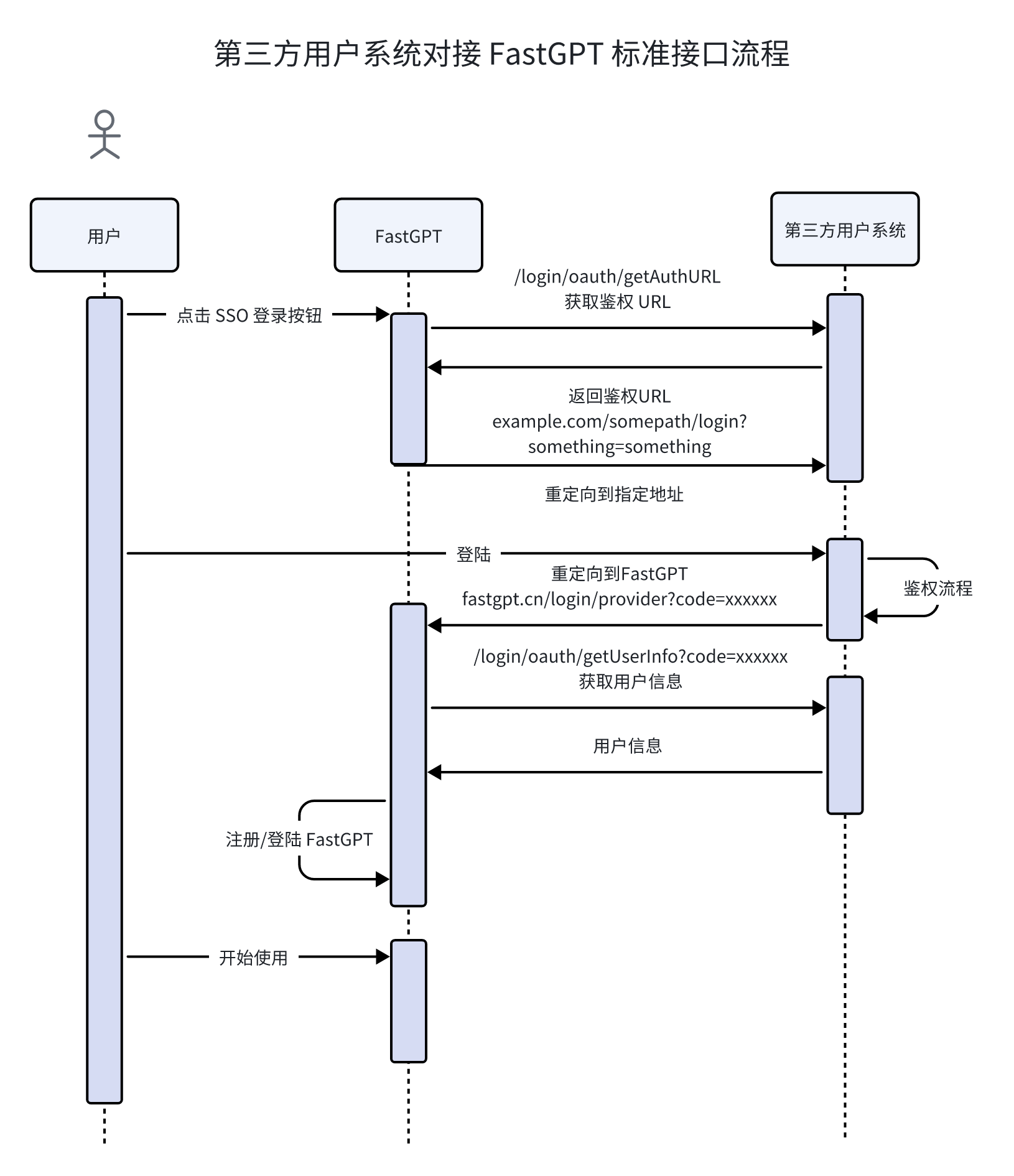
uid是用户的唯一凭证,将会用于拉取对话记录以及保存对话记录。可参考下方实践案例。触发流程
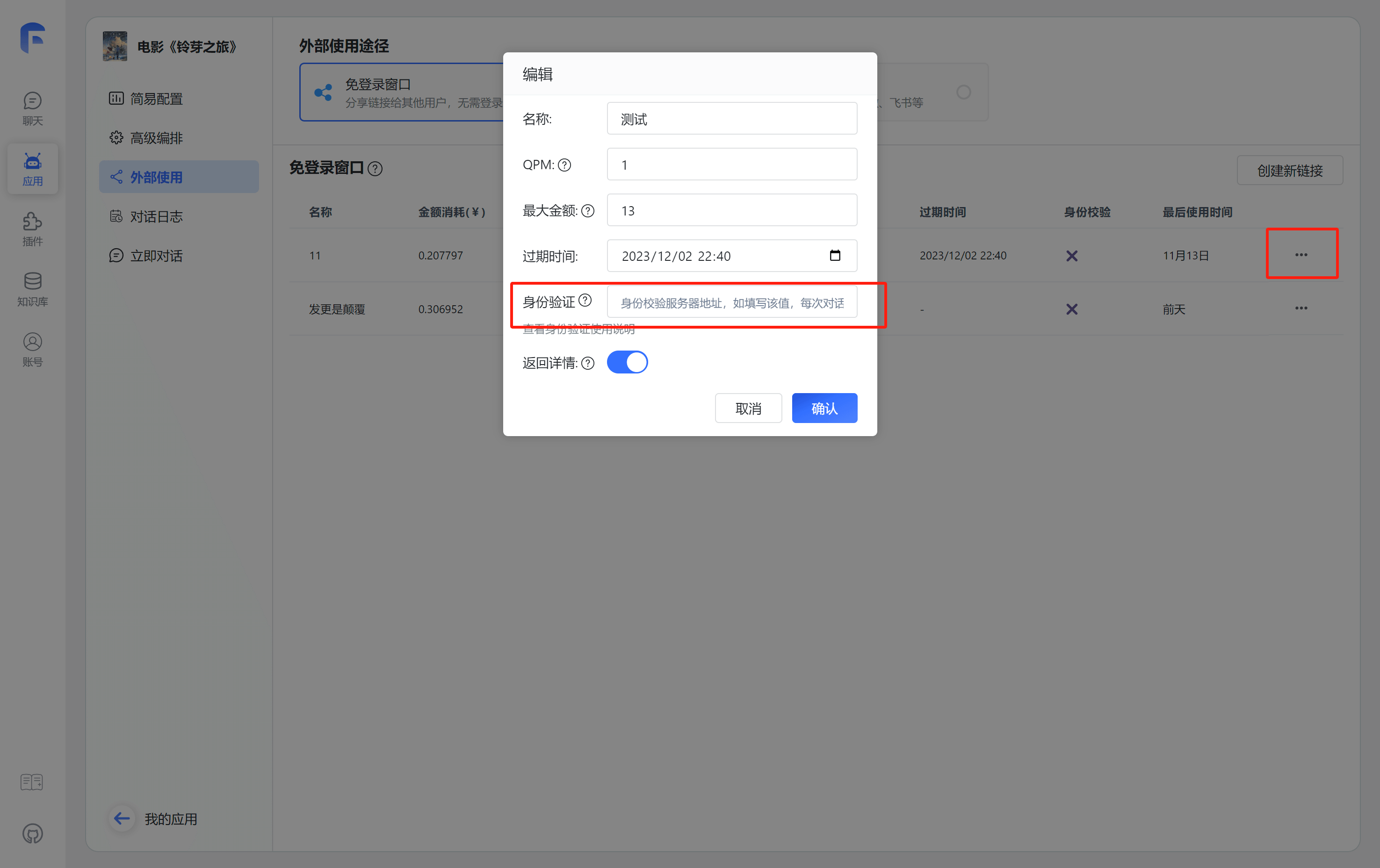
配置教程
1. 配置身份校验地址
配置校验地址后,在每次分享链接使用时,都会向对应的地址发起校验和上报请求。
这里仅需配置根地址,无需具体到完整请求路径。
2. 分享链接中增加额外 query
在分享链接的地址中,增加一个额外的参数: authToken。例如:
原始的链接:
https://share.tryfastgpt.ai/chat/share?shareId=648aaf5ae121349a16d62192完整链接:
https://share.tryfastgpt.ai/chat/share?shareId=648aaf5ae121349a16d62192&authToken=userid12345这个
authToken通常是你系统生成的用户唯一凭证(Token之类的)。FastGPT 会在鉴权接口的body中携带 token={{authToken}} 的参数。3. 编写聊天初始化校验接口
+
FastGPT将会判断success是否为true决定是允许用户继续操作。message与msg是等同的,你可以选择返回其中一个,当success不为true时,将会提示这个错误。
uid是用户的唯一凭证,将会用于拉取对话记录以及保存对话记录。可参考下方实践案例。触发流程
配置教程
1. 配置身份校验地址
配置校验地址后,在每次分享链接使用时,都会向对应的地址发起校验和上报请求。
这里仅需配置根地址,无需具体到完整请求路径。
2. 分享链接中增加额外 query
在分享链接的地址中,增加一个额外的参数: authToken。例如:
原始的链接:
https://share.tryfastgpt.ai/chat/share?shareId=648aaf5ae121349a16d62192完整链接:
https://share.tryfastgpt.ai/chat/share?shareId=648aaf5ae121349a16d62192&authToken=userid12345这个
authToken通常是你系统生成的用户唯一凭证(Token之类的)。FastGPT 会在鉴权接口的body中携带 token={{authToken}} 的参数。3. 编写聊天初始化校验接口
4. 编写对话前校验接口
4. 编写对话前校验接口
curl --location --request POST '{{host}}/shareAuth/start' \ --header 'Content-Type: application/json' \ --data-raw '{ "token": "{{authToken}}", "question": "用户问题", }'-+{ "success": true, "data": { "uid": "用户唯一凭证" } }-+{ "success": false, "message": "身份验证失败", @@ -202,9 +202,9 @@ Table of Contents实践案例
我们以Laf作为服务器为例,简单展示这 3 个接口的使用方式。
1. 创建3个Laf接口
diff --git a/docs/development/upgrading/index.xml b/docs/development/upgrading/index.xml index 393f8d32c..590a0e73b 100644 --- a/docs/development/upgrading/index.xml +++ b/docs/development/upgrading/index.xml @@ -9,7 +9,7 @@ docker-compose pull docker-compose up -d 执行升级初始化脚本 link镜像 QA link为什么需要执行升级脚本 link数据表出现大幅度变更,无法通过设置默认值,或复杂度较高时,会通过升级脚本来更新部分数据表字段。 严格按初始化步骤进行操作,不会造成旧数据丢失。但在初始化过程中,如果数据量大,需要初始化的时间较长,这段时间可能会造成服务无法正常使用。 {{host}} 是什么 link{{}} 代表变量, {{host}}代表一个名为 host 的变量。指的是你服务器的域名或 IP。 Sealos 中,你可以在下图中找到你的域名: -如何获取 rootkey link从docker-compose.yml中的environment中获取,对应的是ROOT_KEY的值。V4.9.7(进行中) https://doc.tryfastgpt.ai/docs/development/upgrading/497/Mon, 01 Jan 0001 00:00:00 +0000 https://doc.tryfastgpt.ai/docs/development/upgrading/497/ 🚀 新增内容 link MCP 工具支持 HTTP Streamable 协议。 MCP server 支持编辑工具名,适配部分客户端不支持中文名问题。 工作流右键可自动对齐节点。 支持生产环境自定义config.json路径。 API 调用,支持传递一个特殊 chatId(NO_RECORD_HISTORIES),使得系统不会进行历史记录存储。 支持 Rerank 模型按量计费。 套餐兑换码功能 支付宝支付 ⚙️ 优化 link Doc2x 文档解析,增加报错信息捕获,增加超时时长。 调整 PG vector 查询语句,强制使用向量索引。 对话时间统计,准确返回工作流整体运行时间。 从 ai_proxy 获取音频解析时长。 🐛 修复 link 文件上传分块大小限制,避免超出 MongoDB 限制。 使用记录仪表盘,无法获取指定成员的使用统计。 仪表盘接口,因未考虑时区问题,统计异常。 LLM 模型测试接口,无法测试未启用的 LLM。同时修复,模型测试接口会把模型自定义请求地址去除问题。 Copy app 权限问题。 导出对话记录,限制单条对话记录消息上限 1000 组,避免导出失败。 工作流变量下一段文本仍是工作流变量,不触发渲染。 调试知识库检索模块,提示无权操作知识库。 文本内容提取节点,默认值赋值逻辑。 分享链接中,会强制返回嵌套应用中的引用内容。 V4.9.6 https://doc.tryfastgpt.ai/docs/development/upgrading/496/Mon, 01 Jan 0001 00:00:00 +0000 https://doc.tryfastgpt.ai/docs/development/upgrading/496/ 🚀 新增内容 link 以 MCP 方式对外提供应用调用。 支持以 MCP SSE 协议创建工具。 批量执行节点支持交互节点,可实现每一轮循环都人工参与。 增加工作台二级菜单,合并工具箱。 增加 grok3、GPT4.1、o系列、Gemini2.5 模型系统配置。 ⚙️ 优化 link 工作流数据类型转化鲁棒性和兼容性增强。 Python sandbox 代码,支持大数据输入。 路径组件支持配置最后一步是否可点击。 知识库工具调用结果,自动补充图片域名。 Github action runner 升级成 unbuntu24 去除飞书、公众号等三方渠道,回复时,可能前后多一个换行的问题。 调整分块策略,大表格时,不进行超大块合并,而是独立拆块。 Iframe 嵌套组件,内置允许麦克风声明。 🐛 修复 link 修复子工作流包含交互节点时,未成功恢复子工作流所有数据。 completion v1 接口,未接受 interactive 参数,导致 API 调用失败。 连续工具调用,上下文截断异常 升级指南 link1. 做好数据备份 link2. 部署 MCP server 服务 linkDocker 部署 link在docker-compose.yml文件中,加入fastgpt-mcp-server服务: +如何获取 rootkey link从docker-compose.yml中的environment中获取,对应的是ROOT_KEY的值。 V4.9.7(进行中) https://doc.tryfastgpt.ai/docs/development/upgrading/497/Mon, 01 Jan 0001 00:00:00 +0000 https://doc.tryfastgpt.ai/docs/development/upgrading/497/ 🚀 新增内容 link MCP 工具支持 HTTP Streamable 协议。 MCP server 支持编辑工具名,适配部分客户端不支持中文名问题。 工作流右键可自动对齐节点。 支持生产环境自定义config.json路径。 API 调用,支持传递一个特殊 chatId(NO_RECORD_HISTORIES),使得系统不会进行历史记录存储。 支持 Rerank 模型按量计费。 套餐兑换码功能 支付宝支付 ⚙️ 优化 link Doc2x 文档解析,增加报错信息捕获,增加超时时长。 调整 PG vector 查询语句,强制使用向量索引。 对话时间统计,准确返回工作流整体运行时间。 从 ai_proxy 获取音频解析时长。 AI 模型 Token 值均优先采用 API usage,确保 tokens 值准确,若为空,则再采用 GPT3.5 的估算方式。 🐛 修复 link 文件上传分块大小限制,避免超出 MongoDB 限制。 使用记录仪表盘,无法获取指定成员的使用统计。 仪表盘接口,因未考虑时区问题,统计异常。 LLM 模型测试接口,无法测试未启用的 LLM。同时修复,模型测试接口会把模型自定义请求地址去除问题。 Copy app 权限问题。 导出对话记录,限制单条对话记录消息上限 1000 组,避免导出失败。 工作流变量下一段文本仍是工作流变量,不触发渲染。 调试知识库检索模块,提示无权操作知识库。 文本内容提取节点,默认值赋值逻辑。 分享链接中,会强制返回嵌套应用中的引用内容。 V4.9.6 https://doc.tryfastgpt.ai/docs/development/upgrading/496/Mon, 01 Jan 0001 00:00:00 +0000 https://doc.tryfastgpt.ai/docs/development/upgrading/496/ 🚀 新增内容 link 以 MCP 方式对外提供应用调用。 支持以 MCP SSE 协议创建工具。 批量执行节点支持交互节点,可实现每一轮循环都人工参与。 增加工作台二级菜单,合并工具箱。 增加 grok3、GPT4.1、o系列、Gemini2.5 模型系统配置。 ⚙️ 优化 link 工作流数据类型转化鲁棒性和兼容性增强。 Python sandbox 代码,支持大数据输入。 路径组件支持配置最后一步是否可点击。 知识库工具调用结果,自动补充图片域名。 Github action runner 升级成 unbuntu24 去除飞书、公众号等三方渠道,回复时,可能前后多一个换行的问题。 调整分块策略,大表格时,不进行超大块合并,而是独立拆块。 Iframe 嵌套组件,内置允许麦克风声明。 🐛 修复 link 修复子工作流包含交互节点时,未成功恢复子工作流所有数据。 completion v1 接口,未接受 interactive 参数,导致 API 调用失败。 连续工具调用,上下文截断异常 升级指南 link1. 做好数据备份 link2. 部署 MCP server 服务 linkDocker 部署 link在docker-compose.yml文件中,加入fastgpt-mcp-server服务: fastgpt-mcp-server: container_name: fastgpt-mcp-server image: ghcr.io/labring/fastgpt-mcp_server:v4.9.6 ports: - 3005:3000 networks: - fastgpt restart: always environment: - FASTGPT_ENDPOINT=http://fastgpt:3000 Sealos 部署 link直接在应用管理中,增加一个fastgpt-mcp-server应用,镜像为ghcr. V4.9.5 https://doc.tryfastgpt.ai/docs/development/upgrading/495/Mon, 01 Jan 0001 00:00:00 +0000 https://doc.tryfastgpt.ai/docs/development/upgrading/495/ 升级指南 link1. 做好数据备份 link2. 更新镜像 tag link 更新 FastGPT 镜像 tag: v4.9.5 更新 FastGPT 商业版镜像 tag: v4.9.5 Sandbox 无需更新 AIProxy 无需更新 🚀 新增内容 link 团队成员权限细分,可分别控制是否可创建在根目录应用/知识库以及 API Key 支持交互节点在嵌套工作流中使用。 团队成员操作日志。 用户输入节点支持多选框。 ⚙️ 优化 link 繁体中文翻译。 Arm 镜像打包 🐛 修复 link password 检测规则错误。 分享链接无法隐藏知识库检索结果。 IOS 低版本正则兼容问题。 修复问答提取队列错误后,计数器未清零问题,导致问答提取队列失效。 Debug 模式交互节点下一步可能造成死循环。 V4.9.4 https://doc.tryfastgpt.ai/docs/development/upgrading/494/Mon, 01 Jan 0001 00:00:00 +0000 https://doc.tryfastgpt.ai/docs/development/upgrading/494/ 升级指南 link1. 做好数据备份 link2. 安装 Redis link docker 部署的用户,参考最新的 docker-compose.yml 文件增加 Redis 配置。增加一个 redis 容器,并配置fastgpt,fastgpt-pro的环境变量,增加 REDIS_URL 环境变量。 Sealos 部署的用户,在数据库里新建一个redis数据库,并复制内网地址的 connection 作为 redis 的链接串。然后配置fastgpt,fastgpt-pro的环境变量,增加 REDIS_URL 环境变量。 3. 更新镜像 tag link 更新 FastGPT 镜像 tag: v4.9.4 更新 FastGPT 商业版镜像 tag: v4.9.4 Sandbox 无需更新 AIProxy 无需更新 4. 执行升级脚本 link该脚本仅需商业版用户执行。 从任意终端,发起 1 个 HTTP 请求。其中 {{rootkey}} 替换成环境变量里的 rootkey;{{host}} 替换成FastGPT 域名。 curl --location --request POST 'https://{{host}}/api/admin/initv494' \ --header 'rootkey: {{rootkey}}' \ --header 'Content-Type: application/json' 脚本功能 V4.9.3 https://doc.tryfastgpt.ai/docs/development/upgrading/493/Mon, 01 Jan 0001 00:00:00 +0000 https://doc.tryfastgpt.ai/docs/development/upgrading/493/ 更新指南 link1. 做好数据库备份 link2. 更新镜像 link 更新 FastGPT 镜像 tag: v4.9.3 更新 FastGPT 商业版镜像 tag: v4.9.3 Sandbox 镜像tag: v4.9.3 AIProxy 镜像tag: v0.1.5 🚀 新增内容 link 工作流 debug 模式支持交互节点。 代码运行支持 Python3 代码。 🐛 修复 link 工作流格式转化异常。 V4.9.2 https://doc.tryfastgpt.ai/docs/development/upgrading/492/Mon, 01 Jan 0001 00:00:00 +0000 https://doc.tryfastgpt.ai/docs/development/upgrading/492/ 更新指南 link可直接升级v4.9.3,v4.9.2存在一个工作流数据类型转化错误。 diff --git a/docs/guide/admin/sso/index.html b/docs/guide/admin/sso/index.html index 67392460b..1f1fc29b5 100644 --- a/docs/guide/admin/sso/index.html +++ b/docs/guide/admin/sso/index.html @@ -176,12 +176,12 @@ Table of Contents 标准接口文档
以下是 FastGPT-pro 中,SSO 和成员同步的标准接口文档,如果需要对接非标准系统,可以参考该章节进行开发。
FastGPT 提供如下标准接口支持:
- https://example.com/login/oauth/getAuthURL 获取鉴权重定向地址
- https://example.com/login/oauth/getUserInfo?code=xxxxx 消费 code,换取用户信息
- https://example.com/org/list 获取组织列表
- https://example.com/user/list 获取成员列表
获取 SSO 登录重定向地址
返回一个重定向登录地址,fastgpt 会自动重定向到该地址。redirect_uri 会自动拼接到该地址的 query中。
+标准接口文档
以下是 FastGPT-pro 中,SSO 和成员同步的标准接口文档,如果需要对接非标准系统,可以参考该章节进行开发。
FastGPT 提供如下标准接口支持:
- https://example.com/login/oauth/getAuthURL 获取鉴权重定向地址
- https://example.com/login/oauth/getUserInfo?code=xxxxx 消费 code,换取用户信息
- https://example.com/org/list 获取组织列表
- https://example.com/user/list 获取成员列表
获取 SSO 登录重定向地址
返回一个重定向登录地址,fastgpt 会自动重定向到该地址。redirect_uri 会自动拼接到该地址的 query中。
SSO 获取用户信息
该接口接受一个 code 参数作为鉴权,消费 code 返回用户信息。
SSO 获取用户信息
该接口接受一个 code 参数作为鉴权,消费 code 返回用户信息。
获取组织
获取组织
获取成员
获取成员
curl -X GET "https://example.com/user/list" \ -H "Authorization: Bearer your_token_here" \ -H "Content-Type: application/json"-返回值类型:
+返回值类型:
type UserListResponseListType = { message?: string; // 报错信息 success: boolean; diff --git a/docs/guide/dashboard/workflow/http/index.html b/docs/guide/dashboard/workflow/http/index.html index 5f2cc4ae0..77b99e29c 100644 --- a/docs/guide/dashboard/workflow/http/index.html +++ b/docs/guide/dashboard/workflow/http/index.html @@ -34,9 +34,9 @@ FAQHTTP 请求
FastGPT HTTP 模块介绍
特点
- 可重复添加
- 手动配置
- 触发执行
- 核中核模块
介绍
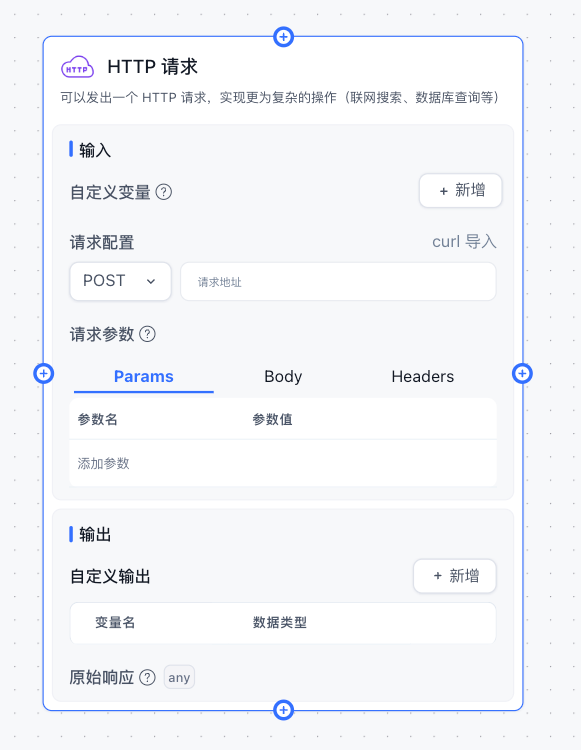
HTTP 模块会向对应的地址发送一个
HTTP请求,实际操作与 Postman 和 ApiFox 这类直流工具使用差不多。
- Params 为路径请求参数,GET请求中用的居多。
- Body 为请求体,POST/PUT请求中用的居多。
- Headers 为请求头,用于传递一些特殊的信息。
- 自定义变量中可以接收前方节点的输出作为变量
- 3 种数据中均可以通过
{{}}来引用变量。- url 也可以通过
{{}}来引用变量。- 变量来自于
全局变量、系统变量、前方节点输出参数结构
系统变量说明
你可以将鼠标放置在
请求参数旁边的问号中,里面会提示你可用的变量。
- appId: 应用的ID
- chatId: 当前对话的ID,测试模式下不存在。
- responseChatItemId: 当前对话中,响应的消息ID,测试模式下不存在。
- variables: 当前对话的全局变量。
- cTime: 当前时间。
- histories: 历史记录(默认最多取10条,无法修改长度)
Params, Headers
不多描述,使用方法和Postman, ApiFox 基本一致。
可通过 {{key}} 来引入变量。例如:
key value appId {{appId}} Authorization Bearer {{token}} Body
只有特定请求类型下会生效。
可以写一个
自定义的 Json,并通过 {{key}} 来引入变量。例如:+Table of ContentshttpHTTP 请求
FastGPT HTTP 模块介绍
特点
- 可重复添加
- 手动配置
- 触发执行
- 核中核模块
介绍
HTTP 模块会向对应的地址发送一个
HTTP请求,实际操作与 Postman 和 ApiFox 这类直流工具使用差不多。
- Params 为路径请求参数,GET请求中用的居多。
- Body 为请求体,POST/PUT请求中用的居多。
- Headers 为请求头,用于传递一些特殊的信息。
- 自定义变量中可以接收前方节点的输出作为变量
- 3 种数据中均可以通过
{{}}来引用变量。- url 也可以通过
{{}}来引用变量。- 变量来自于
全局变量、系统变量、前方节点输出参数结构
系统变量说明
你可以将鼠标放置在
请求参数旁边的问号中,里面会提示你可用的变量。
- appId: 应用的ID
- chatId: 当前对话的ID,测试模式下不存在。
- responseChatItemId: 当前对话中,响应的消息ID,测试模式下不存在。
- variables: 当前对话的全局变量。
- cTime: 当前时间。
- histories: 历史记录(默认最多取10条,无法修改长度)
Params, Headers
不多描述,使用方法和Postman, ApiFox 基本一致。
可通过 {{key}} 来引入变量。例如:
key value appId {{appId}} Authorization Bearer {{token}} Body
只有特定请求类型下会生效。
可以写一个
自定义的 Json,并通过 {{key}} 来引入变量。例如:如何获取返回值
从图中可以看出,FastGPT可以添加多个返回值,这个返回值并不代表接口的返回值,而是代表
如何解析接口返回值,可以通过JSON path的语法,来提取接口响应的值。语法可以参考: https://github.com/JSONPath-Plus/JSONPath?tab=readme-ov-file
如何获取返回值
从图中可以看出,FastGPT可以添加多个返回值,这个返回值并不代表接口的返回值,而是代表
如何解析接口返回值,可以通过JSON path的语法,来提取接口响应的值。语法可以参考: https://github.com/JSONPath-Plus/JSONPath?tab=readme-ov-file