21054 lines
720 KiB
Plaintext
21054 lines
720 KiB
Plaintext
# 开源协议
|
||
## FastGPT 开源许可证
|
||
|
||
FastGPT 项目在 Apache License 2.0 许可下开源,但包含以下附加条件:
|
||
|
||
+ FastGPT 允许被用于商业化,例如作为其他应用的“后端即服务”使用,或者作为应用开发平台提供给企业。然而,当满足以下条件时,必须联系作者获得商业许可:
|
||
|
||
+ 多租户 SaaS 服务:除非获得 FastGPT 的明确书面授权,否则不得使用 tryfastgpt.ai 的源码来运营与 tryfastgpt.ai 服务类似的多租户 SaaS 服务。
|
||
+ LOGO 及版权信息:在使用 FastGPT 的过程中,不得移除或修改 FastGPT 控制台内的 LOGO 或版权信息。
|
||
|
||
请通过电子邮件 yujinlong@sealos.io 联系我们咨询许可事宜。
|
||
|
||
+ 作为贡献者,你必须同意将你贡献的代码用于以下用途:
|
||
|
||
+ 生产者有权将开源协议调整为更严格或更宽松的形式。
|
||
+ 可用于商业目的,例如 FastGPT 的云服务。
|
||
|
||
除此之外,所有其他权利和限制均遵循 Apache License 2.0。如果你需要更多详细信息,可以参考 Apache License 2.0 的完整版本。本产品的交互设计受到外观专利保护。© 2023 Sealos.
|
||
|
||
# 隐私政策
|
||
## FastGPT 隐私政策
|
||
|
||
最后更新时间:2024年3月3日
|
||
|
||
我们非常重视您的隐私保护,在您使用FastGPT云服务时(以下简称为“本服务”),我们将按照以下政策收集、使用、披露和保护您的个人信息。请您仔细阅读并充分理解本隐私政策。
|
||
|
||
**我们可能需要收集的信息**
|
||
|
||
1. 在您注册或使用本服务时,我们可能收集您的姓名、电话号码、电子邮件地址、地址等个人信息。
|
||
2. 在您使用本服务过程中产生的信息,如操作日志、访问IP地址、设备型号等。
|
||
3. 我们可能会通过 Cookies 或其他技术收集和存储您访问本服务的相关信息,以便为您提供更好的用户体验。
|
||
|
||
**我们如何使用收集的信息?**
|
||
|
||
1. 我们会根据法律法规规定以及与用户之间的约定来处理用户的个人信息。
|
||
2. 我们可能会将收集到的信息用于改进服务质量、开发新产品或功能等目的。
|
||
3. 我们可能会将收集到的信息用于向您推送与本服务相关的通知或广告。
|
||
|
||
**信息披露**
|
||
|
||
1. 我们不会向任何第三方披露您的个人信息,除非:
|
||
|
||
1. 您事先同意;
|
||
2. 法律法规要求;
|
||
3. 为维护我们或其他用户的合法权益。
|
||
|
||
2. 我们可能与关联公司、合作伙伴分享您的个人信息,但我们会采取相应的保密措施,确保信息安全。
|
||
|
||
**信息保护**
|
||
|
||
1. 我们采取各种安全措施,包括加密、访问控制等技术手段,以保护您的个人信息免受未经授权的访问、使用或泄露。
|
||
2. 我们会定期对收集、存储和处理的个人信息进行安全评估,以确保个人信息安全。
|
||
3. 在发生个人信息泄露等安全事件时,我们会立即启动应急预案,并在法律法规规定的范围内向您及时告知。
|
||
4. 我们不会使用您的数据进行额外的备份存储或用于模型训练。
|
||
5. 您在本服务进行的数据删除均为物理删除,不可恢复。如有非物理删除的操作,我们会在服务中特别指出。
|
||
|
||
**用户权利**
|
||
|
||
1. 您有权随时查阅、更正或删除您的个人信息。
|
||
2. 您有权拒绝我们收集您的个人信息,但这可能导致您无法使用本服务的部分功能。
|
||
3. 您有权要求我们停止处理您的个人信息,但这可能导致您无法继续使用本服务。
|
||
|
||
**隐私政策更新**
|
||
|
||
1. 我们可能会对本隐私政策进行修改。如本隐私政策发生变更,我们将在本服务页面上发布修改后的隐私政策。如您继续使用本服务,则视为同意修改后的隐私政策。
|
||
2. 我们鼓励您定期查阅本隐私政策,以了解我们如何保护您的个人信息。
|
||
|
||
**未成年人保护**
|
||
|
||
我们非常重视对未成年人个人信息的保护,如您为未成年人,请在监护人指导下使用本服务,并请监护人帮助您在使用本服务过程中正确处理个人信息。
|
||
|
||
**跨境数据传输**
|
||
|
||
由于我们的服务器可能位于不同国家或地区,您同意我们可能需要将您的个人信息传输至其他国家或地区,并在该等国家或地区存储和处理以向您提供服务。我们会采取适当措施确保跨境传输的数据仍然受到适当保护。
|
||
|
||
**联系我们**
|
||
|
||
1. 如您对本隐私政策有任何疑问、建议或投诉,请通过以下方式与我们联系:yujinlong@sealos.io。
|
||
2. 我们将尽快回复并解决您提出的问题。
|
||
|
||
# 服务协议
|
||
## FastGPT 服务协议
|
||
|
||
最后更新时间:2024年3月3日
|
||
|
||
FastGPT 服务协议是您与珠海环界云计算有限公司(以下简称“我们”或“本公司”)之间就FastGPT云服务(以下简称“本服务”)的使用等相关事项所订立的协议。请您仔细阅读并充分理解本协议各条款,特别是免除或者限制我们责任的条款、对您权益的限制条款、争议解决和法律适用条款等。如您不同意本协议任一内容,请勿注册或使用本服务。
|
||
|
||
**第1条 服务内容**
|
||
|
||
1. 我们将向您提供存储、计算、网络传输等基于互联网的信息技术服务。
|
||
2. 我们将不定期向您通过站内信、电子邮件或短信等形式向您推送最新的动态。
|
||
3. 我们将为您提供相关技术支持和客户服务,帮助您更好地使用本服务。
|
||
4. 我们将为您提供稳定的在线服务,保证每月服务可用性不低于99%。
|
||
|
||
**第2条 用户注册与账户管理**
|
||
|
||
1. 您在使用本服务前需要注册一个账户。您保证在注册时提供的信息真实、准确、完整,并及时更新。
|
||
2. 您应妥善保管账户名和密码,对由此产生的全部行为负责。如发现他人使用您的账户,请及时修改账号密码或与我们进行联系。
|
||
3. 我们有权对您的账户进行审查,如发现您的账户存在异常或违法情况,我们有权暂停或终止向您提供服务。
|
||
|
||
**第3条 使用规则**
|
||
|
||
1. 您不得利用本服务从事任何违法活动或侵犯他人合法权益的行为,包括但不限于侵犯知识产权、泄露他人商业机密等。
|
||
2. 您不得通过任何手段恶意注册账户,包括但不限于以牟利、炒作、套现等目的。
|
||
3. 您不得利用本服务传播任何违法、有害、恶意软件等信息。
|
||
4. 您应遵守相关法律法规及本协议的规定,对在本服务中发布的信息及使用本服务所产生的结果承担全部责任。
|
||
5. 我们禁止使用我们对接的模型服务生成可能对个人或社会造成伤害的内容。保障平台的安全性,是长期稳定运营的关键。如发现任何利用平台接入模型能力进行违规内容生成和使用,将立即封号,账号余额不退。违规内容包括但不限于:
|
||
- 剥削和虐待
|
||
- 禁止描述、展示或宣扬儿童性剥削或性虐待的内容,无论法律是否禁止。这包括涉及儿童或使儿童色情的内容。
|
||
- 禁止描述或用于培养儿童的内容。修饰是成年人以剥削,特别是性剥削为目的与儿童建立关系的行为。这包括以性剥削、贩运或其他形式剥削为目的与儿童交流。
|
||
- 未经同意的私密内容
|
||
- 服务禁止描述、提供或宣传未经同意的亲密活动的内容。
|
||
- 禁止描述、提供特征或宣传或用于招揽商业性活动和性服务的内容。这包括鼓励和协调真正的性活动。
|
||
- 禁止描述或用于人口贩运目的的内容。这包括招募人员、便利交通、支付和助长对人的剥削,如强迫劳动、家庭奴役、役、强迫婚姻和强迫医疗程序。
|
||
- 自杀和自残,禁止描述、赞美、支持、促进、美化、鼓励和/或指导个人自残或自杀的内容。
|
||
- 暴力内容和行为
|
||
- 禁止描述、展示或宣扬血腥暴力或血腥的内容。
|
||
- 禁止描绘恐怖主义行为的内容;赞扬或支持恐怖组织、恐怖行为者或暴力恐怖意识形态;鼓励恐怖活动;向恐怖组织或恐怖事业提供援助;或协助恐怖组织招募成员。
|
||
- 禁止通过暴力威胁或煽动来鼓吹或宣扬对他人的暴力行为的内容。
|
||
- 仇恨言论和歧视
|
||
- 禁止基于实际或感知的种族、民族、国籍、性别、性别认同、性取向、宗教信仰、年龄、残疾状况、种姓或与系统性偏见或边缘化相关的任何其他特征等特征攻击、诋毁、恐吓、降级、针对或排斥个人或群体的内容。
|
||
- 禁止针对个人或群体进行威胁、恐吓、侮辱、贬低或贬低的语言或图像、宣扬身体伤害或其他虐待行为(如跟踪)的内容。
|
||
- 禁止故意欺骗并可能对公共利益产生不利影响的内容,包括与健康、安全、选举诚信或公民参与相关的欺骗性或不真实内容。
|
||
- 直接支持非法主动攻击或造成技术危害的恶意软件活动的内容,例如提供恶意可执行文件、组织拒绝服务攻击或管理命令和控制服务器。
|
||
|
||
|
||
**第4条 费用及支付**
|
||
|
||
1. 您同意支付与本服务相关的费用,具体费用标准以我们公布的价格为准。
|
||
2. 我们可能会根据运营成本和市场情况调整费用标准。最新价格以您付款时刻的价格为准。
|
||
|
||
**第5条 服务免责与责任限制**
|
||
|
||
1. 本服务按照现有技术和条件所能达到的水平提供。我们不能保证本服务完全无故障或满足您的所有需求。
|
||
2. 对于因您自身误操作导致的数据丢失、损坏等情况,我们不承担责任。
|
||
3. 由于生成式 AI 的特性,其在不同国家的管控措施也会有所不同,请所有使用者务必遵守所在地的相关法律。如果您以任何违反 FastGPT 可接受使用政策的方式使用,包括但不限于法律、法规、政府命令或法令禁止的任何用途,或任何侵犯他人权利的使用;由使用者自行承担。我们对由客户使用产生的问题概不负责。下面是各国对生成式AI的管控条例的链接:
|
||
|
||
[中国生成式人工智能服务管理办法(征求意见稿)](http://www.cac.gov.cn/2023-04/11/c_1682854275475410.htm)
|
||
|
||
**第6条 知识产权**
|
||
|
||
1. 我们对本服务及相关软件、技术、文档等拥有全部知识产权,除非经我们明确许可,您不得进行复制、分发、出租、反向工程等行为。
|
||
2. 您在使用本服务过程中产生的所有数据和内容(包括但不限于文件、图片等)的知识产权归您所有。我们不会对您的数据和内容进行使用、复制、修改等行为。
|
||
3. 在线服务中其他用户的数据和内容的知识产权归原用户所有,未经原用户许可,您不得进行使用、复制、修改等行为。
|
||
|
||
**第7条 其他条款**
|
||
|
||
1. 如本协议中部分条款因违反法律法规而被视为无效,不影响其他条款的效力。
|
||
2. 本公司保留对本协议及隐私政策的最终解释权。如您对本协议或隐私政策有任何疑问,请联系我们:yujinlong@sealos.io。
|
||
|
||
# 加入社区
|
||
## 加入 FastGPT 开发者社区和我们一起成长
|
||
|
||
FastGPT 是一个由用户和贡献者参与推动的开源项目,如果您对产品使用存在疑问和建议,可尝试以下方式寻求支持。我们的团队与社区会竭尽所能为您提供帮助。
|
||
|
||
+ 📱 扫码加入社区微信交流群👇
|
||
|
||
<img width="400px" src="https://oss.laf.run/otnvvf-imgs/fastgpt-feishu1.png" class="medium-zoom-image" />
|
||
|
||
+ 🐞 请将任何 FastGPT 的 Bug、问题和需求提交到 [GitHub Issue](https://github.com/labring/fastgpt/issues/new/choose)。
|
||
|
||
# 配置文件介绍
|
||
## FastGPT 配置参数介绍
|
||
|
||
由于环境变量不利于配置复杂的内容,新版 FastGPT 采用了 ConfigMap 的形式挂载配置文件,你可以在 `projects/app/data/config.json` 看到默认的配置文件。可以参考 [docker-compose 快速部署](/docs/development/docker/) 来挂载配置文件。
|
||
|
||
**开发环境下**,你需要将示例配置文件 `config.json` 复制成 `config.local.json` 文件才会生效。
|
||
|
||
下面配置文件示例中包含了系统参数和各个模型配置:
|
||
|
||
## 4.8.20+ 版本新配置文件示例
|
||
> 从4.8.20版本开始,模型在页面中进行配置。
|
||
```json
|
||
{
|
||
"feConfigs": {
|
||
"lafEnv": "https://laf.dev" // laf环境。 https://laf.run (杭州阿里云) ,或者私有化的laf环境。如果使用 Laf openapi 功能,需要最新版的 laf 。
|
||
},
|
||
"systemEnv": {
|
||
"vectorMaxProcess": 15, // 向量处理线程数量
|
||
"qaMaxProcess": 15, // 问答拆分线程数量
|
||
"vlmMaxProcess": 15, // 图片理解模型最大处理进程
|
||
"tokenWorkers": 50, // Token 计算线程保持数,会持续占用内存,不能设置太大。
|
||
"hnswEfSearch": 100, // 向量搜索参数,仅对 PG 和 OB 生效。越大,搜索越精确,但是速度越慢。设置为100,有99%+精度。
|
||
"customPdfParse": { // 4.9.0 新增配置
|
||
"url": "", // 自定义 PDF 解析服务地址
|
||
"key": "", // 自定义 PDF 解析服务密钥
|
||
"doc2xKey": "", // doc2x 服务密钥
|
||
"price": 0 // PDF 解析服务价格
|
||
}
|
||
}
|
||
}
|
||
```
|
||
|
||
## 自定义 PDF 解析配置
|
||
|
||
自定义 PDF 服务解析的优先级高于 Doc2x 服务,所以如果使用 Doc2x 服务,请勿配置自定义 PDF 服务。
|
||
|
||
### 使用 Sealos PDF 解析服务
|
||
|
||
#### 1. 申请 Sealos AI proxy API Key
|
||
|
||
[点击打开 Sealos Pdf parser 官网](https://hzh.sealos.run/?uid=fnWRt09fZP&openapp=system-aiproxy),并进行对应 API Key 的申请。
|
||
|
||
#### 2. 修改 FastGPT 配置文件
|
||
|
||
`systemEnv.customPdfParse.url`填写成`https://aiproxy.hzh.sealos.run/v1/parse/pdf?model=parse-pdf`
|
||
`systemEnv.customPdfParse.key`填写成在 Sealos AI proxy 中申请的 API Key。
|
||
|
||

|
||
|
||
### 使用 Doc2x 解析 PDF 文件
|
||
|
||
`Doc2x`是一个国内提供专业 PDF 解析。
|
||
|
||
#### 1. 申请 Doc2x 服务
|
||
|
||
[点击打开 Doc2x 官网](https://doc2x.noedgeai.com?inviteCode=9EACN2),并进行对应 API Key 的申请。
|
||
|
||
#### 2. 修改 FastGPT 配置文件
|
||
|
||
开源版用户在 `config.json` 文件中添加 `systemEnv.customPdfParse.doc2xKey` 配置,并填写上申请到的 API Key。并重启服务。
|
||
|
||
商业版用户在 Admin 后台根据表单指引填写 Doc2x 服务密钥。
|
||
|
||
#### 3. 开始使用
|
||
|
||
在知识库导入数据或应用文件上传配置中,可以勾选`PDF 增强解析`,则在对 PDF 解析时候,会使用 Doc2x 服务进行解析。
|
||
|
||
### 使用 Marker 解析 PDF 文件
|
||
|
||
[点击查看 Marker 接入教程](/docs/development/custom-models/marker)
|
||
|
||
# 接入 bge-rerank 重排模型
|
||
## 接入 bge-rerank 重排模型
|
||
|
||
## 不同模型推荐配置
|
||
|
||
推荐配置如下:
|
||
|
||
{{< table "table-hover table-striped-columns" >}}
|
||
| 模型名 | 内存 | 显存 | 硬盘空间 | 启动命令 |
|
||
|------|---------|---------|----------|--------------------------|
|
||
| bge-reranker-base | >=4GB | >=4GB | >=8GB | python app.py |
|
||
| bge-reranker-large | >=8GB | >=8GB | >=8GB | python app.py |
|
||
| bge-reranker-v2-m3 | >=8GB | >=8GB | >=8GB | python app.py |
|
||
{{< /table >}}
|
||
|
||
## 源码部署
|
||
|
||
### 1. 安装环境
|
||
|
||
- Python 3.9, 3.10
|
||
- CUDA 11.7
|
||
- 科学上网环境
|
||
|
||
### 2. 下载代码
|
||
|
||
3 个模型代码分别为:
|
||
|
||
1. [https://github.com/labring/FastGPT/tree/main/plugins/model/rerank-bge/bge-reranker-base](https://github.com/labring/FastGPT/tree/main/plugins/model/rerank-bge/bge-reranker-base)
|
||
2. [https://github.com/labring/FastGPT/tree/main/plugins/model/rerank-bge/bge-reranker-large](https://github.com/labring/FastGPT/tree/main/plugins/model/rerank-bge/bge-reranker-large)
|
||
3. [https://github.com/labring/FastGPT/tree/main/plugins/model/rerank-bge/bge-reranker-v2-m3](https://github.com/labring/FastGPT/tree/main/plugins/model/rerank-bge/bge-reranker-v2-m3)
|
||
|
||
### 3. 安装依赖
|
||
|
||
```sh
|
||
pip install -r requirements.txt
|
||
```
|
||
|
||
### 4. 下载模型
|
||
|
||
3个模型的 huggingface 仓库地址如下:
|
||
|
||
1. [https://huggingface.co/BAAI/bge-reranker-base](https://huggingface.co/BAAI/bge-reranker-base)
|
||
2. [https://huggingface.co/BAAI/bge-reranker-large](https://huggingface.co/BAAI/bge-reranker-large)
|
||
3. [https://huggingface.co/BAAI/bge-reranker-v2-m3](https://huggingface.co/BAAI/bge-reranker-v2-m3)
|
||
|
||
在对应代码目录下 clone 模型。目录结构:
|
||
|
||
```
|
||
bge-reranker-base/
|
||
app.py
|
||
Dockerfile
|
||
requirements.txt
|
||
```
|
||
|
||
### 5. 运行代码
|
||
|
||
```bash
|
||
python app.py
|
||
```
|
||
|
||
启动成功后应该会显示如下地址:
|
||
|
||

|
||
|
||
> 这里的 `http://0.0.0.0:6006` 就是连接地址。
|
||
|
||
## docker 部署
|
||
|
||
**镜像名分别为:**
|
||
|
||
1. registry.cn-hangzhou.aliyuncs.com/fastgpt/bge-rerank-base:v0.1 (4 GB+)
|
||
2. registry.cn-hangzhou.aliyuncs.com/fastgpt/bge-rerank-large:v0.1 (5 GB+)
|
||
3. registry.cn-hangzhou.aliyuncs.com/fastgpt/bge-rerank-v2-m3:v0.1 (5 GB+)
|
||
|
||
**端口**
|
||
|
||
6006
|
||
|
||
**环境变量**
|
||
|
||
```
|
||
ACCESS_TOKEN=访问安全凭证,请求时,Authorization: Bearer ${ACCESS_TOKEN}
|
||
```
|
||
|
||
**运行命令示例**
|
||
|
||
```sh
|
||
# auth token 为mytoken
|
||
docker run -d --name reranker -p 6006:6006 -e ACCESS_TOKEN=mytoken --gpus all registry.cn-hangzhou.aliyuncs.com/fastgpt/bge-rerank-base:v0.1
|
||
```
|
||
|
||
**docker-compose.yml示例**
|
||
```
|
||
version: "3"
|
||
services:
|
||
reranker:
|
||
image: registry.cn-hangzhou.aliyuncs.com/fastgpt/bge-rerank-base:v0.1
|
||
container_name: reranker
|
||
# GPU运行环境,如果宿主机未安装,将deploy配置隐藏即可
|
||
deploy:
|
||
resources:
|
||
reservations:
|
||
devices:
|
||
- driver: nvidia
|
||
count: all
|
||
capabilities: [gpu]
|
||
ports:
|
||
- 6006:6006
|
||
environment:
|
||
- ACCESS_TOKEN=mytoken
|
||
|
||
```
|
||
## 接入 FastGPT
|
||
|
||
1. 打开 FastGPT 模型配置,新增一个重排模型。
|
||
2. 填写模型配置表单:模型 ID 为`bge-reranker-base`,地址填写`{{host}}/v1/rerank`,host 为你部署的域名/IP:Port。
|
||
|
||

|
||
|
||
## QA
|
||
|
||
### 403报错
|
||
|
||
FastGPT中,自定义请求 Token 和环境变量的 ACCESS_TOKEN 不一致。
|
||
|
||
### Docker 运行提示 `Bus error (core dumped)`
|
||
|
||
尝试增加 `docker-compose.yml` 配置项 `shm_size` ,以增加容器中的共享内存目录大小。
|
||
|
||
```
|
||
...
|
||
services:
|
||
reranker:
|
||
...
|
||
container_name: reranker
|
||
shm_size: '2gb'
|
||
...
|
||
```
|
||
|
||
# 接入 ChatGLM2-m3e 模型
|
||
## 将 FastGPT 接入私有化模型 ChatGLM2和m3e-large
|
||
|
||
## 前言
|
||
|
||
FastGPT 默认使用了 OpenAI 的 LLM 模型和向量模型,如果想要私有化部署的话,可以使用 ChatGLM2 和 m3e-large 模型。以下是由用户@不做了睡大觉 提供的接入方法。该镜像直接集成了 M3E-Large 和 ChatGLM2-6B 模型,可以直接使用。
|
||
|
||
## 部署镜像
|
||
|
||
+ 镜像名: `stawky/chatglm2-m3e:latest`
|
||
+ 国内镜像名: `registry.cn-hangzhou.aliyuncs.com/fastgpt_docker/chatglm2-m3e:latest`
|
||
+ 端口号: 6006
|
||
|
||
```
|
||
# 设置安全凭证(即oneapi中的渠道密钥)
|
||
默认值:sk-aaabbbcccdddeeefffggghhhiiijjjkkk
|
||
也可以通过环境变量引入:sk-key。有关docker环境变量引入的方法请自寻教程,此处不再赘述。
|
||
```
|
||
|
||
## 接入 [One API](/docs/development/modelconfig/one-api/)
|
||
|
||
为 chatglm2 和 m3e-large 各添加一个渠道,参数如下:
|
||
|
||

|
||
|
||
这里我填入 m3e 作为向量模型,chatglm2 作为语言模型
|
||
|
||
## 测试
|
||
|
||
curl 例子:
|
||
|
||
```bash
|
||
curl --location --request POST 'https://domain/v1/embeddings' \
|
||
--header 'Authorization: Bearer sk-aaabbbcccdddeeefffggghhhiiijjjkkk' \
|
||
--header 'Content-Type: application/json' \
|
||
--data-raw '{
|
||
"model": "m3e",
|
||
"input": ["laf是什么"]
|
||
}'
|
||
```
|
||
|
||
```bash
|
||
curl --location --request POST 'https://domain/v1/chat/completions' \
|
||
--header 'Authorization: Bearer sk-aaabbbcccdddeeefffggghhhiiijjjkkk' \
|
||
--header 'Content-Type: application/json' \
|
||
--data-raw '{
|
||
"model": "chatglm2",
|
||
"messages": [{"role": "user", "content": "Hello!"}]
|
||
}'
|
||
```
|
||
|
||
Authorization 为 sk-aaabbbcccdddeeefffggghhhiiijjjkkk。model 为刚刚在 One API 填写的自定义模型。
|
||
|
||
## 接入 FastGPT
|
||
|
||
修改 config.json 配置文件,在 llmModels 中加入 chatglm2, 在 vectorModels 中加入 M3E 模型:
|
||
|
||
```json
|
||
"llmModels": [
|
||
//其他对话模型
|
||
{
|
||
"model": "chatglm2",
|
||
"name": "chatglm2",
|
||
"maxToken": 8000,
|
||
"price": 0,
|
||
"quoteMaxToken": 4000,
|
||
"maxTemperature": 1.2,
|
||
"defaultSystemChatPrompt": ""
|
||
}
|
||
],
|
||
"vectorModels": [
|
||
{
|
||
"model": "text-embedding-ada-002",
|
||
"name": "Embedding-2",
|
||
"price": 0.2,
|
||
"defaultToken": 500,
|
||
"maxToken": 3000
|
||
},
|
||
{
|
||
"model": "m3e",
|
||
"name": "M3E(测试使用)",
|
||
"price": 0.1,
|
||
"defaultToken": 500,
|
||
"maxToken": 1800
|
||
}
|
||
],
|
||
```
|
||
|
||
## 测试使用
|
||
|
||
M3E 模型的使用方法如下:
|
||
|
||
1. 创建知识库时候选择 M3E 模型。
|
||
|
||
注意,一旦选择后,知识库将无法修改向量模型。
|
||
|
||

|
||
|
||
2. 导入数据
|
||
3. 搜索测试
|
||
|
||

|
||
|
||
4. 应用绑定知识库
|
||
|
||
注意,应用只能绑定同一个向量模型的知识库,不能跨模型绑定。并且,需要注意调整相似度,不同向量模型的相似度(距离)会有所区别,需要自行测试实验。
|
||
|
||

|
||
|
||
chatglm2 模型的使用方法如下:
|
||
模型选择 chatglm2 即可
|
||
|
||
# 接入 ChatGLM2-6B
|
||
## 将 FastGPT 接入私有化模型 ChatGLM2-6B
|
||
|
||
## 前言
|
||
|
||
FastGPT 允许你使用自己的 OpenAI API KEY 来快速调用 OpenAI 接口,目前集成了 GPT-3.5, GPT-4 和 embedding,可构建自己的知识库。但考虑到数据安全的问题,我们并不能将所有的数据都交付给云端大模型。
|
||
|
||
那么如何在 FastGPT 上接入私有化模型呢?本文就以清华的 ChatGLM2 为例,为各位讲解如何在 FastGPT 中接入私有化模型。
|
||
|
||
## ChatGLM2-6B 简介
|
||
|
||
ChatGLM2-6B 是开源中英双语对话模型 ChatGLM-6B 的第二代版本,具体介绍可参阅 [ChatGLM2-6B 项目主页](https://github.com/THUDM/ChatGLM2-6B)。
|
||
|
||
{{% alert context="warning" %}}
|
||
注意,ChatGLM2-6B 权重对学术研究完全开放,在获得官方的书面许可后,亦允许商业使用。本教程只是介绍了一种用法,无权给予任何授权!
|
||
{{% /alert %}}
|
||
|
||
## 推荐配置
|
||
|
||
依据官方数据,同样是生成 8192 长度,量化等级为 FP16 要占用 12.8GB 显存、int8 为 8.1GB 显存、int4 为 5.1GB 显存,量化后会稍微影响性能,但不多。
|
||
|
||
因此推荐配置如下:
|
||
|
||
{{< table "table-hover table-striped-columns" >}}
|
||
| 类型 | 内存 | 显存 | 硬盘空间 | 启动命令 |
|
||
|------|---------|---------|----------|--------------------------|
|
||
| fp16 | >=16GB | >=16GB | >=25GB | python openai_api.py 16 |
|
||
| int8 | >=16GB | >=9GB | >=25GB | python openai_api.py 8 |
|
||
| int4 | >=16GB | >=6GB | >=25GB | python openai_api.py 4 |
|
||
{{< /table >}}
|
||
|
||
## 部署
|
||
|
||
### 环境要求
|
||
|
||
- Python 3.8.10
|
||
- CUDA 11.8
|
||
- 科学上网环境
|
||
|
||
### 源码部署
|
||
|
||
1. 根据上面的环境配置配置好环境,具体教程自行 GPT;
|
||
2. 下载 [python 文件](https://github.com/labring/FastGPT/blob/main/plugins/model/llm-ChatGLM2/openai_api.py)
|
||
3. 在命令行输入命令 `pip install -r requirements.txt`;
|
||
4. 打开你需要启动的 py 文件,在代码的 `verify_token` 方法中配置 token,这里的 token 只是加一层验证,防止接口被人盗用;
|
||
5. 执行命令 `python openai_api.py --model_name 16`。这里的数字根据上面的配置进行选择。
|
||
|
||
然后等待模型下载,直到模型加载完毕为止。如果出现报错先问 GPT。
|
||
|
||
启动成功后应该会显示如下地址:
|
||
|
||

|
||
|
||
> 这里的 `http://0.0.0.0:6006` 就是连接地址。
|
||
|
||
### docker 部署
|
||
|
||
**镜像和端口**
|
||
|
||
+ 镜像名: `stawky/chatglm2:latest`
|
||
+ 国内镜像名: `registry.cn-hangzhou.aliyuncs.com/fastgpt_docker/chatglm2:latest`
|
||
+ 端口号: 6006
|
||
|
||
```
|
||
# 设置安全凭证(即oneapi中的渠道密钥)
|
||
默认值:sk-aaabbbcccdddeeefffggghhhiiijjjkkk
|
||
也可以通过环境变量引入:sk-key。有关docker环境变量引入的方法请自寻教程,此处不再赘述。
|
||
```
|
||
|
||
## 接入 One API
|
||
|
||
为 chatglm2 添加一个渠道,参数如下:
|
||
|
||

|
||
|
||
这里我填入 chatglm2 作为语言模型
|
||
|
||
## 测试
|
||
|
||
curl 例子:
|
||
|
||
```bash
|
||
curl --location --request POST 'https://domain/v1/chat/completions' \
|
||
--header 'Authorization: Bearer sk-aaabbbcccdddeeefffggghhhiiijjjkkk' \
|
||
--header 'Content-Type: application/json' \
|
||
--data-raw '{
|
||
"model": "chatglm2",
|
||
"messages": [{"role": "user", "content": "Hello!"}]
|
||
}'
|
||
```
|
||
|
||
Authorization 为 sk-aaabbbcccdddeeefffggghhhiiijjjkkk。model 为刚刚在 One API 填写的自定义模型。
|
||
|
||
## 接入 FastGPT
|
||
|
||
修改 config.json 配置文件,在 llmModels 中加入 chatglm2 模型:
|
||
|
||
```json
|
||
"llmModels": [
|
||
//已有模型
|
||
{
|
||
"model": "chatglm2",
|
||
"name": "chatglm2",
|
||
"maxContext": 4000,
|
||
"maxResponse": 4000,
|
||
"quoteMaxToken": 2000,
|
||
"maxTemperature": 1,
|
||
"vision": false,
|
||
"defaultSystemChatPrompt": ""
|
||
}
|
||
]
|
||
```
|
||
|
||
## 测试使用
|
||
|
||
chatglm2 模型的使用方法如下:
|
||
|
||
模型选择 chatglm2 即可
|
||
|
||
# 接入 M3E 向量模型
|
||
## 将 FastGPT 接入私有化模型 M3E
|
||
|
||
## 前言
|
||
|
||
FastGPT 默认使用了 openai 的 embedding 向量模型,如果你想私有部署的话,可以使用 M3E 向量模型进行替换。M3E 向量模型属于小模型,资源使用不高,CPU 也可以运行。下面教程是基于 “睡大觉” 同学提供的一个的镜像。
|
||
|
||
## 部署镜像
|
||
|
||
镜像名: `stawky/m3e-large-api:latest`
|
||
国内镜像: `registry.cn-hangzhou.aliyuncs.com/fastgpt_docker/m3e-large-api:latest`
|
||
端口号: 6008
|
||
环境变量:
|
||
|
||
```
|
||
# 设置安全凭证(即oneapi中的渠道密钥)
|
||
默认值:sk-aaabbbcccdddeeefffggghhhiiijjjkkk
|
||
也可以通过环境变量引入:sk-key。有关docker环境变量引入的方法请自寻教程,此处不再赘述。
|
||
```
|
||
|
||
## 接入 One API
|
||
|
||
添加一个渠道,参数如下:
|
||
|
||

|
||
|
||
## 测试
|
||
|
||
curl 例子:
|
||
|
||
```bash
|
||
curl --location --request POST 'https://domain/v1/embeddings' \
|
||
--header 'Authorization: Bearer xxxx' \
|
||
--header 'Content-Type: application/json' \
|
||
--data-raw '{
|
||
"model": "m3e",
|
||
"input": ["laf是什么"]
|
||
}'
|
||
```
|
||
|
||
Authorization 为 sk-key。model 为刚刚在 One API 填写的自定义模型。
|
||
|
||
## 接入 FastGPT
|
||
|
||
修改 config.json 配置文件,在 vectorModels 中加入 M3E 模型:
|
||
|
||
```json
|
||
"vectorModels": [
|
||
{
|
||
"model": "text-embedding-ada-002",
|
||
"name": "Embedding-2",
|
||
"price": 0.2,
|
||
"defaultToken": 500,
|
||
"maxToken": 3000
|
||
},
|
||
{
|
||
"model": "m3e",
|
||
"name": "M3E(测试使用)",
|
||
"price": 0.1,
|
||
"defaultToken": 500,
|
||
"maxToken": 1800
|
||
}
|
||
]
|
||
```
|
||
|
||
## 测试使用
|
||
|
||
1. 创建知识库时候选择 M3E 模型。
|
||
|
||
注意,一旦选择后,知识库将无法修改向量模型。
|
||
|
||

|
||
|
||
2. 导入数据
|
||
3. 搜索测试
|
||
|
||

|
||
|
||
4. 应用绑定知识库
|
||
|
||
注意,应用只能绑定同一个向量模型的知识库,不能跨模型绑定。并且,需要注意调整相似度,不同向量模型的相似度(距离)会有所区别,需要自行测试实验。
|
||
|
||

|
||
|
||
# 接入 Marker PDF 文档解析
|
||
## 使用 Marker 解析 PDF 文档,可实现图片提取和布局识别
|
||
|
||
## 背景
|
||
|
||
PDF 是一个相对复杂的文件格式,在 FastGPT 内置的 pdf 解析器中,依赖的是 pdfjs 库解析,该库基于逻辑解析,无法有效的理解复杂的 pdf 文件。所以我们在解析 pdf 时候,如果遇到图片、表格、公式等非简单文本内容,会发现解析效果不佳。
|
||
|
||
市面上目前有多种解析 PDF 的方法,比如使用 [Marker](https://github.com/VikParuchuri/marker),该项目使用了 Surya 模型,基于视觉解析,可以有效提取图片、表格、公式等复杂内容。
|
||
|
||
在 `FastGPT v4.9.0` 版本中,开源版用户可以在`config.json`文件中添加`systemEnv.customPdfParse`配置,来使用 Marker 解析 PDF 文件。商业版用户直接在 Admin 后台根据表单指引填写即可。需重新拉取 Marker 镜像,接口格式已变动。
|
||
|
||
## 使用教程
|
||
|
||
### 1. 安装 Marker
|
||
|
||
参考文档 [Marker 安装教程](https://github.com/labring/FastGPT/tree/main/plugins/model/pdf-marker),安装 Marker 模型。封装的 API 已经适配了 FastGPT 自定义解析服务。
|
||
|
||
这里介绍快速 Docker 安装的方法:
|
||
|
||
```dockerfile
|
||
docker pull crpi-h3snc261q1dosroc.cn-hangzhou.personal.cr.aliyuncs.com/marker11/marker_images:v0.2
|
||
docker run --gpus all -itd -p 7231:7232 --name model_pdf_v2 -e PROCESSES_PER_GPU="2" crpi-h3snc261q1dosroc.cn-hangzhou.personal.cr.aliyuncs.com/marker11/marker_images:v0.2
|
||
```
|
||
### 2. 添加 FastGPT 文件配置
|
||
|
||
```json
|
||
{
|
||
xxx
|
||
"systemEnv": {
|
||
xxx
|
||
"customPdfParse": {
|
||
"url": "http://xxxx.com/v2/parse/file", // 自定义 PDF 解析服务地址 marker v0.2
|
||
"key": "", // 自定义 PDF 解析服务密钥
|
||
"doc2xKey": "", // doc2x 服务密钥
|
||
"price": 0 // PDF 解析服务价格
|
||
}
|
||
}
|
||
}
|
||
```
|
||
|
||
需要重启服务。
|
||
|
||
### 3. 测试效果
|
||
|
||
通过知识库上传一个 pdf 文件,并勾选上 `PDF 增强解析`。
|
||
|
||

|
||
|
||
确认上传后,可以在日志中看到 LOG (LOG_LEVEL需要设置 info 或者 debug):
|
||
|
||
```
|
||
[Info] 2024-12-05 15:04:42 Parsing files from an external service
|
||
[Info] 2024-12-05 15:07:08 Custom file parsing is complete, time: 1316ms
|
||
```
|
||
|
||
然后你就可以发现,通过 Marker 解析出来的 pdf 会携带图片链接:
|
||
|
||

|
||
|
||
同样的,在应用中,你可以在文件上传配置里,勾选上 `PDF 增强解析`。
|
||
|
||

|
||
|
||
|
||
## 效果展示
|
||
|
||
以清华的 [ChatDev Communicative Agents for Software Develop.pdf](https://arxiv.org/abs/2307.07924) 为例,展示 Marker 解析的效果:
|
||
|
||
| | | |
|
||
| --- | --- | --- |
|
||
|  |  |  |
|
||
|  |  |  |
|
||
|
||
上图是分块后的结果,下图是 pdf 原文。整体图片、公式、表格都可以提取出来,效果还是杠杠的。
|
||
|
||
不过要注意的是,[Marker](https://github.com/VikParuchuri/marker) 的协议是`GPL-3.0 license`,请在遵守协议的前提下使用。
|
||
|
||
## 旧版 Marker 使用方法
|
||
|
||
FastGPT V4.9.0 版本之前,可以用以下方式,试用 Marker 解析服务。
|
||
|
||
安装和运行 Marker 服务:
|
||
|
||
```dockerfile
|
||
docker pull crpi-h3snc261q1dosroc.cn-hangzhou.personal.cr.aliyuncs.com/marker11/marker_images:v0.1
|
||
docker run --gpus all -itd -p 7231:7231 --name model_pdf_v1 -e PROCESSES_PER_GPU="2" crpi-h3snc261q1dosroc.cn-hangzhou.personal.cr.aliyuncs.com/marker11/marker_images:v0.1
|
||
```
|
||
|
||
并修改 FastGPT 环境变量:
|
||
|
||
```
|
||
CUSTOM_READ_FILE_URL=http://xxxx.com/v1/parse/file
|
||
CUSTOM_READ_FILE_EXTENSION=pdf
|
||
```
|
||
|
||
* CUSTOM_READ_FILE_URL - 自定义解析服务的地址, host改成解析服务的访问地址,path 不能变动。
|
||
* CUSTOM_READ_FILE_EXTENSION - 支持的文件后缀,多个文件类型,可用逗号隔开。
|
||
|
||
# 使用 Ollama 接入本地模型
|
||
## 采用 Ollama 部署自己的模型
|
||
|
||
[Ollama](https://ollama.com/) 是一个开源的AI大模型部署工具,专注于简化大语言模型的部署和使用,支持一键下载和运行各种大模型。
|
||
|
||
## 安装 Ollama
|
||
|
||
Ollama 本身支持多种安装方式,但是推荐使用 Docker 拉取镜像部署。如果是个人设备上安装了 Ollama 后续需要解决如何让 Docker 中 FastGPT 容器访问宿主机 Ollama的问题,较为麻烦。
|
||
|
||
### Docker 安装(推荐)
|
||
|
||
你可以使用 Ollama 官方的 Docker 镜像来一键安装和启动 Ollama 服务(确保你的机器上已经安装了 Docker),命令如下:
|
||
|
||
```bash
|
||
docker pull ollama/ollama
|
||
docker run --rm -d --name ollama -p 11434:11434 ollama/ollama
|
||
```
|
||
|
||
如果你的 FastGPT 是在 Docker 中进行部署的,建议在拉取 Ollama 镜像时保证和 FastGPT 镜像处于同一网络,否则可能出现 FastGPT 无法访问的问题,命令如下:
|
||
|
||
```bash
|
||
docker run --rm -d --name ollama --network (你的 Fastgpt 容器所在网络) -p 11434:11434 ollama/ollama
|
||
```
|
||
|
||
### 主机安装
|
||
|
||
如果你不想使用 Docker ,也可以采用主机安装,以下是主机安装的一些方式。
|
||
|
||
#### MacOS
|
||
|
||
如果你使用的是 macOS,且系统中已经安装了 Homebrew 包管理器,可通过以下命令来安装 Ollama:
|
||
|
||
```bash
|
||
brew install ollama
|
||
ollama serve #安装完成后,使用该命令启动服务
|
||
```
|
||
|
||
#### Linux
|
||
|
||
在 Linux 系统上,你可以借助包管理器来安装 Ollama。以 Ubuntu 为例,在终端执行以下命令:
|
||
|
||
```bash
|
||
curl https://ollama.com/install.sh | sh #此命令会从官方网站下载并执行安装脚本。
|
||
ollama serve #安装完成后,同样启动服务
|
||
```
|
||
|
||
#### Windows
|
||
|
||
在 Windows 系统中,你可以从 Ollama 官方网站 下载 Windows 版本的安装程序。下载完成后,运行安装程序,按照安装向导的提示完成安装。安装完成后,在命令提示符或 PowerShell 中启动服务:
|
||
|
||
```bash
|
||
ollama serve #安装完成并启动服务后,你可以在浏览器中访问 http://localhost:11434 来验证 Ollama 是否安装成功。
|
||
```
|
||
|
||
#### 补充说明
|
||
|
||
如果你是采用的主机应用 Ollama 而不是镜像,需要确保你的 Ollama 可以监听0.0.0.0。
|
||
|
||
##### 1. Linxu 系统
|
||
|
||
如果 Ollama 作为 systemd 服务运行,打开终端,编辑 Ollama 的 systemd 服务文件,使用命令sudo systemctl edit ollama.service,在[Service]部分添加Environment="OLLAMA_HOST=0.0.0.0"。保存并退出编辑器,然后执行sudo systemctl daemon - reload和sudo systemctl restart ollama使配置生效。
|
||
|
||
##### 2. MacOS 系统
|
||
|
||
打开终端,使用launchctl setenv ollama_host "0.0.0.0"命令设置环境变量,然后重启 Ollama 应用程序以使更改生效。
|
||
|
||
##### 3. Windows 系统
|
||
|
||
通过 “开始” 菜单或搜索栏打开 “编辑系统环境变量”,在 “系统属性” 窗口中点击 “环境变量”,在 “系统变量” 部分点击 “新建”,创建一个名为OLLAMA_HOST的变量,变量值设置为0.0.0.0,点击 “确定” 保存更改,最后从 “开始” 菜单重启 Ollama 应用程序。
|
||
|
||
### Ollama 拉取模型镜像
|
||
|
||
在安装 Ollama 后,本地是没有模型镜像的,需要自己去拉取 Ollama 中的模型镜像。命令如下:
|
||
|
||
```bash
|
||
# Docker 部署需要先进容器,命令为: docker exec -it < Ollama 容器名 > /bin/sh
|
||
ollama pull <模型名>
|
||
```
|
||
|
||

|
||
|
||
|
||
### 测试通信
|
||
|
||
在安装完成后,需要进行检测测试,首先进入 FastGPT 所在的容器,尝试访问自己的 Ollama ,命令如下:
|
||
|
||
```bash
|
||
docker exec -it < FastGPT 所在的容器名 > /bin/sh
|
||
curl http://XXX.XXX.XXX.XXX:11434 #容器部署地址为“http://<容器名>:<端口>”,主机安装地址为"http://<主机IP>:<端口>",主机IP不可为localhost
|
||
```
|
||
|
||
看到访问显示自己的 Ollama 服务以及启动,说明可以正常通信。
|
||
|
||
## 将 Ollama 接入 FastGPT
|
||
|
||
### 1. 查看 Ollama 所拥有的模型
|
||
|
||
首先采用下述命令查看 Ollama 中所拥有的模型,
|
||
|
||
```bash
|
||
# Docker 部署 Ollama,需要此命令 docker exec -it < Ollama 容器名 > /bin/sh
|
||
ollama ls
|
||
```
|
||
|
||

|
||
|
||
### 2. AI Proxy 接入
|
||
|
||
如果你采用的是 FastGPT 中的默认配置文件部署[这里](/docs/development/docker.md),即默认采用 AI Proxy 进行启动。
|
||
|
||

|
||
|
||
以及在确保你的 FastGPT 可以直接访问 Ollama 容器的情况下,无法访问,参考上文[点此跳转](#安装-ollama)的安装过程,检测是不是主机不能监测0.0.0.0,或者容器不在同一个网络。
|
||
|
||

|
||
|
||
在 FastGPT 中点击账号->模型提供商->模型配置->新增模型,添加自己的模型即可,添加模型时需要保证模型ID和 OneAPI 中的模型名称一致。详细参考[这里](/docs/development/modelConfig/intro.md)
|
||
|
||

|
||
|
||

|
||
|
||
运行 FastGPT ,在页面中选择账号->模型提供商->模型渠道->新增渠道。之后,在渠道选择中选择 Ollama ,然后加入自己拉取的模型,填入代理地址,如果是容器中安装 Ollama ,代理地址为http://地址:端口,补充:容器部署地址为“http://<容器名>:<端口>”,主机安装地址为"http://<主机IP>:<端口>",主机IP不可为localhost
|
||
|
||

|
||
|
||
在工作台中创建一个应用,选择自己之前添加的模型,此处模型名称为自己当时设置的别名。注:同一个模型无法多次添加,系统会采取最新添加时设置的别名。
|
||
|
||

|
||
|
||
### 3. OneAPI 接入
|
||
|
||
如果你想使用 OneAPI ,首先需要拉取 OneAPI 镜像,然后将其在 FastGPT 容器的网络中运行。具体命令如下:
|
||
|
||
```bash
|
||
# 拉取 oneAPI 镜像
|
||
docker pull intel/oneapi-hpckit
|
||
|
||
# 运行容器并指定自定义网络和容器名
|
||
docker run -it --network < FastGPT 网络 > --name 容器名 intel/oneapi-hpckit /bin/bash
|
||
```
|
||
|
||
进入 OneAPI 页面,添加新的渠道,类型选择 Ollama ,在模型中填入自己 Ollama 中的模型,需要保证添加的模型名称和 Ollama 中一致,再在下方填入自己的 Ollama 代理地址,默认http://地址:端口,不需要填写/v1。添加成功后在 OneAPI 进行渠道测试,测试成功则说明添加成功。此处演示采用的是 Docker 部署 Ollama 的效果,主机 Ollama需要修改代理地址为http://<主机IP>:<端口>
|
||
|
||

|
||
|
||
渠道添加成功后,点击令牌,点击添加令牌,填写名称,修改配置。
|
||
|
||

|
||
|
||
修改部署 FastGPT 的 docker-compose.yml 文件,在其中将 AI Proxy 的使用注释,在 OPENAI_BASE_URL 中加入自己的 OneAPI 开放地址,默认是http://地址:端口/v1,v1必须填写。KEY 中填写自己在 OneAPI 的令牌。
|
||
|
||

|
||
|
||
[直接跳转5](#5-模型添加和使用)添加模型,并使用。
|
||
|
||
### 4. 直接接入
|
||
|
||
如果你既不想使用 AI Proxy,也不想使用 OneAPI,也可以选择直接接入,修改部署 FastGPT 的 docker-compose.yml 文件,在其中将 AI Proxy 的使用注释,采用和 OneAPI 的类似配置。注释掉 AIProxy 相关代码,在OPENAI_BASE_URL中加入自己的 Ollama 开放地址,默认是http://地址:端口/v1,强调:v1必须填写。在KEY中随便填入,因为 Ollama 默认没有鉴权,如果开启鉴权,请自行填写。其他操作和在 OneAPI 中加入 Ollama 一致,只需在 FastGPT 中加入自己的模型即可使用。此处演示采用的是 Docker 部署 Ollama 的效果,主机 Ollama需要修改代理地址为http://<主机IP>:<端口>
|
||
|
||

|
||
|
||
完成后[点击这里](#5-模型添加和使用)进行模型添加并使用。
|
||
|
||
### 5. 模型添加和使用
|
||
|
||
在 FastGPT 中点击账号->模型提供商->模型配置->新增模型,添加自己的模型即可,添加模型时需要保证模型ID和 OneAPI 中的模型名称一致。
|
||
|
||

|
||
|
||

|
||
|
||
在工作台中创建一个应用,选择自己之前添加的模型,此处模型名称为自己当时设置的别名。注:同一个模型无法多次添加,系统会采取最新添加时设置的别名。
|
||
|
||

|
||
|
||
### 6. 补充
|
||
上述接入 Ollama 的代理地址中,主机安装 Ollama 的地址为“http://<主机IP>:<端口>”,容器部署 Ollama 地址为“http://<容器名>:<端口>”
|
||
|
||
# 使用 Xinference 接入本地模型
|
||
## 一站式本地 LLM 私有化部署
|
||
|
||
[Xinference](https://github.com/xorbitsai/inference) 是一款开源模型推理平台,除了支持 LLM,它还可以部署 Embedding 和 ReRank 模型,这在企业级 RAG 构建中非常关键。同时,Xinference 还提供 Function Calling 等高级功能。还支持分布式部署,也就是说,随着未来应用调用量的增长,它可以进行水平扩展。
|
||
|
||
## 安装 Xinference
|
||
|
||
Xinference 支持多种推理引擎作为后端,以满足不同场景下部署大模型的需要,下面会分使用场景来介绍一下这三种推理后端,以及他们的使用方法。
|
||
|
||
### 1. 服务器
|
||
|
||
如果你的目标是在一台 Linux 或者 Window 服务器上部署大模型,可以选择 Transformers 或 vLLM 作为 Xinference 的推理后端:
|
||
|
||
+ [Transformers](https://huggingface.co/docs/transformers/index):通过集成 Huggingface 的 Transformers 库作为后端,Xinference 可以最快地 集成当今自然语言处理(NLP)领域的最前沿模型(自然也包括 LLM)。
|
||
+ [vLLM](https://vllm.ai/): vLLM 是由加州大学伯克利分校开发的一个开源库,专为高效服务大型语言模型(LLM)而设计。它引入了 PagedAttention 算法, 通过有效管理注意力键和值来改善内存管理,吞吐量能够达到 Transformers 的 24 倍,因此 vLLM 适合在生产环境中使用,应对高并发的用户访问。
|
||
|
||
假设你服务器配备 NVIDIA 显卡,可以参考[这篇文章中的指令来安装 CUDA](https://xorbits.cn/blogs/langchain-streamlit-doc-chat),从而让 Xinference 最大限度地利用显卡的加速功能。
|
||
|
||
#### Docker 部署
|
||
|
||
你可以使用 Xinference 官方的 Docker 镜像来一键安装和启动 Xinference 服务(确保你的机器上已经安装了 Docker),命令如下:
|
||
|
||
```bash
|
||
docker run -p 9997:9997 --gpus all xprobe/xinference:latest xinference-local -H 0.0.0.0
|
||
```
|
||
|
||
#### 直接部署
|
||
|
||
首先我们需要准备一个 3.9 以上的 Python 环境运行来 Xinference,建议先根据 conda 官网文档安装 conda。 然后使用以下命令来创建 3.11 的 Python 环境:
|
||
|
||
```bash
|
||
conda create --name py311 python=3.11
|
||
conda activate py311
|
||
```
|
||
|
||
以下两条命令在安装 Xinference 时,将安装 Transformers 和 vLLM 作为 Xinference 的推理引擎后端:
|
||
|
||
```bash
|
||
pip install "xinference[transformers]"
|
||
pip install "xinference[vllm]"
|
||
pip install "xinference[transformers,vllm]" # 同时安装
|
||
```
|
||
|
||
PyPi 在 安装 Transformers 和 vLLM 时会自动安装 PyTorch,但自动安装的 CUDA 版本可能与你的环境不匹配,此时你可以根据 PyTorch 官网中的[安装指南](https://pytorch.org/get-started/locally/)来手动安装。
|
||
|
||
只需要输入如下命令,就可以在服务上启动 Xinference 服务:
|
||
|
||
```bash
|
||
xinference-local -H 0.0.0.0
|
||
```
|
||
|
||
Xinference 默认会在本地启动服务,端口默认为 9997。因为这里配置了-H 0.0.0.0参数,非本地客户端也可以通过机器的 IP 地址来访问 Xinference 服务。
|
||
|
||
### 2. 个人设备
|
||
|
||
如果你想在自己的 Macbook 或者个人电脑上部署大模型,推荐安装 CTransformers 作为 Xinference 的推理后端。CTransformers 是用 GGML 实现的 C++ 版本 Transformers。
|
||
|
||
[GGML](https://ggml.ai/) 是一个能让大语言模型在[消费级硬件上运行](https://github.com/ggerganov/llama.cpp/discussions/205)的 C++ 库。 GGML 最大的特色在于模型量化。量化一个大语言模型其实就是降低权重表示精度的过程,从而减少使用模型所需的资源。 例如,表示一个高精度浮点数(例如 0.0001)比表示一个低精度浮点数(例如 0.1)需要更多空间。由于 LLM 在推理时需要加载到内存中的,因此你需要花费硬盘空间来存储它们,并且在执行期间有足够大的 RAM 来加载它们,GGML 支持许多不同的量化策略,每种策略在效率和性能之间提供不同的权衡。
|
||
|
||
通过以下命令来安装 CTransformers 作为 Xinference 的推理后端:
|
||
|
||
```bash
|
||
pip install xinference
|
||
pip install ctransformers
|
||
```
|
||
|
||
因为 GGML 是一个 C++ 库,Xinference 通过 `llama-cpp-python` 这个库来实现语言绑定。对于不同的硬件平台,我们需要使用不同的编译参数来安装:
|
||
|
||
- Apple Metal(MPS):`CMAKE_ARGS="-DLLAMA_METAL=on" pip install llama-cpp-python`
|
||
- Nvidia GPU:`CMAKE_ARGS="-DLLAMA_CUBLAS=on" pip install llama-cpp-python`
|
||
- AMD GPU:`CMAKE_ARGS="-DLLAMA_HIPBLAS=on" pip install llama-cpp-python`
|
||
|
||
安装后只需要输入 `xinference-local`,就可以在你的 Mac 上启动 Xinference 服务。
|
||
|
||
## 创建并部署模型(以 Qwen-14B 模型为例)
|
||
|
||
### 1. WebUI 方式启动模型
|
||
|
||
Xinference 启动之后,在浏览器中输入: `http://127.0.0.1:9997`,我们可以访问到本地 Xinference 的 Web UI。
|
||
|
||
打开“Launch Model”标签,搜索到 qwen-chat,选择模型启动的相关参数,然后点击模型卡片左下方的小火箭🚀按钮,就可以部署该模型到 Xinference。 默认 Model UID 是 qwen-chat(后续通过将通过这个 ID 来访问模型)。
|
||
|
||

|
||
|
||
当你第一次启动 Qwen 模型时,Xinference 会从 HuggingFace 下载模型参数,大概需要几分钟的时间。Xinference 将模型文件缓存在本地,这样之后启动时就不需要重新下载了。 Xinference 还支持从其他模型站点下载模型文件,例如 [modelscope](https://inference.readthedocs.io/en/latest/models/sources/sources.html)。
|
||
|
||
### 2. 命令行方式启动模型
|
||
|
||
我们也可以使用 Xinference 的命令行工具来启动模型,默认 Model UID 是 qwen-chat(后续通过将通过这个 ID 来访问模型)。
|
||
|
||
```bash
|
||
xinference launch -n qwen-chat -s 14 -f pytorch
|
||
```
|
||
|
||
除了 WebUI 和命令行工具, Xinference 还提供了 Python SDK 和 RESTful API 等多种交互方式, 更多用法可以参考 [Xinference 官方文档](https://inference.readthedocs.io/en/latest/getting_started/index.html)。
|
||
|
||
## 将本地模型接入 One API
|
||
|
||
One API 的部署和接入请参考[这里](/docs/development/modelconfig/one-api/)。
|
||
|
||
为 qwen1.5-chat 添加一个渠道,这里的 Base URL 需要填 Xinference 服务的端点,并且注册 qwen-chat (模型的 UID) 。
|
||
|
||

|
||
|
||
可以使用以下命令进行测试:
|
||
|
||
```bash
|
||
curl --location --request POST 'https://<oneapi_url>/v1/chat/completions' \
|
||
--header 'Authorization: Bearer <oneapi_token>' \
|
||
--header 'Content-Type: application/json' \
|
||
--data-raw '{
|
||
"model": "qwen-chat",
|
||
"messages": [{"role": "user", "content": "Hello!"}]
|
||
}'
|
||
```
|
||
|
||
将 <oneapi_url> 替换为你的 One API 地址,<oneapi_token> 替换为你的 One API 令牌。model 为刚刚在 One API 填写的自定义模型。
|
||
|
||
## 将本地模型接入 FastGPT
|
||
|
||
修改 FastGPT 的 `config.json` 配置文件的 llmModels 部分加入 qwen-chat 模型:
|
||
|
||
```json
|
||
...
|
||
"llmModels": [
|
||
{
|
||
"model": "qwen-chat", // 模型名(对应OneAPI中渠道的模型名)
|
||
"name": "Qwen", // 模型别名
|
||
"avatar": "/imgs/model/Qwen.svg", // 模型的logo
|
||
"maxContext": 125000, // 最大上下文
|
||
"maxResponse": 4000, // 最大回复
|
||
"quoteMaxToken": 120000, // 最大引用内容
|
||
"maxTemperature": 1.2, // 最大温度
|
||
"charsPointsPrice": 0, // n积分/1k token(商业版)
|
||
"censor": false, // 是否开启敏感校验(商业版)
|
||
"vision": true, // 是否支持图片输入
|
||
"datasetProcess": true, // 是否设置为知识库处理模型(QA),务必保证至少有一个为true,否则知识库会报错
|
||
"usedInClassify": true, // 是否用于问题分类(务必保证至少有一个为true)
|
||
"usedInExtractFields": true, // 是否用于内容提取(务必保证至少有一个为true)
|
||
"usedInToolCall": true, // 是否用于工具调用(务必保证至少有一个为true)
|
||
"toolChoice": true, // 是否支持工具选择(分类,内容提取,工具调用会用到。)
|
||
"functionCall": false, // 是否支持函数调用(分类,内容提取,工具调用会用到。会优先使用 toolChoice,如果为false,则使用 functionCall,如果仍为 false,则使用提示词模式)
|
||
"customCQPrompt": "", // 自定义文本分类提示词(不支持工具和函数调用的模型
|
||
"customExtractPrompt": "", // 自定义内容提取提示词
|
||
"defaultSystemChatPrompt": "", // 对话默认携带的系统提示词
|
||
"defaultConfig": {} // 请求API时,挟带一些默认配置(比如 GLM4 的 top_p)
|
||
}
|
||
],
|
||
...
|
||
```
|
||
|
||
然后重启 FastGPT 就可以在应用配置中选择 Qwen 模型进行对话:
|
||
|
||

|
||
|
||
---
|
||
|
||
+ 参考:[FastGPT + Xinference:一站式本地 LLM 私有化部署和应用开发](https://xorbits.cn/blogs/fastgpt-weather-chat)
|
||
|
||
# 数据集
|
||
## FastGPT 数据集中文件与数据的设计方案
|
||
|
||
## 文件与数据的关系
|
||
|
||
在 FastGPT 中,文件会通过 MongoDB 的 FS 存储,而具体的数据会通过 PostgreSQL 存储,PG 中的数据会有一列 file_id,关联对应的文件。考虑到旧版本的兼容,以及手动输入、标注数据等,我们给 file_id 增加了一些特殊的值,如下:
|
||
|
||
- manual: 手动输入
|
||
- mark: 手动标注的数据
|
||
|
||
注意,file_id 仅在插入数据时会写入,变更时无法修改。
|
||
|
||
## 文件导入流程
|
||
|
||
1. 上传文件到 MongoDB 的 FS 中,获取 file_id,此时文件标记为 `unused` 状态
|
||
2. 浏览器解析文件,获取对应的文本和 chunk
|
||
3. 给每个 chunk 打上 file_id
|
||
4. 点击上传数据:将文件的状态改为 `used`,并将数据推送到 mongo `training` 表中等待训练
|
||
5. 由训练线程从 mongo 中取数据,并在获取向量后插入到 pg。
|
||
|
||
# Docker Compose 快速部署
|
||
## 使用 Docker Compose 快速部署 FastGPT
|
||
|
||
## 前置知识
|
||
|
||
1. 基础的网络知识:端口,防火墙……
|
||
2. Docker 和 Docker Compose 基础知识
|
||
3. 大模型相关接口和参数
|
||
4. RAG 相关知识:向量模型,向量数据库,向量检索
|
||
|
||
## 部署架构图
|
||
|
||

|
||
|
||
{{% alert icon="🤖" context="success" %}}
|
||
|
||
- MongoDB:用于存储除了向量外的各类数据
|
||
- PostgreSQL/Milvus:存储向量数据
|
||
- OneAPI: 聚合各类 AI API,支持多模型调用 (任何模型问题,先自行通过 OneAPI 测试校验)
|
||
|
||
{{% /alert %}}
|
||
|
||
## 推荐配置
|
||
|
||
### PgVector版本
|
||
|
||
非常轻量,适合知识库索引量在 5000 万以下。
|
||
|
||
{{< table "table-hover table-striped-columns" >}}
|
||
| 环境 | 最低配置(单节点) | 推荐配置 |
|
||
| ---- | ---- | ---- |
|
||
| 测试(可以把计算进程设置少一些) | 2c4g | 2c8g |
|
||
| 100w 组向量 | 4c8g 50GB | 4c16g 50GB |
|
||
| 500w 组向量 | 8c32g 200GB | 16c64g 200GB |
|
||
{{< /table >}}
|
||
|
||
### Milvus版本
|
||
|
||
对于亿级以上向量性能更优秀。
|
||
|
||
[点击查看 Milvus 官方推荐配置](https://milvus.io/docs/prerequisite-docker.md)
|
||
|
||
{{< table "table-hover table-striped-columns" >}}
|
||
| 环境 | 最低配置(单节点) | 推荐配置 |
|
||
| ---- | ---- | ---- |
|
||
| 测试 | 2c8g | 4c16g |
|
||
| 100w 组向量 | 未测试 | |
|
||
| 500w 组向量 | | |
|
||
{{< /table >}}
|
||
|
||
### zilliz cloud版本
|
||
|
||
Zilliz Cloud 由 Milvus 原厂打造,是全托管的 SaaS 向量数据库服务,性能优于 Milvus 并提供 SLA,点击使用 [Zilliz Cloud](https://zilliz.com.cn/)。
|
||
|
||
由于向量库使用了 Cloud,无需占用本地资源,无需太关注。
|
||
|
||
## 前置工作
|
||
|
||
### 1. 确保网络环境
|
||
|
||
如果使用`OpenAI`等国外模型接口,请确保可以正常访问,否则会报错:`Connection error` 等。 方案可以参考:[代理方案](/docs/development/proxy/)
|
||
|
||
### 2. 准备 Docker 环境
|
||
|
||
{{< tabs tabTotal="3" >}}
|
||
{{< tab tabName="Linux" >}}
|
||
{{< markdownify >}}
|
||
|
||
```bash
|
||
# 安装 Docker
|
||
curl -fsSL https://get.docker.com | bash -s docker --mirror Aliyun
|
||
systemctl enable --now docker
|
||
# 安装 docker-compose
|
||
curl -L https://github.com/docker/compose/releases/download/v2.20.3/docker-compose-`uname -s`-`uname -m` -o /usr/local/bin/docker-compose
|
||
chmod +x /usr/local/bin/docker-compose
|
||
# 验证安装
|
||
docker -v
|
||
docker-compose -v
|
||
# 如失效,自行百度~
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
{{< tab tabName="MacOS" >}}
|
||
{{< markdownify >}}
|
||
推荐直接使用 [Orbstack](https://orbstack.dev/)。可直接通过 Homebrew 来安装:
|
||
|
||
```bash
|
||
brew install orbstack
|
||
```
|
||
|
||
或者直接[下载安装包](https://orbstack.dev/download)进行安装。
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
{{< tab tabName="Windows" >}}
|
||
{{< markdownify >}}
|
||
|
||
我们建议将源代码和其他数据绑定到 Linux 容器中时,将其存储在 Linux 文件系统中,而不是 Windows 文件系统中。
|
||
|
||
可以选择直接[使用 WSL 2 后端在 Windows 中安装 Docker Desktop](https://docs.docker.com/desktop/wsl/)。
|
||
|
||
也可以直接[在 WSL 2 中安装命令行版本的 Docker](https://nickjanetakis.com/blog/install-docker-in-wsl-2-without-docker-desktop)。
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
{{< /tabs >}}
|
||
|
||
## 开始部署
|
||
|
||
### 1. 下载 docker-compose.yml
|
||
|
||
非 Linux 环境或无法访问外网环境,可手动创建一个目录,并下载配置文件和对应版本的`docker-compose.yml`,在这个文件夹中依据下载的配置文件运行docker,若作为本地开发使用推荐`docker-compose-pgvector`版本,并且自行拉取并运行`sandbox`和`fastgpt`,并在docker配置文件中注释掉`sandbox`和`fastgpt`的部分
|
||
|
||
- [config.json](https://raw.githubusercontent.com/labring/FastGPT/refs/heads/main/projects/app/data/config.json)
|
||
- [docker-compose.yml](https://github.com/labring/FastGPT/blob/main/deploy/docker) (注意,不同向量库版本的文件不一样)
|
||
|
||
{{% alert icon="🤖" context="success" %}}
|
||
|
||
所有 `docker-compose.yml` 配置文件中 `MongoDB` 为 5.x,需要用到AVX指令集,部分 CPU 不支持,需手动更改其镜像版本为 4.4.24**(需要自己在docker hub下载,阿里云镜像没做备份)
|
||
|
||
{{% /alert %}}
|
||
|
||
**Linux 快速脚本**
|
||
|
||
```bash
|
||
mkdir fastgpt
|
||
cd fastgpt
|
||
curl -O https://raw.githubusercontent.com/labring/FastGPT/main/projects/app/data/config.json
|
||
|
||
# pgvector 版本(测试推荐,简单快捷)
|
||
curl -o docker-compose.yml https://raw.githubusercontent.com/labring/FastGPT/main/deploy/docker/docker-compose-pgvector.yml
|
||
# oceanbase 版本(需要将init.sql和docker-compose.yml放在同一个文件夹,方便挂载)
|
||
# curl -o docker-compose.yml https://raw.githubusercontent.com/labring/FastGPT/main/deploy/docker/docker-compose-oceanbase/docker-compose.yml
|
||
# curl -o init.sql https://raw.githubusercontent.com/labring/FastGPT/main/deploy/docker/docker-compose-oceanbase/init.sql
|
||
# milvus 版本
|
||
# curl -o docker-compose.yml https://raw.githubusercontent.com/labring/FastGPT/main/deploy/docker/docker-compose-milvus.yml
|
||
# zilliz 版本
|
||
# curl -o docker-compose.yml https://raw.githubusercontent.com/labring/FastGPT/main/deploy/docker/docker-compose-zilliz.yml
|
||
```
|
||
|
||
### 2. 修改环境变量
|
||
|
||
找到 yml 文件中,fastgpt 容器的环境变量进行下面操作:
|
||
|
||
{{< tabs tabTotal="3" >}}
|
||
{{< tab tabName="PgVector版本" >}}
|
||
{{< markdownify >}}
|
||
|
||
无需操作
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
{{< tab tabName="Oceanbase版本" >}}
|
||
{{< markdownify >}}
|
||
|
||
无需操作
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
{{< tab tabName="Milvus版本" >}}
|
||
{{< markdownify >}}
|
||
|
||
无需操作
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
{{< tab tabName="Zilliz版本" >}}
|
||
{{< markdownify >}}
|
||
|
||
打开 [Zilliz Cloud](https://zilliz.com.cn/), 创建实例并获取相关秘钥。
|
||
|
||

|
||
|
||
{{% alert icon="🤖" context="success" %}}
|
||
|
||
1. 修改`MILVUS_ADDRESS`和`MILVUS_TOKEN`链接参数,分别对应 `zilliz` 的 `Public Endpoint` 和 `Api key`,记得把自己ip加入白名单。
|
||
|
||
{{% /alert %}}
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
{{< /tabs >}}
|
||
|
||
### 3. 启动容器
|
||
|
||
在 docker-compose.yml 同级目录下执行。请确保`docker-compose`版本最好在2.17以上,否则可能无法执行自动化命令。
|
||
|
||
```bash
|
||
# 启动容器
|
||
docker-compose up -d
|
||
```
|
||
|
||
### 4. 访问 FastGPT
|
||
|
||
目前可以通过 `ip:3000` 直接访问(注意开放防火墙)。登录用户名为 `root`,密码为`docker-compose.yml`环境变量里设置的 `DEFAULT_ROOT_PSW`。
|
||
|
||
如果需要域名访问,请自行安装并配置 Nginx。
|
||
|
||
首次运行,会自动初始化 root 用户,密码为 `1234`(与环境变量中的`DEFAULT_ROOT_PSW`一致),日志可能会提示一次`MongoServerError: Unable to read from a snapshot due to pending collection catalog changes;`可忽略。
|
||
|
||
### 5. 配置模型
|
||
|
||
- 首次登录FastGPT后,系统会提示未配置`语言模型`和`索引模型`,并自动跳转模型配置页面。系统必须至少有这两类模型才能正常使用。
|
||
- 如果系统未正常跳转,可以在`账号-模型提供商`页面,进行模型配置。[点击查看相关教程](/docs/development/modelconfig/ai-proxy)
|
||
- 目前已知可能问题:首次进入系统后,整个浏览器 tab 无法响应。此时需要删除该tab,重新打开一次即可。
|
||
|
||
## FAQ
|
||
|
||
### 登录系统后,浏览器无法响应
|
||
|
||
无法点击任何内容,刷新也无效。此时需要删除该tab,重新打开一次即可。
|
||
|
||
### Mongo 副本集自动初始化失败
|
||
|
||
最新的 docker-compose 示例优化 Mongo 副本集初始化,实现了全自动。目前在 unbuntu20,22 centos7, wsl2, mac, window 均通过测试。仍无法正常启动,大部分是因为 cpu 不支持 AVX 指令集,可以切换 Mongo4.x 版本。
|
||
|
||
如果是由于,无法自动初始化副本集合,可以手动初始化副本集:
|
||
|
||
1. 终端中执行下面命令,创建mongo密钥:
|
||
|
||
```bash
|
||
openssl rand -base64 756 > ./mongodb.key
|
||
chmod 600 ./mongodb.key
|
||
# 修改密钥权限,部分系统是admin,部分是root
|
||
chown 999:root ./mongodb.key
|
||
```
|
||
|
||
2. 修改 docker-compose.yml,挂载密钥
|
||
|
||
```yml
|
||
mongo:
|
||
# image: mongo:5.0.18
|
||
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/mongo:5.0.18 # 阿里云
|
||
container_name: mongo
|
||
ports:
|
||
- 27017:27017
|
||
networks:
|
||
- fastgpt
|
||
command: mongod --keyFile /data/mongodb.key --replSet rs0
|
||
environment:
|
||
# 默认的用户名和密码,只有首次允许有效
|
||
- MONGO_INITDB_ROOT_USERNAME=myusername
|
||
- MONGO_INITDB_ROOT_PASSWORD=mypassword
|
||
volumes:
|
||
- ./mongo/data:/data/db
|
||
- ./mongodb.key:/data/mongodb.key
|
||
```
|
||
|
||
3. 重启服务
|
||
|
||
```bash
|
||
docker-compose down
|
||
docker-compose up -d
|
||
```
|
||
|
||
4. 进入容器执行副本集合初始化
|
||
|
||
```bash
|
||
# 查看 mongo 容器是否正常运行
|
||
docker ps
|
||
# 进入容器
|
||
docker exec -it mongo bash
|
||
|
||
# 连接数据库(这里要填Mongo的用户名和密码)
|
||
mongo -u myusername -p mypassword --authenticationDatabase admin
|
||
|
||
# 初始化副本集。如果需要外网访问,mongo:27017 。如果需要外网访问,需要增加Mongo连接参数:directConnection=true
|
||
rs.initiate({
|
||
_id: "rs0",
|
||
members: [
|
||
{ _id: 0, host: "mongo:27017" }
|
||
]
|
||
})
|
||
# 检查状态。如果提示 rs0 状态,则代表运行成功
|
||
rs.status()
|
||
```
|
||
|
||
### 如何修改API地址和密钥
|
||
|
||
默认是写了OneAPi的连接地址和密钥,可以通过修改`docker-compose.yml`中,fastgpt容器的环境变量实现。
|
||
|
||
`OPENAI_BASE_URL`(API 接口的地址,需要加/v1)
|
||
`CHAT_API_KEY`(API 接口的凭证)。
|
||
|
||
修改完后重启:
|
||
|
||
```bash
|
||
docker-compose down
|
||
docker-compose up -d
|
||
```
|
||
|
||
### 如何更新版本?
|
||
|
||
1. 查看[更新文档](/docs/development/upgrading/intro/),确认要升级的版本,避免跨版本升级。
|
||
2. 修改镜像 tag 到指定版本
|
||
3. 执行下面命令会自动拉取镜像:
|
||
|
||
```bash
|
||
docker-compose pull
|
||
docker-compose up -d
|
||
```
|
||
|
||
4. 执行初始化脚本(如果有)
|
||
|
||
### 如何自定义配置文件?
|
||
|
||
修改`config.json`文件,并执行`docker-compose down`再执行`docker-compose up -d`重起容器。具体配置,参考[配置详解](/docs/development/configuration)。
|
||
|
||
### 如何检查自定义配置文件是否挂载
|
||
|
||
1. `docker logs fastgpt` 可以查看日志,在启动容器后,第一次请求网页,会进行配置文件读取,可以看看有没有读取成功以及有无错误日志。
|
||
2. `docker exec -it fastgpt sh` 进入 FastGPT 容器,可以通过`ls data`查看目录下是否成功挂载`config.json`文件。可通过`cat data/config.json`查看配置文件。
|
||
|
||
**可能不生效的原因**
|
||
|
||
1. 挂载目录不正确
|
||
2. 配置文件不正确,日志中会提示`invalid json`,配置文件需要是标准的 JSON 文件。
|
||
3. 修改后,没有`docker-compose down`再`docker-compose up -d`,restart是不会重新挂载文件的。
|
||
|
||
### 如何检查环境变量是否正常加载
|
||
|
||
1. `docker exec -it fastgpt sh` 进入 FastGPT 容器。
|
||
2. 直接输入`env`命令查看所有环境变量。
|
||
|
||
### 为什么无法连接`本地模型`镜像
|
||
|
||
`docker-compose.yml`中使用了桥接的模式建立了`fastgpt`网络,如想通过0.0.0.0或镜像名访问其它镜像,需将其它镜像也加入到网络中。
|
||
|
||
### 端口冲突怎么解决?
|
||
|
||
docker-compose 端口定义为:`映射端口:运行端口`。
|
||
|
||
桥接模式下,容器运行端口不会有冲突,但是会有映射端口冲突,只需将映射端口修改成不同端口即可。
|
||
|
||
如果`容器1`需要连接`容器2`,使用`容器2:运行端口`来进行连接即可。
|
||
|
||
(自行补习 docker 基本知识)
|
||
|
||
### relation "modeldata" does not exist
|
||
|
||
PG 数据库没有连接上/初始化失败,可以查看日志。FastGPT 会在每次连接上 PG 时进行表初始化,如果报错会有对应日志。
|
||
|
||
1. 检查数据库容器是否正常启动
|
||
2. 非 docker 部署的,需要手动安装 pg vector 插件
|
||
3. 查看 fastgpt 日志,有没有相关报错
|
||
|
||
### Illegal instruction
|
||
|
||
可能原因:
|
||
|
||
1. arm架构。需要使用 Mongo 官方镜像: mongo:5.0.18
|
||
2. cpu 不支持 AVX,无法用 mongo5,需要换成 mongo4.x。把 mongo 的 image 换成: mongo:4.4.29
|
||
|
||
### Operation `auth_codes.findOne()` buffering timed out after 10000ms
|
||
|
||
mongo连接失败,查看mongo的运行状态**对应日志**。
|
||
|
||
可能原因:
|
||
|
||
1. mongo 服务有没有起来(有些 cpu 不支持 AVX,无法用 mongo5,需要换成 mongo4.x,可以docker hub找个最新的4.x,修改镜像版本,重新运行)
|
||
2. 连接数据库的环境变量填写错误(账号密码,注意host和port,非容器网络连接,需要用公网ip并加上 directConnection=true)
|
||
3. 副本集启动失败。导致容器一直重启。
|
||
4. `Illegal instruction.... Waiting for MongoDB to start`: cpu 不支持 AVX,无法用 mongo5,需要换成 mongo4.x
|
||
|
||
### 首次部署,root用户提示未注册
|
||
|
||
日志会有错误提示。大概率是没有启动 Mongo 副本集模式。
|
||
|
||
### 无法导出知识库、无法使用语音输入/播报
|
||
|
||
没配置 SSL 证书,无权使用部分功能。
|
||
|
||
### 登录提示 Network Error
|
||
|
||
由于服务初始化错误,系统重启导致。
|
||
|
||
- 90%是由于配置文件写不对,导致 JSON 解析报错
|
||
- 剩下的基本是因为向量数据库连不上
|
||
|
||
### 如何修改密码
|
||
|
||
修改`docker-compose.yml`文件中`DEFAULT_ROOT_PSW`并重启即可,密码会自动更新。
|
||
|
||
# 私有部署常见问题
|
||
## FastGPT 私有部署常见问题
|
||
|
||
## 一、错误排查方式
|
||
|
||
可以先找找[Issue](https://github.com/labring/FastGPT/issues),或新提 Issue,私有部署错误,务必提供详细的操作步骤、日志、截图,否则很难排查。
|
||
|
||
### 获取后端错误
|
||
|
||
1. `docker ps -a` 查看所有容器运行状态,检查是否全部 running,如有异常,尝试`docker logs 容器名`查看对应日志。
|
||
2. 容器都运行正常的,`docker logs 容器名` 查看报错日志
|
||
|
||
### 前端错误
|
||
|
||
前端报错时,页面会出现崩溃,并提示检查控制台日志。可以打开浏览器控制台,并查看`console`中的 log 日志。还可以点击对应 log 的超链接,会提示到具体错误文件,可以把这些详细错误信息提供,方便排查。
|
||
|
||
### OneAPI 错误
|
||
|
||
带有`requestId`的,都是 OneAPI 提示错误,大部分都是因为模型接口报错。可以参考 [OneAPI 常见错误](/docs/development/faq/#三常见的-oneapi-错误)
|
||
|
||
## 二、通用问题
|
||
|
||
### 前端页面崩溃
|
||
|
||
1. 90% 情况是模型配置不正确:确保每类模型都至少有一个启用;检查模型中一些`对象`参数是否异常(数组和对象),如果为空,可以尝试给个空数组或空对象。
|
||
2. 少部分是由于浏览器兼容问题,由于项目中包含一些高阶语法,可能低版本浏览器不兼容,可以将具体操作步骤和控制台中错误信息提供 issue。
|
||
3. 关闭浏览器翻译功能,如果浏览器开启了翻译,可能会导致页面崩溃。
|
||
|
||
### 通过sealos部署的话,是否没有本地部署的一些限制?
|
||
|
||

|
||
这是索引模型的长度限制,通过任何方式部署都一样的,但不同索引模型的配置不一样,可以在后台修改参数。
|
||
|
||
### 怎么挂载小程序配置文件
|
||
|
||
将验证文件,挂载到指定位置:/app/projects/app/public/xxxx.txt
|
||
|
||
然后重启。例如:
|
||
|
||

|
||
|
||
### 数据库3306端口被占用了,启动服务失败
|
||
|
||

|
||
|
||
把端口映射改成 3307 之类的,例如 3307:3306。
|
||
|
||
### 本地部署的限制
|
||
|
||
具体内容参考https://fael3z0zfze.feishu.cn/wiki/OFpAw8XzAi36Guk8dfucrCKUnjg。
|
||
|
||
### 能否纯本地运行
|
||
|
||
可以。需要准备好向量模型和LLM模型。
|
||
|
||
### 其他模型没法进行问题分类/内容提取
|
||
|
||
1. 看日志。如果提示 JSON invalid,not support tool 之类的,说明该模型不支持工具调用或函数调用,需要设置`toolChoice=false`和`functionCall=false`,就会默认走提示词模式。目前内置提示词仅针对了商业模型API进行测试。问题分类基本可用,内容提取不太行。
|
||
2. 如果已经配置正常,并且没有错误日志,则说明可能提示词不太适合该模型,可以通过修改`customCQPrompt`来自定义提示词。
|
||
|
||
### 页面崩溃
|
||
|
||
1. 关闭翻译
|
||
2. 检查配置文件是否正常加载,如果没有正常加载会导致缺失系统信息,在某些操作下会导致空指针。
|
||
* 95%情况是配置文件不对。会提示 xxx undefined
|
||
* 提示`URI malformed`,请 Issue 反馈具体操作和页面,这是由于特殊字符串编码解析报错。
|
||
3. 某些api不兼容问题(较少)
|
||
|
||
### 开启内容补全后,响应速度变慢
|
||
|
||
1. 问题补全需要经过一轮AI生成。
|
||
2. 会进行3~5轮的查询,如果数据库性能不足,会有明显影响。
|
||
|
||
### 页面中可以正常回复,API 报错
|
||
|
||
页面中是用 stream=true 模式,所以API也需要设置 stream=true 来进行测试。部分模型接口(国产居多)非 Stream 的兼容有点垃圾。
|
||
和上一个问题一样,curl 测试。
|
||
|
||
### 知识库索引没有进度/索引很慢
|
||
|
||
先看日志报错信息。有以下几种情况:
|
||
|
||
1. 可以对话,但是索引没有进度:没有配置向量模型(vectorModels)
|
||
2. 不能对话,也不能索引:API调用失败。可能是没连上OneAPI或OpenAI
|
||
3. 有进度,但是非常慢:api key不行,OpenAI的免费号,一分钟只有3次还是60次。一天上限200次。
|
||
|
||
### Connection error
|
||
|
||
网络异常。国内服务器无法请求OpenAI,自行检查与AI模型的连接是否正常。
|
||
|
||
或者是FastGPT请求不到 OneAPI(没放同一个网络)
|
||
|
||
### 修改了 vectorModels 但是没有生效
|
||
|
||
1. 重启容器,确保模型配置已经加载(可以在日志或者新建知识库时候看到新模型)
|
||
2. 记得刷新一次浏览器。
|
||
3. 如果是已经创建的知识库,需要删除重建。向量模型是创建时候绑定的,不会动态更新。
|
||
|
||
## 三、常见的 OneAPI 错误
|
||
|
||
带有 requestId 的都是 OneAPI 的报错。
|
||
|
||
### insufficient_user_quota user quota is not enough
|
||
|
||
OneAPI 账号的余额不足,默认 root 用户只有 200 刀,可以手动修改。
|
||
|
||
路径:打开OneAPI -> 用户 -> root用户右边的编辑 -> 剩余余额调大
|
||
|
||
### xxx渠道找不到
|
||
|
||
FastGPT 模型配置文件中的 model 必须与 OneAPI 渠道中的模型对应上,否则就会提示这个错误。可检查下面内容:
|
||
|
||
1. OneAPI 中没有配置该模型渠道,或者被禁用了。
|
||
2. FastGPT 配置文件有 OneAPI 没有配置的模型。如果 OneAPI 没有配置对应模型的,配置文件中也不要写。
|
||
3. 使用旧的向量模型创建了知识库,后又更新了向量模型。这时候需要删除以前的知识库,重建。
|
||
|
||
如果OneAPI中,没有配置对应的模型,`config.json`中也不要配置,否则容易报错。
|
||
|
||
### 点击模型测试失败
|
||
|
||
OneAPI 只会测试渠道的第一个模型,并且只会测试对话模型,向量模型无法自动测试,需要手动发起请求进行测试。[查看测试模型命令示例](/docs/development/faq/#如何检查模型问题)
|
||
### get request url failed: Post "https://xxx dial tcp: xxxx
|
||
|
||
OneAPI 与模型网络不通,需要检查网络配置。
|
||
|
||
### Incorrect API key provided: sk-xxxx.You can find your api Key at xxx
|
||
|
||
OneAPI 的 API Key 配置错误,需要修改`OPENAI_API_KEY`环境变量,并重启容器(先 docker-compose down 然后再 docker-compose up -d 运行一次)。
|
||
|
||
可以`exec`进入容器,`env`查看环境变量是否生效。
|
||
|
||
### bad_response_status_code bad response status code 503
|
||
|
||
1. 模型服务不可用
|
||
2. 模型接口参数异常(温度、max token等可能不适配)
|
||
3. ....
|
||
|
||
|
||
### Tiktoken 下载失败
|
||
|
||
由于 OneAPI 会在启动时从网络下载一个 tiktoken 的依赖,如果网络异常,就会导致启动失败。可以参考[OneAPI 离线部署](https://blog.csdn.net/wanh/article/details/139039216)解决。
|
||
|
||
## 四、常见模型问题
|
||
|
||
### 如何检查模型可用性问题
|
||
|
||
1. 私有部署模型,先确认部署的模型是否正常。
|
||
2. 通过 CURL 请求,直接测试上游模型是否正常运行(云端模型或私有模型均进行测试)
|
||
3. 通过 CURL 请求,请求 OneAPI 去测试模型是否正常。
|
||
4. 在 FastGPT 中使用该模型进行测试。
|
||
|
||
下面是几个测试 CURL 示例:
|
||
|
||
{{< tabs tabTotal="5" >}}
|
||
{{< tab tabName="LLM模型" >}}
|
||
{{< markdownify >}}
|
||
|
||
```bash
|
||
curl https://api.openai.com/v1/chat/completions \
|
||
-H "Content-Type: application/json" \
|
||
-H "Authorization: Bearer $OPENAI_API_KEY" \
|
||
-d '{
|
||
"model": "gpt-4o",
|
||
"messages": [
|
||
{
|
||
"role": "system",
|
||
"content": "You are a helpful assistant."
|
||
},
|
||
{
|
||
"role": "user",
|
||
"content": "Hello!"
|
||
}
|
||
]
|
||
}'
|
||
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="Embedding模型" >}}
|
||
{{< markdownify >}}
|
||
|
||
```bash
|
||
curl https://api.openai.com/v1/embeddings \
|
||
-H "Authorization: Bearer $OPENAI_API_KEY" \
|
||
-H "Content-Type: application/json" \
|
||
-d '{
|
||
"input": "The food was delicious and the waiter...",
|
||
"model": "text-embedding-ada-002",
|
||
"encoding_format": "float"
|
||
}'
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="Rerank 模型" >}}
|
||
{{< markdownify >}}
|
||
|
||
```bash
|
||
curl --location --request POST 'https://xxxx.com/api/v1/rerank' \
|
||
--header 'Authorization: Bearer {{ACCESS_TOKEN}}' \
|
||
--header 'Content-Type: application/json' \
|
||
--data-raw '{
|
||
"model": "bge-rerank-m3",
|
||
"query": "导演是谁",
|
||
"documents": [
|
||
"你是谁?\n我是电影《铃芽之旅》助手"
|
||
]
|
||
}'
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="TTS 模型" >}}
|
||
{{< markdownify >}}
|
||
|
||
```bash
|
||
curl https://api.openai.com/v1/audio/speech \
|
||
-H "Authorization: Bearer $OPENAI_API_KEY" \
|
||
-H "Content-Type: application/json" \
|
||
-d '{
|
||
"model": "tts-1",
|
||
"input": "The quick brown fox jumped over the lazy dog.",
|
||
"voice": "alloy"
|
||
}' \
|
||
--output speech.mp3
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="Whisper 模型" >}}
|
||
{{< markdownify >}}
|
||
|
||
```bash
|
||
curl https://api.openai.com/v1/audio/transcriptions \
|
||
-H "Authorization: Bearer $OPENAI_API_KEY" \
|
||
-H "Content-Type: multipart/form-data" \
|
||
-F file="@/path/to/file/audio.mp3" \
|
||
-F model="whisper-1"
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< /tabs >}}
|
||
|
||
### 报错 - 模型响应为空/模型报错
|
||
|
||
该错误是由于 stream 模式下,oneapi 直接结束了流请求,并且未返回任何内容导致。
|
||
|
||
4.8.10 版本新增了错误日志,报错时,会在日志中打印出实际发送的 Body 参数,可以复制该参数后,通过 curl 向 oneapi 发起请求测试。
|
||
|
||
由于 oneapi 在 stream 模式下,无法正确捕获错误,有时候可以设置成 `stream=false` 来获取到精确的错误。
|
||
|
||
可能的报错问题:
|
||
|
||
1. 国内模型命中风控
|
||
2. 不支持的模型参数:只保留 messages 和必要参数来测试,删除其他参数测试。
|
||
3. 参数不符合模型要求:例如有的模型 temperature 不支持 0,有些不支持两位小数。max_tokens 超出,上下文超长等。
|
||
4. 模型部署有问题,stream 模式不兼容。
|
||
|
||
测试示例如下,可复制报错日志中的请求体进行测试:
|
||
|
||
```bash
|
||
curl --location --request POST 'https://api.openai.com/v1/chat/completions' \
|
||
--header 'Authorization: Bearer sk-xxxx' \
|
||
--header 'Content-Type: application/json' \
|
||
--data-raw '{
|
||
"model": "xxx",
|
||
"temperature": 0.01,
|
||
"max_tokens": 1000,
|
||
"stream": true,
|
||
"messages": [
|
||
{
|
||
"role": "user",
|
||
"content": " 你是饿"
|
||
}
|
||
]
|
||
}'
|
||
```
|
||
|
||
### 如何测试模型是否支持工具调用
|
||
|
||
需要模型提供商和 oneapi 同时支持工具调用才可使用,测试方法如下:
|
||
|
||
##### 1. 通过 `curl` 向 `oneapi` 发起第一轮 stream 模式的 tool 测试。
|
||
|
||
```bash
|
||
curl --location --request POST 'https://oneapi.xxx/v1/chat/completions' \
|
||
--header 'Authorization: Bearer sk-xxxx' \
|
||
--header 'Content-Type: application/json' \
|
||
--data-raw '{
|
||
"model": "gpt-4o-mini",
|
||
"temperature": 0.01,
|
||
"max_tokens": 8000,
|
||
"stream": true,
|
||
"messages": [
|
||
{
|
||
"role": "user",
|
||
"content": "几点了"
|
||
}
|
||
],
|
||
"tools": [
|
||
{
|
||
"type": "function",
|
||
"function": {
|
||
"name": "hCVbIY",
|
||
"description": "获取用户当前时区的时间。",
|
||
"parameters": {
|
||
"type": "object",
|
||
"properties": {},
|
||
"required": []
|
||
}
|
||
}
|
||
}
|
||
],
|
||
"tool_choice": "auto"
|
||
}'
|
||
```
|
||
|
||
##### 2. 检查响应参数
|
||
|
||
如果能正常调用工具,会返回对应 `tool_calls` 参数。
|
||
|
||
```json
|
||
{
|
||
"id": "chatcmpl-A7kwo1rZ3OHYSeIFgfWYxu8X2koN3",
|
||
"object": "chat.completion.chunk",
|
||
"created": 1726412126,
|
||
"model": "gpt-4o-mini-2024-07-18",
|
||
"system_fingerprint": "fp_483d39d857",
|
||
"choices": [
|
||
{
|
||
"index": 0,
|
||
"delta": {
|
||
"role": "assistant",
|
||
"content": null,
|
||
"tool_calls": [
|
||
{
|
||
"index": 0,
|
||
"id": "call_0n24eiFk8OUyIyrdEbLdirU7",
|
||
"type": "function",
|
||
"function": {
|
||
"name": "mEYIcFl84rYC",
|
||
"arguments": ""
|
||
}
|
||
}
|
||
],
|
||
"refusal": null
|
||
},
|
||
"logprobs": null,
|
||
"finish_reason": null
|
||
}
|
||
],
|
||
"usage": null
|
||
}
|
||
```
|
||
|
||
##### 3. 通过 `curl` 向 `oneapi` 发起第二轮 stream 模式的 tool 测试。
|
||
|
||
第二轮请求是把工具结果发送给模型。发起后会得到模型回答的结果。
|
||
|
||
```bash
|
||
curl --location --request POST 'https://oneapi.xxxx/v1/chat/completions' \
|
||
--header 'Authorization: Bearer sk-xxx' \
|
||
--header 'Content-Type: application/json' \
|
||
--data-raw '{
|
||
"model": "gpt-4o-mini",
|
||
"temperature": 0.01,
|
||
"max_tokens": 8000,
|
||
"stream": true,
|
||
"messages": [
|
||
{
|
||
"role": "user",
|
||
"content": "几点了"
|
||
},
|
||
{
|
||
"role": "assistant",
|
||
"tool_calls": [
|
||
{
|
||
"id": "kDia9S19c4RO",
|
||
"type": "function",
|
||
"function": {
|
||
"name": "hCVbIY",
|
||
"arguments": "{}"
|
||
}
|
||
}
|
||
]
|
||
},
|
||
{
|
||
"tool_call_id": "kDia9S19c4RO",
|
||
"role": "tool",
|
||
"name": "hCVbIY",
|
||
"content": "{\n \"time\": \"2024-09-14 22:59:21 Sunday\"\n}"
|
||
}
|
||
],
|
||
"tools": [
|
||
{
|
||
"type": "function",
|
||
"function": {
|
||
"name": "hCVbIY",
|
||
"description": "获取用户当前时区的时间。",
|
||
"parameters": {
|
||
"type": "object",
|
||
"properties": {},
|
||
"required": []
|
||
}
|
||
}
|
||
}
|
||
],
|
||
"tool_choice": "auto"
|
||
}'
|
||
```
|
||
|
||
### 向量检索得分大于 1
|
||
|
||
由于模型没有归一化导致的。目前仅支持归一化的模型。
|
||
|
||
# 快速开始本地开发
|
||
## 对 FastGPT 进行开发调试
|
||
|
||
本文档介绍了如何设置开发环境以构建和测试 [FastGPT](https://tryfastgpt.ai),。
|
||
|
||
## 前置依赖项
|
||
|
||
您需要在计算机上安装和配置以下依赖项才能构建 [FastGPT](https://tryfastgpt.ai):
|
||
|
||
- [Git](http://git-scm.com/)
|
||
- [Docker](https://www.docker.com/)(构建镜像)
|
||
- [Node.js v20.14.0](http://nodejs.org)(版本尽量一样,可以使用nvm管理node版本)
|
||
- [pnpm](https://pnpm.io/) 推荐版本 9.4.0 (目前官方的开发环境)
|
||
- make命令: 根据不同平台,百度安装 (官方是GNU Make 4.3)
|
||
|
||
## 开始本地开发
|
||
|
||
{{% alert context="success" %}}
|
||
|
||
1. 用户默认的时区为 `Asia/Shanghai`,非 linux 环境时候,获取系统时间会异常,本地开发时候,可以将用户的时区调整成 UTC(+0)。
|
||
2. 建议先服务器装好**数据库**,再进行本地开发。
|
||
{{% /alert %}}
|
||
|
||
### 1. Fork 存储库
|
||
|
||
您需要 Fork [存储库](https://github.com/labring/FastGPT)。
|
||
|
||
### 2. 克隆存储库
|
||
|
||
克隆您在 GitHub 上 Fork 的存储库:
|
||
|
||
```
|
||
git clone git@github.com:<github_username>/FastGPT.git
|
||
```
|
||
|
||
**目录简要说明**
|
||
|
||
1. `projects` 目录下为 FastGPT 应用代码。其中 `app` 为 FastGPT 核心应用。(后续可能会引入其他应用)
|
||
2. NextJS 框架前后端放在一起,API 服务位于 `src/pages/api` 目录内。
|
||
3. `packages` 目录为共用代码,通过 workspace 被注入到 `projects` 中,已配置 monorepo 自动注入,无需额外打包。
|
||
|
||
### 3. 安装数据库
|
||
|
||
第一次开发,需要先部署数据库,建议本地开发可以随便找一台 2C2G 的轻量小数据库实践,或者新建文件夹并配置相关文件用以运行docker。数据库部署教程:[Docker 快速部署](/docs/development/docker/)。部署完了,可以本地访问其数据库。
|
||
{{% alert context="warning" %}}
|
||
Mongo 数据库需要注意,需要注意在连接地址中增加 `directConnection=true` 参数,才能连接上副本集的数据库。
|
||
{{% /alert %}}
|
||
|
||
### 4. 初始配置
|
||
|
||
以下文件均在 `projects/app` 路径下。
|
||
|
||
**1. 环境变量**
|
||
|
||
复制`.env.template`文件,在同级目录下生成一个`.env.local` 文件,修改`.env.local` 里内容才是有效的变量。变量说明见 .env.template,主要需要修改`API_KEY`和数据库的地址与端口以及数据库账号的用户名和密码,具体配置需要和docker配置文件相同,其中用户名和密码如需修改需要修改docker配置文件、数据库和`.env.local`文件,不能只改一处。
|
||
|
||
**2. config 配置文件**
|
||
|
||
复制 `data/config.json` 文件,生成一个 `data/config.local.json` 配置文件,具体配置参数说明,可参考 [config 配置说明](/docs/development/configuration)
|
||
|
||
**注意:json 配置文件不能包含注释,介绍中为了方便看才加入的注释**
|
||
|
||
这个文件大部分时候不需要修改。只需要关注 `systemEnv` 里的参数:
|
||
|
||
- `vectorMaxProcess`: 向量生成最大进程,根据数据库和 key 的并发数来决定,通常单个 120 号,2c4g 服务器设置 10~15。
|
||
- `qaMaxProcess`: QA 生成最大进程
|
||
- `vlmMaxProcess`: 图片理解模型最大进程
|
||
- `hnswEfSearch`: 向量搜索参数,仅对 PG 和 OB 生效,越大搜索精度越高但是速度越慢。
|
||
|
||
### 5. 运行
|
||
|
||
可参考项目根目录下的 `dev.md`,第一次编译运行可能会有点慢,需要点耐心哦
|
||
|
||
```bash
|
||
# 代码根目录下执行,会安装根 package、projects 和 packages 内所有依赖
|
||
# 如果提示 isolate-vm 安装失败,可以参考:https://github.com/laverdet/isolated-vm?tab=readme-ov-file#requirements
|
||
pnpm i
|
||
|
||
# 非 Make 运行
|
||
cd projects/app
|
||
pnpm dev
|
||
|
||
# Make 运行
|
||
make dev name=app
|
||
```
|
||
|
||
### 6. 部署打包
|
||
|
||
```bash
|
||
# Docker cmd: Build image, not proxy
|
||
docker build -f ./projects/app/Dockerfile -t registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt:v4.8.1 . --build-arg name=app
|
||
# Make cmd: Build image, not proxy
|
||
make build name=app image=registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt:v4.8.1
|
||
|
||
# Docker cmd: Build image with proxy
|
||
docker build -f ./projects/app/Dockerfile -t registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt:v4.8.1 . --build-arg name=app --build-arg proxy=taobao
|
||
# Make cmd: Build image with proxy
|
||
make build name=app image=registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt:v4.8.1 proxy=taobao
|
||
```
|
||
|
||
如果不使用 `docker` 打包,需要手动把 `Dockerfile` 里 run 阶段的内容全部手动执行一遍(非常不推荐)。
|
||
|
||
## 提交代码至开源仓库
|
||
|
||
1. 确保你的代码是 Fork [FastGPT](https://github.com/labring/FastGPT) 仓库
|
||
2. 尽可能少量的提交代码,每次提交仅解决一个问题。
|
||
3. 向 FastGPT 的 main 分支提交一个 PR,提交请求后,FastGPT 团队/社区的其他人将与您一起审查它。
|
||
|
||
如果遇到问题,比如合并冲突或不知道如何打开拉取请求,请查看 GitHub 的[拉取请求教程](https://docs.github.com/en/pull-requests/collaborating-with-pull-requests),了解如何解决合并冲突和其他问题。一旦您的 PR 被合并,您将自豪地被列为[贡献者表](https://github.com/labring/FastGPT/graphs/contributors)中的一员。
|
||
|
||
## QA
|
||
|
||
### 本地数据库无法连接
|
||
|
||
1. 如果你是连接远程的数据库,先检查对应的端口是否开放。
|
||
2. 如果是本地运行的数据库,可尝试`host`改成`localhost`或`127.0.0.1`
|
||
3. 本地连接远程的 Mongo,需要增加 `directConnection=true` 参数,才能连接上副本集的数据库。
|
||
4. mongo使用`mongocompass`客户端进行连接测试和可视化管理。
|
||
5. pg使用`navicat`进行连接和管理。
|
||
|
||
### sh ./scripts/postinstall.sh 没权限
|
||
|
||
FastGPT 在`pnpm i`后会执行`postinstall`脚本,用于自动生成`ChakraUI`的`Type`。如果没有权限,可以先执行`chmod -R +x ./scripts/`,再执行`pnpm i`。
|
||
|
||
仍不可行的话,可以手动执行`./scripts/postinstall.sh`里的内容。
|
||
*如果是Windows下的话,可以使用git bash给`postinstall`脚本添加执行权限并执行sh脚本*
|
||
|
||
### TypeError: Cannot read properties of null (reading 'useMemo' )
|
||
|
||
删除所有的`node_modules`,用 Node18 重新 install 试试,可能最新的 Node 有问题。 本地开发流程:
|
||
|
||
1. 根目录: `pnpm i`
|
||
2. 复制 `config.json` -> `config.local.json`
|
||
3. 复制 `.env.template` -> `.env.local`
|
||
4. `cd projects/app`
|
||
5. `pnpm dev`
|
||
|
||
### Error response from daemon: error while creating mount source path 'XXX': mkdir XXX: file exists
|
||
|
||
这个错误可能是之前停止容器时有文件残留导致的,首先需要确认相关镜像都全部关闭,然后手动删除相关文件或者重启docker即可
|
||
|
||
## 加入社区
|
||
|
||
遇到困难了吗?有任何问题吗? 加入飞书群与开发者和用户保持沟通。
|
||
|
||
<img width="400px" src="https://oss.laf.run/otnvvf-imgs/fastgpt-feishu1.png" class="medium-zoom-image" />
|
||
|
||
## 代码结构说明
|
||
|
||
### nextjs
|
||
|
||
FastGPT 使用了 nextjs 的 page route 作为框架。为了区分好前后端代码,在目录分配上会分成 global, service, web 3个自目录,分别对应着 `前后端共用`、`后端专用`、`前端专用`的代码。
|
||
|
||
### monorepo
|
||
|
||
FastGPT 采用 pnpm workspace 方式构建 monorepo 项目,主要分为两个部分:
|
||
|
||
- projects/app - FastGPT 主项目
|
||
- packages/ - 子模块
|
||
- global - 共用代码,通常是放一些前后端都能执行的函数、类型声明、常量。
|
||
- service - 服务端代码
|
||
- web - 前端代码
|
||
- plugin - 工作流自定义插件的代码
|
||
|
||
### 领域驱动模式(DDD)
|
||
|
||
FastGPT 在代码模块划分时,按DDD的思想进行划分,主要分为以下几个领域:
|
||
|
||
core - 核心功能(知识库,工作流,应用,对话)
|
||
support - 支撑功能(用户体系,计费,鉴权等)
|
||
common - 基础功能(日志管理,文件读写等)
|
||
|
||
{{% details title="代码结构说明" closed="true" %}}
|
||
|
||
```
|
||
.
|
||
├── .github // github 相关配置
|
||
├── .husky // 格式化配置
|
||
├── docSite // 文档
|
||
├── files // 一些外部文件,例如 docker-compose, helm
|
||
├── packages // 子包
|
||
│ ├── global // 前后端通用子包
|
||
│ ├── plugins // 工作流插件(需要自定义包时候使用到)
|
||
│ ├── service // 后端子包
|
||
│ └── web // 前端子包
|
||
├── projects
|
||
│ └── app // FastGPT 主项目
|
||
├── python // 存放一些模型代码,和 FastGPT 本身无关
|
||
└── scripts // 一些自动化脚本
|
||
├── icon // icon预览脚本,可以在顶层 pnpm initIcon(把svg写入到代码中), pnpm previewIcon(预览icon)
|
||
└── postinstall.sh // chakraUI自定义theme初始化 ts 类型
|
||
├── package.json // 顶层monorepo
|
||
├── pnpm-lock.yaml
|
||
├── pnpm-workspace.yaml // monorepo 声明
|
||
├── Dockerfile
|
||
├── LICENSE
|
||
├── README.md
|
||
├── README_en.md
|
||
├── README_ja.md
|
||
├── dev.md
|
||
```
|
||
|
||
{{% /details %}}
|
||
|
||
# Docker 数据库迁移(无脑操作)
|
||
## FastGPT Docker 数据库备份和迁移
|
||
|
||
## 1. 停止服务
|
||
|
||
```bash
|
||
docker-compose down
|
||
```
|
||
|
||
|
||
## 2. Copy文件夹
|
||
|
||
Docker 部署数据库都会通过 volume 挂载本地的目录进入容器,如果要迁移,直接复制这些目录即可。
|
||
|
||
`PG 数据`: pg/data
|
||
`Mongo 数据`: mongo/data
|
||
|
||
直接把pg 和 mongo目录全部复制走即可。
|
||
|
||
# Docker Mongo迁移(dump模式)
|
||
## FastGPT Docker Mongo迁移
|
||
|
||
## 作者
|
||
|
||
[https://github.com/samqin123](https://github.com/samqin123)
|
||
|
||
[相关PR。有问题可打开这里与作者交流](https://github.com/labring/FastGPT/pull/1426)
|
||
|
||
## 介绍
|
||
|
||
如何使用Mongodump来完成从A环境到B环境的Fastgpt的mongodb迁移
|
||
|
||
前提说明:
|
||
|
||
A环境:我在阿里云上部署的fastgpt,现在需要迁移到B环境。
|
||
B环境:是新环境比如腾讯云新部署的fastgpt,更特殊一点的是,NAS(群晖或者QNAP)部署了fastgpt,mongo必须改成4.2或者4.4版本(其实云端更方便,支持fastgpt mongo默认版本)
|
||
C环境:妥善考虑,用本地电脑作为C环境过渡,保存相关文件并分离操作
|
||
|
||
|
||
## 1. 环境准备:进入 docker mongo 【A环境】
|
||
```
|
||
docker exec -it mongo sh
|
||
mongo -u 'username' -p 'password'
|
||
>> show dbs
|
||
```
|
||
看到fastgpt数据库,以及其它几个,确定下导出数据库名称
|
||
准备:
|
||
检查数据库,容器和宿主机都创建一下 backup 目录 【A环境 + C环境】
|
||
|
||
##### 准备:
|
||
|
||
检查数据库,容器和宿主机都创建一下“数据导出导入”临时目录 ,比如data/backup 【A环境建目录 + C环境建目录用于同步到容器中】
|
||
|
||
#### 先在【A环境】创建文件目录,用于dump导出操作
|
||
容器:(先进入fastgpt docker容器)
|
||
```
|
||
docker exec -it fastgpt sh
|
||
mkdir -p /data/backup
|
||
```
|
||
|
||
建好后,未来导出mongo的数据,会在A环境本地fastgpt的安装目录/Data/下看到自动同步好的目录,数据会在data\backup中,然后可以衔接后续的压缩和下载转移动作。如果没有同步到本地,也可以手动建一下,配合docker cp 把文件拷到本地用(基本不会发生)
|
||
|
||
#### 然后,【C环境】宿主机目录类似操作,用于把上传的文件自动同步到C环境部署的fastgpt容器里。
|
||
到fastgpt目录,进入mongo目录,有data目录,下面建backup
|
||
```
|
||
mkdir -p /fastgpt/data/backup
|
||
```
|
||
准备好后,后续上传
|
||
```
|
||
### 新fastgpt环境【B】中也需要建一个,比如/fastgpt/mongobackup目录,注意不要在fastgpt/data目录下建立目录
|
||
```
|
||
mkdir -p /fastgpt/mongobackup
|
||
```
|
||
|
||
###2. 正题开始,从fastgpt老环境【A】中导出数据
|
||
进入A环境,使用mongodump 导出mongo数据库。
|
||
|
||
#### 2.1 导出
|
||
可以使用mongodump在源头容器中导出数据文件, 导出路径为上面指定临时目录,即"data\backup"
|
||
|
||
[导出的文件在代码中指定为/data/backup,因为fastgpt配置文件已经建立了data的持久化,所以会同步到容器所在环境本地fast/mongo/data应该就能看到这个导出的目录:backup,里面有文件]
|
||
|
||
一行指令导出代码,在服务器本地环境运行,不需要进入容器。
|
||
```
|
||
docker exec -it mongo bash -c "mongodump --db fastgpt -u 'username' -p 'password' --authenticationDatabase admin --out /data/backup"
|
||
```
|
||
|
||
也可以进入环境,熟手可以结合建目录,一次性完成建导出目录,以及使用mongodump导出数据到该目录
|
||
```
|
||
1.docker exec -it fastgpt sh
|
||
|
||
2.mkdir -p /data/backup
|
||
|
||
3. mongodump --host 127.0.0.1:27017 --db fastgpt -u "username" -p "password" --authenticationDatabase admin --out /data/backup
|
||
|
||
|
||
##### 补充:万一没自动同步,也可以将mongodump导出的文件,手工导出到宿主机【A环境】,备用指令如下:
|
||
```
|
||
docker cp mongo:/data/backup <A环境本地fastgpt目录>:/fastgpt/data/backup>
|
||
```
|
||
|
||
2.2 对新手,建议稳妥起见,压缩这个文件目录,并将压缩文件下载到本地过渡环境【A环境 -> C环境】;原因是因为留存一份,并且检查文件数量是否一致。
|
||
|
||
熟手可以直接复制到新部署服务器(腾讯云或者NAS)【A环境-> B环境】
|
||
|
||
|
||
2.2.1 先进入 【A环境】源头系统的本地环境 fastgpt/mongo/data 目录
|
||
|
||
```
|
||
cd /usr/fastgpt/mongo/data
|
||
```
|
||
|
||
#执行,压缩文件命令
|
||
```
|
||
tar -czvf ../fastgpt-mongo-backup-$(date +%Y-%m-%d).tar.gz ./ 【A环境】
|
||
```
|
||
#接下来,把压缩包下载到本地 【A环境-> C环境】,以便于检查和留存版本。熟手,直接将该压缩包同步到B环境中新fastgpt目录data目录下备用。
|
||
|
||
```
|
||
scp -i /Users/path/<user.pem换成你自己的pem文件链接> root@<fastgpt所在云服务器地址>:/usr/fastgpt/mongo/fastgptbackup-2024-05-03.tar.gz /<本地电脑路径>/Downloads/fastgpt
|
||
|
||
```
|
||
熟手直接换成新环境地址
|
||
|
||
```
|
||
scp -i /Users/path/<user.pem换成你自己的pem文件链接> root@<老环境fastgpt服务器地址>:/usr/fastgpt/mongo/fastgptbackup-2024-05-03.tar.gz root@<新环境fastgpt服务器地址>:/Downloads/fastgpt2
|
||
|
||
```
|
||
|
||
2.2 【C环境】检查压缩文件是否完整,如果不完整,重新导出。事实上,我也出现过问题,因为跨环境scp会出现丢数据的情况。
|
||
|
||
压缩数据包导入到C环境本地后,可以考虑在宿主机目录解压缩,放在一个自定义目录比如. < user/fastgpt/mongobackup/data>
|
||
|
||
```
|
||
tar -xvzf fastgptbackup-2024-05-03.tar.gz -C user/fastgpt/mongobackup/data
|
||
```
|
||
解压缩后里面是bson文件,这里可以检查下,压缩文件数量是否一致。如果不一致,后续启动新环境的fastgpt容器,也不会有任何数据。
|
||
|
||
<img width="1561" alt="image" src="https://github.com/labring/FastGPT/assets/103937568/cbb8a93c-5834-4a0d-be6c-c45c701f593e">
|
||
|
||
|
||
如果没问题,准备进入下一步,将压缩包文件上传到B环境,也就是新fastgpt环境里的指定目录,比如/fastgpt/mongobackup, 注意不要放到fastgpt/data目录下,因为下面会先清空一次这个目录,否则导入会报错。
|
||
```
|
||
scp -rfv <本地电脑路径>/Downloads/fastgpt/fastgptbackup-2024-05-03.tar.gz root@<新环境fastgpt服务器地址>:/Downloads/fastgpt/backup
|
||
```
|
||
|
||
## 3 导入恢复: 实际恢复和导入步骤
|
||
|
||
### 3.1. 进入新fastgpt本地环境的安装目录后,找到迁移的压缩文件包fastgptbackup-2024-05-03.tar.gz,解压缩到指定目录
|
||
|
||
```
|
||
tar -xvzf fastgptbackup-2024-05-03.tar.gz -C user/fastgpt/mongobackup/data
|
||
```
|
||
再次核对文件数量,和上面对比一下。
|
||
|
||
熟手可以用tar指令检查文件完整性,上面是给新手准备的,便于比对核查。
|
||
|
||
|
||
### 3.2 手动上传新fastgpt docker容器里备用 【C环境】
|
||
说明:因为没有放在data里,所以不会自动同步到容器里。而且要确保容器的data目录被清理干净,否则导入时会报错。
|
||
|
||
```
|
||
docker cp user/fastgpt/mongobackup/data mongo:/tmp/backup
|
||
```
|
||
|
||
### 3.3 建议初始化一次docker compose ,运行后建立新的 mongo/data 持久化目录
|
||
如果不是初始化的 mongo/db 目录, mongorestore 导入可能会报错。如果报错,建议尝试初始化mongo。
|
||
|
||
操作指令
|
||
```
|
||
cd /fastgpt安装目录/mongo/data
|
||
rm -rf *
|
||
```
|
||
|
||
|
||
4.恢复: mongorestore 恢复 [C环境】
|
||
简单一点,退回到本地环境,用 docker 命令一键导入,当然你也可以在容器里操作
|
||
|
||
```
|
||
docker exec -it mongo mongorestore -u "username" -p "password" --authenticationDatabase admin /tmp/backup/ --db fastgpt
|
||
```
|
||
<img width="1668" alt="image" src="https://github.com/labring/FastGPT/assets/103937568/32c2cdb8-bf80-4d31-9269-4bf3909cf04e">
|
||
注意:导入文件数量量级太少,大概率是没导入成功的表现。如果导入不成功,新环境fastgpt可以登入,但是一片空白。
|
||
|
||
|
||
5.重启容器 【C环境】
|
||
```
|
||
docker compose restart
|
||
docker logs -f mongo **强烈建议先检查mongo运行情况,在去做登录动作,如果mongo报错,访问web也会报错”
|
||
```
|
||
|
||
如果mongo启动正常,显示的是类似这样的,而不是 “mongo is restarting”,后者就是错误
|
||
<img width="1736" alt="iShot_2024-05-09_19 21 26" src="https://github.com/labring/FastGPT/assets/103937568/94ee00db-43de-48bd-a1fc-22dfe86aaa90">
|
||
|
||
报错情况
|
||
<img width="508" alt="iShot_2024-05-09_19 23 13" src="https://github.com/labring/FastGPT/assets/103937568/2e2afc9f-484c-4b63-93ee-1c14aef03de0">
|
||
|
||
|
||
6. 启动fastgpt容器服务后,登录新fastgpt web,能看到原来的数据库内容完整显示,说明已经导入系统了。
|
||
<img width="1728" alt="iShot_2024-05-09_19 23 51" src="https://github.com/labring/FastGPT/assets/103937568/846b6157-6b6a-4468-a1d9-c44d681ebf7c">
|
||
|
||
# 通过 AI Proxy 接入模型
|
||
## 通过 AI Proxy 接入模型
|
||
|
||
从 `FastGPT 4.8.23` 版本开始,引入 AI Proxy 来进一步方便模型的配置。
|
||
|
||
AI Proxy 与 One API 类似,也是作为一个 OpenAI 接口管理 & 分发系统,可以通过标准的 OpenAI API 格式访问所有的大模型,开箱即用。
|
||
|
||
## 部署
|
||
|
||
### Docker 版本
|
||
|
||
`docker-compose.yml` 文件已加入了 AI Proxy 配置,可直接使用。[点击查看最新的 yml 配置](https://raw.githubusercontent.com/labring/FastGPT/main/deploy/docker/docker-compose-pgvector.yml)
|
||
|
||
从旧版升级的用户,可以复制 yml 里,ai proxy 的配置,加入到旧的 yml 文件中。
|
||
|
||
## 运行原理
|
||
|
||
AI proxy 核心模块:
|
||
|
||
1. 渠道管理:管理各家模型提供商的 API Key 和可用模型列表。
|
||
2. 模型调用:根据请求的模型,选中对应的渠道;根据渠道的 API 格式,构造请求体,发送请求;格式化响应体成标准格式返回。
|
||
3. 调用日志:详细记录模型调用的日志,并在错误时候可以记录其入参和报错信息,方便排查。
|
||
|
||
运行流程:
|
||
|
||

|
||
|
||
## 在 FastGPT 中使用
|
||
|
||
AI proxy 相关功能,可以在`账号-模型提供商`页面找到。
|
||
|
||
### 1. 创建渠道
|
||
|
||
在`模型提供商`的配置页面,点击`模型渠道`,进入渠道配置页面
|
||
|
||

|
||
|
||
点击右上角的“新增渠道”,即可进入渠道配置页面
|
||
|
||

|
||
|
||
以阿里云的模型为例,进行如下配置
|
||
|
||

|
||
|
||
1. 渠道名:展示在外部的渠道名称,仅作标识;
|
||
2. 厂商:模型对应的厂商,不同厂商对应不同的默认地址和 API 密钥格式;
|
||
3. 模型:当前渠道具体可以使用的模型,系统内置了主流的一些模型,如果下拉框中没有想要的选项,可以点击“新增模型”,[增加自定义模型](/docs/development/modelconfig/intro/#新增自定义模型);
|
||
4. 模型映射:将 FastGPT 请求的模型,映射到具体提供的模型上。例如:
|
||
|
||
```json
|
||
{
|
||
"gpt-4o-test": "gpt-4o",
|
||
}
|
||
```
|
||
|
||
FatGPT 中的模型为 `gpt-4o-test`,向 AI Proxy 发起请求时也是 `gpt-4o-test`。AI proxy 在向上游发送请求时,实际的`model`为 `gpt-4o`。
|
||
|
||
5. 代理地址:具体请求的地址,系统给每个主流渠道配置了默认的地址,如果无需改动则不用填。
|
||
6. API 密钥:从模型厂商处获取的 API 凭证。注意部分厂商需要提供多个密钥组合,可以根据提示进行输入。
|
||
|
||
最后点击“新增”,就能在“模型渠道”下看到刚刚配置的渠道
|
||
|
||

|
||
|
||
### 2. 渠道测试
|
||
|
||
然后可以对渠道进行测试,确保配置的模型有效
|
||
|
||

|
||
|
||
点击“模型测试”,可以看到配置的模型列表,点击“开始测试”
|
||
|
||

|
||
|
||
等待模型测试完成后,会输出每个模型的测试结果以及请求时长
|
||
|
||

|
||
|
||
### 3. 启用模型
|
||
|
||
最后在`模型配置`中,可以选择启用对应的模型,这样就能在平台中使用了,更多模型配置可以参考[模型配置](/docs/development/modelconfig/intro)
|
||
|
||

|
||
|
||
## 其他功能介绍
|
||
|
||
### 优先级
|
||
|
||
范围1~100。数值越大,越容易被优先选中。
|
||
|
||

|
||
|
||
### 启用/禁用
|
||
|
||
在渠道右侧的控制菜单中,还可以控制渠道的启用或禁用,被禁用的渠道将无法再提供模型服务
|
||
|
||

|
||
|
||
### 调用日志
|
||
|
||
在 `调用日志` 页面,会展示发送到模型处的请求记录,包括具体的输入输出 tokens、请求时间、请求耗时、请求地址等等。错误的请求,则会详细的入参和错误信息,方便排查,但仅会保留 1 小时(环境变量里可配置)。
|
||
|
||

|
||
|
||
## 从 OneAPI 迁移到 AI Proxy
|
||
|
||
可以从任意终端,发起 1 个 HTTP 请求。其中 `{{host}}` 替换成 AI Proxy 地址,`{{admin_key}}` 替换成 AI Proxy 中 `ADMIN_KEY` 的值。
|
||
|
||
Body 参数 `dsn` 为 OneAPI 的 mysql 连接串。
|
||
|
||
```bash
|
||
curl --location --request POST '{{host}}/api/channels/import/oneapi' \
|
||
--header 'Authorization: Bearer {{admin_key}}' \
|
||
--header 'Content-Type: application/json' \
|
||
--data-raw '{
|
||
"dsn": "mysql://root:s5mfkwst@tcp(dbconn.sealoshzh.site:33123)/mydb"
|
||
}'
|
||
```
|
||
|
||
执行成功的情况下会返回 "success": true
|
||
|
||
脚本目前不是完全准,仅是简单的做数据映射,主要是迁移`代理地址`、`模型`和`API 密钥`,建议迁移后再进行手动检查。
|
||
|
||
# FastGPT 模型配置说明
|
||
## FastGPT 模型配置说明
|
||
|
||
在 4.8.20 版本以前,FastGPT 模型配置在 `config.json` 文件中声明,你可以在 https://github.com/labring/FastGPT/blob/main/projects/app/data/model.json 中找到旧版的配置文件示例。
|
||
|
||
从 4.8.20 版本开始,你可以直接在 FastGPT 页面中进行模型配置,并且系统内置了大量模型,无需从 0 开始配置。下面介绍模型配置的基本流程:
|
||
|
||
## 配置模型
|
||
|
||
### 1. 对接模型提供商
|
||
|
||
#### AI Proxy
|
||
|
||
从 4.8.23 版本开始, FastGPT 支持在页面上配置模型提供商,即使用 [AI Proxy 接入教程](/docs/development/modelconfig/ai-proxy) 来进行模型聚合,从而可以对接更多模型提供商。
|
||
|
||
#### One API
|
||
|
||
也可以使用 [OneAPI 接入教程](/docs/development/modelconfig/one-api)。你需要先在各服务商申请好 API 接入 OneAPI 后,才能在 FastGPT 中使用这些模型。示例流程如下:
|
||
|
||

|
||
|
||
除了各模型官方的服务外,还有一些第三方服务商提供模型接入服务,当然你也可以用 Ollama 等来部署本地模型,最终都需要接入 OneAPI,下面是一些第三方服务商:
|
||
|
||
{{% alert icon=" " context="info" %}}
|
||
- [SiliconCloud(硅基流动)](https://cloud.siliconflow.cn/i/TR9Ym0c4): 提供开源模型调用的平台。
|
||
- [Sealos AIProxy](https://hzh.sealos.run/?uid=fnWRt09fZP&openapp=system-aiproxy): 提供国内各家模型代理,无需逐一申请 api。
|
||
{{% /alert %}}
|
||
|
||
在 OneAPI 配置好模型后,你就可以打开 FastGPT 页面,启用对应模型了。
|
||
|
||
### 2. 配置介绍
|
||
|
||
{{% alert icon="🤖 " context="success" %}}
|
||
注意:
|
||
1. 目前语音识别模型和重排模型仅会生效一个,所以配置时候,只需要配置一个即可。
|
||
2. 系统至少需要一个语言模型和一个索引模型才能正常使用。
|
||
{{% /alert %}}
|
||
|
||
#### 核心配置
|
||
|
||
- 模型 ID:接口请求时候,Body 中`model`字段的值,全局唯一。
|
||
- 自定义请求地址/Key:如果需要绕过`OneAPI`,可以设置自定义请求地址和 Token。一般情况下不需要,如果 OneAPI 不支持某些模型,可以使用该特性。
|
||
|
||
#### 模型类型
|
||
|
||
1. 语言模型 - 进行文本对话,多模态模型支持图片识别。
|
||
2. 索引模型 - 对文本块进行索引,用于相关文本检索。
|
||
3. 重排模型 - 对检索结果进行重排,用于优化检索排名。
|
||
4. 语音合成 - 将文本转换为语音。
|
||
5. 语音识别 - 将语音转换为文本。
|
||
|
||
#### 启用模型
|
||
|
||
系统内置了目前主流厂商的模型,如果你不熟悉配置,直接点击`启用`即可,需要注意的是,`模型 ID`需要和 OneAPI 中渠道的`模型`一致。
|
||
|
||
| | |
|
||
| --- | --- |
|
||
|  |  |
|
||
|
||
#### 修改模型配置
|
||
|
||
点击模型右侧的齿轮即可进行模型配置,不同类型模型的配置有区别。
|
||
|
||
| | |
|
||
| --- | --- |
|
||
|  |  |
|
||
|
||
## 新增自定义模型
|
||
|
||
如果系统内置的模型无法满足你的需求,你可以添加自定义模型。自定义模型中,如果`模型 ID`与系统内置的模型 ID 一致,则会被认为是修改系统模型。
|
||
|
||
| | |
|
||
| --- | --- |
|
||
|  |  |
|
||
|
||
#### 通过配置文件配置
|
||
|
||
如果你觉得通过页面配置模型比较麻烦,你也可以通过配置文件来配置模型。或者希望快速将一个系统的配置,复制到另一个系统,也可以通过配置文件来实现。
|
||
|
||
| | |
|
||
| --- | --- |
|
||
|  |  |
|
||
|
||
**语言模型字段说明:**
|
||
|
||
```json
|
||
{
|
||
"model": "模型 ID",
|
||
"metadata": {
|
||
"isCustom": true, // 是否为自定义模型
|
||
"isActive": true, // 是否启用
|
||
"provider": "OpenAI", // 模型提供商,主要用于分类展示,目前已经内置提供商包括:https://github.com/labring/FastGPT/blob/main/packages/global/core/ai/provider.ts, 可 pr 提供新的提供商,或直接填写 Other
|
||
"model": "gpt-4o-mini", // 模型ID(对应OneAPI中渠道的模型名)
|
||
"name": "gpt-4o-mini", // 模型别名
|
||
"maxContext": 125000, // 最大上下文
|
||
"maxResponse": 16000, // 最大回复
|
||
"quoteMaxToken": 120000, // 最大引用内容
|
||
"maxTemperature": 1.2, // 最大温度
|
||
"charsPointsPrice": 0, // n积分/1k token(商业版)
|
||
"censor": false, // 是否开启敏感校验(商业版)
|
||
"vision": true, // 是否支持图片输入
|
||
"datasetProcess": true, // 是否设置为文本理解模型(QA),务必保证至少有一个为true,否则知识库会报错
|
||
"usedInClassify": true, // 是否用于问题分类(务必保证至少有一个为true)
|
||
"usedInExtractFields": true, // 是否用于内容提取(务必保证至少有一个为true)
|
||
"usedInToolCall": true, // 是否用于工具调用(务必保证至少有一个为true)
|
||
"toolChoice": true, // 是否支持工具选择(分类,内容提取,工具调用会用到。)
|
||
"functionCall": false, // 是否支持函数调用(分类,内容提取,工具调用会用到。会优先使用 toolChoice,如果为false,则使用 functionCall,如果仍为 false,则使用提示词模式)
|
||
"customCQPrompt": "", // 自定义文本分类提示词(不支持工具和函数调用的模型
|
||
"customExtractPrompt": "", // 自定义内容提取提示词
|
||
"defaultSystemChatPrompt": "", // 对话默认携带的系统提示词
|
||
"defaultConfig": {}, // 请求API时,挟带一些默认配置(比如 GLM4 的 top_p)
|
||
"fieldMap": {} // 字段映射(o1 模型需要把 max_tokens 映射为 max_completion_tokens)
|
||
}
|
||
}
|
||
```
|
||
|
||
**索引模型字段说明:**
|
||
|
||
```json
|
||
{
|
||
"model": "模型 ID",
|
||
"metadata": {
|
||
"isCustom": true, // 是否为自定义模型
|
||
"isActive": true, // 是否启用
|
||
"provider": "OpenAI", // 模型提供商
|
||
"model": "text-embedding-3-small", // 模型ID
|
||
"name": "text-embedding-3-small", // 模型别名
|
||
"charsPointsPrice": 0, // n积分/1k token
|
||
"defaultToken": 512, // 默认文本分割时候的 token
|
||
"maxToken": 3000 // 最大 token
|
||
}
|
||
}
|
||
```
|
||
|
||
**重排模型字段说明:**
|
||
|
||
```json
|
||
{
|
||
"model": "模型 ID",
|
||
"metadata": {
|
||
"isCustom": true, // 是否为自定义模型
|
||
"isActive": true, // 是否启用
|
||
"provider": "BAAI", // 模型提供商
|
||
"model": "bge-reranker-v2-m3", // 模型ID
|
||
"name": "ReRanker-Base", // 模型别名
|
||
"requestUrl": "", // 自定义请求地址
|
||
"requestAuth": "", // 自定义请求认证
|
||
"type": "rerank" // 模型类型
|
||
}
|
||
}
|
||
```
|
||
|
||
**语音合成模型字段说明:**
|
||
|
||
```json
|
||
{
|
||
"model": "模型 ID",
|
||
"metadata": {
|
||
"isActive": true, // 是否启用
|
||
"isCustom": true, // 是否为自定义模型
|
||
"type": "tts", // 模型类型
|
||
"provider": "FishAudio", // 模型提供商
|
||
"model": "fishaudio/fish-speech-1.5", // 模型ID
|
||
"name": "fish-speech-1.5", // 模型别名
|
||
"voices": [ // 音色
|
||
{
|
||
"label": "fish-alex", // 音色名称
|
||
"value": "fishaudio/fish-speech-1.5:alex", // 音色ID
|
||
},
|
||
{
|
||
"label": "fish-anna", // 音色名称
|
||
"value": "fishaudio/fish-speech-1.5:anna", // 音色ID
|
||
}
|
||
],
|
||
"charsPointsPrice": 0 // n积分/1k token
|
||
}
|
||
}
|
||
```
|
||
|
||
**语音识别模型字段说明:**
|
||
|
||
```json
|
||
{
|
||
"model": "whisper-1",
|
||
"metadata": {
|
||
"isActive": true, // 是否启用
|
||
"isCustom": true, // 是否为自定义模型
|
||
"provider": "OpenAI", // 模型提供商
|
||
"model": "whisper-1", // 模型ID
|
||
"name": "whisper-1", // 模型别名
|
||
"charsPointsPrice": 0, // n积分/1k token
|
||
"type": "stt" // 模型类型
|
||
}
|
||
}
|
||
```
|
||
|
||
## 模型测试
|
||
|
||
FastGPT 页面上提供了每类模型的简单测试,可以初步检查模型是否正常工作,会实际按模板发送一个请求。
|
||
|
||

|
||
|
||
## 特殊接入示例
|
||
|
||
### ReRank 模型接入
|
||
|
||
由于 OneAPI 不支持 Rerank 模型,所以需要单独配置。FastGPT 中,模型配置支持自定义请求地址,可以绕过 OneAPI,直接向提供商发起请求,可以利用这个特性来接入 Rerank 模型。
|
||
|
||
|
||
#### 使用硅基流动的在线模型
|
||
|
||
有免费的 `bge-reranker-v2-m3` 模型可以使用。
|
||
|
||
1. [点击注册硅基流动账号](https://cloud.siliconflow.cn/i/TR9Ym0c4)
|
||
2. 进入控制台,获取 API key: https://cloud.siliconflow.cn/account/ak
|
||
3. 打开 FastGPT 模型配置,新增一个`BAAI/bge-reranker-v2-m3`的重排模型(如果系统内置了,也可以直接变更,无需新增)。
|
||
|
||

|
||
|
||
#### 私有部署模型
|
||
|
||
[点击查看部署 ReRank 模型教程](/docs/development/custom-models/bge-rerank/)
|
||
|
||
### 接入语音识别模型
|
||
|
||
OneAPI 的语言识别接口,无法正确的识别其他模型(会始终识别成 whisper-1),所以如果想接入其他模型,可以通过自定义请求地址来实现。例如,接入硅基流动的 `FunAudioLLM/SenseVoiceSmall` 模型,可以参考如下配置:
|
||
|
||
点击模型编辑:
|
||
|
||

|
||
|
||
填写硅基流动的地址:`https://api.siliconflow.cn/v1/audio/transcriptions`,并填写硅基流动的 API Key。
|
||
|
||

|
||
|
||
## 其他配置项说明
|
||
|
||
### 自定义请求地址
|
||
|
||
如果填写了该值,则可以允许你绕过 OneAPI,直接向自定义请求地址发起请求。需要填写完整的请求地址,例如:
|
||
|
||
- LLM: {{host}}/v1/chat/completions
|
||
- Embedding: {{host}}/v1/embeddings
|
||
- STT: {{host}}/v1/audio/transcriptions
|
||
- TTS: {{host}}/v1/audio/speech
|
||
- Rerank: {{host}}/v1/rerank
|
||
|
||
自定义请求 Key,则是向自定义请求地址发起请求时候,携带请求头:Authorization: Bearer xxx 进行请求。
|
||
|
||
所有接口均遵循 OpenAI 提供的模型格式,可参考 [OpenAI API 文档](https://platform.openai.com/docs/api-reference/introduction) 进行配置。
|
||
|
||
由于 OpenAI 没有提供 ReRank 模型,遵循的是 Cohere 的格式。[点击查看接口请求示例](/docs/development/faq/#如何检查模型问题)
|
||
|
||
|
||
### 模型价格配置
|
||
|
||
商业版用户可以通过配置模型价格,来进行账号计费。系统包含两种计费模式:按总 tokens 计费和输入输出 Tokens 分开计费。
|
||
|
||
如果需要配置`输入输出 Tokens 分开计费模式`,则填写`模型输入价格`和`模型输出价格`两个值。
|
||
如果需要配置`按总 tokens 计费模式`,则填写`模型综合价格`一个值。
|
||
|
||
## 如何提交内置模型
|
||
|
||
由于模型更新非常频繁,官方不一定及时更新,如果未能找到你期望的内置模型,你可以[提交 Issue](https://github.com/labring/FastGPT/issues),提供模型的名字和对应官网。或者直接[提交 PR](https://github.com/labring/FastGPT/pulls),提供模型配置。
|
||
|
||
|
||
### 添加模型提供商
|
||
|
||
如果你需要添加模型提供商,需要修改以下代码:
|
||
|
||
1. FastGPT/packages/web/components/common/Icon/icons/model - 在此目录下,添加模型提供商的 svg 头像地址。
|
||
2. 在 FastGPT 根目录下,运行`pnpm initIcon`,将图片加载到配置文件中。
|
||
3. FastGPT/packages/global/core/ai/provider.ts - 在此文件中,追加模型提供商的配置。
|
||
|
||
### 添加模型
|
||
|
||
你可以在`FastGPT/packages/service/core/ai/config/provider`目录下,找对应模型提供商的配置文件,并追加模型配置。请自行全文检查,`model`字段,必须在所有模型中唯一。具体配置字段说明,参考[模型配置字段说明](/docs/development/modelconfig/intro/#通过配置文件配置)
|
||
|
||
## 旧版模型配置说明
|
||
|
||
配置好 OneAPI 后,需要在`config.json`文件中,手动的增加模型配置,并重启。
|
||
|
||
由于环境变量不利于配置复杂的内容,FastGPT 采用了 ConfigMap 的形式挂载配置文件,你可以在 `projects/app/data/config.json` 看到默认的配置文件。可以参考 [docker-compose 快速部署](/docs/development/docker/) 来挂载配置文件。
|
||
|
||
**开发环境下**,你需要将示例配置文件 `config.json` 复制成 `config.local.json` 文件才会生效。
|
||
**Docker部署**,修改`config.json` 文件,需要重启容器。
|
||
|
||
下面配置文件示例中包含了系统参数和各个模型配置:
|
||
|
||
```json
|
||
{
|
||
"feConfigs": {
|
||
"lafEnv": "https://laf.dev" // laf环境。 https://laf.run (杭州阿里云) ,或者私有化的laf环境。如果使用 Laf openapi 功能,需要最新版的 laf 。
|
||
},
|
||
"systemEnv": {
|
||
"vectorMaxProcess": 15, // 向量处理线程数量
|
||
"qaMaxProcess": 15, // 问答拆分线程数量
|
||
"tokenWorkers": 50, // Token 计算线程保持数,会持续占用内存,不能设置太大。
|
||
"hnswEfSearch": 100 // 向量搜索参数,仅对 PG 和 OB 生效。越大,搜索越精确,但是速度越慢。设置为100,有99%+精度。
|
||
},
|
||
"llmModels": [
|
||
{
|
||
"provider": "OpenAI", // 模型提供商,主要用于分类展示,目前已经内置提供商包括:https://github.com/labring/FastGPT/blob/main/packages/global/core/ai/provider.ts, 可 pr 提供新的提供商,或直接填写 Other
|
||
"model": "gpt-4o-mini", // 模型名(对应OneAPI中渠道的模型名)
|
||
"name": "gpt-4o-mini", // 模型别名
|
||
"maxContext": 125000, // 最大上下文
|
||
"maxResponse": 16000, // 最大回复
|
||
"quoteMaxToken": 120000, // 最大引用内容
|
||
"maxTemperature": 1.2, // 最大温度
|
||
"charsPointsPrice": 0, // n积分/1k token(商业版)
|
||
"censor": false, // 是否开启敏感校验(商业版)
|
||
"vision": true, // 是否支持图片输入
|
||
"datasetProcess": true, // 是否设置为文本理解模型(QA),务必保证至少有一个为true,否则知识库会报错
|
||
"usedInClassify": true, // 是否用于问题分类(务必保证至少有一个为true)
|
||
"usedInExtractFields": true, // 是否用于内容提取(务必保证至少有一个为true)
|
||
"usedInToolCall": true, // 是否用于工具调用(务必保证至少有一个为true)
|
||
"toolChoice": true, // 是否支持工具选择(分类,内容提取,工具调用会用到。)
|
||
"functionCall": false, // 是否支持函数调用(分类,内容提取,工具调用会用到。会优先使用 toolChoice,如果为false,则使用 functionCall,如果仍为 false,则使用提示词模式)
|
||
"customCQPrompt": "", // 自定义文本分类提示词(不支持工具和函数调用的模型
|
||
"customExtractPrompt": "", // 自定义内容提取提示词
|
||
"defaultSystemChatPrompt": "", // 对话默认携带的系统提示词
|
||
"defaultConfig": {}, // 请求API时,挟带一些默认配置(比如 GLM4 的 top_p)
|
||
"fieldMap": {} // 字段映射(o1 模型需要把 max_tokens 映射为 max_completion_tokens)
|
||
},
|
||
{
|
||
"provider": "OpenAI",
|
||
"model": "gpt-4o",
|
||
"name": "gpt-4o",
|
||
"maxContext": 125000,
|
||
"maxResponse": 4000,
|
||
"quoteMaxToken": 120000,
|
||
"maxTemperature": 1.2,
|
||
"charsPointsPrice": 0,
|
||
"censor": false,
|
||
"vision": true,
|
||
"datasetProcess": true,
|
||
"usedInClassify": true,
|
||
"usedInExtractFields": true,
|
||
"usedInToolCall": true,
|
||
"toolChoice": true,
|
||
"functionCall": false,
|
||
"customCQPrompt": "",
|
||
"customExtractPrompt": "",
|
||
"defaultSystemChatPrompt": "",
|
||
"defaultConfig": {},
|
||
"fieldMap": {}
|
||
},
|
||
{
|
||
"provider": "OpenAI",
|
||
"model": "o1-mini",
|
||
"name": "o1-mini",
|
||
"maxContext": 125000,
|
||
"maxResponse": 65000,
|
||
"quoteMaxToken": 120000,
|
||
"maxTemperature": 1.2,
|
||
"charsPointsPrice": 0,
|
||
"censor": false,
|
||
"vision": false,
|
||
"datasetProcess": true,
|
||
"usedInClassify": true,
|
||
"usedInExtractFields": true,
|
||
"usedInToolCall": true,
|
||
"toolChoice": false,
|
||
"functionCall": false,
|
||
"customCQPrompt": "",
|
||
"customExtractPrompt": "",
|
||
"defaultSystemChatPrompt": "",
|
||
"defaultConfig": {
|
||
"temperature": 1,
|
||
"max_tokens": null,
|
||
"stream": false
|
||
}
|
||
},
|
||
{
|
||
"provider": "OpenAI",
|
||
"model": "o1-preview",
|
||
"name": "o1-preview",
|
||
"maxContext": 125000,
|
||
"maxResponse": 32000,
|
||
"quoteMaxToken": 120000,
|
||
"maxTemperature": 1.2,
|
||
"charsPointsPrice": 0,
|
||
"censor": false,
|
||
"vision": false,
|
||
"datasetProcess": true,
|
||
"usedInClassify": true,
|
||
"usedInExtractFields": true,
|
||
"usedInToolCall": true,
|
||
"toolChoice": false,
|
||
"functionCall": false,
|
||
"customCQPrompt": "",
|
||
"customExtractPrompt": "",
|
||
"defaultSystemChatPrompt": "",
|
||
"defaultConfig": {
|
||
"temperature": 1,
|
||
"max_tokens": null,
|
||
"stream": false
|
||
}
|
||
}
|
||
],
|
||
"vectorModels": [
|
||
{
|
||
"provider": "OpenAI",
|
||
"model": "text-embedding-3-small",
|
||
"name": "text-embedding-3-small",
|
||
"charsPointsPrice": 0,
|
||
"defaultToken": 512,
|
||
"maxToken": 3000,
|
||
"weight": 100
|
||
},
|
||
{
|
||
"provider": "OpenAI",
|
||
"model": "text-embedding-3-large",
|
||
"name": "text-embedding-3-large",
|
||
"charsPointsPrice": 0,
|
||
"defaultToken": 512,
|
||
"maxToken": 3000,
|
||
"weight": 100,
|
||
"defaultConfig": {
|
||
"dimensions": 1024
|
||
}
|
||
},
|
||
{
|
||
"provider": "OpenAI",
|
||
"model": "text-embedding-ada-002", // 模型名(与OneAPI对应)
|
||
"name": "Embedding-2", // 模型展示名
|
||
"charsPointsPrice": 0, // n积分/1k token
|
||
"defaultToken": 700, // 默认文本分割时候的 token
|
||
"maxToken": 3000, // 最大 token
|
||
"weight": 100, // 优先训练权重
|
||
"defaultConfig": {}, // 自定义额外参数。例如,如果希望使用 embedding3-large 的话,可以传入 dimensions:1024,来返回1024维度的向量。(目前必须小于1536维度)
|
||
"dbConfig": {}, // 存储时的额外参数(非对称向量模型时候需要用到)
|
||
"queryConfig": {} // 参训时的额外参数
|
||
}
|
||
],
|
||
"reRankModels": [],
|
||
"audioSpeechModels": [
|
||
{
|
||
"provider": "OpenAI",
|
||
"model": "tts-1",
|
||
"name": "OpenAI TTS1",
|
||
"charsPointsPrice": 0,
|
||
"voices": [
|
||
{ "label": "Alloy", "value": "alloy", "bufferId": "openai-Alloy" },
|
||
{ "label": "Echo", "value": "echo", "bufferId": "openai-Echo" },
|
||
{ "label": "Fable", "value": "fable", "bufferId": "openai-Fable" },
|
||
{ "label": "Onyx", "value": "onyx", "bufferId": "openai-Onyx" },
|
||
{ "label": "Nova", "value": "nova", "bufferId": "openai-Nova" },
|
||
{ "label": "Shimmer", "value": "shimmer", "bufferId": "openai-Shimmer" }
|
||
]
|
||
}
|
||
],
|
||
"whisperModel": {
|
||
"provider": "OpenAI",
|
||
"model": "whisper-1",
|
||
"name": "Whisper1",
|
||
"charsPointsPrice": 0
|
||
}
|
||
}
|
||
```
|
||
|
||
# 通过 OneAPI 接入模型
|
||
## 通过 OneAPI 接入模型
|
||
|
||
FastGPT 目前采用模型分离的部署方案,FastGPT 中只兼容 OpenAI 的模型规范(OpenAI 不存在的模型采用一个较为通用的规范),并通过 [One API](https://github.com/songquanpeng/one-api) 来实现对不同模型接口的统一。
|
||
|
||
[One API](https://github.com/songquanpeng/one-api) 是一个 OpenAI 接口管理 & 分发系统,可以通过标准的 OpenAI API 格式访问所有的大模型,开箱即用。
|
||
|
||
|
||
## FastGPT 与 One API 关系
|
||
|
||
可以把 One API 当做一个网关,FastGPT 与 One API 关系:
|
||
|
||

|
||
|
||
## 部署
|
||
|
||
### Sealos 版本
|
||
|
||
* 北京区: [点击部署 OneAPI](https://hzh.sealos.run/?openapp=system-template%3FtemplateName%3Done-api)
|
||
* 新加坡区(可用 GPT) [点击部署 OneAPI](https://cloud.sealos.io/?openapp=system-template%3FtemplateName%3Done-api&uid=fnWRt09fZP)
|
||
|
||

|
||
|
||
部署完后,可以打开 OneAPI 访问链接,进行下一步操作。
|
||
|
||
## OneAPI 基础教程
|
||
|
||
### 概念
|
||
|
||
1. 渠道:
|
||
1. OneApi 中一个渠道对应一个 `Api Key`,这个 `Api Key` 可以是GPT、微软、ChatGLM、文心一言的。一个`Api Key`通常可以调用同一个厂商的多个模型。
|
||
2. One API 会根据请求传入的`模型`来决定使用哪一个`渠道`,如果一个模型对应了多个`渠道`,则会随机调用。
|
||
2. 令牌:访问 One API 所需的凭证,只需要这`1`个凭证即可访问`One API`上配置的模型。因此`FastGPT`中,只需要配置`One API`的`baseurl`和`令牌`即可。令牌不要设置任何的模型范围权限,否则容易报错。
|
||
|
||

|
||
|
||
### 大致工作流程
|
||
|
||
1. 客户端请求 One API
|
||
2. 根据请求中的 `model` 参数,匹配对应的渠道(根据渠道里的模型进行匹配,必须完全一致)。如果匹配到多个渠道,则随机选择一个(同优先级)。
|
||
3. One API 向真正的地址发出请求。
|
||
4. One API 将结果返回给客户端。
|
||
|
||
### 1. 登录 One API
|
||
|
||

|
||
|
||
### 2. 创建渠道
|
||
|
||
在 One API 中添加对应渠道,直接点击 【添加基础模型】,不要遗漏了向量模型(Embedding)
|
||
|
||

|
||
|
||
### 3. 创建令牌
|
||
|
||
| | |
|
||
| --- | --- |
|
||
|  |  |
|
||
|
||
### 4. 修改账号余额
|
||
|
||
One API 默认 root 用户只有 200刀,可以自行修改编辑。
|
||
|
||

|
||
|
||
### 5. 修改 FastGPT 的环境变量
|
||
|
||
有了 One API 令牌后,FastGPT 可以通过修改 `baseurl` 和 `key` 去请求到 One API,再由 One API 去请求不同的模型。修改下面两个环境变量:
|
||
|
||
```bash
|
||
# 务必写上 v1。如果在同一个网络内,可改成内网地址。
|
||
OPENAI_BASE_URL=https://xxxx.cloud.sealos.io/v1
|
||
# 下面的 key 是由 One API 提供的令牌
|
||
CHAT_API_KEY=sk-xxxxxx
|
||
```
|
||
|
||
## 接入其他模型
|
||
|
||
**以添加文心一言为例:**
|
||
|
||
### 1. OneAPI 新增模型渠道
|
||
|
||
类型选择百度文心千帆。
|
||
|
||

|
||
|
||
### 2. 修改 FastGPT 模型配置
|
||
|
||
打开 FastGPT 模型配置,启动文心千帆模型,如果希望未内置,可以通过新增模型来配置。
|
||
|
||

|
||
|
||
|
||
## 其他服务商接入参考
|
||
|
||
这章介绍一些提供商接入 OneAPI 的教程,配置后不要忘记在 FastGPT 模型配置中启用。
|
||
|
||
### 阿里通义千问
|
||
|
||
千问目前已经兼容 GPT 格式,可以直接选择 OpenAI 类型来接入即可。如下图,选择类型为`OpenAI`,代理填写阿里云的代理地址。
|
||
|
||
目前可以直接使用阿里云的语言模型和 `text-embedding-v3` 向量模型(实测已经归一化,可直接使用)
|
||
|
||

|
||
|
||
### 硅基流动 —— 开源模型大合集
|
||
|
||
[硅基流动](https://cloud.siliconflow.cn/i/TR9Ym0c4) 是一个专门提供开源模型调用平台,并拥有自己的加速引擎。模型覆盖面广,非常适合低成本来测试开源模型。接入教程:
|
||
|
||
1. [点击注册硅基流动账号](https://cloud.siliconflow.cn/i/TR9Ym0c4)
|
||
2. 进入控制台,获取 API key: https://cloud.siliconflow.cn/account/ak
|
||
3. 新增 OneAPI 渠道,选择`OpenAI`类型,代理填写:`https://api.siliconflow.cn`,密钥是第二步创建的密钥。
|
||
|
||

|
||
|
||
由于 OneAPI 未内置 硅基流动 的模型名,可以通过自定义模型名称来填入,下面是获取模型名称的教程:
|
||
|
||
1. 打开[硅基流动模型列表](https://siliconflow.cn/zh-cn/models)
|
||
2. 单击模型后,会打开模型详情。
|
||
3. 复制模型名到 OneAPI 中。
|
||
|
||
| | | |
|
||
| --- | --- | --- |
|
||
|  | |  |
|
||
|
||
# 通过 PPIO LLM API 接入模型
|
||
## 通过 PPIO LLM API 接入模型
|
||
|
||
FastGPT 还可以通过 PPIO LLM API 接入模型。
|
||
{{% alert context="warning" %}}
|
||
以下内容搬运自 [FastGPT 接入 PPIO LLM API](https://ppinfra.com/docs/third-party/fastgpt-use),可能会有更新不及时的情况。
|
||
{{% /alert %}}
|
||
|
||
FastGPT 是一个将 AI 开发、部署和使用全流程简化为可视化操作的平台。它使开发者不需要深入研究算法,
|
||
用户也不需要掌握复杂技术,通过一站式服务将人工智能技术变成易于使用的工具。
|
||
|
||
PPIO 派欧云提供简单易用的 API 接口,让开发者能够轻松调用 DeepSeek 等模型。
|
||
|
||
- 对开发者:无需重构架构,3 个接口完成从文本生成到决策推理的全场景接入,像搭积木一样设计 AI 工作流;
|
||
- 对生态:自动适配从中小应用到企业级系统的资源需求,让智能随业务自然生长。
|
||
|
||
下方教程提供完整接入方案(含密钥配置),帮助您快速将 FastGPT 与 PPIO API 连接起来。
|
||
|
||
## 1. 配置前置条件
|
||
|
||
(1) 获取 API 接口地址
|
||
|
||
固定为: `https://api.ppinfra.com/v3/openai/chat/completions`。
|
||
|
||
(2) 获取 【API 密钥】
|
||
|
||
登录派欧云控制台 [API 秘钥管理](https://www.ppinfra.com/settings/key-management) 页面,点击创建按钮。
|
||
注册账号填写邀请码【VOJL20】得 50 代金券
|
||
|
||
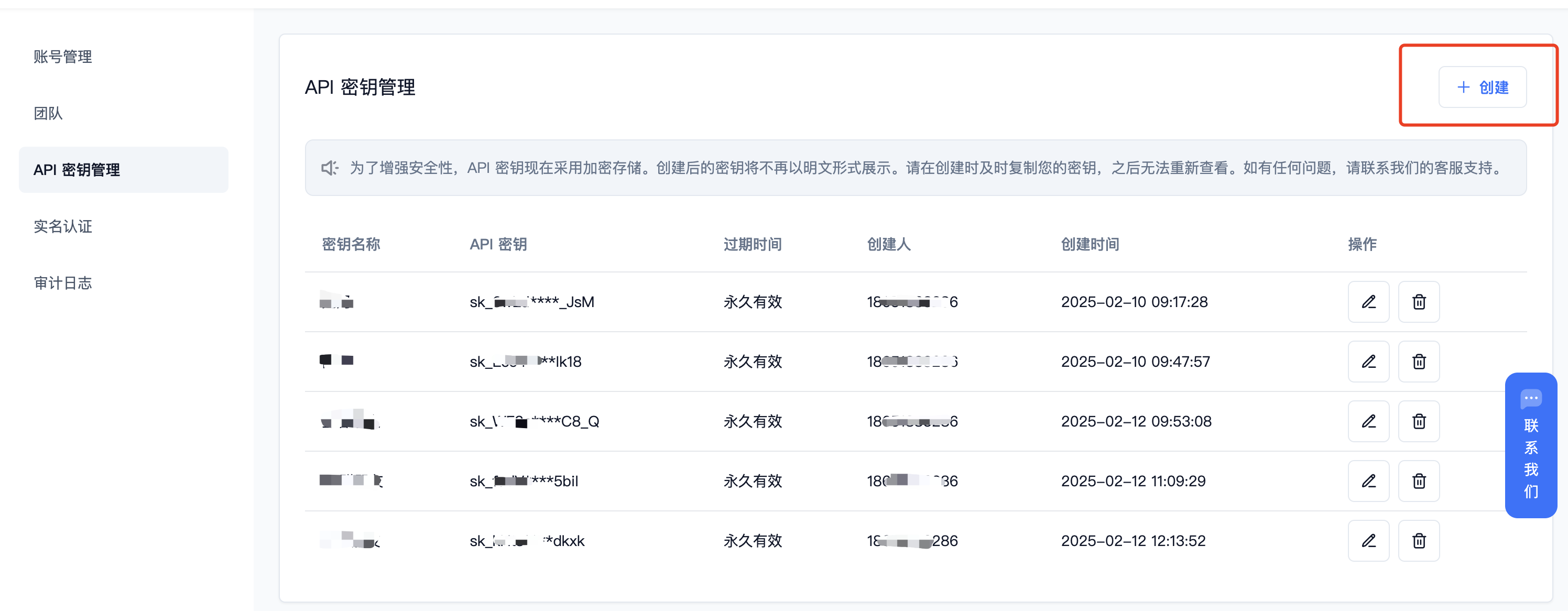
|
||
|
||
(3) 生成并保存 【API 密钥】
|
||
{{% alert context="warning" %}}
|
||
秘钥在服务端是加密存储,请在生成时保存好秘钥;若遗失可以在控制台上删除并创建一个新的秘钥。
|
||
{{% /alert %}}
|
||
|
||
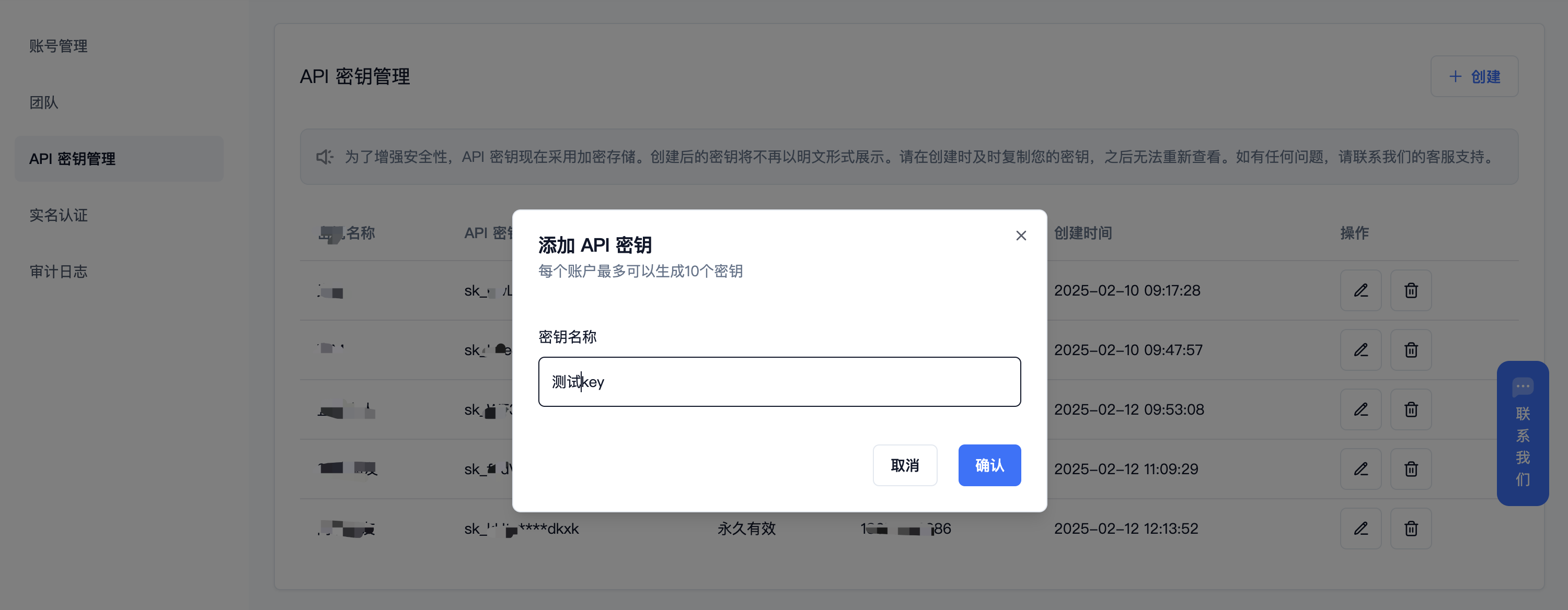
|
||
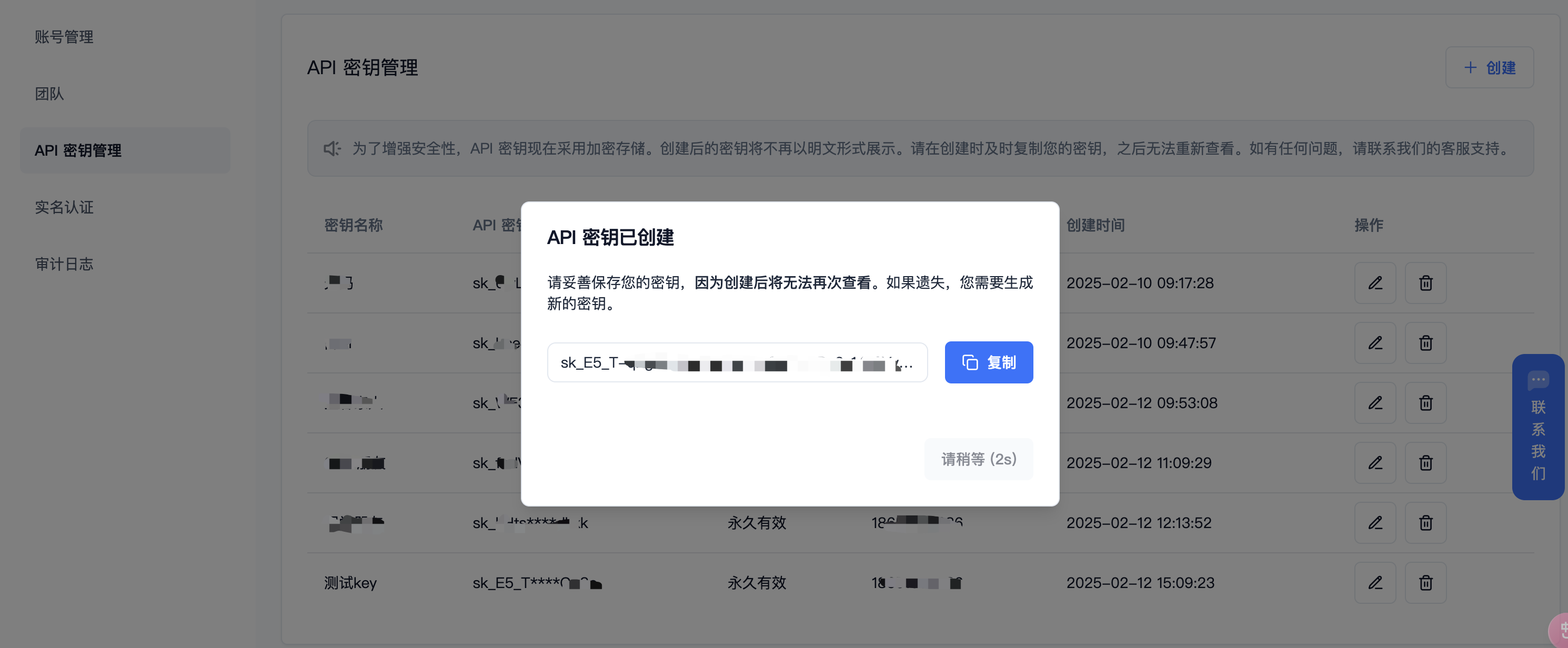
|
||
|
||
(4) 获取需要使用的模型 ID
|
||
|
||
deepseek 系列:
|
||
|
||
- DeepSeek R1:deepseek/deepseek-r1/community
|
||
|
||
- DeepSeek V3:deepseek/deepseek-v3/community
|
||
|
||
其他模型 ID、最大上下文及价格可参考:[模型列表](https://ppinfra.com/model-api/pricing)
|
||
|
||
## 2. 部署最新版 FastGPT 到本地环境
|
||
{{% alert context="warning" %}}
|
||
请使用 v4.8.22 以上版本,部署参考: https://doc.tryfastgpt.ai/docs/development/intro/
|
||
{{% /alert %}}
|
||
|
||
## 3. 模型配置(下面两种方式二选其一)
|
||
|
||
(1)通过 OneAPI 接入模型 PPIO 模型: 参考 OneAPI 使用文档,修改 FastGPT 的环境变量 在 One API 生成令牌后,FastGPT 可以通过修改 baseurl 和 key 去请求到 One API,再由 One API 去请求不同的模型。修改下面两个环境变量: 务必写上 v1。如果在同一个网络内,可改成内网地址。
|
||
|
||
OPENAI_BASE_URL= http://OneAPI-IP:OneAPI-PORT/v1
|
||
|
||
下面的 key 是由 One API 提供的令牌 CHAT_API_KEY=sk-UyVQcpQWMU7ChTVl74B562C28e3c46Fe8f16E6D8AeF8736e
|
||
|
||
- 修改后重启 FastGPT,按下图在模型提供商中选择派欧云
|
||
|
||
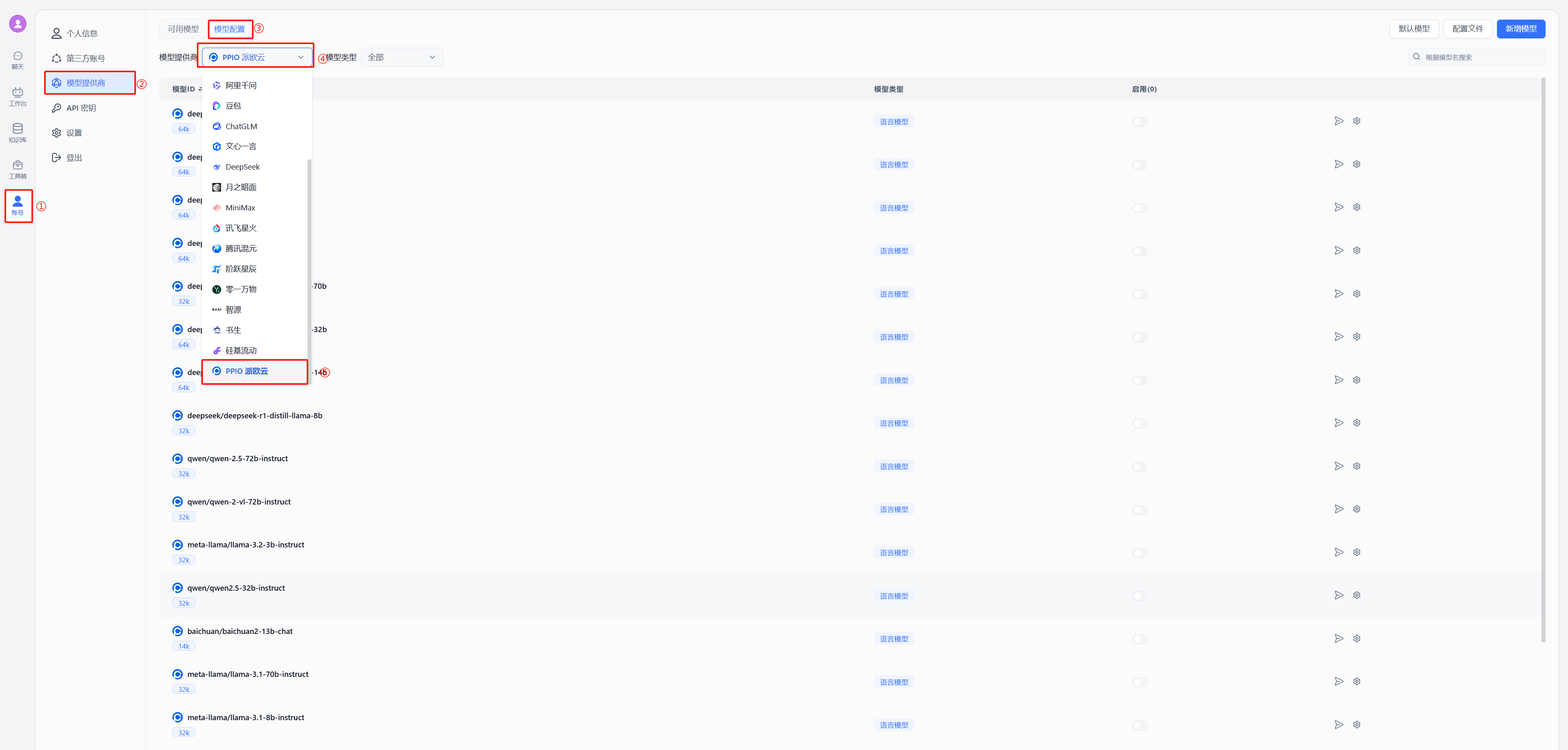
|
||
|
||
- 测试连通性
|
||
以 deepseek 为例,在模型中选择使用 deepseek/deepseek-r1/community,点击图中②的位置进行连通性测试,出现图中绿色的的成功显示证明连通成功,可以进行后续的配置对话了
|
||
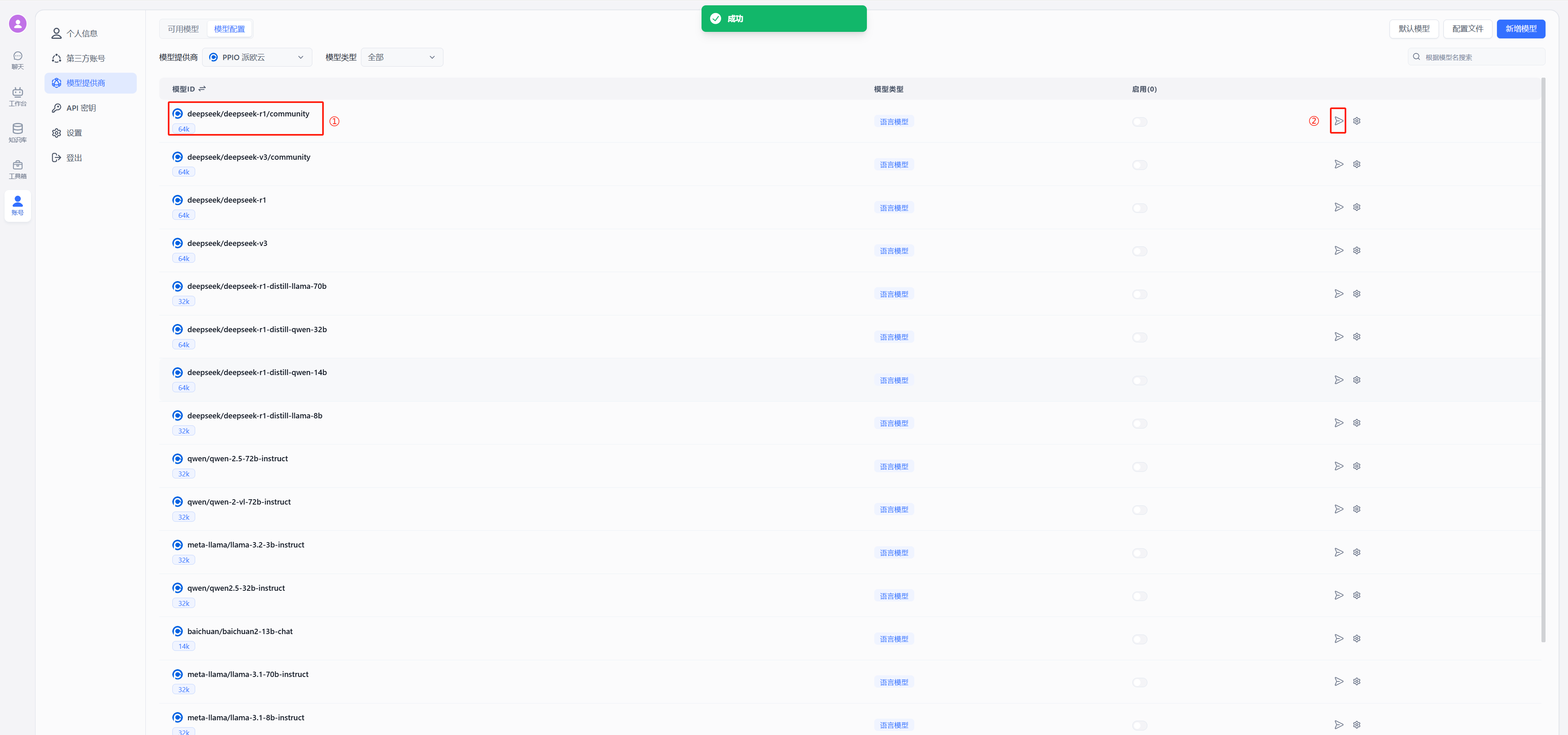
|
||
|
||
(2)不使用 OneAPI 接入 PPIO 模型
|
||
|
||
按照下图在模型提供商中选择派欧云
|
||
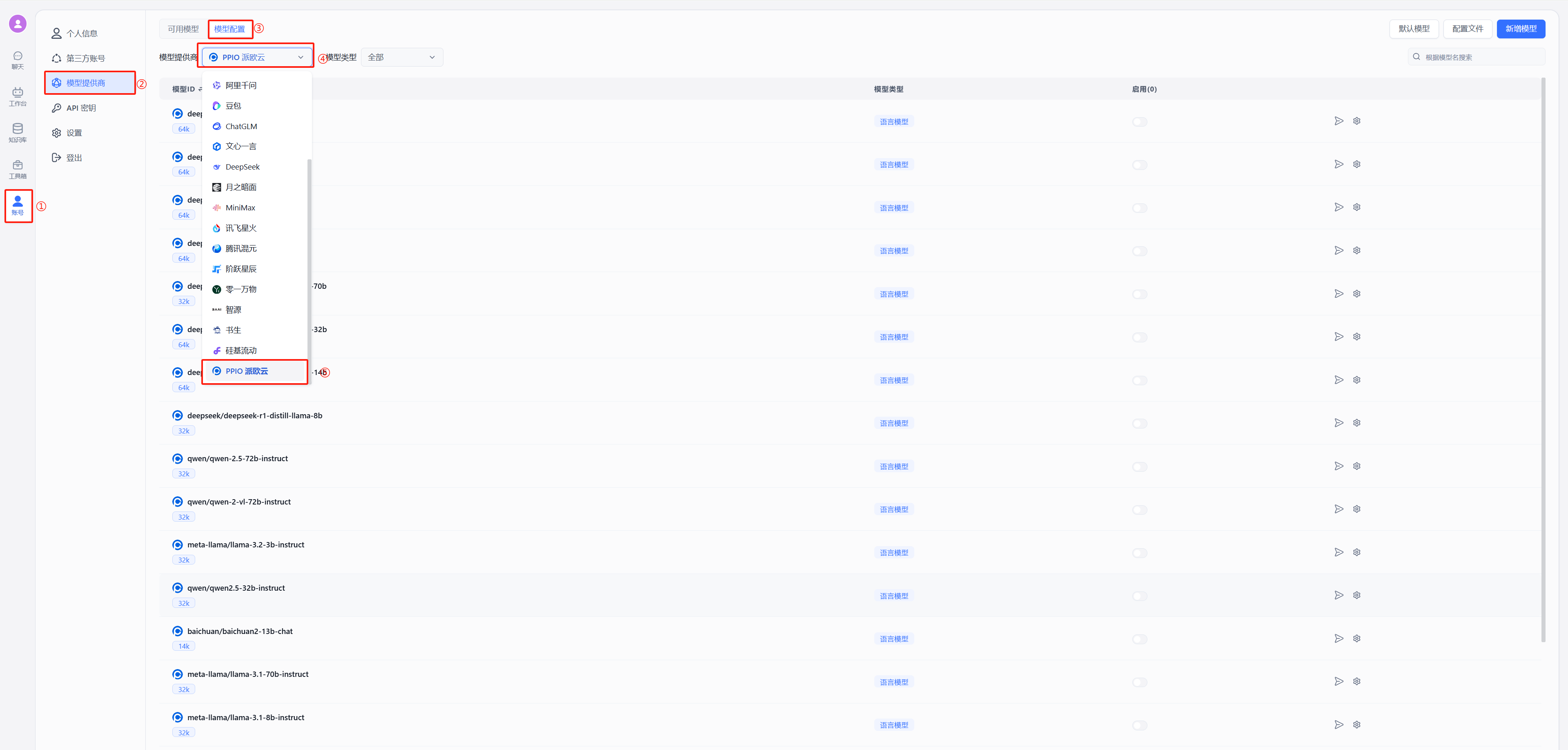
|
||
|
||
- 配置模型 自定义请求地址中输入:`https://api.ppinfra.com/v3/openai/chat/completions`
|
||
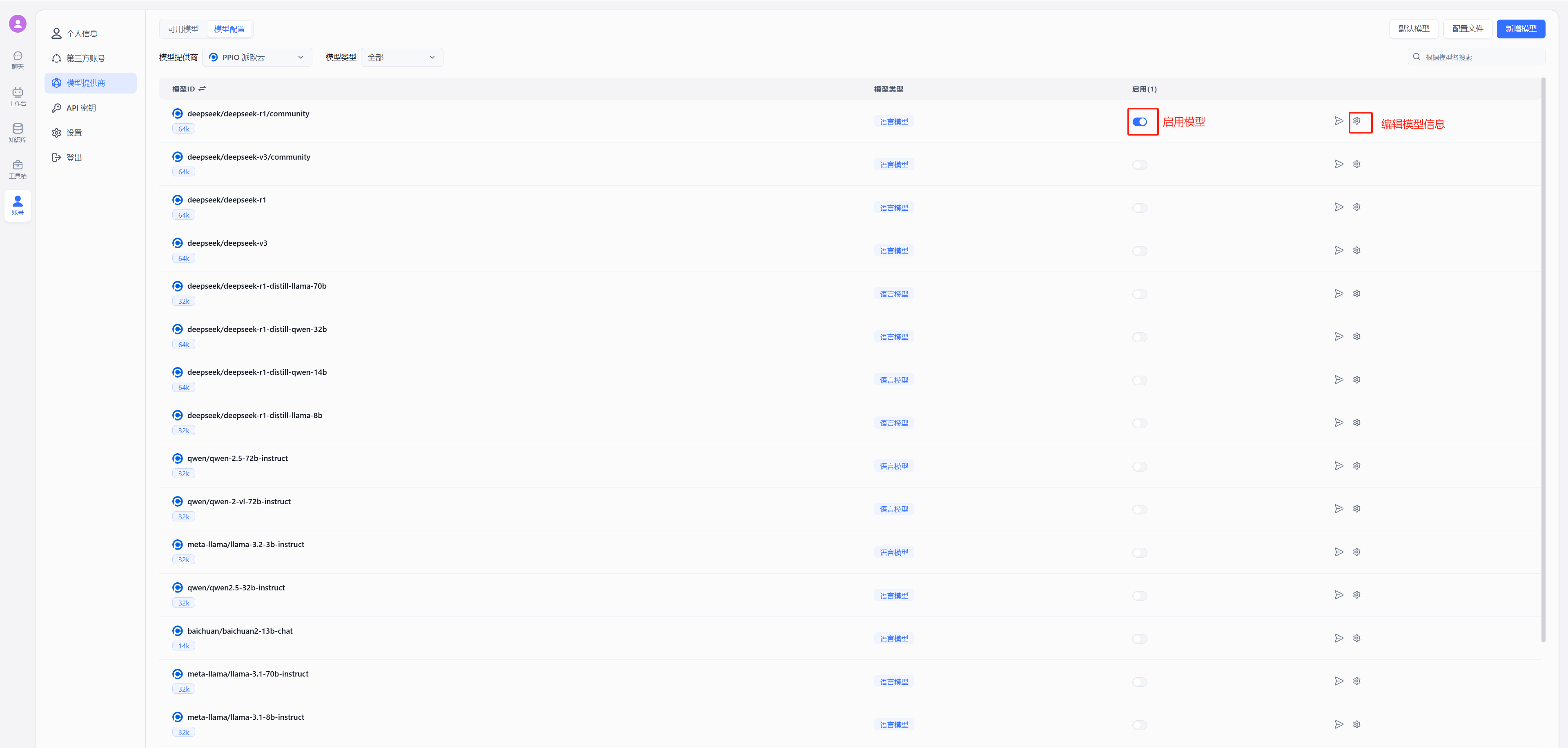
|
||
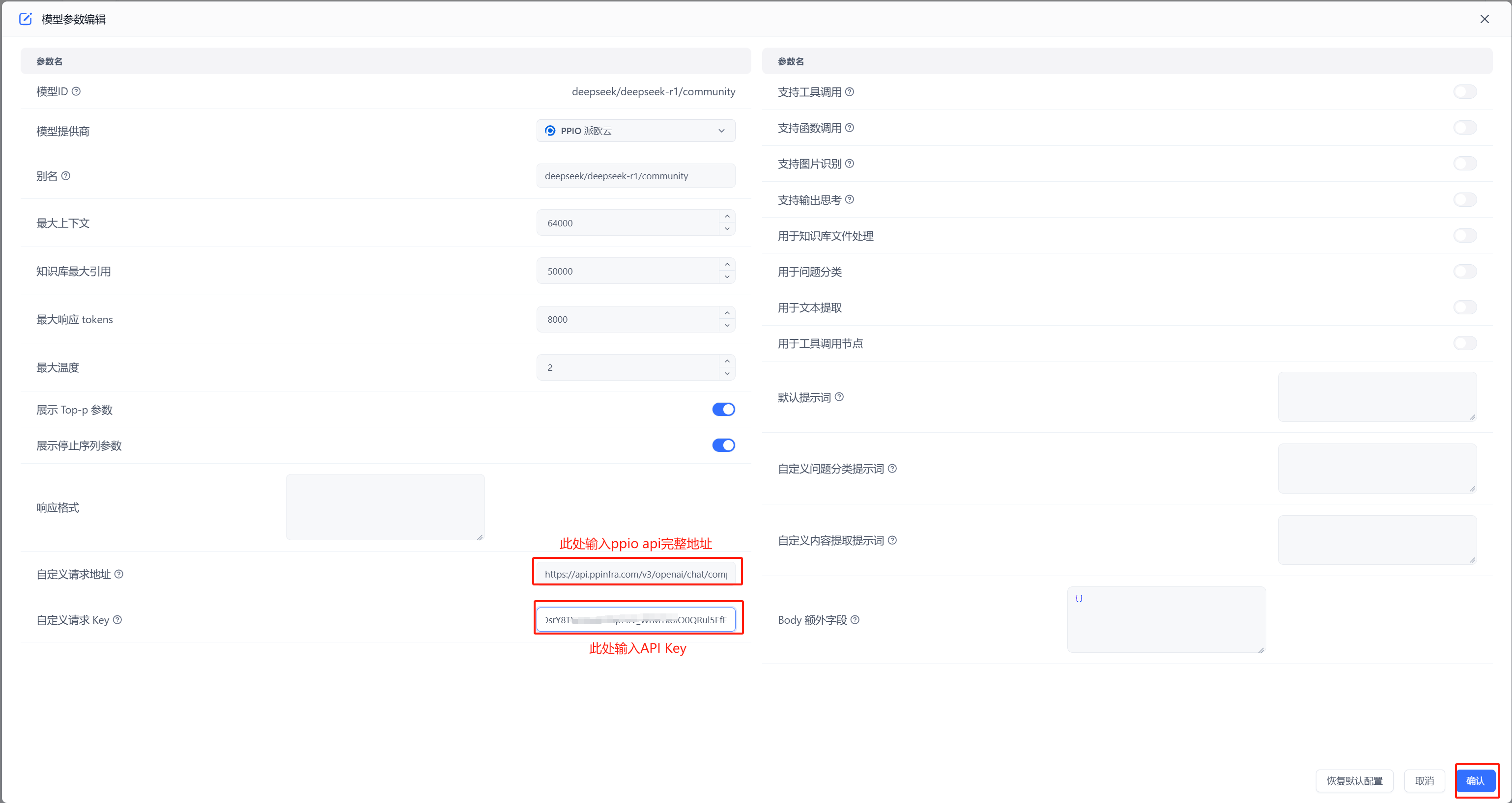
|
||
|
||
- 测试连通性
|
||
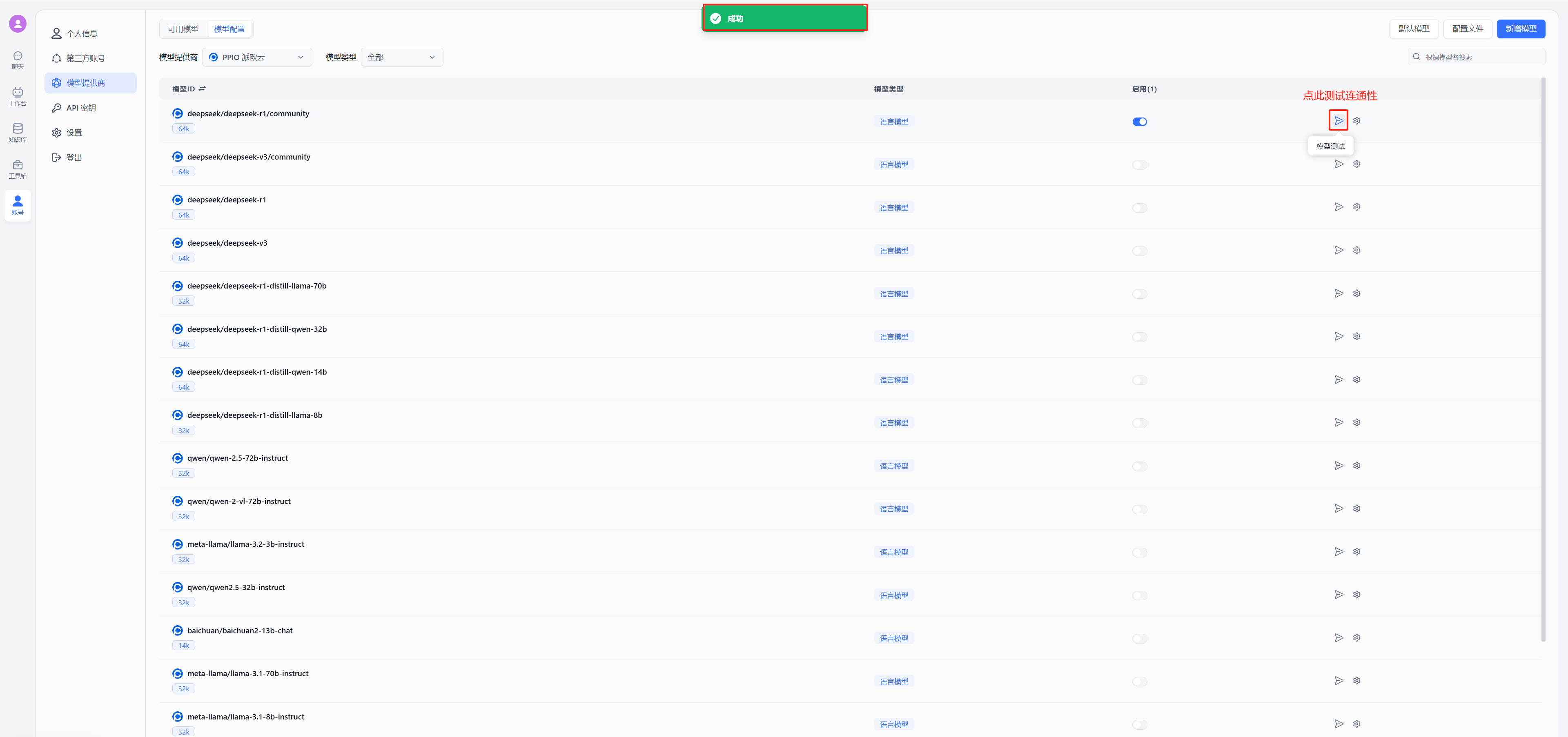
|
||
|
||
出现图中绿色的的成功显示证明连通成功,可以进行对话配置
|
||
|
||
## 4. 配置对话
|
||
(1)新建工作台
|
||
|
||
(2)开始聊天
|
||
|
||
|
||
## PPIO 全新福利重磅来袭 🔥
|
||
顺利完成教程配置步骤后,您将解锁两大权益:1. 畅享 PPIO 高速通道与 FastGPT 的效能组合;2.立即激活 **「新用户邀请奖励」** ————通过专属邀请码邀好友注册,您与好友可各领 50 元代金券,硬核福利助力 AI 工具效率倍增!
|
||
|
||
🎁 新手专享:立即使用邀请码【VOJL20】完成注册,50 元代金券奖励即刻到账!
|
||
|
||
# 通过 SiliconCloud 体验开源模型
|
||
## 通过 SiliconCloud 体验开源模型
|
||
|
||
[SiliconCloud(硅基流动)](https://cloud.siliconflow.cn/i/TR9Ym0c4) 是一个以提供开源模型调用为主的平台,并拥有自己的加速引擎。帮助用户低成本、快速的进行开源模型的测试和使用。实际体验下来,他们家模型的速度和稳定性都非常不错,并且种类丰富,覆盖语言、向量、重排、TTS、STT、绘图、视频生成模型,可以满足 FastGPT 中所有模型需求。
|
||
|
||
如果你想部分模型使用 SiliconCloud 的模型,可额外参考[OneAPI接入硅基流动](/docs/development/modelconfig/one-api/#硅基流动--开源模型大合集)。
|
||
|
||
本文会介绍完全使用 SiliconCloud 模型来部署 FastGPT 的方案。
|
||
|
||
|
||
## 1. 注册 SiliconCloud 账号
|
||
|
||
1. [点击注册硅基流动账号](https://cloud.siliconflow.cn/i/TR9Ym0c4)
|
||
2. 进入控制台,获取 API key: https://cloud.siliconflow.cn/account/ak
|
||
|
||
## 2. 修改 FastGPT 环境变量
|
||
|
||
```bash
|
||
OPENAI_BASE_URL=https://api.siliconflow.cn/v1
|
||
# 填写 SiliconCloud 控制台提供的 Api Key
|
||
CHAT_API_KEY=sk-xxxxxx
|
||
```
|
||
|
||
## 3. 修改 FastGPT 模型配置
|
||
|
||
系统内置了几个硅基流动的模型进行体验,如果需要其他模型,可以手动添加。
|
||
|
||
这里启动了 `Qwen2.5 72b` 的纯语言和视觉模型;选择 `bge-m3` 作为向量模型;选择 `bge-reranker-v2-m3` 作为重排模型。选择 `fish-speech-1.5` 作为语音模型;选择 `SenseVoiceSmall` 作为语音输入模型。
|
||
|
||

|
||
|
||
## 4. 体验测试
|
||
|
||
### 测试对话和图片识别
|
||
|
||
随便新建一个简易应用,选择对应模型,并开启图片上传后进行测试:
|
||
|
||
| | |
|
||
| --- | --- |
|
||
|  |  |
|
||
|
||
可以看到,72B 的模型,性能还是非常快的,这要是本地没几个 4090,不说配置环境,输出怕都要 30s 了。
|
||
|
||
### 测试知识库导入和知识库问答
|
||
|
||
新建一个知识库(由于只配置了一个向量模型,页面上不会展示向量模型选择)
|
||
|
||
| | |
|
||
| --- | --- |
|
||
|  |  |
|
||
|
||
导入本地文件,直接选择文件,然后一路下一步即可。79 个索引,大概花了 20s 的时间就完成了。现在我们去测试一下知识库问答。
|
||
|
||
首先回到我们刚创建的应用,选择知识库,调整一下参数后即可开始对话:
|
||
|
||
| | | |
|
||
| --- | --- | --- |
|
||
|  |  |  |
|
||
|
||
对话完成后,点击底部的引用,可以查看引用详情,同时可以看到具体的检索和重排得分:
|
||
|
||
| | |
|
||
| --- | --- |
|
||
|  |  |
|
||
|
||
### 测试语音播放
|
||
|
||
继续在刚刚的应用中,左侧配置中找到语音播放,点击后可以从弹窗中选择语音模型,并进行试听:
|
||
|
||

|
||
|
||
### 测试语言输入
|
||
|
||
继续在刚刚的应用中,左侧配置中找到语音输入,点击后可以从弹窗中开启语言输入
|
||
|
||

|
||
|
||
开启后,对话输入框中,会增加一个话筒的图标,点击可进行语音输入:
|
||
|
||
| | |
|
||
| --- | --- |
|
||
|  |  |
|
||
|
||
## 总结
|
||
|
||
如果你想快速的体验开源模型或者快速的使用 FastGPT,不想在不同服务商申请各类 Api Key,那么可以选择 SiliconCloud 的模型先进行快速体验。
|
||
|
||
如果你决定未来私有化部署模型和 FastGPT,前期可通过 SiliconCloud 进行测试验证,后期再进行硬件采购,减少 POC 时间和成本。
|
||
|
||
# 对话接口
|
||
## FastGPT OpenAPI 对话接口
|
||
|
||
# 如何获取 AppId
|
||
|
||
可在应用详情的路径里获取 AppId。
|
||
|
||

|
||
|
||
# 发起对话
|
||
|
||
{{% alert icon="🤖 " context="success" %}}
|
||
* 该接口的 API Key 需使用`应用特定的 key`,否则会报错。
|
||
|
||
<!-- * 对话现在有`v1`和`v2`两个接口,可以按需使用,v2 自 4.9.4 版本新增,v1 接口同时不再维护 -->
|
||
|
||
* 有些包调用时,`BaseUrl`需要添加`v1`路径,有些不需要,如果出现404情况,可补充`v1`重试。
|
||
{{% /alert %}}
|
||
|
||
## 请求简易应用和工作流
|
||
|
||
`v1`对话接口兼容`GPT`的接口!如果你的项目使用的是标准的`GPT`官方接口,可以直接通过修改`BaseUrl`和 `Authorization`来访问 FastGpt 应用,不过需要注意下面几个规则:
|
||
|
||
{{% alert icon="🤖 " context="success" %}}
|
||
* 传入的`model`,`temperature`等参数字段均无效,这些字段由编排决定,不会根据 API 参数改变。
|
||
* 不会返回实际消耗`Token`值,如果需要,可以设置`detail=true`,并手动计算 `responseData` 里的`tokens`值。
|
||
{{% /alert %}}
|
||
|
||
### 请求
|
||
|
||
{{< tabs tabTotal="3" >}}
|
||
{{< tab tabName="基础请求示例" >}}
|
||
{{< markdownify >}}
|
||
|
||
```bash
|
||
curl --location --request POST 'http://localhost:3000/api/v1/chat/completions' \
|
||
--header 'Authorization: Bearer fastgpt-xxxxxx' \
|
||
--header 'Content-Type: application/json' \
|
||
--data-raw '{
|
||
"chatId": "my_chatId",
|
||
"stream": false,
|
||
"detail": false,
|
||
"responseChatItemId": "my_responseChatItemId",
|
||
"variables": {
|
||
"uid": "asdfadsfasfd2323",
|
||
"name": "张三"
|
||
},
|
||
"messages": [
|
||
{
|
||
"role": "user",
|
||
"content": "导演是谁"
|
||
}
|
||
]
|
||
}'
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="图片/文件请求示例" >}}
|
||
{{< markdownify >}}
|
||
|
||
* 仅`messages`有部分区别,其他参数一致。
|
||
* 目前不支持上传文件,需上传到自己的对象存储中,获取对应的文件链接。
|
||
|
||
```bash
|
||
curl --location --request POST 'http://localhost:3000/api/v1/chat/completions' \
|
||
--header 'Authorization: Bearer fastgpt-xxxxxx' \
|
||
--header 'Content-Type: application/json' \
|
||
--data-raw '{
|
||
"chatId": "abcd",
|
||
"stream": false,
|
||
"messages": [
|
||
{
|
||
"role": "user",
|
||
"content": [
|
||
{
|
||
"type": "text",
|
||
"text": "导演是谁"
|
||
},
|
||
{
|
||
"type": "image_url",
|
||
"image_url": {
|
||
"url": "图片链接"
|
||
}
|
||
},
|
||
{
|
||
"type": "file_url",
|
||
"name": "文件名",
|
||
"url": "文档链接,支持 txt md html word pdf ppt csv excel"
|
||
}
|
||
]
|
||
}
|
||
]
|
||
}'
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="参数说明" >}}
|
||
{{< markdownify >}}
|
||
|
||
{{% alert context="info" %}}
|
||
- headers.Authorization: Bearer {{apikey}}
|
||
- chatId: string | undefined 。
|
||
- 为 `undefined` 时(不传入),不使用 FastGpt 提供的上下文功能,完全通过传入的 messages 构建上下文。
|
||
- 为`非空字符串`时,意味着使用 chatId 进行对话,自动从 FastGpt 数据库取历史记录,并使用 messages 数组最后一个内容作为用户问题,其余 message 会被忽略。请自行确保 chatId 唯一,长度小于250,通常可以是自己系统的对话框ID。
|
||
- messages: 结构与 [GPT接口](https://platform.openai.com/docs/api-reference/chat/object) chat模式一致。
|
||
- responseChatItemId: string | undefined 。如果传入,则会将该值作为本次对话的响应消息的 ID,FastGPT 会自动将该 ID 存入数据库。请确保,在当前`chatId`下,`responseChatItemId`是唯一的。
|
||
- detail: 是否返回中间值(模块状态,响应的完整结果等),`stream模式`下会通过`event`进行区分,`非stream模式`结果保存在`responseData`中。
|
||
- variables: 模块变量,一个对象,会替换模块中,输入框内容里的`{{key}}`
|
||
{{% /alert %}}
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
{{< /tabs >}}
|
||
|
||
<!-- #### v2
|
||
|
||
v1,v2 接口请求参数一致,仅请求地址不一样。
|
||
|
||
{{< tabs tabTotal="3" >}}
|
||
{{< tab tabName="基础请求示例" >}}
|
||
{{< markdownify >}}
|
||
|
||
```bash
|
||
curl --location --request POST 'http://localhost:3000/api/v2/chat/completions' \
|
||
--header 'Authorization: fastgpt-xxxxxx' \
|
||
--header 'Content-Type: application/json' \
|
||
--data-raw '{
|
||
"chatId": "my_chatId",
|
||
"stream": false,
|
||
"detail": false,
|
||
"responseChatItemId": "my_responseChatItemId",
|
||
"variables": {
|
||
"uid": "asdfadsfasfd2323",
|
||
"name": "张三"
|
||
},
|
||
"messages": [
|
||
{
|
||
"role": "user",
|
||
"content": "你是谁"
|
||
}
|
||
]
|
||
}'
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="图片/文件请求示例" >}}
|
||
{{< markdownify >}}
|
||
|
||
* 仅`messages`有部分区别,其他参数一致。
|
||
* 目前不支持上传文件,需上传到自己的对象存储中,获取对应的文件链接。
|
||
|
||
```bash
|
||
curl --location --request POST 'http://localhost:3000/api/v2/chat/completions' \
|
||
--header 'Authorization: Bearer fastgpt-xxxxxx' \
|
||
--header 'Content-Type: application/json' \
|
||
--data-raw '{
|
||
"chatId": "abcd",
|
||
"stream": false,
|
||
"messages": [
|
||
{
|
||
"role": "user",
|
||
"content": [
|
||
{
|
||
"type": "text",
|
||
"text": "导演是谁"
|
||
},
|
||
{
|
||
"type": "image_url",
|
||
"image_url": {
|
||
"url": "图片链接"
|
||
}
|
||
},
|
||
{
|
||
"type": "file_url",
|
||
"name": "文件名",
|
||
"url": "文档链接,支持 txt md html word pdf ppt csv excel"
|
||
}
|
||
]
|
||
}
|
||
]
|
||
}'
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="参数说明" >}}
|
||
{{< markdownify >}}
|
||
|
||
{{% alert context="info" %}}
|
||
- headers.Authorization: Bearer {{apikey}}
|
||
- chatId: string | undefined 。
|
||
- 为 `undefined` 时(不传入),不使用 FastGpt 提供的上下文功能,完全通过传入的 messages 构建上下文。
|
||
- 为`非空字符串`时,意味着使用 chatId 进行对话,自动从 FastGpt 数据库取历史记录,并使用 messages 数组最后一个内容作为用户问题,其余 message 会被忽略。请自行确保 chatId 唯一,长度小于250,通常可以是自己系统的对话框ID。
|
||
- messages: 结构与 [GPT接口](https://platform.openai.com/docs/api-reference/chat/object) chat模式一致。
|
||
- responseChatItemId: string | undefined 。如果传入,则会将该值作为本次对话的响应消息的 ID,FastGPT 会自动将该 ID 存入数据库。请确保,在当前`chatId`下,`responseChatItemId`是唯一的。
|
||
- detail: 是否返回中间值(模块状态,响应的完整结果等),`stream模式`下会通过`event`进行区分,`非stream模式`结果保存在`responseData`中。
|
||
- variables: 模块变量,一个对象,会替换模块中,输入框内容里的`{{key}}`
|
||
{{% /alert %}}
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
{{< /tabs >}}
|
||
|
||
#### v1
|
||
|
||
|
||
|
||
### 响应
|
||
|
||
#### v2
|
||
|
||
v2 接口比起 v1,主要变变化在于:会在每个节点运行结束后及时返回 response,而不是等工作流结束后再统一返回。
|
||
|
||
{{< tabs tabTotal="5" >}}
|
||
{{< tab tabName="detail=false,stream=false 响应" >}}
|
||
{{< markdownify >}}
|
||
|
||
```json
|
||
{
|
||
"id": "",
|
||
"model": "",
|
||
"usage": {
|
||
"prompt_tokens": 1,
|
||
"completion_tokens": 1,
|
||
"total_tokens": 1
|
||
},
|
||
"choices": [
|
||
{
|
||
"message": {
|
||
"role": "assistant",
|
||
"content": "我是一个人工智能助手,旨在回答问题和提供信息。如果你有任何问题或者需要帮助,随时问我!"
|
||
},
|
||
"finish_reason": "stop",
|
||
"index": 0
|
||
}
|
||
]
|
||
}
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="detail=false,stream=true 响应" >}}
|
||
{{< markdownify >}}
|
||
|
||
|
||
```bash
|
||
data: {"id":"","object":"","created":0,"model":"","choices":[{"delta":{"role":"assistant","content":"你好"},"index":0,"finish_reason":null}]}
|
||
|
||
data: {"id":"","object":"","created":0,"model":"","choices":[{"delta":{"role":"assistant","content":"!"},"index":0,"finish_reason":null}]}
|
||
|
||
data: {"id":"","object":"","created":0,"model":"","choices":[{"delta":{"role":"assistant","content":"今天"},"index":0,"finish_reason":null}]}
|
||
|
||
data: {"id":"","object":"","created":0,"model":"","choices":[{"delta":{"role":"assistant","content":"过得怎么样?"},"index":0,"finish_reason":null}]}
|
||
|
||
data: {"id":"","object":"","created":0,"model":"","choices":[{"delta":{"role":"assistant","content":null},"index":0,"finish_reason":"stop"}]}
|
||
|
||
data: [DONE]
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="detail=true,stream=false 响应" >}}
|
||
{{< markdownify >}}
|
||
|
||
```json
|
||
{
|
||
"responseData": [
|
||
{
|
||
"id": "iSol79OFrBH1I9kC",
|
||
"nodeId": "448745",
|
||
"moduleName": "common:core.module.template.work_start",
|
||
"moduleType": "workflowStart",
|
||
"runningTime": 0
|
||
},
|
||
{
|
||
"id": "t1T94WCy6Su3BK4V",
|
||
"nodeId": "fjLpE3XPegmoGtbU",
|
||
"moduleName": "AI 对话",
|
||
"moduleType": "chatNode",
|
||
"runningTime": 1.46,
|
||
"totalPoints": 0,
|
||
"model": "GPT-4o-mini",
|
||
"tokens": 64,
|
||
"inputTokens": 10,
|
||
"outputTokens": 54,
|
||
"query": "你是谁",
|
||
"reasoningText": "",
|
||
"historyPreview": [
|
||
{
|
||
"obj": "Human",
|
||
"value": "你是谁"
|
||
},
|
||
{
|
||
"obj": "AI",
|
||
"value": "我是一个人工智能助手,旨在帮助回答问题和提供信息。如果你有任何问题或需要帮助,请告诉我!"
|
||
}
|
||
],
|
||
"contextTotalLen": 2
|
||
}
|
||
],
|
||
"newVariables": {
|
||
|
||
},
|
||
"id": "",
|
||
"model": "",
|
||
"usage": {
|
||
"prompt_tokens": 1,
|
||
"completion_tokens": 1,
|
||
"total_tokens": 1
|
||
},
|
||
"choices": [
|
||
{
|
||
"message": {
|
||
"role": "assistant",
|
||
"content": "我是一个人工智能助手,旨在帮助回答问题和提供信息。如果你有任何问题或需要帮助,请告诉我!"
|
||
},
|
||
"finish_reason": "stop",
|
||
"index": 0
|
||
}
|
||
]
|
||
}
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
|
||
{{< tab tabName="detail=true,stream=true 响应" >}}
|
||
{{< markdownify >}}
|
||
|
||
```bash
|
||
event: flowNodeResponse
|
||
data: {"id":"iYv2uA9rCWAtulWo","nodeId":"workflowStartNodeId","moduleName":"流程开始","moduleType":"workflowStart","runningTime":0}
|
||
|
||
event: flowNodeStatus
|
||
data: {"status":"running","name":"AI 对话"}
|
||
|
||
event: answer
|
||
data: {"id":"","object":"","created":0,"model":"","choices":[{"delta":{"role":"assistant","content":"你好"},"index":0,"finish_reason":null}]}
|
||
|
||
event: answer
|
||
data: {"id":"","object":"","created":0,"model":"","choices":[{"delta":{"role":"assistant","content":"!"},"index":0,"finish_reason":null}]}
|
||
|
||
event: answer
|
||
data: {"id":"","object":"","created":0,"model":"","choices":[{"delta":{"role":"assistant","content":"今天"},"index":0,"finish_reason":null}]}
|
||
|
||
event: answer
|
||
data: {"id":"","object":"","created":0,"model":"","choices":[{"delta":{"role":"assistant","content":"过得怎么样?"},"index":0,"finish_reason":null}]}
|
||
|
||
event: flowNodeResponse
|
||
data: {"id":"pVzLBF7M3Ol4n7s6","nodeId":"ixe20AHN3jy74pKf","moduleName":"AI 对话","moduleType":"chatNode","runningTime":1.48,"totalPoints":0.0042,"model":"Qwen-plus","tokens":28,"inputTokens":8,"outputTokens":20,"query":"你好","reasoningText":"","historyPreview":[{"obj":"Human","value":"你好"},{"obj":"AI","value":"你好!今天过得怎么样?"}],"contextTotalLen":2}
|
||
|
||
event: answer
|
||
data: {"id":"","object":"","created":0,"model":"","choices":[{"delta":{"role":"assistant","content":null},"index":0,"finish_reason":"stop"}]}
|
||
|
||
event: answer
|
||
data: [DONE]
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="event值" >}}
|
||
{{< markdownify >}}
|
||
|
||
event取值:
|
||
|
||
- answer: 返回给客户端的文本(最终会算作回答)
|
||
- fastAnswer: 指定回复返回给客户端的文本(最终会算作回答)
|
||
- toolCall: 执行工具
|
||
- toolParams: 工具参数
|
||
- toolResponse: 工具返回
|
||
- flowNodeStatus: 运行到的节点状态
|
||
- flowNodeResponse: 单个节点详细响应
|
||
- updateVariables: 更新变量
|
||
- error: 报错
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
{{< /tabs >}}
|
||
|
||
#### v1 -->
|
||
|
||
{{< tabs tabTotal="5" >}}
|
||
{{< tab tabName="detail=false,stream=false 响应" >}}
|
||
{{< markdownify >}}
|
||
|
||
```json
|
||
{
|
||
"id": "adsfasf",
|
||
"model": "",
|
||
"usage": {
|
||
"prompt_tokens": 1,
|
||
"completion_tokens": 1,
|
||
"total_tokens": 1
|
||
},
|
||
"choices": [
|
||
{
|
||
"message": {
|
||
"role": "assistant",
|
||
"content": "电影《铃芽之旅》的导演是新海诚。"
|
||
},
|
||
"finish_reason": "stop",
|
||
"index": 0
|
||
}
|
||
]
|
||
}
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="detail=false,stream=true 响应" >}}
|
||
{{< markdownify >}}
|
||
|
||
|
||
```bash
|
||
data: {"id":"","object":"","created":0,"choices":[{"delta":{"content":""},"index":0,"finish_reason":null}]}
|
||
|
||
data: {"id":"","object":"","created":0,"choices":[{"delta":{"content":"电"},"index":0,"finish_reason":null}]}
|
||
|
||
data: {"id":"","object":"","created":0,"choices":[{"delta":{"content":"影"},"index":0,"finish_reason":null}]}
|
||
|
||
data: {"id":"","object":"","created":0,"choices":[{"delta":{"content":"《"},"index":0,"finish_reason":null}]}
|
||
```
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="detail=true,stream=false 响应" >}}
|
||
{{< markdownify >}}
|
||
|
||
```json
|
||
{
|
||
"responseData": [ // 不同模块的响应值, 不同版本具体值可能有差异,可先 log 自行查看最新值。
|
||
{
|
||
"moduleName": "Dataset Search",
|
||
"price": 1.2000000000000002,
|
||
"model": "Embedding-2",
|
||
"tokens": 6,
|
||
"similarity": 0.61,
|
||
"limit": 3
|
||
},
|
||
{
|
||
"moduleName": "AI Chat",
|
||
"price": 454.5,
|
||
"model": "FastAI-4k",
|
||
"tokens": 303,
|
||
"question": "导演是谁",
|
||
"answer": "电影《铃芽之旅》的导演是新海诚。",
|
||
"maxToken": 2050,
|
||
"quoteList": [
|
||
{
|
||
"dataset_id": "646627f4f7b896cfd8910e38",
|
||
"id": "8099",
|
||
"q": "本作的主人公是谁?",
|
||
"a": "本作的主人公是名叫铃芽的少女。",
|
||
"source": "手动修改"
|
||
},
|
||
{
|
||
"dataset_id": "646627f4f7b896cfd8910e38",
|
||
"id": "8686",
|
||
"q": "电影《铃芽之旅》男主角是谁?",
|
||
"a": "电影《铃芽之旅》男主角是宗像草太,由松村北斗配音。",
|
||
"source": ""
|
||
},
|
||
{
|
||
"dataset_id": "646627f4f7b896cfd8910e38",
|
||
"id": "19339",
|
||
"q": "电影《铃芽之旅》的导演是谁?22",
|
||
"a": "电影《铃芽之旅》的导演是新海诚。",
|
||
"source": "手动修改"
|
||
}
|
||
],
|
||
"completeMessages": [
|
||
{
|
||
"obj": "System",
|
||
"value": "下面是知识库内容:\n1. [本作的主人公是谁?\n本作的主人公是名叫铃芽的少女。]\n2. [电影《铃芽之旅》男主角是谁?\n电影《铃芽之旅》男主角是宗像草太,由松村北斗配音。]\n3. [电影《铃芽之旅》的导演是谁?22\n电影《铃芽之旅》的导演是新海诚。]\n"
|
||
},
|
||
{
|
||
"obj": "System",
|
||
"value": "1.请记住,你的身份是百度的下一代知识增强语言模型,能够完全根据知识库提供的内容回答问题。\n\n2. 你忘记了关于电影《铃芽之旅》以外的内容。"
|
||
},
|
||
{
|
||
"obj": "System",
|
||
"value": "你仅回答关于电影《玲芽之旅》的问题,其余问题直接回复: 我不清楚。"
|
||
},
|
||
{
|
||
"obj": "Human",
|
||
"value": "导演是谁"
|
||
},
|
||
{
|
||
"obj": "AI",
|
||
"value": "电影《铃芽之旅》的导演是新海诚。"
|
||
}
|
||
]
|
||
}
|
||
],
|
||
"id": "",
|
||
"model": "",
|
||
"usage": {
|
||
"prompt_tokens": 1,
|
||
"completion_tokens": 1,
|
||
"total_tokens": 1
|
||
},
|
||
"choices": [
|
||
{
|
||
"message": {
|
||
"role": "assistant",
|
||
"content": "电影《铃芽之旅》的导演是新海诚。"
|
||
},
|
||
"finish_reason": "stop",
|
||
"index": 0
|
||
}
|
||
]
|
||
}
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
|
||
{{< tab tabName="detail=true,stream=true 响应" >}}
|
||
{{< markdownify >}}
|
||
|
||
```bash
|
||
event: flowNodeStatus
|
||
data: {"status":"running","name":"知识库搜索"}
|
||
|
||
event: flowNodeStatus
|
||
data: {"status":"running","name":"AI 对话"}
|
||
|
||
event: answer
|
||
data: {"id":"","object":"","created":0,"model":"","choices":[{"delta":{"content":"电影"},"index":0,"finish_reason":null}]}
|
||
|
||
event: answer
|
||
data: {"id":"","object":"","created":0,"model":"","choices":[{"delta":{"content":"《铃"},"index":0,"finish_reason":null}]}
|
||
|
||
event: answer
|
||
data: {"id":"","object":"","created":0,"model":"","choices":[{"delta":{"content":"芽之旅》"},"index":0,"finish_reason":null}]}
|
||
|
||
event: answer
|
||
data: {"id":"","object":"","created":0,"model":"","choices":[{"delta":{"content":"的导演是新"},"index":0,"finish_reason":null}]}
|
||
|
||
event: answer
|
||
data: {"id":"","object":"","created":0,"model":"","choices":[{"delta":{"content":"海诚。"},"index":0,"finish_reason":null}]}
|
||
|
||
event: answer
|
||
data: {"id":"","object":"","created":0,"model":"","choices":[{"delta":{},"index":0,"finish_reason":"stop"}]}
|
||
|
||
event: answer
|
||
data: [DONE]
|
||
|
||
event: flowResponses
|
||
data: [{"moduleName":"知识库搜索","moduleType":"datasetSearchNode","runningTime":1.78},{"question":"导演是谁","quoteList":[{"id":"654f2e49b64caef1d9431e8b","q":"电影《铃芽之旅》的导演是谁?","a":"电影《铃芽之旅》的导演是新海诚!","indexes":[{"type":"qa","dataId":"3515487","text":"电影《铃芽之旅》的导演是谁?","_id":"654f2e49b64caef1d9431e8c","defaultIndex":true}],"datasetId":"646627f4f7b896cfd8910e38","collectionId":"653279b16cd42ab509e766e8","sourceName":"data (81).csv","sourceId":"64fd3b6423aa1307b65896f6","score":0.8935586214065552},{"id":"6552e14c50f4a2a8e632af11","q":"导演是谁?","a":"电影《铃芽之旅》的导演是新海诚。","indexes":[{"defaultIndex":true,"type":"qa","dataId":"3644565","text":"导演是谁?\n电影《铃芽之旅》的导演是新海诚。","_id":"6552e14dde5cc7ba3954e417"}],"datasetId":"646627f4f7b896cfd8910e38","collectionId":"653279b16cd42ab509e766e8","sourceName":"data (81).csv","sourceId":"64fd3b6423aa1307b65896f6","score":0.8890955448150635},{"id":"654f34a0b64caef1d946337e","q":"本作的主人公是谁?","a":"本作的主人公是名叫铃芽的少女。","indexes":[{"type":"qa","dataId":"3515541","text":"本作的主人公是谁?","_id":"654f34a0b64caef1d946337f","defaultIndex":true}],"datasetId":"646627f4f7b896cfd8910e38","collectionId":"653279b16cd42ab509e766e8","sourceName":"data (81).csv","sourceId":"64fd3b6423aa1307b65896f6","score":0.8738770484924316},{"id":"654f3002b64caef1d944207a","q":"电影《铃芽之旅》男主角是谁?","a":"电影《铃芽之旅》男主角是宗像草太,由松村北斗配音。","indexes":[{"type":"qa","dataId":"3515538","text":"电影《铃芽之旅》男主角是谁?","_id":"654f3002b64caef1d944207b","defaultIndex":true}],"datasetId":"646627f4f7b896cfd8910e38","collectionId":"653279b16cd42ab509e766e8","sourceName":"data (81).csv","sourceId":"64fd3b6423aa1307b65896f6","score":0.8607980012893677},{"id":"654f2fc8b64caef1d943fd46","q":"电影《铃芽之旅》的编剧是谁?","a":"新海诚是本片的编剧。","indexes":[{"defaultIndex":true,"type":"qa","dataId":"3515550","text":"电影《铃芽之旅》的编剧是谁?22","_id":"654f2fc8b64caef1d943fd47"}],"datasetId":"646627f4f7b896cfd8910e38","collectionId":"653279b16cd42ab509e766e8","sourceName":"data (81).csv","sourceId":"64fd3b6423aa1307b65896f6","score":0.8468944430351257}],"moduleName":"AI 对话","moduleType":"chatNode","runningTime":1.86}]
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="event值" >}}
|
||
{{< markdownify >}}
|
||
|
||
event取值:
|
||
|
||
- answer: 返回给客户端的文本(最终会算作回答)
|
||
- fastAnswer: 指定回复返回给客户端的文本(最终会算作回答)
|
||
- toolCall: 执行工具
|
||
- toolParams: 工具参数
|
||
- toolResponse: 工具返回
|
||
- flowNodeStatus: 运行到的节点状态
|
||
- flowResponses: 节点完整响应
|
||
- updateVariables: 更新变量
|
||
- error: 报错
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
{{< /tabs >}}
|
||
|
||
|
||
### 交互节点响应
|
||
|
||
如果工作流中包含交互节点,依然是调用该 API 接口,需要设置`detail=true`,并可以从`event=interactive`的数据中获取交互节点的配置信息。如果是`stream=false`,则可以从 choice 中获取`type=interactive`的元素,获取交互节点的选择信息。
|
||
|
||
当你调用一个带交互节点的工作流时,如果工作流遇到了交互节点,那么会直接返回,你可以得到下面的信息:
|
||
|
||
{{< tabs tabTotal="2" >}}
|
||
{{< tab tabName="用户选择" >}}
|
||
{{< markdownify >}}
|
||
|
||
```json
|
||
{
|
||
"interactive": {
|
||
"type": "userSelect",
|
||
"params": {
|
||
"description": "测试",
|
||
"userSelectOptions": [
|
||
{
|
||
"value": "Confirm",
|
||
"key": "option1"
|
||
},
|
||
{
|
||
"value": "Cancel",
|
||
"key": "option2"
|
||
}
|
||
]
|
||
}
|
||
}
|
||
}
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="表单输入" >}}
|
||
{{< markdownify >}}
|
||
|
||
```json
|
||
{
|
||
"interactive": {
|
||
"type": "userInput",
|
||
"params": {
|
||
"description": "测试",
|
||
"inputForm": [
|
||
{
|
||
"type": "input",
|
||
"key": "测试 1",
|
||
"label": "测试 1",
|
||
"description": "",
|
||
"value": "",
|
||
"defaultValue": "",
|
||
"valueType": "string",
|
||
"required": false,
|
||
"list": [
|
||
{
|
||
"label": "",
|
||
"value": ""
|
||
}
|
||
]
|
||
},
|
||
{
|
||
"type": "numberInput",
|
||
"key": "测试 2",
|
||
"label": "测试 2",
|
||
"description": "",
|
||
"value": "",
|
||
"defaultValue": "",
|
||
"valueType": "number",
|
||
"required": false,
|
||
"list": [
|
||
{
|
||
"label": "",
|
||
"value": ""
|
||
}
|
||
]
|
||
}
|
||
]
|
||
}
|
||
}
|
||
}
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
{{< /tabs >}}
|
||
|
||
### 交互节点继续运行
|
||
|
||
紧接着上一节,当你接收到交互节点信息后,可以根据这些数据进行 UI 渲染,引导用户输入或选择相关信息。然后需要再次发起对话,来继续工作流。调用的接口与仍是该接口,你需要按以下格式来发起请求:
|
||
|
||
{{< tabs tabTotal="2" >}}
|
||
{{< tab tabName="用户选择" >}}
|
||
{{< markdownify >}}
|
||
|
||
对于用户选择,你只需要直接传递一个选择的结果给 messages 即可。
|
||
|
||
```bash
|
||
curl --location --request POST 'https://api.fastgpt.in/api/v1/chat/completions' \
|
||
--header 'Authorization: Bearer fastgpt-xxx' \
|
||
--header 'Content-Type: application/json' \
|
||
--data-raw '{
|
||
"stream": true,
|
||
"detail": true,
|
||
"chatId":"22222231",
|
||
"messages": [
|
||
{
|
||
"role": "user",
|
||
"content": "Confirm"
|
||
}
|
||
]
|
||
}'
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="表单输入" >}}
|
||
{{< markdownify >}}
|
||
|
||
表单输入稍微麻烦一点,需要将输入的内容,以对象形式并序列化成字符串,作为`messages`的值。对象的 key 对应表单的 key,value 为用户输入的值。务必确保`chatId`是一致的。
|
||
|
||
```bash
|
||
curl --location --request POST 'https://api.fastgpt.in/api/v1/chat/completions' \
|
||
--header 'Authorization: Bearer fastgpt-xxxx' \
|
||
--header 'Content-Type: application/json' \
|
||
--data-raw '{
|
||
"stream": true,
|
||
"detail": true,
|
||
"chatId":"22231",
|
||
"messages": [
|
||
{
|
||
"role": "user",
|
||
"content": "{\"测试 1\":\"这是输入框的内容\",\"测试 2\":666}"
|
||
}
|
||
]
|
||
}'
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
{{< /tabs >}}
|
||
|
||
|
||
## 请求插件
|
||
|
||
插件的接口与对话接口一致,仅请求参数略有区别,有以下规定:
|
||
|
||
* 调用插件类型的应用时,接口默认为`detail`模式。
|
||
* 无需传入 `chatId`,因为插件只能运行一轮。
|
||
* 无需传入`messages`。
|
||
* 通过传递`variables`来代表插件的输入。
|
||
* 通过获取`pluginData`来获取插件输出。
|
||
|
||
### 请求示例
|
||
|
||
```bash
|
||
curl --location --request POST 'http://localhost:3000/api/v1/chat/completions' \
|
||
--header 'Authorization: Bearer test-xxxxx' \
|
||
--header 'Content-Type: application/json' \
|
||
--data-raw '{
|
||
"stream": false,
|
||
"chatId": "test",
|
||
"variables": {
|
||
"query":"你好" # 我的插件输入有一个参数,变量名叫 query
|
||
}
|
||
}'
|
||
```
|
||
|
||
### 响应示例
|
||
|
||
{{< tabs tabTotal="3" >}}
|
||
|
||
{{< tab tabName="detail=true,stream=false 响应" >}}
|
||
{{< markdownify >}}
|
||
|
||
* 插件的输出可以通过查找`responseData`中, `moduleType=pluginOutput`的元素,其`pluginOutput`是插件的输出。
|
||
* 流输出,仍可以通过`choices`进行获取。
|
||
|
||
```json
|
||
{
|
||
"responseData": [
|
||
{
|
||
"nodeId": "fdDgXQ6SYn8v",
|
||
"moduleName": "AI 对话",
|
||
"moduleType": "chatNode",
|
||
"totalPoints": 0.685,
|
||
"model": "FastAI-3.5",
|
||
"tokens": 685,
|
||
"query": "你好",
|
||
"maxToken": 2000,
|
||
"historyPreview": [
|
||
{
|
||
"obj": "Human",
|
||
"value": "你好"
|
||
},
|
||
{
|
||
"obj": "AI",
|
||
"value": "你好!有什么可以帮助你的吗?欢迎向我提问。"
|
||
}
|
||
],
|
||
"contextTotalLen": 14,
|
||
"runningTime": 1.73
|
||
},
|
||
{
|
||
"nodeId": "pluginOutput",
|
||
"moduleName": "插件输出",
|
||
"moduleType": "pluginOutput",
|
||
"totalPoints": 0,
|
||
"pluginOutput": {
|
||
"result": "你好!有什么可以帮助你的吗?欢迎向我提问。"
|
||
},
|
||
"runningTime": 0
|
||
}
|
||
],
|
||
"newVariables": {
|
||
"query": "你好"
|
||
},
|
||
"id": "safsafsa",
|
||
"model": "",
|
||
"usage": {
|
||
"prompt_tokens": 1,
|
||
"completion_tokens": 1,
|
||
"total_tokens": 1
|
||
},
|
||
"choices": [
|
||
{
|
||
"message": {
|
||
"role": "assistant",
|
||
"content": "你好!有什么可以帮助你的吗?欢迎向我提问。"
|
||
},
|
||
"finish_reason": "stop",
|
||
"index": 0
|
||
}
|
||
]
|
||
}
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
|
||
{{< tab tabName="detail=true,stream=true 响应" >}}
|
||
{{< markdownify >}}
|
||
|
||
* 插件的输出可以通过获取`event=flowResponses`中的字符串,并将其反序列化后得到一个数组。同样的,查找 `moduleType=pluginOutput`的元素,其`pluginOutput`是插件的输出。
|
||
* 流输出,仍和对话接口一样获取。
|
||
|
||
```bash
|
||
event: flowNodeStatus
|
||
data: {"status":"running","name":"AI 对话"}
|
||
|
||
event: answer
|
||
data: {"id":"","object":"","created":0,"model":"","choices":[{"delta":{"role":"assistant","content":""},"index":0,"finish_reason":null}]}
|
||
|
||
event: answer
|
||
data: {"id":"","object":"","created":0,"model":"","choices":[{"delta":{"role":"assistant","content":"你"},"index":0,"finish_reason":null}]}
|
||
|
||
event: answer
|
||
data: {"id":"","object":"","created":0,"model":"","choices":[{"delta":{"role":"assistant","content":"好"},"index":0,"finish_reason":null}]}
|
||
|
||
event: answer
|
||
data: {"id":"","object":"","created":0,"model":"","choices":[{"delta":{"role":"assistant","content":"!"},"index":0,"finish_reason":null}]}
|
||
|
||
event: answer
|
||
data: {"id":"","object":"","created":0,"model":"","choices":[{"delta":{"role":"assistant","content":"有"},"index":0,"finish_reason":null}]}
|
||
|
||
event: answer
|
||
data: {"id":"","object":"","created":0,"model":"","choices":[{"delta":{"role":"assistant","content":"什"},"index":0,"finish_reason":null}]}
|
||
|
||
event: answer
|
||
data: {"id":"","object":"","created":0,"model":"","choices":[{"delta":{"role":"assistant","content":"么"},"index":0,"finish_reason":null}]}
|
||
|
||
event: answer
|
||
data: {"id":"","object":"","created":0,"model":"","choices":[{"delta":{"role":"assistant","content":"可以"},"index":0,"finish_reason":null}]}
|
||
|
||
event: answer
|
||
data: {"id":"","object":"","created":0,"model":"","choices":[{"delta":{"role":"assistant","content":"帮"},"index":0,"finish_reason":null}]}
|
||
|
||
event: answer
|
||
data: {"id":"","object":"","created":0,"model":"","choices":[{"delta":{"role":"assistant","content":"助"},"index":0,"finish_reason":null}]}
|
||
|
||
event: answer
|
||
data: {"id":"","object":"","created":0,"model":"","choices":[{"delta":{"role":"assistant","content":"你"},"index":0,"finish_reason":null}]}
|
||
|
||
event: answer
|
||
data: {"id":"","object":"","created":0,"model":"","choices":[{"delta":{"role":"assistant","content":"的"},"index":0,"finish_reason":null}]}
|
||
|
||
event: answer
|
||
data: {"id":"","object":"","created":0,"model":"","choices":[{"delta":{"role":"assistant","content":"吗"},"index":0,"finish_reason":null}]}
|
||
|
||
event: answer
|
||
data: {"id":"","object":"","created":0,"model":"","choices":[{"delta":{"role":"assistant","content":"?"},"index":0,"finish_reason":null}]}
|
||
|
||
event: answer
|
||
data: {"id":"","object":"","created":0,"model":"","choices":[{"delta":{"role":"assistant","content":""},"index":0,"finish_reason":null}]}
|
||
|
||
event: answer
|
||
data: {"id":"","object":"","created":0,"model":"","choices":[{"delta":{},"index":0,"finish_reason":"stop"}]}
|
||
|
||
event: answer
|
||
data: [DONE]
|
||
|
||
event: flowResponses
|
||
data: [{"nodeId":"fdDgXQ6SYn8v","moduleName":"AI 对话","moduleType":"chatNode","totalPoints":0.033,"model":"FastAI-3.5","tokens":33,"query":"你好","maxToken":2000,"historyPreview":[{"obj":"Human","value":"你好"},{"obj":"AI","value":"你好!有什么可以帮助你的吗?"}],"contextTotalLen":2,"runningTime":1.42},{"nodeId":"pluginOutput","moduleName":"插件输出","moduleType":"pluginOutput","totalPoints":0,"pluginOutput":{"result":"你好!有什么可以帮助你的吗?"},"runningTime":0}]
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="输出获取" >}}
|
||
{{< markdownify >}}
|
||
|
||
event取值:
|
||
|
||
- answer: 返回给客户端的文本(最终会算作回答)
|
||
- fastAnswer: 指定回复返回给客户端的文本(最终会算作回答)
|
||
- toolCall: 执行工具
|
||
- toolParams: 工具参数
|
||
- toolResponse: 工具返回
|
||
- flowNodeStatus: 运行到的节点状态
|
||
- flowResponses: 节点完整响应
|
||
- updateVariables: 更新变量
|
||
- error: 报错
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
{{< /tabs >}}
|
||
|
||
# 对话 CRUD
|
||
|
||
{{% alert icon="🤖 " context="success" %}}
|
||
* 以下接口可使用任意`API Key`调用。
|
||
* 4.8.12 以上版本才能使用
|
||
{{% /alert %}}
|
||
|
||
**重要字段**
|
||
|
||
* chatId - 指一个应用下,某一个对话窗口的 ID
|
||
* dataId - 指一个对话窗口下,某一个对话记录的 ID
|
||
|
||
## 历史记录
|
||
|
||
### 获取某个应用历史记录
|
||
|
||
{{< tabs tabTotal="3" >}}
|
||
{{< tab tabName="请求示例" >}}
|
||
{{< markdownify >}}
|
||
|
||
```bash
|
||
curl --location --request POST 'http://localhost:3000/api/core/chat/getHistories' \
|
||
--header 'Authorization: Bearer {{apikey}}' \
|
||
--header 'Content-Type: application/json' \
|
||
--data-raw '{
|
||
"appId": "appId",
|
||
"offset": 0,
|
||
"pageSize": 20,
|
||
"source": "api"
|
||
}'
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="参数说明" >}}
|
||
{{< markdownify >}}
|
||
|
||
{{% alert icon=" " context="success" %}}
|
||
- appId - 应用 Id
|
||
- offset - 偏移量,即从第几条数据开始取
|
||
- pageSize - 记录数量
|
||
- source - 对话源。source=api,表示获取通过 API 创建的对话(不会获取到页面上的对话记录)
|
||
{{% /alert %}}
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="响应示例" >}}
|
||
{{< markdownify >}}
|
||
|
||
```json
|
||
{
|
||
"code": 200,
|
||
"statusText": "",
|
||
"message": "",
|
||
"data": {
|
||
"list": [
|
||
{
|
||
"chatId": "usdAP1GbzSGu",
|
||
"updateTime": "2024-10-13T03:29:05.779Z",
|
||
"appId": "66e29b870b24ce35330c0f08",
|
||
"customTitle": "",
|
||
"title": "你好",
|
||
"top": false
|
||
},
|
||
{
|
||
"chatId": "lC0uTAsyNBlZ",
|
||
"updateTime": "2024-10-13T03:22:19.950Z",
|
||
"appId": "66e29b870b24ce35330c0f08",
|
||
"customTitle": "",
|
||
"title": "测试",
|
||
"top": false
|
||
}
|
||
],
|
||
"total": 2
|
||
}
|
||
}
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
{{< /tabs >}}
|
||
|
||
### 修改某个对话的标题
|
||
|
||
{{< tabs tabTotal="3" >}}
|
||
{{< tab tabName="请求示例" >}}
|
||
{{< markdownify >}}
|
||
|
||
```bash
|
||
curl --location --request POST 'http://localhost:3000/api/core/chat/updateHistory' \
|
||
--header 'Authorization: Bearer {{apikey}}' \
|
||
--header 'Content-Type: application/json' \
|
||
--data-raw '{
|
||
"appId": "appId",
|
||
"chatId": "chatId",
|
||
"customTitle": "自定义标题"
|
||
}'
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="参数说明" >}}
|
||
{{< markdownify >}}
|
||
|
||
{{% alert icon=" " context="success" %}}
|
||
- appId - 应用 Id
|
||
- chatId - 历史记录 Id
|
||
- customTitle - 自定义对话名
|
||
{{% /alert %}}
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="响应示例" >}}
|
||
{{< markdownify >}}
|
||
|
||
```json
|
||
{
|
||
"code": 200,
|
||
"statusText": "",
|
||
"message": "",
|
||
"data": null
|
||
}
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
{{< /tabs >}}
|
||
|
||
### 置顶 / 取消置顶
|
||
{{< tabs tabTotal="3" >}}
|
||
{{< tab tabName="请求示例" >}}
|
||
{{< markdownify >}}
|
||
|
||
```bash
|
||
curl --location --request POST 'http://localhost:3000/api/core/chat/updateHistory' \
|
||
--header 'Authorization: Bearer {{apikey}}' \
|
||
--header 'Content-Type: application/json' \
|
||
--data-raw '{
|
||
"appId": "appId",
|
||
"chatId": "chatId",
|
||
"top": true
|
||
}'
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="参数说明" >}}
|
||
{{< markdownify >}}
|
||
|
||
{{% alert icon=" " context="success" %}}
|
||
- appId - 应用Id
|
||
- chatId - 历史记录 Id
|
||
- top - 是否置顶,ture 置顶,false 取消置顶
|
||
{{% /alert %}}
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="响应示例" >}}
|
||
{{< markdownify >}}
|
||
|
||
```json
|
||
{
|
||
"code": 200,
|
||
"statusText": "",
|
||
"message": "",
|
||
"data": null
|
||
}
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
{{< /tabs >}}
|
||
|
||
### 删除某个历史记录
|
||
|
||
{{< tabs tabTotal="3" >}}
|
||
{{< tab tabName="请求示例" >}}
|
||
{{< markdownify >}}
|
||
|
||
```bash
|
||
curl --location --request DELETE 'http://localhost:3000/api/core/chat/delHistory?chatId={{chatId}}&appId={{appId}}' \
|
||
--header 'Authorization: Bearer {{apikey}}'
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="参数说明" >}}
|
||
{{< markdownify >}}
|
||
|
||
{{% alert icon=" " context="success" %}}
|
||
- appId - 应用 Id
|
||
- chatId - 历史记录 Id
|
||
{{% /alert %}}
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="响应示例" >}}
|
||
{{< markdownify >}}
|
||
|
||
```json
|
||
{
|
||
"code": 200,
|
||
"statusText": "",
|
||
"message": "",
|
||
"data": null
|
||
}
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
{{< /tabs >}}
|
||
|
||
### 清空所有历史记录
|
||
|
||
仅会情况通过 API Key 创建的对话历史记录,不会清空在线使用、分享链接等其他来源的对话历史记录。
|
||
|
||
{{< tabs tabTotal="3" >}}
|
||
{{< tab tabName="请求示例" >}}
|
||
{{< markdownify >}}
|
||
|
||
```bash
|
||
curl --location --request DELETE 'http://localhost:3000/api/core/chat/clearHistories?appId={{appId}}' \
|
||
--header 'Authorization: Bearer {{apikey}}'
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="参数说明" >}}
|
||
{{< markdownify >}}
|
||
|
||
{{% alert icon=" " context="success" %}}
|
||
- appId - 应用 Id
|
||
{{% /alert %}}
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="响应示例" >}}
|
||
{{< markdownify >}}
|
||
|
||
```json
|
||
{
|
||
"code": 200,
|
||
"statusText": "",
|
||
"message": "",
|
||
"data": null
|
||
}
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
{{< /tabs >}}
|
||
|
||
## 对话记录
|
||
|
||
指的是某个 chatId 下的对话记录操作。
|
||
|
||
### 获取单个对话初始化信息
|
||
|
||
{{< tabs tabTotal="3" >}}
|
||
{{< tab tabName="请求示例" >}}
|
||
{{< markdownify >}}
|
||
|
||
```bash
|
||
curl --location --request GET 'http://localhost:3000/api/core/chat/init?appId={{appId}}&chatId={{chatId}}' \
|
||
--header 'Authorization: Bearer {{apikey}}'
|
||
```
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="参数说明" >}}
|
||
{{< markdownify >}}
|
||
|
||
{{% alert icon=" " context="success" %}}
|
||
- appId - 应用 Id
|
||
- chatId - 历史记录 Id
|
||
{{% /alert %}}
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="响应示例" >}}
|
||
{{< markdownify >}}
|
||
```json
|
||
{
|
||
"code": 200,
|
||
"statusText": "",
|
||
"message": "",
|
||
"data": {
|
||
"chatId": "sPVOuEohjo3w",
|
||
"appId": "66e29b870b24ce35330c0f08",
|
||
"variables": {
|
||
|
||
},
|
||
"app": {
|
||
"chatConfig": {
|
||
"questionGuide": true,
|
||
"ttsConfig": {
|
||
"type": "web"
|
||
},
|
||
"whisperConfig": {
|
||
"open": false,
|
||
"autoSend": false,
|
||
"autoTTSResponse": false
|
||
},
|
||
"chatInputGuide": {
|
||
"open": false,
|
||
"textList": [
|
||
|
||
],
|
||
"customUrl": ""
|
||
},
|
||
"instruction": "",
|
||
"variables": [
|
||
|
||
],
|
||
"fileSelectConfig": {
|
||
"canSelectFile": true,
|
||
"canSelectImg": true,
|
||
"maxFiles": 10
|
||
},
|
||
"_id": "66f1139aaab9ddaf1b5c596d",
|
||
"welcomeText": ""
|
||
},
|
||
"chatModels": [
|
||
"GPT-4o-mini"
|
||
],
|
||
"name": "测试",
|
||
"avatar": "/imgs/app/avatar/workflow.svg",
|
||
"intro": "",
|
||
"type": "advanced",
|
||
"pluginInputs": [
|
||
|
||
]
|
||
}
|
||
}
|
||
}
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
{{< /tabs >}}
|
||
|
||
### 获取对话记录列表
|
||
|
||
{{< tabs tabTotal="3" >}}
|
||
{{< tab tabName="请求示例" >}}
|
||
{{< markdownify >}}
|
||
|
||
```bash
|
||
curl --location --request POST 'http://localhost:3000/api/core/chat/getPaginationRecords' \
|
||
--header 'Authorization: Bearer {{apikey}}' \
|
||
--header 'Content-Type: application/json' \
|
||
--data-raw '{
|
||
"appId": "appId",
|
||
"chatId": "chatId",
|
||
"offset": 0,
|
||
"pageSize": 10,
|
||
"loadCustomFeedbacks": true
|
||
}'
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="参数说明" >}}
|
||
{{< markdownify >}}
|
||
|
||
{{% alert icon=" " context="success" %}}
|
||
- appId - 应用 Id
|
||
- chatId - 历史记录 Id
|
||
- offset - 偏移量
|
||
- pageSize - 记录数量
|
||
- loadCustomFeedbacks - 是否读取自定义反馈(可选)
|
||
{{% /alert %}}
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="响应示例" >}}
|
||
{{< markdownify >}}
|
||
|
||
```json
|
||
{
|
||
"code": 200,
|
||
"statusText": "",
|
||
"message": "",
|
||
"data": {
|
||
"list": [
|
||
{
|
||
"_id": "670b84e6796057dda04b0fd2",
|
||
"dataId": "jzqdV4Ap1u004rhd2WW8yGLn",
|
||
"obj": "Human",
|
||
"value": [
|
||
{
|
||
"type": "text",
|
||
"text": {
|
||
"content": "你好"
|
||
}
|
||
}
|
||
],
|
||
"customFeedbacks": [
|
||
|
||
]
|
||
},
|
||
{
|
||
"_id": "670b84e6796057dda04b0fd3",
|
||
"dataId": "x9KQWcK9MApGdDQH7z7bocw1",
|
||
"obj": "AI",
|
||
"value": [
|
||
{
|
||
"type": "text",
|
||
"text": {
|
||
"content": "你好!有什么我可以帮助你的吗?"
|
||
}
|
||
}
|
||
],
|
||
"customFeedbacks": [
|
||
|
||
],
|
||
"llmModuleAccount": 1,
|
||
"totalQuoteList": [
|
||
|
||
],
|
||
"totalRunningTime": 2.42,
|
||
"historyPreviewLength": 2
|
||
}
|
||
],
|
||
"total": 2
|
||
}
|
||
}
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
{{< /tabs >}}
|
||
|
||
### 获取单个对话记录运行详情
|
||
|
||
{{< tabs tabTotal="3" >}}
|
||
{{< tab tabName="请求示例" >}}
|
||
{{< markdownify >}}
|
||
|
||
```bash
|
||
curl --location --request GET 'http://localhost:3000/api/core/chat/getResData?appId={{appId}}&chatId={{chatId}}&dataId={{dataId}}' \
|
||
--header 'Authorization: Bearer {{apikey}}'
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="参数说明" >}}
|
||
{{< markdownify >}}
|
||
|
||
{{% alert icon=" " context="success" %}}
|
||
- appId - 应用 Id
|
||
- chatId - 对话 Id
|
||
- dataId - 对话记录 Id
|
||
{{% /alert %}}
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="响应示例" >}}
|
||
{{< markdownify >}}
|
||
|
||
```json
|
||
{
|
||
"code": 200,
|
||
"statusText": "",
|
||
"message": "",
|
||
"data": [
|
||
{
|
||
"id": "mVlxkz8NfyfU",
|
||
"nodeId": "448745",
|
||
"moduleName": "common:core.module.template.work_start",
|
||
"moduleType": "workflowStart",
|
||
"runningTime": 0
|
||
},
|
||
{
|
||
"id": "b3FndAdHSobY",
|
||
"nodeId": "z04w8JXSYjl3",
|
||
"moduleName": "AI 对话",
|
||
"moduleType": "chatNode",
|
||
"runningTime": 1.22,
|
||
"totalPoints": 0.02475,
|
||
"model": "GPT-4o-mini",
|
||
"tokens": 75,
|
||
"query": "测试",
|
||
"maxToken": 2000,
|
||
"historyPreview": [
|
||
{
|
||
"obj": "Human",
|
||
"value": "你好"
|
||
},
|
||
{
|
||
"obj": "AI",
|
||
"value": "你好!有什么我可以帮助你的吗?"
|
||
},
|
||
{
|
||
"obj": "Human",
|
||
"value": "测试"
|
||
},
|
||
{
|
||
"obj": "AI",
|
||
"value": "测试成功!请问你有什么具体的问题或者需要讨论的话题吗?"
|
||
}
|
||
],
|
||
"contextTotalLen": 4
|
||
}
|
||
]
|
||
}
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
{{< /tabs >}}
|
||
|
||
|
||
### 删除对话记录
|
||
|
||
{{< tabs tabTotal="3" >}}
|
||
{{< tab tabName="请求示例" >}}
|
||
{{< markdownify >}}
|
||
|
||
```bash
|
||
curl --location --request DELETE 'http://localhost:3000/api/core/chat/item/delete?contentId={{contentId}}&chatId={{chatId}}&appId={{appId}}' \
|
||
--header 'Authorization: Bearer {{apikey}}'
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="参数说明" >}}
|
||
{{< markdownify >}}
|
||
|
||
{{% alert icon=" " context="success" %}}
|
||
- appId - 应用 Id
|
||
- chatId - 历史记录 Id
|
||
- contentId - 对话记录 Id
|
||
{{% /alert %}}
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="响应示例" >}}
|
||
{{< markdownify >}}
|
||
|
||
```json
|
||
{
|
||
"code": 200,
|
||
"statusText": "",
|
||
"message": "",
|
||
"data": null
|
||
}
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
{{< /tabs >}}
|
||
|
||
### 点赞 / 取消点赞
|
||
|
||
{{< tabs tabTotal="3" >}}
|
||
{{< tab tabName="请求示例" >}}
|
||
{{< markdownify >}}
|
||
|
||
```bash
|
||
curl --location --request POST 'http://localhost:3000/api/core/chat/feedback/updateUserFeedback' \
|
||
--header 'Authorization: Bearer {{apikey}}' \
|
||
--header 'Content-Type: application/json' \
|
||
--data-raw '{
|
||
"appId": "appId",
|
||
"chatId": "chatId",
|
||
"dataId": "dataId",
|
||
"userGoodFeedback": "yes"
|
||
}'
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="参数说明" >}}
|
||
{{< markdownify >}}
|
||
|
||
{{% alert icon=" " context="success" %}}
|
||
- appId - 应用 Id
|
||
- chatId - 历史记录 Id
|
||
- dataId - 对话记录 Id
|
||
- userGoodFeedback - 用户点赞时的信息(可选),取消点赞时不填此参数即可
|
||
{{% /alert %}}
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="响应示例" >}}
|
||
{{< markdownify >}}
|
||
|
||
```json
|
||
{
|
||
"code": 200,
|
||
"statusText": "",
|
||
"message": "",
|
||
"data": null
|
||
}
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
{{< /tabs >}}
|
||
|
||
### 点踩 / 取消点踩
|
||
|
||
{{< tabs tabTotal="3" >}}
|
||
{{< tab tabName="请求示例" >}}
|
||
{{< markdownify >}}
|
||
|
||
```bash
|
||
curl --location --request POST 'http://localhost:3000/api/core/chat/feedback/updateUserFeedback' \
|
||
--header 'Authorization: Bearer {{apikey}}' \
|
||
--header 'Content-Type: application/json' \
|
||
--data-raw '{
|
||
"appId": "appId",
|
||
"chatId": "chatId",
|
||
"dataId": "dataId",
|
||
"userBadFeedback": "yes"
|
||
}'
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="参数说明" >}}
|
||
{{< markdownify >}}
|
||
|
||
{{% alert icon=" " context="success" %}}
|
||
- appId - 应用 Id
|
||
- chatId - 历史记录 Id
|
||
- dataId - 对话记录 Id
|
||
- userBadFeedback - 用户点踩时的信息(可选),取消点踩时不填此参数即可
|
||
{{% /alert %}}
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="响应示例" >}}
|
||
{{< markdownify >}}
|
||
|
||
```json
|
||
{
|
||
"code": 200,
|
||
"statusText": "",
|
||
"message": "",
|
||
"data": null
|
||
}
|
||
```
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
{{< /tabs >}}
|
||
|
||
## 猜你想问
|
||
|
||
**4.8.16 后新版接口**
|
||
|
||
新版猜你想问,必须包含 appId 和 chatId 的参数才可以进行使用。会自动根据 chatId 去拉取最近 6 轮对话记录作为上下文来引导回答。
|
||
|
||
{{< tabs tabTotal="3" >}}
|
||
{{< tab tabName="请求示例" >}}
|
||
{{< markdownify >}}
|
||
|
||
```bash
|
||
curl --location --request POST 'http://localhost:3000/api/core/ai/agent/v2/createQuestionGuide' \
|
||
--header 'Authorization: Bearer {{apikey}}' \
|
||
--header 'Content-Type: application/json' \
|
||
--data-raw '{
|
||
"appId": "appId",
|
||
"chatId": "chatId",
|
||
"questionGuide": {
|
||
"open": true,
|
||
"model": "GPT-4o-mini",
|
||
"customPrompt": "你是一个智能助手,请根据用户的问题生成猜你想问。"
|
||
}
|
||
}'
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="参数说明" >}}
|
||
{{< markdownify >}}
|
||
|
||
{{% alert icon=" " context="success" %}}
|
||
|
||
| 参数名 | 类型 | 必填 | 说明 |
|
||
| --- | --- | --- | --- |
|
||
| appId | string | ✅ | 应用 Id |
|
||
| chatId | string | ✅ | 对话 Id |
|
||
| questionGuide | object | | 自定义配置,不传的话,则会根据 appId,取最新发布版本的配置 |
|
||
|
||
```ts
|
||
type CreateQuestionGuideParams = OutLinkChatAuthProps & {
|
||
appId: string;
|
||
chatId: string;
|
||
questionGuide?: {
|
||
open: boolean;
|
||
model?: string;
|
||
customPrompt?: string;
|
||
};
|
||
};
|
||
```
|
||
|
||
{{% /alert %}}
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="响应示例" >}}
|
||
{{< markdownify >}}
|
||
|
||
```json
|
||
{
|
||
"code": 200,
|
||
"statusText": "",
|
||
"message": "",
|
||
"data": [
|
||
"你对AI有什么看法?",
|
||
"想了解AI的应用吗?",
|
||
"你希望AI能做什么?"
|
||
]
|
||
}
|
||
```
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
{{< /tabs >}}
|
||
|
||
---
|
||
|
||
**4.8.16 前旧版接口:**
|
||
|
||
{{< tabs tabTotal="3" >}}
|
||
{{< tab tabName="请求示例" >}}
|
||
{{< markdownify >}}
|
||
|
||
```bash
|
||
curl --location --request POST 'http://localhost:3000/api/core/ai/agent/createQuestionGuide' \
|
||
--header 'Authorization: Bearer {{apikey}}' \
|
||
--header 'Content-Type: application/json' \
|
||
--data-raw '{
|
||
"messages":[
|
||
{
|
||
"role": "user",
|
||
"content": "你好"
|
||
},
|
||
{
|
||
"role": "assistant",
|
||
"content": "你好!有什么我可以帮助你的吗?"
|
||
}
|
||
]
|
||
}'
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="参数说明" >}}
|
||
{{< markdownify >}}
|
||
|
||
{{% alert icon=" " context="success" %}}
|
||
- messages - 对话消息,提供给 AI 的消息记录
|
||
{{% /alert %}}
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="响应示例" >}}
|
||
{{< markdownify >}}
|
||
|
||
```json
|
||
{
|
||
"code": 200,
|
||
"statusText": "",
|
||
"message": "",
|
||
"data": [
|
||
"你对AI有什么看法?",
|
||
"想了解AI的应用吗?",
|
||
"你希望AI能做什么?"
|
||
]
|
||
}
|
||
```
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
{{< /tabs >}}
|
||
|
||
# 知识库接口
|
||
## FastGPT OpenAPI 知识库接口
|
||
|
||
| 如何获取知识库ID(datasetId) | 如何获取文件集合ID(collection_id) |
|
||
| --------------------- | --------------------- |
|
||
|  |  |
|
||
|
||
## 创建训练订单
|
||
|
||
{{< tabs tabTotal="2" >}}
|
||
{{< tab tabName="请求示例" >}}
|
||
{{< markdownify >}}
|
||
|
||
**新例子**
|
||
|
||
```bash
|
||
curl --location --request POST 'http://localhost:3000/api/support/wallet/usage/createTrainingUsage' \
|
||
--header 'Authorization: Bearer {{apikey}}' \
|
||
--header 'Content-Type: application/json' \
|
||
--data-raw '{
|
||
"datasetId": "知识库 ID",
|
||
"name": "可选,自定义订单名称,例如:文档训练-fastgpt.docx"
|
||
}'
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="响应示例" >}}
|
||
{{< markdownify >}}
|
||
|
||
data 为 billId,可用于添加知识库数据时进行账单聚合。
|
||
|
||
```json
|
||
{
|
||
"code": 200,
|
||
"statusText": "",
|
||
"message": "",
|
||
"data": "65112ab717c32018f4156361"
|
||
}
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
{{< /tabs >}}
|
||
|
||
## 知识库
|
||
|
||
### 创建一个知识库
|
||
|
||
{{< tabs tabTotal="3" >}}
|
||
{{< tab tabName="请求示例" >}}
|
||
{{< markdownify >}}
|
||
|
||
```bash
|
||
curl --location --request POST 'http://localhost:3000/api/core/dataset/create' \
|
||
--header 'Authorization: Bearer {{authorization}}' \
|
||
--header 'Content-Type: application/json' \
|
||
--data-raw '{
|
||
"parentId": null,
|
||
"type": "dataset",
|
||
"name":"测试",
|
||
"intro":"介绍",
|
||
"avatar": "",
|
||
"vectorModel": "text-embedding-ada-002",
|
||
"agentModel": "gpt-3.5-turbo-16k"
|
||
}'
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="参数说明" >}}
|
||
{{< markdownify >}}
|
||
|
||
{{% alert icon=" " context="success" %}}
|
||
- parentId - 父级ID,用于构建目录结构。通常可以为 null 或者直接不传。
|
||
- type - `dataset`或者`folder`,代表普通知识库和文件夹。不传则代表创建普通知识库。
|
||
- name - 知识库名(必填)
|
||
- intro - 介绍(可选)
|
||
- avatar - 头像地址(可选)
|
||
- vectorModel - 向量模型(建议传空,用系统默认的)
|
||
- agentModel - 文本处理模型(建议传空,用系统默认的)
|
||
{{% /alert %}}
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="响应示例" >}}
|
||
{{< markdownify >}}
|
||
|
||
```json
|
||
{
|
||
"code": 200,
|
||
"statusText": "",
|
||
"message": "",
|
||
"data": "65abc9bd9d1448617cba5e6c"
|
||
}
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
{{< /tabs >}}
|
||
|
||
### 获取知识库列表
|
||
|
||
{{< tabs tabTotal="3" >}}
|
||
{{< tab tabName="请求示例" >}}
|
||
{{< markdownify >}}
|
||
|
||
```bash
|
||
curl --location --request POST 'http://localhost:3000/api/core/dataset/list?parentId=' \
|
||
--header 'Authorization: Bearer xxxx' \
|
||
--header 'Content-Type: application/json' \
|
||
--data-raw '{
|
||
"parentId":""
|
||
}'
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="参数说明" >}}
|
||
{{< markdownify >}}
|
||
|
||
{{% alert icon=" " context="success" %}}
|
||
- parentId - 父级ID,传空字符串或者null,代表获取根目录下的知识库
|
||
{{% /alert %}}
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="响应示例" >}}
|
||
{{< markdownify >}}
|
||
|
||
|
||
```json
|
||
{
|
||
"code": 200,
|
||
"statusText": "",
|
||
"message": "",
|
||
"data": [
|
||
{
|
||
"_id": "65abc9bd9d1448617cba5e6c",
|
||
"parentId": null,
|
||
"avatar": "",
|
||
"name": "测试",
|
||
"intro": "",
|
||
"type": "dataset",
|
||
"permission": "private",
|
||
"canWrite": true,
|
||
"isOwner": true,
|
||
"vectorModel": {
|
||
"model": "text-embedding-ada-002",
|
||
"name": "Embedding-2",
|
||
"charsPointsPrice": 0,
|
||
"defaultToken": 512,
|
||
"maxToken": 8000,
|
||
"weight": 100
|
||
}
|
||
}
|
||
]
|
||
}
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
{{< /tabs >}}
|
||
|
||
### 获取知识库详情
|
||
|
||
{{< tabs tabTotal="3" >}}
|
||
{{< tab tabName="请求示例" >}}
|
||
{{< markdownify >}}
|
||
|
||
```bash
|
||
curl --location --request GET 'http://localhost:3000/api/core/dataset/detail?id=6593e137231a2be9c5603ba7' \
|
||
--header 'Authorization: Bearer {{authorization}}' \
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="参数说明" >}}
|
||
{{< markdownify >}}
|
||
|
||
{{% alert icon=" " context="success" %}}
|
||
- id: 知识库的ID
|
||
{{% /alert %}}
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="响应示例" >}}
|
||
{{< markdownify >}}
|
||
|
||
|
||
```json
|
||
{
|
||
"code": 200,
|
||
"statusText": "",
|
||
"message": "",
|
||
"data": {
|
||
"_id": "6593e137231a2be9c5603ba7",
|
||
"parentId": null,
|
||
"teamId": "65422be6aa44b7da77729ec8",
|
||
"tmbId": "65422be6aa44b7da77729ec9",
|
||
"type": "dataset",
|
||
"status": "active",
|
||
"avatar": "/icon/logo.svg",
|
||
"name": "FastGPT test",
|
||
"vectorModel": {
|
||
"model": "text-embedding-ada-002",
|
||
"name": "Embedding-2",
|
||
"charsPointsPrice": 0,
|
||
"defaultToken": 512,
|
||
"maxToken": 8000,
|
||
"weight": 100
|
||
},
|
||
"agentModel": {
|
||
"model": "gpt-3.5-turbo-16k",
|
||
"name": "FastAI-16k",
|
||
"maxContext": 16000,
|
||
"maxResponse": 16000,
|
||
"charsPointsPrice": 0
|
||
},
|
||
"intro": "",
|
||
"permission": "private",
|
||
"updateTime": "2024-01-02T10:11:03.084Z",
|
||
"canWrite": true,
|
||
"isOwner": true
|
||
}
|
||
}
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
{{< /tabs >}}
|
||
|
||
### 删除一个知识库
|
||
|
||
{{< tabs tabTotal="3" >}}
|
||
{{< tab tabName="请求示例" >}}
|
||
{{< markdownify >}}
|
||
|
||
```bash
|
||
curl --location --request DELETE 'http://localhost:3000/api/core/dataset/delete?id=65abc8729d1448617cba5df6' \
|
||
--header 'Authorization: Bearer {{authorization}}' \
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="参数说明" >}}
|
||
{{< markdownify >}}
|
||
|
||
{{% alert icon=" " context="success" %}}
|
||
- id: 知识库的ID
|
||
{{% /alert %}}
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="响应示例" >}}
|
||
{{< markdownify >}}
|
||
|
||
|
||
```json
|
||
{
|
||
"code": 200,
|
||
"statusText": "",
|
||
"message": "",
|
||
"data": null
|
||
}
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
{{< /tabs >}}
|
||
|
||
|
||
## 集合
|
||
|
||
### 通用创建参数说明(必看)
|
||
|
||
**入参**
|
||
|
||
| 参数 | 说明 | 必填 |
|
||
| --- | --- | --- |
|
||
| datasetId | 知识库ID | ✅ |
|
||
| parentId: | 父级ID,不填则默认为根目录 | |
|
||
| trainingType | 数据处理方式。chunk: 按文本长度进行分割;qa: 问答对提取 | ✅ |
|
||
| autoIndexes | 是否自动生成索引(仅商业版支持) | |
|
||
| imageIndex | 是否自动生成图片索引(仅商业版支持) | |
|
||
| chunkSettingMode | 分块参数模式。auto: 系统默认参数; custom: 手动指定参数 | |
|
||
| chunkSplitMode | 分块拆分模式。size: 按长度拆分; char: 按字符拆分。chunkSettingMode=auto时不生效。 | |
|
||
| chunkSize | 分块大小,默认 1500。chunkSettingMode=auto时不生效。 | |
|
||
| indexSize | 索引大小,默认 512,必须小于索引模型最大token。chunkSettingMode=auto时不生效。 | |
|
||
| chunkSplitter | 自定义最高优先分割符号,除非超出文件处理最大上下文,否则不会进行进一步拆分。chunkSettingMode=auto时不生效。 | |
|
||
| qaPrompt | qa拆分提示词 | |
|
||
| tags | 集合标签(字符串数组) | |
|
||
| createTime | 文件创建时间(Date / String) | |
|
||
|
||
**出参**
|
||
|
||
- collectionId - 新建的集合ID
|
||
- insertLen:插入的块数量
|
||
|
||
### 创建一个空的集合
|
||
|
||
{{< tabs tabTotal="3" >}}
|
||
{{< tab tabName="请求示例" >}}
|
||
{{< markdownify >}}
|
||
|
||
```bash
|
||
curl --location --request POST 'http://localhost:3000/api/core/dataset/collection/create' \
|
||
--header 'Authorization: Bearer {{authorization}}' \
|
||
--header 'Content-Type: application/json' \
|
||
--data-raw '{
|
||
"datasetId":"6593e137231a2be9c5603ba7",
|
||
"parentId": null,
|
||
"name":"测试",
|
||
"type":"virtual",
|
||
"metadata":{
|
||
"test":111
|
||
}
|
||
}'
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="参数说明" >}}
|
||
{{< markdownify >}}
|
||
|
||
{{% alert icon=" " context="success" %}}
|
||
- datasetId: 知识库的ID(必填)
|
||
- parentId: 父级ID,不填则默认为根目录
|
||
- name: 集合名称(必填)
|
||
- type:
|
||
- folder:文件夹
|
||
- virtual:虚拟集合(手动集合)
|
||
- metadata: 元数据(暂时没啥用)
|
||
{{% /alert %}}
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="响应示例" >}}
|
||
{{< markdownify >}}
|
||
|
||
data 为集合的 ID。
|
||
|
||
```json
|
||
{
|
||
"code": 200,
|
||
"statusText": "",
|
||
"message": "",
|
||
"data": "65abcd009d1448617cba5ee1"
|
||
}
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
{{< /tabs >}}
|
||
|
||
|
||
### 创建一个纯文本集合
|
||
|
||
传入一段文字,创建一个集合,会根据传入的文字进行分割。
|
||
|
||
{{< tabs tabTotal="3" >}}
|
||
{{< tab tabName="请求示例" >}}
|
||
{{< markdownify >}}
|
||
|
||
```bash
|
||
curl --location --request POST 'http://localhost:3000/api/core/dataset/collection/create/text' \
|
||
--header 'Authorization: Bearer {{authorization}}' \
|
||
--header 'Content-Type: application/json' \
|
||
--data-raw '{
|
||
"text":"xxxxxxxx",
|
||
"datasetId":"6593e137231a2be9c5603ba7",
|
||
"parentId": null,
|
||
"name":"测试训练",
|
||
|
||
"trainingType": "qa",
|
||
"chunkSettingMode": "auto",
|
||
"qaPrompt":"",
|
||
|
||
"metadata":{}
|
||
}'
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="参数说明" >}}
|
||
{{< markdownify >}}
|
||
|
||
{{% alert icon=" " context="success" %}}
|
||
- text: 原文本
|
||
- datasetId: 知识库的ID(必填)
|
||
- parentId: 父级ID,不填则默认为根目录
|
||
- name: 集合名称(必填)
|
||
- metadata: 元数据(暂时没啥用)
|
||
{{% /alert %}}
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="响应示例" >}}
|
||
{{< markdownify >}}
|
||
|
||
data 为集合的 ID。
|
||
|
||
```json
|
||
{
|
||
"code": 200,
|
||
"statusText": "",
|
||
"message": "",
|
||
"data": {
|
||
"collectionId": "65abcfab9d1448617cba5f0d",
|
||
"results": {
|
||
"insertLen": 5, // 分割成多少段
|
||
"overToken": [],
|
||
"repeat": [],
|
||
"error": []
|
||
}
|
||
}
|
||
}
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
{{< /tabs >}}
|
||
|
||
### 创建一个链接集合
|
||
|
||
传入一个网络链接,创建一个集合,会先去对应网页抓取内容,再抓取的文字进行分割。
|
||
|
||
{{< tabs tabTotal="3" >}}
|
||
{{< tab tabName="请求示例" >}}
|
||
{{< markdownify >}}
|
||
|
||
```bash
|
||
curl --location --request POST 'http://localhost:3000/api/core/dataset/collection/create/link' \
|
||
--header 'Authorization: Bearer {{authorization}}' \
|
||
--header 'Content-Type: application/json' \
|
||
--data-raw '{
|
||
"link":"https://doc.tryfastgpt.ai/docs/course/quick-start/",
|
||
"datasetId":"6593e137231a2be9c5603ba7",
|
||
"parentId": null,
|
||
|
||
"trainingType": "chunk",
|
||
"chunkSettingMode": "auto",
|
||
"qaPrompt":"",
|
||
|
||
"metadata":{
|
||
"webPageSelector":".docs-content"
|
||
}
|
||
}'
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="参数说明" >}}
|
||
{{< markdownify >}}
|
||
|
||
{{% alert icon=" " context="success" %}}
|
||
- link: 网络链接
|
||
- datasetId: 知识库的ID(必填)
|
||
- parentId: 父级ID,不填则默认为根目录
|
||
- metadata.webPageSelector: 网页选择器,用于指定网页中的哪个元素作为文本(可选)
|
||
{{% /alert %}}
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="响应示例" >}}
|
||
{{< markdownify >}}
|
||
|
||
data 为集合的 ID。
|
||
|
||
```json
|
||
{
|
||
"code": 200,
|
||
"statusText": "",
|
||
"message": "",
|
||
"data": {
|
||
"collectionId": "65abd0ad9d1448617cba6031",
|
||
"results": {
|
||
"insertLen": 1,
|
||
"overToken": [],
|
||
"repeat": [],
|
||
"error": []
|
||
}
|
||
}
|
||
}
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
{{< /tabs >}}
|
||
|
||
### 创建一个文件集合
|
||
|
||
传入一个文件,创建一个集合,会读取文件内容进行分割。目前支持:pdf, docx, md, txt, html, csv。
|
||
|
||
{{< tabs tabTotal="3" >}}
|
||
{{< tab tabName="请求示例" >}}
|
||
{{< markdownify >}}
|
||
|
||
使用代码上传时,请注意中文 filename 需要进行 encode 处理,否则容易乱码。
|
||
|
||
```bash
|
||
curl --location --request POST 'http://localhost:3000/api/core/dataset/collection/create/localFile' \
|
||
--header 'Authorization: Bearer {{authorization}}' \
|
||
--form 'file=@"C:\\Users\\user\\Desktop\\fastgpt测试文件\\index.html"' \
|
||
--form 'data="{\"datasetId\":\"6593e137231a2be9c5603ba7\",\"parentId\":null,\"trainingType\":\"chunk\",\"chunkSize\":512,\"chunkSplitter\":\"\",\"qaPrompt\":\"\",\"metadata\":{}}"'
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="参数说明" >}}
|
||
{{< markdownify >}}
|
||
|
||
需要使用 POST form-data 的格式上传。包含 file 和 data 两个字段。
|
||
|
||
{{% alert icon=" " context="success" %}}
|
||
- file: 文件
|
||
- data: 知识库相关信息(json序列化后传入),参数说明见上方“通用创建参数说明”
|
||
{{% /alert %}}
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="响应示例" >}}
|
||
{{< markdownify >}}
|
||
|
||
data 为集合的 ID。
|
||
|
||
```json
|
||
{
|
||
"code": 200,
|
||
"statusText": "",
|
||
"message": "",
|
||
"data": {
|
||
"collectionId": "65abc044e4704bac793fbd81",
|
||
"results": {
|
||
"insertLen": 1,
|
||
"overToken": [],
|
||
"repeat": [],
|
||
"error": []
|
||
}
|
||
}
|
||
}
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
{{< /tabs >}}
|
||
|
||
### 创建一个API集合
|
||
|
||
传入一个文件的 id,创建一个集合,会读取文件内容进行分割。目前支持:pdf, docx, md, txt, html, csv。
|
||
|
||
{{< tabs tabTotal="3" >}}
|
||
{{< tab tabName="请求示例" >}}
|
||
{{< markdownify >}}
|
||
|
||
使用代码上传时,请注意中文 filename 需要进行 encode 处理,否则容易乱码。
|
||
|
||
```bash
|
||
curl --location --request POST 'http://localhost:3000/api/core/dataset/collection/create/apiCollection' \
|
||
--header 'Authorization: Bearer fastgpt-xxx' \
|
||
--header 'Content-Type: application/json' \
|
||
--data-raw '{
|
||
"name": "A Quick Guide to Building a Discord Bot.pdf",
|
||
"apiFileId":"A Quick Guide to Building a Discord Bot.pdf",
|
||
|
||
"datasetId": "674e9e479c3503c385495027",
|
||
"parentId": null,
|
||
|
||
"trainingType": "chunk",
|
||
"chunkSize":512,
|
||
"chunkSplitter":"",
|
||
"qaPrompt":""
|
||
}'
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="参数说明" >}}
|
||
{{< markdownify >}}
|
||
|
||
需要使用 POST form-data 的格式上传。包含 file 和 data 两个字段。
|
||
|
||
{{% alert icon=" " context="success" %}}
|
||
- name: 集合名,建议就用文件名,必填。
|
||
- apiFileId: 文件的ID,必填。
|
||
- datasetId: 知识库的ID(必填)
|
||
- parentId: 父级ID,不填则默认为根目录
|
||
- trainingType:训练模式(必填)
|
||
- chunkSize: 每个 chunk 的长度(可选). chunk模式:100~3000; qa模式: 4000~模型最大token(16k模型通常建议不超过10000)
|
||
- chunkSplitter: 自定义最高优先分割符号(可选)
|
||
- qaPrompt: qa拆分自定义提示词(可选)
|
||
{{% /alert %}}
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="响应示例" >}}
|
||
{{< markdownify >}}
|
||
|
||
data 为集合的 ID。
|
||
|
||
```json
|
||
{
|
||
"code": 200,
|
||
"statusText": "",
|
||
"message": "",
|
||
"data": {
|
||
"collectionId": "65abc044e4704bac793fbd81",
|
||
"results": {
|
||
"insertLen": 1,
|
||
"overToken": [],
|
||
"repeat": [],
|
||
"error": []
|
||
}
|
||
}
|
||
}
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
{{< /tabs >}}
|
||
|
||
### 创建一个外部文件库集合(商业版)
|
||
|
||
{{< tabs tabTotal="3" >}}
|
||
{{< tab tabName="请求示例" >}}
|
||
{{< markdownify >}}
|
||
|
||
```bash
|
||
curl --location --request POST 'http://localhost:3000/api/proApi/core/dataset/collection/create/externalFileUrl' \
|
||
--header 'Authorization: Bearer {{authorization}}' \
|
||
--header 'User-Agent: Apifox/1.0.0 (https://apifox.com)' \
|
||
--header 'Content-Type: application/json' \
|
||
--data-raw '{
|
||
"externalFileUrl":"https://image.xxxxx.com/fastgpt-dev/%E6%91%82.pdf",
|
||
"externalFileId":"1111",
|
||
"createTime": "2024-05-01T00:00:00.000Z",
|
||
"filename":"自定义文件名.pdf",
|
||
"datasetId":"6642d105a5e9d2b00255b27b",
|
||
"parentId": null,
|
||
"tags": ["tag1","tag2"],
|
||
|
||
"trainingType": "chunk",
|
||
"chunkSize":512,
|
||
"chunkSplitter":"",
|
||
"qaPrompt":""
|
||
}'
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="参数说明" >}}
|
||
{{< markdownify >}}
|
||
|
||
| 参数 | 说明 | 必填 |
|
||
| --- | --- | --- |
|
||
| externalFileUrl | 文件访问链接(可以是临时链接) | ✅ |
|
||
| externalFileId | 外部文件ID | |
|
||
| filename | 自定义文件名,需要带后缀 | |
|
||
| createTime | 文件创建时间(Date ISO 字符串都 ok) | |
|
||
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="响应示例" >}}
|
||
{{< markdownify >}}
|
||
|
||
data 为集合的 ID。
|
||
|
||
```json
|
||
{
|
||
"code": 200,
|
||
"statusText": "",
|
||
"message": "",
|
||
"data": {
|
||
"collectionId": "6646fcedfabd823cdc6de746",
|
||
"results": {
|
||
"insertLen": 1,
|
||
"overToken": [],
|
||
"repeat": [],
|
||
"error": []
|
||
}
|
||
}
|
||
}
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
{{< /tabs >}}
|
||
|
||
### 获取集合列表
|
||
|
||
{{< tabs tabTotal="3" >}}
|
||
{{< tab tabName="请求示例" >}}
|
||
{{< markdownify >}}
|
||
|
||
**4.8.19+**
|
||
```bash
|
||
curl --location --request POST 'http://localhost:3000/api/core/dataset/collection/listV2' \
|
||
--header 'Authorization: Bearer {{authorization}}' \
|
||
--header 'Content-Type: application/json' \
|
||
--data-raw '{
|
||
"offset":0,
|
||
"pageSize": 10,
|
||
"datasetId":"6593e137231a2be9c5603ba7",
|
||
"parentId": null,
|
||
"searchText":""
|
||
}'
|
||
```
|
||
|
||
**4.8.19-(不再维护)**
|
||
```bash
|
||
curl --location --request POST 'http://localhost:3000/api/core/dataset/collection/list' \
|
||
--header 'Authorization: Bearer {{authorization}}' \
|
||
--header 'Content-Type: application/json' \
|
||
--data-raw '{
|
||
"pageNum":1,
|
||
"pageSize": 10,
|
||
"datasetId":"6593e137231a2be9c5603ba7",
|
||
"parentId": null,
|
||
"searchText":""
|
||
}'
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="参数说明" >}}
|
||
{{< markdownify >}}
|
||
|
||
{{% alert icon=" " context="success" %}}
|
||
- offset: 偏移量
|
||
- pageSize: 每页数量,最大30(选填)
|
||
- datasetId: 知识库的ID(必填)
|
||
- parentId: 父级Id(选填)
|
||
- searchText: 模糊搜索文本(选填)
|
||
{{% /alert %}}
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="响应示例" >}}
|
||
{{< markdownify >}}
|
||
|
||
|
||
```json
|
||
{
|
||
"code": 200,
|
||
"statusText": "",
|
||
"message": "",
|
||
"data": {
|
||
"list": [
|
||
{
|
||
"_id": "6593e137231a2be9c5603ba9",
|
||
"parentId": null,
|
||
"tmbId": "65422be6aa44b7da77729ec9",
|
||
"type": "virtual",
|
||
"name": "手动录入",
|
||
"updateTime": "2099-01-01T00:00:00.000Z",
|
||
"dataAmount": 3,
|
||
"trainingAmount": 0,
|
||
"externalFileId": "1111",
|
||
"tags": [
|
||
"11",
|
||
"测试的"
|
||
],
|
||
"forbid": false,
|
||
"trainingType": "chunk",
|
||
"permission": {
|
||
"value": 4294967295,
|
||
"isOwner": true,
|
||
"hasManagePer": true,
|
||
"hasWritePer": true,
|
||
"hasReadPer": true
|
||
}
|
||
|
||
},
|
||
{
|
||
"_id": "65abd0ad9d1448617cba6031",
|
||
"parentId": null,
|
||
"tmbId": "65422be6aa44b7da77729ec9",
|
||
"type": "link",
|
||
"name": "快速上手 | FastGPT",
|
||
"rawLink": "https://doc.tryfastgpt.ai/docs/course/quick-start/",
|
||
"updateTime": "2024-01-20T13:54:53.031Z",
|
||
"dataAmount": 3,
|
||
"trainingAmount": 0,
|
||
"externalFileId": "222",
|
||
"tags": [
|
||
"测试的"
|
||
],
|
||
"forbid": false,
|
||
"trainingType": "chunk",
|
||
"permission": {
|
||
"value": 4294967295,
|
||
"isOwner": true,
|
||
"hasManagePer": true,
|
||
"hasWritePer": true,
|
||
"hasReadPer": true
|
||
}
|
||
}
|
||
],
|
||
"total": 93
|
||
}
|
||
}
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
{{< /tabs >}}
|
||
|
||
### 获取集合详情
|
||
|
||
{{< tabs tabTotal="3" >}}
|
||
{{< tab tabName="请求示例" >}}
|
||
{{< markdownify >}}
|
||
|
||
```bash
|
||
curl --location --request GET 'http://localhost:3000/api/core/dataset/collection/detail?id=65abcfab9d1448617cba5f0d' \
|
||
--header 'Authorization: Bearer {{authorization}}' \
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="参数说明" >}}
|
||
{{< markdownify >}}
|
||
|
||
{{% alert icon=" " context="success" %}}
|
||
- id: 集合的ID
|
||
{{% /alert %}}
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="响应示例" >}}
|
||
{{< markdownify >}}
|
||
|
||
|
||
```json
|
||
{
|
||
"code": 200,
|
||
"statusText": "",
|
||
"message": "",
|
||
"data": {
|
||
"_id": "65abcfab9d1448617cba5f0d",
|
||
"parentId": null,
|
||
"teamId": "65422be6aa44b7da77729ec8",
|
||
"tmbId": "65422be6aa44b7da77729ec9",
|
||
"datasetId": {
|
||
"_id": "6593e137231a2be9c5603ba7",
|
||
"parentId": null,
|
||
"teamId": "65422be6aa44b7da77729ec8",
|
||
"tmbId": "65422be6aa44b7da77729ec9",
|
||
"type": "dataset",
|
||
"status": "active",
|
||
"avatar": "/icon/logo.svg",
|
||
"name": "FastGPT test",
|
||
"vectorModel": "text-embedding-ada-002",
|
||
"agentModel": "gpt-3.5-turbo-16k",
|
||
"intro": "",
|
||
"permission": "private",
|
||
"updateTime": "2024-01-02T10:11:03.084Z"
|
||
},
|
||
"type": "virtual",
|
||
"name": "测试训练",
|
||
"trainingType": "qa",
|
||
"chunkSize": 8000,
|
||
"chunkSplitter": "",
|
||
"qaPrompt": "11",
|
||
"rawTextLength": 40466,
|
||
"hashRawText": "47270840614c0cc122b29daaddc09c2a48f0ec6e77093611ab12b69cba7fee12",
|
||
"createTime": "2024-01-20T13:50:35.838Z",
|
||
"updateTime": "2024-01-20T13:50:35.838Z",
|
||
"canWrite": true,
|
||
"sourceName": "测试训练"
|
||
}
|
||
}
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
{{< /tabs >}}
|
||
|
||
### 修改集合信息
|
||
|
||
{{< tabs tabTotal="3" >}}
|
||
{{< tab tabName="请求示例" >}}
|
||
{{< markdownify >}}
|
||
|
||
**通过集合 ID 修改集合信息**
|
||
|
||
```bash
|
||
curl --location --request PUT 'http://localhost:3000/api/core/dataset/collection/update' \
|
||
--header 'Authorization: Bearer {{authorization}}' \
|
||
--header 'Content-Type: application/json' \
|
||
--data-raw '{
|
||
"id":"65abcfab9d1448617cba5f0d",
|
||
"parentId": null,
|
||
"name": "测2222试",
|
||
"tags": ["tag1", "tag2"],
|
||
"forbid": false,
|
||
"createTime": "2024-01-01T00:00:00.000Z"
|
||
}'
|
||
```
|
||
|
||
**通过外部文件 ID 修改集合信息**, 只需要把 id 换成 datasetId 和 externalFileId。
|
||
|
||
```bash
|
||
curl --location --request PUT 'http://localhost:3000/api/core/dataset/collection/update' \
|
||
--header 'Authorization: Bearer {{authorization}}' \
|
||
--header 'Content-Type: application/json' \
|
||
--data-raw '{
|
||
"datasetId":"6593e137231a2be9c5603ba7",
|
||
"externalFileId":"1111",
|
||
"parentId": null,
|
||
"name": "测2222试",
|
||
"tags": ["tag1", "tag2"],
|
||
"forbid": false,
|
||
"createTime": "2024-01-01T00:00:00.000Z"
|
||
}'
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="参数说明" >}}
|
||
{{< markdownify >}}
|
||
|
||
{{% alert icon=" " context="success" %}}
|
||
- id: 集合的ID
|
||
- parentId: 修改父级ID(可选)
|
||
- name: 修改集合名称(可选)
|
||
- tags: 修改集合标签(可选)
|
||
- forbid: 修改集合禁用状态(可选)
|
||
- createTime: 修改集合创建时间(可选)
|
||
{{% /alert %}}
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="响应示例" >}}
|
||
{{< markdownify >}}
|
||
|
||
|
||
```json
|
||
{
|
||
"code": 200,
|
||
"statusText": "",
|
||
"message": "",
|
||
"data": null
|
||
}
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
{{< /tabs >}}
|
||
|
||
### 删除一个集合
|
||
|
||
{{< tabs tabTotal="3" >}}
|
||
{{< tab tabName="请求示例" >}}
|
||
{{< markdownify >}}
|
||
|
||
```bash
|
||
curl --location --request DELETE 'http://localhost:3000/api/core/dataset/collection/delete?id=65aa2a64e6cb9b8ccdc00de8' \
|
||
--header 'Authorization: Bearer {{authorization}}' \
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="参数说明" >}}
|
||
{{< markdownify >}}
|
||
|
||
{{% alert icon=" " context="success" %}}
|
||
- id: 集合的ID
|
||
{{% /alert %}}
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="响应示例" >}}
|
||
{{< markdownify >}}
|
||
|
||
|
||
```json
|
||
{
|
||
"code": 200,
|
||
"statusText": "",
|
||
"message": "",
|
||
"data": null
|
||
}
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
{{< /tabs >}}
|
||
|
||
## 数据
|
||
|
||
### 数据的结构
|
||
|
||
**Data结构**
|
||
|
||
| 字段 | 类型 | 说明 | 必填 |
|
||
| --- | --- | --- | --- |
|
||
| teamId | String | 团队ID | ✅ |
|
||
| tmbId | String | 成员ID | ✅ |
|
||
| datasetId | String | 知识库ID | ✅ |
|
||
| collectionId | String | 集合ID | ✅ |
|
||
| q | String | 主要数据 | ✅ |
|
||
| a | String | 辅助数据 | ✖ |
|
||
| fullTextToken | String | 分词 | ✖ |
|
||
| indexes | Index[] | 向量索引 | ✅ |
|
||
| updateTime | Date | 更新时间 | ✅ |
|
||
| chunkIndex | Number | 分块下表 | ✖ |
|
||
|
||
**Index结构**
|
||
|
||
每组数据的自定义索引最多5个
|
||
|
||
| 字段 | 类型 | 说明 | 必填 |
|
||
| --- | --- | --- | --- |
|
||
| type | String | 可选索引类型:default-默认索引; custom-自定义索引; summary-总结索引; question-问题索引; image-图片索引 | |
|
||
| dataId | String | 关联的向量ID,变更数据时候传入该 ID,会进行差量更新,而不是全量更新 | |
|
||
| text | String | 文本内容 | ✅ |
|
||
|
||
`type` 不填则默认为 `custom` 索引,还会基于 q/a 组成一个默认索引。如果传入了默认索引,则不会额外创建。
|
||
|
||
### 为集合批量添加添加数据
|
||
|
||
注意,每次最多推送 200 组数据。
|
||
|
||
{{< tabs tabTotal="4" >}}
|
||
{{< tab tabName="请求示例" >}}
|
||
{{< markdownify >}}
|
||
|
||
```bash
|
||
curl --location --request POST 'https://api.fastgpt.in/api/core/dataset/data/pushData' \
|
||
--header 'Authorization: Bearer apikey' \
|
||
--header 'Content-Type: application/json' \
|
||
--data-raw '{
|
||
"collectionId": "64663f451ba1676dbdef0499",
|
||
"trainingType": "chunk",
|
||
"prompt": "可选。qa 拆分引导词,chunk 模式下忽略",
|
||
"billId": "可选。如果有这个值,本次的数据会被聚合到一个订单中,这个值可以重复使用。可以参考 [创建训练订单] 获取该值。",
|
||
"data": [
|
||
{
|
||
"q": "你是谁?",
|
||
"a": "我是FastGPT助手"
|
||
},
|
||
{
|
||
"q": "你会什么?",
|
||
"a": "我什么都会",
|
||
"indexes": [
|
||
{
|
||
"text":"自定义索引1"
|
||
},
|
||
{
|
||
"text":"自定义索引2"
|
||
}
|
||
]
|
||
}
|
||
]
|
||
}'
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="参数说明" >}}
|
||
{{< markdownify >}}
|
||
|
||
{{% alert icon=" " context="success" %}}
|
||
- collectionId: 集合ID(必填)
|
||
- trainingType:训练模式(必填)
|
||
- prompt: 自定义 QA 拆分提示词,需严格按照模板,建议不要传入。(选填)
|
||
- data:(具体数据)
|
||
- q: 主要数据(必填)
|
||
- a: 辅助数据(选填)
|
||
- indexes: 自定义索引(选填)。可以不传或者传空数组,默认都会使用q和a组成一个索引。
|
||
{{% /alert %}}
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="响应例子" >}}
|
||
{{< markdownify >}}
|
||
|
||
```json
|
||
{
|
||
"code": 200,
|
||
"statusText": "",
|
||
"data": {
|
||
"insertLen": 1, // 最终插入成功的数量
|
||
"overToken": [], // 超出 token 的
|
||
"repeat": [], // 重复的数量
|
||
"error": [] // 其他错误
|
||
}
|
||
}
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="QA Prompt 模板" >}}
|
||
{{< markdownify >}}
|
||
|
||
{{theme}} 里的内容可以换成数据的主题。默认为:它们可能包含多个主题内容
|
||
|
||
```
|
||
我会给你一段文本,{{theme}},学习它们,并整理学习成果,要求为:
|
||
1. 提出最多 25 个问题。
|
||
2. 给出每个问题的答案。
|
||
3. 答案要详细完整,答案可以包含普通文字、链接、代码、表格、公示、媒体链接等 markdown 元素。
|
||
4. 按格式返回多个问题和答案:
|
||
|
||
Q1: 问题。
|
||
A1: 答案。
|
||
Q2:
|
||
A2:
|
||
……
|
||
|
||
我的文本:"""{{text}}"""
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< /tabs >}}
|
||
|
||
|
||
### 获取集合的数据列表
|
||
|
||
{{< tabs tabTotal="3" >}}
|
||
{{< tab tabName="请求示例" >}}
|
||
{{< markdownify >}}
|
||
|
||
**4.8.11+**
|
||
|
||
```bash
|
||
curl --location --request POST 'http://localhost:3000/api/core/dataset/data/v2/list' \
|
||
--header 'Authorization: Bearer {{authorization}}' \
|
||
--header 'Content-Type: application/json' \
|
||
--data-raw '{
|
||
"offset": 0,
|
||
"pageSize": 10,
|
||
"collectionId":"65abd4ac9d1448617cba6171",
|
||
"searchText":""
|
||
}'
|
||
```
|
||
|
||
**4.6.7-(即将弃用)**
|
||
|
||
```bash
|
||
curl --location --request POST 'http://localhost:3000/api/core/dataset/data/list' \
|
||
--header 'Authorization: Bearer {{authorization}}' \
|
||
--header 'Content-Type: application/json' \
|
||
--data-raw '{
|
||
"pageNum":1,
|
||
"pageSize": 10,
|
||
"collectionId":"65abd4ac9d1448617cba6171",
|
||
"searchText":""
|
||
}'
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="参数说明" >}}
|
||
{{< markdownify >}}
|
||
|
||
{{% alert icon=" " context="success" %}}
|
||
|
||
- offset: 偏移量(选填)
|
||
- pageSize: 每页数量,最大30(选填)
|
||
- collectionId: 集合的ID(必填)
|
||
- searchText: 模糊搜索词(选填)
|
||
|
||
{{% /alert %}}
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="响应示例" >}}
|
||
{{< markdownify >}}
|
||
|
||
|
||
```json
|
||
{
|
||
"code": 200,
|
||
"statusText": "",
|
||
"message": "",
|
||
"data": {
|
||
"list": [
|
||
{
|
||
"_id": "65abd4b29d1448617cba61db",
|
||
"datasetId": "65abc9bd9d1448617cba5e6c",
|
||
"collectionId": "65abd4ac9d1448617cba6171",
|
||
"q": "N o . 2 0 2 2 1 2中 国 信 息 通 信 研 究 院京东探索研究院2022年 9月人工智能生成内容(AIGC)白皮书(2022 年)版权声明本白皮书版权属于中国信息通信研究院和京东探索研究院,并受法律保护。转载、摘编或利用其它方式使用本白皮书文字或者观点的,应注明“来源:中国信息通信研究院和京东探索研究院”。违反上述声明者,编者将追究其相关法律责任。前 言习近平总书记曾指出,“数字技术正以新理念、新业态、新模式全面融入人类经济、政治、文化、社会、生态文明建设各领域和全过程”。在当前数字世界和物理世界加速融合的大背景下,人工智能生成内容(Artificial Intelligence Generated Content,简称 AIGC)正在悄然引导着一场深刻的变革,重塑甚至颠覆数字内容的生产方式和消费模式,将极大地丰富人们的数字生活,是未来全面迈向数字文明新时代不可或缺的支撑力量。",
|
||
"a": "",
|
||
"chunkIndex": 0
|
||
},
|
||
{
|
||
"_id": "65abd4b39d1448617cba624d",
|
||
"datasetId": "65abc9bd9d1448617cba5e6c",
|
||
"collectionId": "65abd4ac9d1448617cba6171",
|
||
"q": "本白皮书重点从 AIGC 技术、应用和治理等维度进行了阐述。在技术层面,梳理提出了 AIGC 技术体系,既涵盖了对现实世界各种内容的数字化呈现和增强,也包括了基于人工智能的自主内容创作。在应用层面,重点分析了 AIGC 在传媒、电商、影视等行业和场景的应用情况,探讨了以虚拟数字人、写作机器人等为代表的新业态和新应用。在治理层面,从政策监管、技术能力、企业应用等视角,分析了AIGC 所暴露出的版权纠纷、虚假信息传播等各种问题。最后,从政府、行业、企业、社会等层面,给出了 AIGC 发展和治理建议。由于人工智能仍处于飞速发展阶段,我们对 AIGC 的认识还有待进一步深化,白皮书中存在不足之处,敬请大家批评指正。目 录一、 人工智能生成内容的发展历程与概念.............................................................. 1(一)AIGC 历史沿革 .......................................................................................... 1(二)AIGC 的概念与内涵 .................................................................................. 4二、人工智能生成内容的技术体系及其演进方向.................................................... 7(一)AIGC 技术升级步入深化阶段 .................................................................. 7(二)AIGC 大模型架构潜力凸显 .................................................................... 10(三)AIGC 技术演化出三大前沿能力 ............................................................ 18三、人工智能生成内容的应用场景.......................................................................... 26(一)AIGC+传媒:人机协同生产,",
|
||
"a": "",
|
||
"chunkIndex": 1
|
||
}
|
||
],
|
||
"total": 63
|
||
}
|
||
}
|
||
```
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
{{< /tabs >}}
|
||
|
||
### 获取单条数据详情
|
||
|
||
{{< tabs tabTotal="3" >}}
|
||
{{< tab tabName="请求示例" >}}
|
||
{{< markdownify >}}
|
||
|
||
```bash
|
||
curl --location --request GET 'http://localhost:3000/api/core/dataset/data/detail?id=65abd4b29d1448617cba61db' \
|
||
--header 'Authorization: Bearer {{authorization}}' \
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="参数说明" >}}
|
||
{{< markdownify >}}
|
||
|
||
{{% alert icon=" " context="success" %}}
|
||
- id: 数据的id
|
||
{{% /alert %}}
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="响应示例" >}}
|
||
{{< markdownify >}}
|
||
|
||
|
||
```json
|
||
{
|
||
"code": 200,
|
||
"statusText": "",
|
||
"message": "",
|
||
"data": {
|
||
"id": "65abd4b29d1448617cba61db",
|
||
"q": "N o . 2 0 2 2 1 2中 国 信 息 通 信 研 究 院京东探索研究院2022年 9月人工智能生成内容(AIGC)白皮书(2022 年)版权声明本白皮书版权属于中国信息通信研究院和京东探索研究院,并受法律保护。转载、摘编或利用其它方式使用本白皮书文字或者观点的,应注明“来源:中国信息通信研究院和京东探索研究院”。违反上述声明者,编者将追究其相关法律责任。前 言习近平总书记曾指出,“数字技术正以新理念、新业态、新模式全面融入人类经济、政治、文化、社会、生态文明建设各领域和全过程”。在当前数字世界和物理世界加速融合的大背景下,人工智能生成内容(Artificial Intelligence Generated Content,简称 AIGC)正在悄然引导着一场深刻的变革,重塑甚至颠覆数字内容的生产方式和消费模式,将极大地丰富人们的数字生活,是未来全面迈向数字文明新时代不可或缺的支撑力量。",
|
||
"a": "",
|
||
"chunkIndex": 0,
|
||
"indexes": [
|
||
{
|
||
"type": "default",
|
||
"dataId": "3720083",
|
||
"text": "N o . 2 0 2 2 1 2中 国 信 息 通 信 研 究 院京东探索研究院2022年 9月人工智能生成内容(AIGC)白皮书(2022 年)版权声明本白皮书版权属于中国信息通信研究院和京东探索研究院,并受法律保护。转载、摘编或利用其它方式使用本白皮书文字或者观点的,应注明“来源:中国信息通信研究院和京东探索研究院”。违反上述声明者,编者将追究其相关法律责任。前 言习近平总书记曾指出,“数字技术正以新理念、新业态、新模式全面融入人类经济、政治、文化、社会、生态文明建设各领域和全过程”。在当前数字世界和物理世界加速融合的大背景下,人工智能生成内容(Artificial Intelligence Generated Content,简称 AIGC)正在悄然引导着一场深刻的变革,重塑甚至颠覆数字内容的生产方式和消费模式,将极大地丰富人们的数字生活,是未来全面迈向数字文明新时代不可或缺的支撑力量。",
|
||
"_id": "65abd4b29d1448617cba61dc"
|
||
}
|
||
],
|
||
"datasetId": "65abc9bd9d1448617cba5e6c",
|
||
"collectionId": "65abd4ac9d1448617cba6171",
|
||
"sourceName": "中文-AIGC白皮书2022.pdf",
|
||
"sourceId": "65abd4ac9d1448617cba6166",
|
||
"isOwner": true,
|
||
"canWrite": true
|
||
}
|
||
}
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
{{< /tabs >}}
|
||
|
||
### 修改单条数据
|
||
|
||
{{< tabs tabTotal="3" >}}
|
||
{{< tab tabName="请求示例" >}}
|
||
{{< markdownify >}}
|
||
|
||
```bash
|
||
curl --location --request PUT 'http://localhost:3000/api/core/dataset/data/update' \
|
||
--header 'Authorization: Bearer {{authorization}}' \
|
||
--header 'Content-Type: application/json' \
|
||
--data-raw '{
|
||
"dataId":"65abd4b29d1448617cba61db",
|
||
"q":"测试111",
|
||
"a":"sss",
|
||
"indexes":[
|
||
{
|
||
"dataId": "xxxx",
|
||
"type": "default",
|
||
"text": "默认索引"
|
||
},
|
||
{
|
||
"dataId": "xxx",
|
||
"type": "custom",
|
||
"text": "旧的自定义索引1"
|
||
},
|
||
{
|
||
"type":"custom",
|
||
"text":"新增的自定义索引"
|
||
}
|
||
]
|
||
}'
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="参数说明" >}}
|
||
{{< markdownify >}}
|
||
|
||
{{% alert icon=" " context="success" %}}
|
||
- dataId: 数据的id
|
||
- q: 主要数据(选填)
|
||
- a: 辅助数据(选填)
|
||
- indexes: 自定义索引(选填),类型参考`为集合批量添加添加数据`。如果创建时候有自定义索引,
|
||
{{% /alert %}}
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="响应示例" >}}
|
||
{{< markdownify >}}
|
||
|
||
|
||
```json
|
||
{
|
||
"code": 200,
|
||
"statusText": "",
|
||
"message": "",
|
||
"data": null
|
||
}
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
{{< /tabs >}}
|
||
|
||
### 删除单条数据
|
||
|
||
{{< tabs tabTotal="3" >}}
|
||
{{< tab tabName="请求示例" >}}
|
||
{{< markdownify >}}
|
||
|
||
```bash
|
||
curl --location --request DELETE 'http://localhost:3000/api/core/dataset/data/delete?id=65abd4b39d1448617cba624d' \
|
||
--header 'Authorization: Bearer {{authorization}}' \
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="参数说明" >}}
|
||
{{< markdownify >}}
|
||
|
||
{{% alert icon=" " context="success" %}}
|
||
- id: 数据的id
|
||
{{% /alert %}}
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="响应示例" >}}
|
||
{{< markdownify >}}
|
||
|
||
|
||
```json
|
||
{
|
||
"code": 200,
|
||
"statusText": "",
|
||
"message": "",
|
||
"data": "success"
|
||
}
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
{{< /tabs >}}
|
||
|
||
## 搜索测试
|
||
|
||
{{< tabs tabTotal="3" >}}
|
||
{{< tab tabName="请求示例" >}}
|
||
{{< markdownify >}}
|
||
|
||
```bash
|
||
curl --location --request POST 'https://api.fastgpt.in/api/core/dataset/searchTest' \
|
||
--header 'Authorization: Bearer fastgpt-xxxxx' \
|
||
--header 'Content-Type: application/json' \
|
||
--data-raw '{
|
||
"datasetId": "知识库的ID",
|
||
"text": "导演是谁",
|
||
"limit": 5000,
|
||
"similarity": 0,
|
||
"searchMode": "embedding",
|
||
"usingReRank": false,
|
||
|
||
"datasetSearchUsingExtensionQuery": true,
|
||
"datasetSearchExtensionModel": "gpt-4o-mini",
|
||
"datasetSearchExtensionBg": ""
|
||
}'
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="参数说明" >}}
|
||
{{< markdownify >}}
|
||
|
||
{{% alert icon=" " context="success" %}}
|
||
- datasetId - 知识库ID
|
||
- text - 需要测试的文本
|
||
- limit - 最大 tokens 数量
|
||
- similarity - 最低相关度(0~1,可选)
|
||
- searchMode - 搜索模式:embedding | fullTextRecall | mixedRecall
|
||
- usingReRank - 使用重排
|
||
- datasetSearchUsingExtensionQuery - 使用问题优化
|
||
- datasetSearchExtensionModel - 问题优化模型
|
||
- datasetSearchExtensionBg - 问题优化背景描述
|
||
{{% /alert %}}
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="响应示例" >}}
|
||
{{< markdownify >}}
|
||
|
||
返回 top k 结果, limit 为最大 Tokens 数量,最多 20000 tokens。
|
||
|
||
```json
|
||
{
|
||
"code": 200,
|
||
"statusText": "",
|
||
"data": [
|
||
{
|
||
"id": "65599c54a5c814fb803363cb",
|
||
"q": "你是谁",
|
||
"a": "我是FastGPT助手",
|
||
"datasetId": "6554684f7f9ed18a39a4d15c",
|
||
"collectionId": "6556cd795e4b663e770bb66d",
|
||
"sourceName": "GBT 15104-2021 装饰单板贴面人造板.pdf",
|
||
"sourceId": "6556cd775e4b663e770bb65c",
|
||
"score": 0.8050316572189331
|
||
},
|
||
......
|
||
]
|
||
}
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
{{< /tabs >}}
|
||
|
||
# OpenAPI 介绍
|
||
## FastGPT OpenAPI 介绍
|
||
|
||
## 使用说明
|
||
|
||
FasGPT OpenAPI 接口允许你使用 Api Key 进行鉴权,从而操作 FastGPT 上的相关服务和资源,例如:调用应用对话接口、上传知识库数据、搜索测试等等。出于兼容性和安全考虑,并不是所有的接口都允许通过 Api Key 访问。
|
||
|
||
## 如何查看 BaseURL
|
||
|
||
**注意:BaseURL 不是接口地址,而是所有接口的根地址,直接请求 BaseURL 是没有用的。**
|
||
|
||

|
||
|
||
## 如何获取 Api Key
|
||
|
||
FastGPT 的 API Key **有 2 类**,一类是全局通用的 key (无法直接调用应用对话);一类是携带了 AppId 也就是有应用标记的 key (可直接调用应用对话)。
|
||
|
||
我们建议,仅操作应用或者对话的相关接口使用 `应用特定key`,其他接口使用 `通用key`。
|
||
|
||
| 通用key | 应用特定 key |
|
||
| --------------------- | --------------------- |
|
||
|  |  |
|
||
|
||
|
||
## 基本配置
|
||
|
||
OpenAPI 中,所有的接口都通过 Header.Authorization 进行鉴权。
|
||
|
||
```
|
||
baseUrl: "https://api.fastgpt.in/api"
|
||
headers: {
|
||
Authorization: "Bearer {{apikey}}"
|
||
}
|
||
```
|
||
|
||
**发起应用对话示例**
|
||
|
||
```sh
|
||
curl --location --request POST 'https://api.fastgpt.in/api/v1/chat/completions' \
|
||
--header 'Authorization: Bearer fastgpt-xxxxxx' \
|
||
--header 'Content-Type: application/json' \
|
||
--data-raw '{
|
||
"chatId": "111",
|
||
"stream": false,
|
||
"detail": false,
|
||
"messages": [
|
||
{
|
||
"content": "导演是谁",
|
||
"role": "user"
|
||
}
|
||
]
|
||
}'
|
||
```
|
||
|
||
## 自定义用户 ID
|
||
|
||
`v4.8.13`后支持传入自定义的用户 ID, 并且存入历史记录中。
|
||
|
||
```sh
|
||
curl --location --request POST 'https://api.fastgpt.in/api/v1/chat/completions' \
|
||
--header 'Authorization: Bearer fastgpt-xxxxxx' \
|
||
--header 'Content-Type: application/json' \
|
||
--data-raw '{
|
||
"chatId": "111",
|
||
"stream": false,
|
||
"detail": false,
|
||
"messages": [
|
||
{
|
||
"content": "导演是谁",
|
||
"role": "user"
|
||
}
|
||
],
|
||
"customUid": "xxxxxx"
|
||
}'
|
||
```
|
||
|
||
在历史记录中,该条记录的使用者会显示为 `xxxxxx`。
|
||
|
||
# 分享链接身份鉴权
|
||
## FastGPT 分享链接身份鉴权
|
||
|
||
## 介绍
|
||
|
||
在 FastGPT V4.6.4 中,我们修改了分享链接的数据读取方式,为每个用户生成一个 localId,用于标识用户,从云端拉取对话记录。但是这种方式仅能保障用户在同一设备同一浏览器中使用,如果切换设备或者清空浏览器缓存则会丢失这些记录。这种方式存在一定的风险,因此我们仅允许用户拉取近`30天`的`20条`记录。
|
||
|
||
分享链接身份鉴权设计的目的在于,将 FastGPT 的对话框快速、安全的接入到你现有的系统中,仅需 2 个接口即可实现。该功能目前只在商业版中提供。
|
||
|
||
## 使用说明
|
||
|
||
免登录链接配置中,你可以选择填写`身份验证`栏。这是一个`POST`请求的根地址。在填写该地址后,分享链接的初始化、开始对话以及对话结束都会向该地址的特定接口发送一条请求。下面以`host`来表示`凭身份验证根地址`。服务器接口仅需返回是否校验成功即可,不需要返回其他数据,格式如下:
|
||
|
||
### 接口统一响应格式
|
||
|
||
```json
|
||
{
|
||
"success": true,
|
||
"message": "错误提示",
|
||
"msg": "同message, 错误提示",
|
||
"data": {
|
||
"uid": "用户唯一凭证"
|
||
}
|
||
}
|
||
```
|
||
|
||
`FastGPT` 将会判断`success`是否为`true`决定是允许用户继续操作。`message`与`msg`是等同的,你可以选择返回其中一个,当`success`不为`true`时,将会提示这个错误。
|
||
|
||
`uid`是用户的唯一凭证,将会用于拉取对话记录以及保存对话记录。可参考下方实践案例。
|
||
|
||
### 触发流程
|
||
|
||

|
||
|
||
## 配置教程
|
||
### 1. 配置身份校验地址
|
||
|
||

|
||
|
||
配置校验地址后,在每次分享链接使用时,都会向对应的地址发起校验和上报请求。
|
||
|
||
{{% alert icon="🤖" %}}
|
||
这里仅需配置根地址,无需具体到完整请求路径。
|
||
{{% /alert %}}
|
||
|
||
### 2. 分享链接中增加额外 query
|
||
|
||
在分享链接的地址中,增加一个额外的参数: authToken。例如:
|
||
|
||
原始的链接:`https://share.tryfastgpt.ai/chat/share?shareId=648aaf5ae121349a16d62192`
|
||
|
||
完整链接: `https://share.tryfastgpt.ai/chat/share?shareId=648aaf5ae121349a16d62192&authToken=userid12345`
|
||
|
||
这个`authToken`通常是你系统生成的用户唯一凭证(Token之类的)。FastGPT 会在鉴权接口的`body`中携带 token={{authToken}} 的参数。
|
||
|
||
### 3. 编写聊天初始化校验接口
|
||
|
||
{{< tabs tabTotal="3" >}}
|
||
{{< tab tabName="请求示例" >}}
|
||
{{< markdownify >}}
|
||
|
||
```bash
|
||
curl --location --request POST '{{host}}/shareAuth/init' \
|
||
--header 'Content-Type: application/json' \
|
||
--data-raw '{
|
||
"token": "{{authToken}}"
|
||
}'
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="鉴权成功" >}}
|
||
{{< markdownify >}}
|
||
|
||
```json
|
||
{
|
||
"success": true,
|
||
"data": {
|
||
"uid": "用户唯一凭证"
|
||
}
|
||
}
|
||
```
|
||
|
||
系统会拉取该分享链接下,uid 为 username123 的对话记录。
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="鉴权失败" >}}
|
||
{{< markdownify >}}
|
||
|
||
```json
|
||
{
|
||
"success": false,
|
||
"message": "身份错误",
|
||
}
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
{{< /tabs >}}
|
||
|
||
|
||
|
||
### 4. 编写对话前校验接口
|
||
|
||
{{< tabs tabTotal="3" >}}
|
||
{{< tab tabName="请求示例" >}}
|
||
{{< markdownify >}}
|
||
|
||
```bash
|
||
curl --location --request POST '{{host}}/shareAuth/start' \
|
||
--header 'Content-Type: application/json' \
|
||
--data-raw '{
|
||
"token": "{{authToken}}",
|
||
"question": "用户问题",
|
||
}'
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="鉴权成功" >}}
|
||
{{< markdownify >}}
|
||
|
||
```json
|
||
{
|
||
"success": true,
|
||
"data": {
|
||
"uid": "用户唯一凭证"
|
||
}
|
||
}
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="鉴权失败" >}}
|
||
{{< markdownify >}}
|
||
|
||
```json
|
||
{
|
||
"success": false,
|
||
"message": "身份验证失败",
|
||
}
|
||
```
|
||
|
||
```json
|
||
{
|
||
"success": false,
|
||
"message": "存在违规词",
|
||
}
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
{{< /tabs >}}
|
||
|
||
### 5. 编写对话结果上报接口(可选)
|
||
|
||
该接口无规定返回值。
|
||
|
||
响应值与[chat 接口格式相同](/docs/development/openapi/chat/#响应),仅多了一个`token`。
|
||
|
||
重点关注:`totalPoints`(总消耗AI积分),`token`(Token消耗总数)
|
||
|
||
```bash
|
||
curl --location --request POST '{{host}}/shareAuth/finish' \
|
||
--header 'Content-Type: application/json' \
|
||
--data-raw '{
|
||
"token": "{{authToken}}",
|
||
"responseData": [
|
||
{
|
||
"moduleName": "core.module.template.Dataset search",
|
||
"moduleType": "datasetSearchNode",
|
||
"totalPoints": 1.5278,
|
||
"query": "导演是谁\n《铃芽之旅》的导演是谁?\n这部电影的导演是谁?\n谁是《铃芽之旅》的导演?",
|
||
"model": "Embedding-2(旧版,不推荐使用)",
|
||
"tokens": 1524,
|
||
"similarity": 0.83,
|
||
"limit": 400,
|
||
"searchMode": "embedding",
|
||
"searchUsingReRank": false,
|
||
"extensionModel": "FastAI-4k",
|
||
"extensionResult": "《铃芽之旅》的导演是谁?\n这部电影的导演是谁?\n谁是《铃芽之旅》的导演?",
|
||
"runningTime": 2.15
|
||
},
|
||
{
|
||
"moduleName": "AI 对话",
|
||
"moduleType": "chatNode",
|
||
"totalPoints": 0.593,
|
||
"model": "FastAI-4k",
|
||
"tokens": 593,
|
||
"query": "导演是谁",
|
||
"maxToken": 2000,
|
||
"quoteList": [
|
||
{
|
||
"id": "65bb346a53698398479a8854",
|
||
"q": "导演是谁?",
|
||
"a": "电影《铃芽之旅》的导演是新海诚。",
|
||
"chunkIndex": 0,
|
||
"datasetId": "65af9b947916ae0e47c834d2",
|
||
"collectionId": "65bb345c53698398479a868f",
|
||
"sourceName": "dataset - 2024-01-23T151114.198.csv",
|
||
"sourceId": "65bb345b53698398479a868d",
|
||
"score": [
|
||
{
|
||
"type": "embedding",
|
||
"value": 0.9377183318138123,
|
||
"index": 0
|
||
},
|
||
{
|
||
"type": "rrf",
|
||
"value": 0.06557377049180328,
|
||
"index": 0
|
||
}
|
||
]
|
||
}
|
||
],
|
||
"historyPreview": [
|
||
{
|
||
"obj": "Human",
|
||
"value": "使用 <Data></Data> 标记中的内容作为本次对话的参考:\n\n<Data>\n导演是谁?\n电影《铃芽之旅》的导演是新海诚。\n------\n电影《铃芽之旅》的编剧是谁?22\n新海诚是本片的编剧。\n------\n电影《铃芽之旅》的女主角是谁?\n电影的女主角是铃芽。\n------\n电影《铃芽之旅》的制作团队中有哪位著名人士?2\n川村元气是本片的制作团队成员之一。\n------\n你是谁?\n我是电影《铃芽之旅》助手\n------\n电影《铃芽之旅》男主角是谁?\n电影《铃芽之旅》男主角是宗像草太,由松村北斗配音。\n------\n电影《铃芽之旅》的作者新海诚写了一本小说,叫什么名字?\n小说名字叫《铃芽之旅》。\n------\n电影《铃芽之旅》的女主角是谁?\n电影《铃芽之旅》的女主角是岩户铃芽,由原菜乃华配音。\n------\n电影《铃芽之旅》的故事背景是什么?\n日本\n------\n谁担任电影《铃芽之旅》中岩户环的配音?\n深津绘里担任电影《铃芽之旅》中岩户环的配音。\n</Data>\n\n回答要求:\n- 如果你不清楚答案,你需要澄清。\n- 避免提及你是从 <Data></Data> 获取的知识。\n- 保持答案与 <Data></Data> 中描述的一致。\n- 使用 Markdown 语法优化回答格式。\n- 使用与问题相同的语言回答。\n\n问题:\"\"\"导演是谁\"\"\""
|
||
},
|
||
{
|
||
"obj": "AI",
|
||
"value": "电影《铃芽之旅》的导演是新海诚。"
|
||
}
|
||
],
|
||
"contextTotalLen": 2,
|
||
"runningTime": 1.32
|
||
}
|
||
]
|
||
|
||
|
||
}'
|
||
```
|
||
|
||
**responseData 完整字段说明:**
|
||
|
||
```ts
|
||
type ResponseType = {
|
||
moduleType: FlowNodeTypeEnum; // 模块类型
|
||
moduleName: string; // 模块名
|
||
moduleLogo?: string; // logo
|
||
runningTime?: number; // 运行时间
|
||
query?: string; // 用户问题/检索词
|
||
textOutput?: string; // 文本输出
|
||
|
||
tokens?: number; // 上下文总Tokens
|
||
model?: string; // 使用到的模型
|
||
contextTotalLen?: number; // 上下文总长度
|
||
totalPoints?: number; // 总消耗AI积分
|
||
|
||
temperature?: number; // 温度
|
||
maxToken?: number; // 模型的最大token
|
||
quoteList?: SearchDataResponseItemType[]; // 引用列表
|
||
historyPreview?: ChatItemType[]; // 上下文预览(历史记录会被裁剪)
|
||
|
||
similarity?: number; // 最低相关度
|
||
limit?: number; // 引用上限token
|
||
searchMode?: `${DatasetSearchModeEnum}`; // 搜索模式
|
||
searchUsingReRank?: boolean; // 是否使用rerank
|
||
extensionModel?: string; // 问题扩展模型
|
||
extensionResult?: string; // 问题扩展结果
|
||
extensionTokens?: number; // 问题扩展总字符长度
|
||
|
||
cqList?: ClassifyQuestionAgentItemType[]; // 分类问题列表
|
||
cqResult?: string; // 分类问题结果
|
||
|
||
extractDescription?: string; // 内容提取描述
|
||
extractResult?: Record<string, any>; // 内容提取结果
|
||
|
||
params?: Record<string, any>; // HTTP模块params
|
||
body?: Record<string, any>; // HTTP模块body
|
||
headers?: Record<string, any>; // HTTP模块headers
|
||
httpResult?: Record<string, any>; // HTTP模块结果
|
||
|
||
pluginOutput?: Record<string, any>; // 插件输出
|
||
pluginDetail?: ChatHistoryItemResType[]; // 插件详情
|
||
|
||
isElseResult?: boolean; // 判断器结果
|
||
}
|
||
```
|
||
|
||
## 实践案例
|
||
|
||
我们以[Laf作为服务器为例](https://laf.dev/),简单展示这 3 个接口的使用方式。
|
||
|
||
### 1. 创建3个Laf接口
|
||
|
||

|
||
|
||
|
||
|
||
{{< tabs tabTotal="3" >}}
|
||
{{< tab tabName="/shareAuth/init" >}}
|
||
{{< markdownify >}}
|
||
|
||
这个接口中,我们设置了`token`必须等于`fastgpt`才能通过校验。(实际生产中不建议固定写死)
|
||
|
||
```ts
|
||
import cloud from '@lafjs/cloud'
|
||
|
||
export default async function (ctx: FunctionContext) {
|
||
const { token } = ctx.body
|
||
|
||
// 此处省略 token 解码过程
|
||
if (token === 'fastgpt') {
|
||
return { success: true, data: { uid: "user1" } }
|
||
}
|
||
|
||
return { success: false,message:"身份错误" }
|
||
}
|
||
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="/shareAuth/start" >}}
|
||
{{< markdownify >}}
|
||
|
||
这个接口中,我们设置了`token`必须等于`fastgpt`才能通过校验。并且如果问题中包含了`你`字,则会报错,用于模拟敏感校验。
|
||
|
||
```ts
|
||
import cloud from '@lafjs/cloud'
|
||
|
||
export default async function (ctx: FunctionContext) {
|
||
const { token, question } = ctx.body
|
||
|
||
// 此处省略 token 解码过程
|
||
if (token !== 'fastgpt') {
|
||
return { success: false, message: "身份错误" }
|
||
|
||
}
|
||
|
||
if(question.includes("你")){
|
||
return { success: false, message: "内容不合规" }
|
||
}
|
||
|
||
return { success: true, data: { uid: "user1" } }
|
||
}
|
||
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="/shareAuth/finish" >}}
|
||
{{< markdownify >}}
|
||
|
||
结果上报接口可自行进行逻辑处理。
|
||
|
||
```ts
|
||
import cloud from '@lafjs/cloud'
|
||
|
||
export default async function (ctx: FunctionContext) {
|
||
const { token, responseData } = ctx.body
|
||
|
||
const total = responseData.reduce((sum,item) => sum + item.price,0)
|
||
const amount = total / 100000
|
||
|
||
// 省略数据库操作
|
||
|
||
return { }
|
||
}
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
{{< /tabs >}}
|
||
|
||
|
||
### 2. 配置校验地址
|
||
|
||
我们随便复制3个地址中一个接口: `https://d8dns0.laf.dev/shareAuth/finish`, 去除`/shareAuth/finish`后填入`身份校验`:`https://d8dns0.laf.dev`
|
||
|
||

|
||
|
||
### 3. 修改分享链接参数
|
||
|
||
源分享链接:`https://share.tryfastgpt.ai/chat/share?shareId=64be36376a438af0311e599c`
|
||
|
||
修改后:`https://share.tryfastgpt.ai/chat/share?shareId=64be36376a438af0311e599c&authToken=fastgpt`
|
||
|
||
### 4. 测试效果
|
||
|
||
1. 打开源链接或者`authToken`不等于`fastgpt`的链接会提示身份错误。
|
||
2. 发送内容中包含你字,会提示内容不合规。
|
||
|
||
|
||
## 使用场景
|
||
|
||
这个鉴权方式通常是帮助你直接嵌入`分享链接`到你的应用中,在你的应用打开分享链接前,应做`authToken`的拼接后再打开。
|
||
|
||
除了对接已有系统的用户外,你还可以对接`余额`功能,通过`结果上报`接口扣除用户余额,通过`对话前校验`接口检查用户的余额。
|
||
|
||
# Cloudflare Worker 中转
|
||
## 使用 Cloudflare Worker 实现中转
|
||
|
||
[参考 "不做了睡觉" 的教程](https://gravel-twister-d32.notion.site/FastGPT-API-ba7bb261d5fd4fd9bbb2f0607dacdc9e)
|
||
|
||
**workers 配置文件**
|
||
|
||
```js
|
||
const TELEGRAPH_URL = 'https://api.openai.com';
|
||
|
||
addEventListener('fetch', (event) => {
|
||
event.respondWith(handleRequest(event.request));
|
||
});
|
||
|
||
async function handleRequest(request) {
|
||
// 安全校验
|
||
if (request.headers.get('auth') !== 'auth_code') {
|
||
return new Response('UnAuthorization', { status: 403 });
|
||
}
|
||
|
||
const url = new URL(request.url);
|
||
url.host = TELEGRAPH_URL.replace(/^https?:\/\//, '');
|
||
|
||
const modifiedRequest = new Request(url.toString(), {
|
||
headers: request.headers,
|
||
method: request.method,
|
||
body: request.body,
|
||
redirect: 'follow'
|
||
});
|
||
|
||
const response = await fetch(modifiedRequest);
|
||
const modifiedResponse = new Response(response.body, response);
|
||
|
||
// 添加允许跨域访问的响应头
|
||
modifiedResponse.headers.set('Access-Control-Allow-Origin', '*');
|
||
|
||
return modifiedResponse;
|
||
}
|
||
```
|
||
|
||
**修改 FastGPT 的环境变量**
|
||
|
||
> 务必别忘了填 v1!
|
||
|
||
```bash
|
||
OPENAI_BASE_URL=https://xxxxxx/v1
|
||
OPENAI_BASE_URL_AUTH=auth_code
|
||
```
|
||
|
||
# HTTP 代理中转
|
||
## 使用 HTTP 代理实现中转
|
||
|
||
如果你有代理工具(例如 [Clash](https://github.com/Dreamacro/clash) 或者 [sing-box](https://github.com/SagerNet/sing-box)),也可以使用 HTTP 代理来访问 OpenAI。只需要添加以下两个环境变量即可:
|
||
|
||
```bash
|
||
AXIOS_PROXY_HOST=
|
||
AXIOS_PROXY_PORT=
|
||
```
|
||
|
||
以 Clash 为例,建议指定 `api.openai.com` 走代理,其他请求都直连。示例配置如下:
|
||
|
||
```yaml
|
||
mixed-port: 7890
|
||
allow-lan: false
|
||
bind-address: '*'
|
||
mode: rule
|
||
log-level: warning
|
||
dns:
|
||
enable: true
|
||
ipv6: false
|
||
nameserver:
|
||
- 8.8.8.8
|
||
- 8.8.4.4
|
||
cache-size: 400
|
||
proxies:
|
||
-
|
||
proxy-groups:
|
||
- { name: '♻️ 自动选择', type: url-test, proxies: [香港V01×1.5], url: 'https://api.openai.com', interval: 3600}
|
||
rules:
|
||
- 'DOMAIN-SUFFIX,api.openai.com,♻️ 自动选择'
|
||
- 'MATCH,DIRECT'
|
||
```
|
||
|
||
然后给 FastGPT 添加两个环境变量:
|
||
|
||
```bash
|
||
AXIOS_PROXY_HOST=127.0.0.1
|
||
AXIOS_PROXY_PORT=7890
|
||
```
|
||
|
||
# Nginx 中转
|
||
## 使用 Sealos 部署 Nginx 实现中转
|
||
|
||
## 登录 Sealos
|
||
|
||
[Sealos](https://cloud.sealos.io?uid=fnWRt09fZP)
|
||
|
||
## 创建应用
|
||
|
||
打开 「应用管理」,点击「新建应用」:
|
||
|
||

|
||

|
||
|
||
### 填写基本配置
|
||
|
||
务必开启外网访问,复制外网访问提供的地址。
|
||
|
||

|
||
|
||
### 添加配置文件
|
||
|
||
1. 复制下面这段配置文件,注意 `server_name` 后面的内容替换成第二步的外网访问地址。
|
||
|
||
```nginx
|
||
user nginx;
|
||
worker_processes auto;
|
||
worker_rlimit_nofile 51200;
|
||
|
||
events {
|
||
worker_connections 1024;
|
||
}
|
||
|
||
http {
|
||
resolver 8.8.8.8;
|
||
proxy_ssl_server_name on;
|
||
|
||
access_log off;
|
||
server_names_hash_bucket_size 512;
|
||
client_header_buffer_size 64k;
|
||
large_client_header_buffers 4 64k;
|
||
client_max_body_size 50M;
|
||
|
||
proxy_connect_timeout 240s;
|
||
proxy_read_timeout 240s;
|
||
proxy_buffer_size 128k;
|
||
proxy_buffers 4 256k;
|
||
|
||
server {
|
||
listen 80;
|
||
server_name tgohwtdlrmer.cloud.sealos.io; # 这个地方替换成 Sealos 提供的外网地址
|
||
|
||
location ~ /openai/(.*) {
|
||
proxy_pass https://api.openai.com/$1$is_args$args;
|
||
proxy_set_header Host api.openai.com;
|
||
proxy_set_header X-Real-IP $remote_addr;
|
||
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
|
||
# 如果响应是流式的
|
||
proxy_set_header Connection '';
|
||
proxy_http_version 1.1;
|
||
chunked_transfer_encoding off;
|
||
proxy_buffering off;
|
||
proxy_cache off;
|
||
# 如果响应是一般的
|
||
proxy_buffer_size 128k;
|
||
proxy_buffers 4 256k;
|
||
proxy_busy_buffers_size 256k;
|
||
}
|
||
}
|
||
}
|
||
```
|
||
|
||
2. 点开高级配置。
|
||
3. 点击「新增配置文件」。
|
||
4. 文件名写: `/etc/nginx/nginx.conf`。
|
||
5. 文件值为刚刚复制的那段代码。
|
||
6. 点击确认。
|
||
|
||

|
||
|
||
### 部署应用
|
||
|
||
填写完毕后,点击右上角的「部署」,即可完成部署。
|
||
|
||
## 修改 FastGPT 环境变量
|
||
|
||
1. 进入刚刚部署应用的详情,复制外网地址
|
||
|
||
> 注意:这是个 API 地址,点击打开是无效的。如需验证,可以访问: `*.cloud.sealos.io/openai/api`,如果提示 `Invalid URL (GET /api)` 则代表成功。
|
||
|
||

|
||
|
||
2. 修改环境变量(是 FastGPT 的环境变量,不是 Sealos 的):
|
||
|
||
```bash
|
||
OPENAI_BASE_URL=https://tgohwtdlrmer.cloud.sealos.io/openai/v1
|
||
```
|
||
|
||
**Done!**
|
||
|
||
# Sealos 一键部署
|
||
## 使用 Sealos 一键部署 FastGPT
|
||
|
||
## 部署架构图
|
||
|
||

|
||
|
||
## 多模型支持
|
||
|
||
FastGPT 使用了 one-api 项目来管理模型池,其可以兼容 OpenAI 、Azure 、国内主流模型和本地模型等。
|
||
|
||
可参考:[Sealos 快速部署 OneAPI](/docs/development/modelconfig/one-api)
|
||
|
||
|
||
## 一键部署
|
||
|
||
使用 Sealos 服务,无需采购服务器、无需域名,支持高并发 & 动态伸缩,并且数据库应用采用 kubeblocks 的数据库,在 IO 性能方面,远超于简单的 Docker 容器部署。可以根据需求,再下面两个区域选择部署。
|
||
|
||
### 新加坡区
|
||
|
||
新加披区的服务器在国外,可以直接访问 OpenAI,但国内用户需要梯子才可以正常访问新加坡区。国际区价格稍贵,点击下面按键即可部署👇
|
||
|
||
<a href="https://template.cloud.sealos.io/deploy?templateName=fastgpt&uid=fnWRt09fZP" rel="external" target="_blank"><img src="https://cdn.jsdelivr.net/gh/labring-actions/templates@main/Deploy-on-Sealos.svg" alt="Deploy on Sealos"/></a>
|
||
|
||
### 北京区
|
||
|
||
北京区服务提供商为火山云,国内用户可以稳定访问,但无法访问 OpenAI 等境外服务,价格约为新加坡区的 1/4。点击下面按键即可部署👇
|
||
|
||
<a href="https://bja.sealos.run/?openapp=system-template%3FtemplateName%3Dfastgpt&uid=fnWRt09fZP" rel="external" target="_blank"><img src="https://raw.githubusercontent.com/labring-actions/templates/main/Deploy-on-Sealos.svg" alt="Deploy on Sealos"/></a>
|
||
|
||
### 1. 开始部署
|
||
|
||
由于需要部署数据库,部署完后需要等待 2~4 分钟才能正常访问。默认用了最低配置,首次访问时会有些慢。
|
||
|
||
根据提示,输入`root_password`,和 `openai`/`oneapi` 的地址和密钥。
|
||
|
||

|
||
|
||
点击部署后,会跳转到应用管理页面。可以点击`fastgpt`主应用右侧的详情按键(名字为 fastgpt-xxxx), 如下图所示。
|
||
|
||

|
||
|
||
点击详情后,会跳转到 fastgpt 的部署管理页面,点击外网访问地址中的链接,即可打开 fastgpt 服务。
|
||
|
||
如需绑定自定义域名、修改部署参数,可以点击右上角变更,根据 sealos 的指引完成。
|
||
|
||

|
||
|
||
### 2. 登录
|
||
|
||
用户名:`root`
|
||
|
||
密码是刚刚一键部署时设置的`root_password`
|
||
|
||
### 3. 配置模型
|
||
|
||
### 4. 配置模型
|
||
|
||
务必先配置至少一组模型,否则系统无法正常使用。
|
||
|
||
[点击查看模型配置教程](/docs/development/modelConfig/intro/)
|
||
|
||
## 收费
|
||
|
||
Sealos 采用按量计费的方式,也就是申请了多少 cpu、内存、磁盘,就按该申请量进行计费。具体的计费标准,可以打开`sealos`控制面板中的`费用中心`进行查看。
|
||
|
||
## Sealos 使用
|
||
|
||
### 简介
|
||
|
||
FastGPT 商业版共包含了2个应用(fastgpt, fastgpt-plus)和2个数据库,使用多 Api Key 时候需要安装 OneAPI(一个应用和一个数据库),总计3个应用和3个数据库。
|
||
|
||

|
||
|
||
点击右侧的详情,可以查看对应应用的详细信息。
|
||
|
||
### 修改配置文件和环境变量
|
||
|
||
在 Sealos 中,你可以打开`应用管理`(App Launchpad)看到部署的 FastGPT,可以打开`数据库`(Database)看到对应的数据库。
|
||
|
||
在`应用管理`中,选中 FastGPT,点击变更,可以看到对应的环境变量和配置文件。
|
||
|
||

|
||
|
||
{{% alert icon="🤖 " context="success" %}}
|
||
在 Sealos 上,FastGPT 一共运行了 1 个服务和 2 个数据库,如暂停和删除请注意数据库一同操作。(你可以白天启动,晚上暂停它们,省钱大法)
|
||
{{% /alert %}}
|
||
|
||
### 如何更新/升级 FastGPT
|
||
|
||
[升级脚本文档](https://doc.tryfastgpt.ai/docs/development/upgrading/)先看下文档,看下需要升级哪个版本。注意,不要跨版本升级!!!!!
|
||
|
||
例如,目前是4.5 版本,要升级到4.5.1,就先把镜像版本改成v4.5.1,执行一下升级脚本,等待完成后再继续升级。如果目标版本不需要执行初始化,则可以跳过。
|
||
|
||
升级步骤:
|
||
|
||
1. 查看[更新文档](/docs/development/upgrading/intro/),确认要升级的版本,避免跨版本升级。
|
||
2. 打开 sealos 的应用管理
|
||
3. 有2个应用 fastgpt , fastgpt-pro
|
||
4. 点击对应应用右边3个点,变更。或者点详情后右上角的变更。
|
||
5. 修改镜像的版本号
|
||
|
||

|
||
|
||
6. 点击变更/重启,会自动拉取最新镜像进行更新
|
||
7. 执行对应版本的初始化脚本(如果有)
|
||
|
||
### 如何获取 FastGPT 访问链接
|
||
|
||
打开对应的应用,点击外网访问地址。
|
||
|
||

|
||
|
||
### 配置自定义域名
|
||
|
||
点击对应应用的变更->点击自定义域名->填写域名-> 操作域名 Cname -> 确认 -> 确认变。
|
||
|
||

|
||
|
||
### 如何修改配置文件
|
||
|
||
打开 Sealos 的应用管理 -> 找到对应的应用 -> 变更 -> 往下拉到高级配置,里面有个配置文件 -> 新增或点击对应的配置文件可以进行编辑 -> 点击右上角确认变。
|
||
|
||

|
||
|
||
[配置文件参考](https://doc.tryfastgpt.ai/docs/development/configuration/)
|
||
|
||
### 修改站点名称以及 favicon
|
||
修改应用的环境变量,增加
|
||
|
||
```
|
||
SYSTEM_NAME=FastGPT
|
||
SYSTEM_DESCRIPTION=
|
||
SYSTEM_FAVICON=/favicon.ico
|
||
HOME_URL=/dashboard/apps
|
||
```
|
||
|
||
SYSTEM_FAVICON 可以是一个网络地址
|
||
|
||

|
||
|
||
### 挂载logo
|
||
目前暂时无法 把浏览器上的logo替换。仅支持svg,待后续可视化做了后可以全部替换。
|
||
新增一个挂载文件,文件名为:/app/projects/app/public/icon/logo.svg ,值为 svg 对应的值。
|
||
|
||

|
||
|
||

|
||
|
||
### 商业版镜像配置文件
|
||
|
||
```
|
||
{
|
||
"license": "",
|
||
"system": {
|
||
"title": "" // 系统名称
|
||
}
|
||
}
|
||
```
|
||
|
||
### One API 使用
|
||
|
||
[参考 OneAPI 使用步骤](/docs/development/modelconfig/one-api/)
|
||
|
||
# 升级到 V4.0
|
||
## FastGPT 从旧版本升级到 V4.0 操作指南
|
||
|
||
如果您是**从旧版本升级到 V4**,由于新版 MongoDB 表变更比较大,需要按照本文档的说明执行一些初始化脚本。
|
||
|
||
## 重命名表名
|
||
|
||
需要连接上 MongoDB 数据库,执行两条命令:
|
||
|
||
```mongodb
|
||
db.models.renameCollection("apps")
|
||
db.sharechats.renameCollection("outlinks")
|
||
```
|
||
|
||
{{% alert context="warning" %}}
|
||
注意:从旧版更新到 V4, MongoDB 会自动创建空表,你需要先手动删除这两个空表,再执行上面的操作。
|
||
{{% /alert %}}
|
||
|
||
## 初始化几个表中的字段
|
||
|
||
依次执行下面 3 条命令,时间比较长,不成功可以重复执行(会跳过已经初始化的数据),直到所有数据更新完成。
|
||
|
||
```mongodb
|
||
db.chats.find({appId: {$exists: false}}).forEach(function(item){
|
||
db.chats.updateOne(
|
||
{
|
||
_id: item._id,
|
||
},
|
||
{ "$set": {"appId":item.modelId}}
|
||
)
|
||
})
|
||
|
||
db.collections.find({appId: {$exists: false}}).forEach(function(item){
|
||
db.collections.updateOne(
|
||
{
|
||
_id: item._id,
|
||
},
|
||
{ "$set": {"appId":item.modelId}}
|
||
)
|
||
})
|
||
|
||
db.outlinks.find({shareId: {$exists: false}}).forEach(function(item){
|
||
db.outlinks.updateOne(
|
||
{
|
||
_id: item._id,
|
||
},
|
||
{ "$set": {"shareId":item._id.toString(),"appId":item.modelId}}
|
||
)
|
||
})
|
||
```
|
||
|
||
## 初始化 API
|
||
|
||
部署新版项目,并发起 3 个 HTTP 请求(记得携带 `headers.rootkey`,这个值是环境变量里的)
|
||
|
||
1. https://xxxxx/api/admin/initv4
|
||
2. https://xxxxx/api/admin/initChat
|
||
3. https://xxxxx/api/admin/initOutlink
|
||
|
||
1 和 2 有可能会因为内存不足挂掉,可以重复执行。
|
||
|
||
# 升级到 V4.1
|
||
## FastGPT 从旧版本升级到 V4.1 操作指南
|
||
|
||
如果您是**从旧版本升级到 V4.1**,由于新版重新设置了对话存储结构,需要初始化原来的存储内容。
|
||
|
||
## 更新环境变量
|
||
|
||
V4.1 优化了 PostgreSQL 和 MongoDB 的连接变量,只需要填 1 个 URL 即可:
|
||
|
||
注意:/fastgpt 和 /postgres 是指数据库名称,需要和旧版的变量对应。
|
||
|
||
```bash
|
||
# mongo 配置,不需要改. 如果连不上,可能需要去掉 ?authSource=admin
|
||
- MONGODB_URI=mongodb://username:password@mongo:27017/fastgpt?authSource=admin
|
||
# pg配置. 不需要改
|
||
- PG_URL=postgresql://username:password@pg:5432/postgres
|
||
```
|
||
|
||
## 初始化 API
|
||
|
||
部署新版项目,并发起 1 个 HTTP 请求(记得携带 `headers.rootkey`,这个值是环境变量里的)
|
||
|
||
- https://xxxxx/api/admin/initChatItem
|
||
|
||
# 升级到 V4.2
|
||
## FastGPT 从旧版本升级到 V4.2 操作指南
|
||
|
||
99.9%用户不影响,升级 4.2 主要是修改了配置文件中 QAModel 的格式。从原先的数组改成对象:
|
||
|
||
```json
|
||
"QAModel": {
|
||
"model": "gpt-3.5-turbo-16k",
|
||
"name": "GPT35-16k",
|
||
"maxToken": 16000,
|
||
"price": 0
|
||
}
|
||
```
|
||
|
||
改动目的是,我们认为不需要留有选择余地,选择一个最合适的模型去进行任务即可。
|
||
|
||
# 升级到 V4.2.1
|
||
## FastGPT 从旧版本升级到 V4.2.1 操作指南
|
||
|
||
私有部署,如果添加了配置文件,需要在配置文件中修改 `VectorModels` 字段。增加 defaultToken 和 maxToken,分别对应直接分段时的默认 token 数量和该模型支持的 token 上限 (通常不建议超过 3000)
|
||
|
||
```json
|
||
"VectorModels": [
|
||
{
|
||
"model": "text-embedding-ada-002",
|
||
"name": "Embedding-2",
|
||
"price": 0,
|
||
"defaultToken": 500,
|
||
"maxToken": 3000
|
||
}
|
||
]
|
||
```
|
||
|
||
改动目的是,我们认为不需要留有选择余地,选择一个最合适的模型去进行任务即可。
|
||
|
||
# 升级到 V4.3(包含升级脚本)
|
||
## FastGPT 从旧版本升级到 V4.3 操作指南
|
||
|
||
## 执行初始化 API
|
||
|
||
发起 1 个 HTTP 请求 (记得携带 `headers.rootkey`,这个值是环境变量里的)
|
||
|
||
1. https://xxxxx/api/admin/initv43
|
||
|
||
```bash
|
||
curl --location --request POST 'https://{{host}}/api/admin/initv43' \
|
||
--header 'rootkey: {{rootkey}}' \
|
||
--header 'Content-Type: application/json'
|
||
```
|
||
|
||
会给 PG 数据库的 modeldata 表插入一个新列 file_id,用于存储文件 ID。
|
||
|
||
## 增加环境变量
|
||
|
||
增加一个 `FILE_TOKEN_KEY` 环境变量,用于生成文件预览链接,过期时间为 30 分钟。
|
||
|
||
```
|
||
FILE_TOKEN_KEY=filetokenkey
|
||
```
|
||
|
||
# 升级到 V4.4(包含升级脚本)
|
||
## FastGPT 从旧版本升级到 V4.4 操作指南
|
||
|
||
## 执行初始化 API
|
||
|
||
发起 1 个 HTTP 请求 (记得携带 `headers.rootkey`,这个值是环境变量里的)
|
||
|
||
1. https://xxxxx/api/admin/initv44
|
||
|
||
```bash
|
||
curl --location --request POST 'https://{{host}}/api/admin/initv44' \
|
||
--header 'rootkey: {{rootkey}}' \
|
||
--header 'Content-Type: application/json'
|
||
```
|
||
|
||
会给初始化 Mongo 的部分字段。
|
||
|
||
# 升级到 V4.4.1(包含升级脚本)
|
||
## FastGPT 从旧版本升级到 V4.4.1 操作指南
|
||
|
||
## 执行初始化 API
|
||
|
||
发起 1 个 HTTP 请求(记得携带 `headers.rootkey`,这个值是环境变量里的)
|
||
|
||
1. https://xxxxx/api/admin/initv441
|
||
|
||
```bash
|
||
curl --location --request POST 'https://{{host}}/api/admin/initv441' \
|
||
--header 'rootkey: {{rootkey}}' \
|
||
--header 'Content-Type: application/json'
|
||
```
|
||
|
||
会给初始化 Mongo 的 dataset.files,将所有数据设置为可用。
|
||
|
||
# 升级到 V4.4.2(包含升级脚本)
|
||
## FastGPT 从旧版本升级到 V4.4.2 操作指南
|
||
|
||
## 执行初始化 API
|
||
|
||
发起 1 个 HTTP 请求 (记得携带 `headers.rootkey`,这个值是环境变量里的)
|
||
|
||
1. https://xxxxx/api/admin/initv442
|
||
|
||
```bash
|
||
curl --location --request POST 'https://{{host}}/api/admin/initv442' \
|
||
--header 'rootkey: {{rootkey}}' \
|
||
--header 'Content-Type: application/json'
|
||
```
|
||
|
||
会给初始化 Mongo 的 Bill 表的索引,之前过期时间有误。
|
||
|
||
# V4.4.5(包含升级脚本)
|
||
## FastGPT V4.4.5 更新
|
||
|
||
## 执行初始化 API
|
||
|
||
发起 1 个 HTTP 请求(记得携带 `headers.rootkey`,这个值是环境变量里的)
|
||
|
||
1. https://xxxxx/api/admin/initv445
|
||
|
||
```bash
|
||
curl --location --request POST 'https://{{host}}/api/admin/initv445' \
|
||
--header 'rootkey: {{rootkey}}' \
|
||
--header 'Content-Type: application/json'
|
||
```
|
||
|
||
初始化了 variable 模块,将其合并到用户引导模块中。
|
||
|
||
## 功能介绍
|
||
|
||
### Fast GPT V4.4.5
|
||
|
||
1. 新增 - 下一步指引选项,可以通过模型生成 3 个预测问题。
|
||
2. 商业版新增 - 分享链接限制及 hook 身份校验(可对接已有的用户系统)。
|
||
3. 商业版新增 - Api Key 使用。增加别名、额度限制和过期时间。自带 appId,无需额外连接。
|
||
4. 优化 - 全局变量与开场白合并成同一模块。
|
||
|
||
# V4.4.6
|
||
## FastGPT V4.4.6 更新
|
||
|
||
## 功能介绍
|
||
|
||
1. 高级编排新增模块 - 应用调用,可调用其他应用。
|
||
2. 新增 - 必要连接校验
|
||
3. 修复 - 下一步指引在免登录中身份问题。
|
||
|
||
# V4.4.7(需执行升级脚本)
|
||
## FastGPT V4.4.7 更新(需执行升级脚本)
|
||
|
||
## 执行初始化 API
|
||
|
||
发起 1 个 HTTP 请求({{rootkey}} 替换成环境变量里的`rootkey`,{{host}}替换成自己域名)
|
||
|
||
1. https://xxxxx/api/admin/initv447
|
||
|
||
```bash
|
||
curl --location --request POST 'https://{{host}}/api/admin/initv447' \
|
||
--header 'rootkey: {{rootkey}}' \
|
||
--header 'Content-Type: application/json'
|
||
```
|
||
|
||
初始化 pg 索引以及将 file_id 中空对象转成 manual 对象。如果数据多,可能需要较长时间,可以通过日志查看进度。
|
||
|
||
## 功能介绍
|
||
|
||
### Fast GPT V4.4.7
|
||
|
||
1. 优化了数据库文件 crud。
|
||
2. 兼容链接读取,作为 source。
|
||
3. 区分手动录入和标注,可追数据至某个文件。
|
||
4. 升级 openai sdk。
|
||
|
||
# V4.5(需进行较为复杂更新)
|
||
## FastGPT V4.5 更新
|
||
|
||
FastGPT V4.5 引入 PgVector0.5 版本的 HNSW 索引,极大的提高了知识库检索的速度,比起`IVFFlat`索引大致有3~10倍的性能提升,可轻松实现百万数据毫秒级搜索。缺点在于构建索引的速度非常慢,4c16g 500w 组数据使用`并行构建`大约花了 48 小时。具体参数配置可参考 [PgVector官方](https://github.com/pgvector/pgvector)
|
||
|
||
下面需要对数据库进行一些操作升级:
|
||
|
||
## PgVector升级:Sealos 部署方案
|
||
|
||
1. 点击[Sealos桌面](https://cloud.sealos.io?uid=fnWRt09fZP)的数据库应用。
|
||
2. 点击【pg】数据库的详情。
|
||
3. 点击右上角的重启,等待重启完成。
|
||
4. 点击左侧的一键链接,等待打开 Terminal。
|
||
5. 依次输入下方 sql 命令
|
||
|
||
```sql
|
||
-- 升级插件名
|
||
ALTER EXTENSION vector UPDATE;
|
||
-- 插件是否升级成功,成功的话,vector插件版本为 0.5.0,旧版的为 0.4.1
|
||
\dx
|
||
|
||
-- 下面两个语句会设置 pg 在构建索引时可用的内存大小,需根据自身的数据库规格来动态配置,可配置为 1/4 的内存大小
|
||
alter system set maintenance_work_mem = '2400MB';
|
||
select pg_reload_conf();
|
||
|
||
-- 重构数据库索引和排序
|
||
REINDEX DATABASE postgres;
|
||
|
||
-- 开始构建索引,该索引构建时间非常久,直接点击右上角的叉,退出 Terminal 即可
|
||
CREATE INDEX CONCURRENTLY vector_index ON modeldata USING hnsw (vector vector_ip_ops) WITH (m = 16, ef_construction = 64);
|
||
-- 可以再次点击一键链接,进入 Terminal,输入下方命令,如果看到 "vector_index" hnsw (vector vector_ip_ops) WITH (m='16', ef_construction='64') 则代表构建完成(注意,后面没有 INVALID)
|
||
\d modeldata
|
||
```
|
||
|
||
| | |
|
||
| --------------------- | --------------------- |
|
||
|  |  |
|
||
|  |  |
|
||
|
||
|
||
|
||
## PgVector升级:Docker-compose.yml 部署方案
|
||
|
||
下面的命令是基于给的 docker-compose 模板,如果数据库账号密码更换了,请自行调整。
|
||
|
||
1. 修改 `docker-compose.yml` 中pg的镜像版本,改成 `ankane/pgvector:v0.5.0` 或 `registry.cn-hangzhou.aliyuncs.com/fastgpt/pgvector:v0.5.0`
|
||
2. 重启 pg 容器(docker-compose pull && docker-compose up -d),等待重启完成。
|
||
3. 进入容器: `docker exec -it pg bash`
|
||
4. 连接数据库: `psql 'postgresql://username:password@localhost:5432/postgres'`
|
||
5. 执行下面 sql 命令
|
||
|
||
```sql
|
||
-- 升级插件名
|
||
ALTER EXTENSION vector UPDATE;
|
||
-- 插件是否升级成功,成功的话,vector插件版本为 0.5.0,旧版的为 0.4.2
|
||
\dx
|
||
|
||
-- 下面两个语句会设置 pg 在构建索引时可用的内存大小,需根据自身的数据库规格来动态配置,可配置为 1/4 的内存大小
|
||
alter system set maintenance_work_mem = '2400MB';
|
||
select pg_reload_conf();
|
||
|
||
-- 重构数据库索引和排序
|
||
REINDEX DATABASE postgres;
|
||
ALTER DATABASE postgres REFRESH COLLATION VERSION;
|
||
|
||
-- 开始构建索引,该索引构建时间非常久,直接关掉终端即可,不要使用 ctrl+c 关闭
|
||
CREATE INDEX CONCURRENTLY vector_index ON modeldata USING hnsw (vector vector_ip_ops) WITH (m = 16, ef_construction = 64);
|
||
-- 可以再次连接数据库,输入下方命令。如果看到 "vector_index" hnsw (vector vector_ip_ops) WITH (m='16', ef_construction='64') 则代表构建完成(注意,后面没有 INVALID)
|
||
\d modeldata
|
||
|
||
|
||
```
|
||
|
||
## 版本新功能介绍
|
||
|
||
### Fast GPT V4.5
|
||
|
||
1. 新增 - 升级 PgVector 插件,引入 HNSW 索引,极大加快的知识库搜索速度。
|
||
2. 新增 - AI对话模块,增加【返回AI内容】选项,可控制 AI 的内容不直接返回浏览器。
|
||
3. 新增 - 支持问题分类选择模型
|
||
4. 优化 - TextSplitter,采用递归拆解法。
|
||
5. 优化 - 高级编排 UX 性能
|
||
6. 修复 - 分享链接鉴权问题
|
||
|
||
## 该版本需要修改 `config.json` 文件
|
||
|
||
最新配置可参考: [V45版本最新 config.json](/docs/development/configuration)
|
||
|
||
# V4.5.1(需进行初始化)
|
||
## FastGPT V4.5.1 更新
|
||
|
||
## 执行初始化 API
|
||
|
||
发起 1 个 HTTP 请求({{rootkey}} 替换成环境变量里的`rootkey`,{{host}}替换成自己域名)
|
||
|
||
1. https://xxxxx/api/admin/initv451
|
||
|
||
```bash
|
||
curl --location --request POST 'https://{{host}}/api/admin/initv451' \
|
||
--header 'rootkey: {{rootkey}}' \
|
||
--header 'Content-Type: application/json'
|
||
```
|
||
|
||
初始化内容:
|
||
1. rename 数据库字段
|
||
2. 初始化 Mongo APP 表中知识库的相关字段
|
||
3. 初始化 PG 和 Mongo 的内容,为每个文件创建一个集合(存储 Mongo 中),并反馈赋值给 PG。
|
||
|
||
**该初始化接口可能速度很慢,返回超时不用管,注意看日志即可**
|
||
|
||
## 功能介绍
|
||
|
||
### Fast GPT V4.5.1
|
||
|
||
1. 新增知识库文件夹管理
|
||
2. 修复了 openai4.x sdk 无法兼容 oneapi 的智谱和阿里的接口。
|
||
3. 修复部分模块无法触发完成事件
|
||
|
||
# V4.5.2
|
||
## FastGPT V4.5.2 更新
|
||
|
||
## 功能介绍
|
||
|
||
### Fast GPT V4.5.2
|
||
|
||
1. 新增 - 模块插件,允许自行组装插件进行模块复用。
|
||
2. 优化 - 知识库引用提示。
|
||
|
||
# V4.6(包含升级脚本)
|
||
## FastGPT V4.6 更新
|
||
|
||
**V4.6 版本加入了简单的团队功能,可以邀请其他用户进来管理资源。该版本升级后无法执行旧的升级脚本,且无法回退。**
|
||
|
||
## 1。更新镜像并变更配置文件
|
||
|
||
更新镜像至 latest 或者 v4.6 版本。商业版镜像更新至 V0.2.1
|
||
|
||
最新配置可参考:[V46 版本最新 config.json](/docs/development/configuration),商业镜像配置文件也更新,参考最新的飞书文档。
|
||
|
||
|
||
## 2。执行初始化 API
|
||
|
||
发起 2 个 HTTP 请求 ({{rootkey}} 替换成环境变量里的 `rootkey`,{{host}} 替换成自己域名)
|
||
|
||
**该初始化接口可能速度很慢,返回超时不用管,注意看日志即可,需要注意的是,需确保 initv46 成功后,在执行 initv46-2**
|
||
|
||
1. https://xxxxx/api/admin/initv46
|
||
|
||
```bash
|
||
curl --location --request POST 'https://{{host}}/api/admin/initv46' \
|
||
--header 'rootkey: {{rootkey}}' \
|
||
--header 'Content-Type: application/json'
|
||
```
|
||
|
||
2. https://xxxxx/api/admin/initv46-2
|
||
|
||
```bash
|
||
curl --location --request POST 'https://{{host}}/api/admin/initv46-2' \
|
||
--header 'rootkey: {{rootkey}}' \
|
||
--header 'Content-Type: application/json'
|
||
```
|
||
|
||
初始化内容:
|
||
1。创建默认团队
|
||
2。初始化 Mongo 所有资源的团队字段
|
||
3。初始化 Pg 的字段
|
||
4。初始化 Mongo Data
|
||
|
||
|
||
## V4.6 功能介绍
|
||
|
||
1. 新增 - 团队空间
|
||
2. 新增 - 多路向量 (多个向量映射一组数据)
|
||
3. 新增 - tts 语音
|
||
4. 新增 - 支持知识库配置文本预处理模型
|
||
5. 线上环境新增 - ReRank 向量召回,提高召回精度
|
||
6. 优化 - 知识库导出,可直接触发流下载,无需等待转圈圈
|
||
|
||
## 4.6 缺陷修复
|
||
|
||
旧的 4.6 版本由于缺少一个字段,导致文件导入时知识库数据无法显示,可执行下面的脚本:
|
||
|
||
https://xxxxx/api/admin/initv46-fix
|
||
|
||
```bash
|
||
curl --location --request POST 'https://{{host}}/api/admin/initv46-fix' \
|
||
--header 'rootkey: {{rootkey}}' \
|
||
--header 'Content-Type: application/json'
|
||
```
|
||
|
||
# V4.6.1
|
||
## FastGPT V4.6 .1
|
||
|
||
## V4.6.1 功能介绍
|
||
|
||
1. 新增 - GPT4-v 模型支持
|
||
2. 新增 - whisper 语音输入
|
||
3. 优化 - TTS 流传输
|
||
4. 优化 - TTS 缓存
|
||
|
||
# V4.6.2(包含升级脚本)
|
||
## FastGPT V4.6.2
|
||
|
||
## 1。执行初始化 API
|
||
|
||
发起 1 个 HTTP 请求 ({{rootkey}} 替换成环境变量里的 `rootkey`,{{host}} 替换成自己域名)
|
||
|
||
1. https://xxxxx/api/admin/initv462
|
||
|
||
```bash
|
||
curl --location --request POST 'https://{{host}}/api/admin/initv462' \
|
||
--header 'rootkey: {{rootkey}}' \
|
||
--header 'Content-Type: application/json'
|
||
```
|
||
|
||
初始化说明:
|
||
1. 初始化全文索引
|
||
|
||
## V4.6.2 功能介绍
|
||
|
||
1. 新增 - 全文索引(需配合 Rerank 模型,在看怎么放到开源版,模型接口比较特殊)
|
||
2. 新增 - 插件来源(预计4.7/4.8版本会正式使用)
|
||
3. 优化 - PDF读取
|
||
4. 优化 - docx文件读取,转成 markdown 并保留其图片内容
|
||
5. 修复和优化 TextSplitter 函数
|
||
|
||
# V4.6.3(包含升级脚本)
|
||
## FastGPT V4.6.3
|
||
|
||
## 1。执行初始化 API
|
||
|
||
发起 1 个 HTTP 请求 ({{rootkey}} 替换成环境变量里的 `rootkey`,{{host}} 替换成自己域名)
|
||
|
||
1. https://xxxxx/api/admin/initv463
|
||
|
||
```bash
|
||
curl --location --request POST 'https://{{host}}/api/admin/initv463' \
|
||
--header 'rootkey: {{rootkey}}' \
|
||
--header 'Content-Type: application/json'
|
||
```
|
||
|
||
初始化说明:
|
||
1. 初始化Mongo 中 dataset,collection 和 data 的部分字段
|
||
|
||
## V4.6.3 功能介绍
|
||
|
||
1. 商业版新增 - web站点同步
|
||
2. 新增 - 集合元数据记录
|
||
3. 优化 - url 读取内容
|
||
4. 优化 - 流读取文件,防止内存溢出
|
||
5. 优化 - 4v模型自动将 url 转 base64,本地也可调试
|
||
6. 优化 - 图片压缩等级
|
||
7. 修复 - 图片压缩失败报错,防止文件读取过程卡死。
|
||
|
||
# V4.6.4(包含升级脚本)
|
||
## FastGPT V4.6.4
|
||
|
||
## 1。执行初始化 API
|
||
|
||
发起 1 个 HTTP 请求 ({{rootkey}} 替换成环境变量里的 `rootkey`,{{host}} 替换成自己域名)
|
||
|
||
1. https://xxxxx/api/admin/initv464
|
||
|
||
```bash
|
||
curl --location --request POST 'https://{{host}}/api/admin/initv464' \
|
||
--header 'rootkey: {{rootkey}}' \
|
||
--header 'Content-Type: application/json'
|
||
```
|
||
|
||
初始化说明:
|
||
1. 初始化 PG 的createTime字段
|
||
2. 初始化 Mongo 中 chat 的 feedback 字段
|
||
|
||
|
||
## V4.6.4 功能介绍
|
||
|
||
1. 重写 - 分享链接身份逻辑,采用 localID 记录用户的ID。
|
||
2. 商业版新增 - 分享链接 SSO 方案,通过`身份鉴权`地址,仅需`3个接口`即可完全接入已有用户系统。具体参考[分享链接身份鉴权](/docs/development/openapi/share/)
|
||
3. 新增 - 分享链接更多嵌入方式提示,更多DIY方式。
|
||
4. 优化 - 历史记录模块。弃用旧的历史记录模块,直接在对应地方填写数值即可。
|
||
5. 调整 - 知识库搜索模块 topk 逻辑,采用 MaxToken 计算,兼容不同长度的文本块
|
||
6. 调整鉴权顺序,提高 apikey 的优先级,避免cookie抢占 apikey 的鉴权。
|
||
7. 链接读取支持多选择器。参考[Web 站点同步用法](/docs/guide/knowledge_base/websync/)
|
||
8. 修复 - 分享链接图片上传鉴权问题
|
||
9. 修复 - Mongo 连接池未释放问题。
|
||
10. 修复 - Dataset Intro 无法更新
|
||
11. 修复 - md 代码块问题
|
||
12. 修复 - root 权限问题
|
||
13. 优化 docker file
|
||
|
||
# V4.6.5(需要改配置文件)
|
||
## FastGPT V4.6.5
|
||
|
||
## 配置文件变更
|
||
|
||
由于 openai 已开始弃用 function call,改为 toolChoice。FastGPT 同步的修改了对于的配置和调用方式,需要对配置文件做一些修改:
|
||
|
||
[点击查看最新的配置文件](/docs/development/configuration/)
|
||
|
||
1. 主要是修改模型的`functionCall`字段,改成`toolChoice`即可。设置为`true`的模型,会默认走 openai 的 tools 模式;未设置或设置为`false`的,会走提示词生成模式。
|
||
|
||
问题优化模型与内容提取模型使用同一组配置。
|
||
|
||
2. 增加 `"ReRankModels": []`
|
||
|
||
## V4.6.5 功能介绍
|
||
|
||
1. 新增 - [问题优化模块](/docs/guide/dashboard/workflow/coreferenceresolution/)
|
||
2. 新增 - [文本编辑模块](/docs/guide/dashboard/workflow/text_editor/)
|
||
3. 新增 - [判断器模块](/docs/guide/dashboard/workflow/tfswitch//)
|
||
4. 新增 - [自定义反馈模块](/docs/guide/dashboard/workflow/custom_feedback/)
|
||
5. 新增 - 【内容提取】模块支持选择模型,以及字段枚举
|
||
6. 优化 - docx读取,兼容表格(表格转markdown)
|
||
7. 优化 - 高级编排连接线交互
|
||
8. 优化 - 由于 html2md 导致的 cpu密集计算,阻断线程问题
|
||
9. 修复 - 高级编排提示词提取描述
|
||
|
||
# V4.6.6(需要改配置文件)
|
||
## FastGPT V4.6.6
|
||
|
||
## 配置文件变更
|
||
|
||
为了减少代码重复度,我们对配置文件做了一些修改:[点击查看最新的配置文件](/docs/development/configuration/)
|
||
|
||
## 商业版变更
|
||
|
||
1. 更新商业版镜像到 4.6.6 版本。
|
||
2. 将旧版配置文件中的 `SystemParams.pluginBaseUrl` 放置到环境变量中:
|
||
|
||
PRO_URL=商业版镜像地址(此处不再需要以 /api 结尾),例如:
|
||
PRO_URL=http://fastgpt-plugin.ns-hsss5d.svc.cluster.local:3000
|
||
|
||
3. 原本在配置文件中的 `FeConfig` 已被移除,可以直接打开新的商业版镜像外网地址进行配置。包括 FastGPT 的各个参数和模型都可以直接在商业版镜像中配置,无需再变更 `config.json` 文件。
|
||
|
||
## V4.6.6 更新说明
|
||
|
||
1. 查看 [FastGPT 2024 RoadMap](https://github.com/labring/FastGPT?tab=readme-ov-file#-%E5%9C%A8%E7%BA%BF%E4%BD%BF%E7%94%A8)
|
||
2. 新增 - Http 模块请求头支持 Json 编辑器。
|
||
3. 新增 - [ReRank模型部署](/docs/development/custom-models/bge-rerank/)
|
||
4. 新增 - 搜索方式:分离向量语义检索,全文检索和重排,通过 RRF 进行排序合并。
|
||
5. 优化 - 问题分类提示词,id引导。测试国产商用 api 模型(百度阿里智谱讯飞)使用 Prompt 模式均可分类。
|
||
6. UI 优化,未来将逐步替换新的UI设计。
|
||
7. 优化代码:Icon 抽离和自动化获取。
|
||
8. 修复 - 链接读取的数据集,未保存选择器,导致同步时不使用选择器。
|
||
|
||
# V4.6.7(需要初始化)
|
||
## FastGPT V4.6.7
|
||
|
||
## 1。执行初始化 API
|
||
|
||
发起 1 个 HTTP 请求 ({{rootkey}} 替换成环境变量里的 `rootkey`,{{host}} 替换成自己域名)
|
||
|
||
1. https://xxxxx/api/admin/initv467
|
||
|
||
```bash
|
||
curl --location --request POST 'https://{{host}}/api/admin/initv467' \
|
||
--header 'rootkey: {{rootkey}}' \
|
||
--header 'Content-Type: application/json'
|
||
```
|
||
|
||
初始化说明:
|
||
1. 将 images 重新关联到数据集
|
||
2. 设置 pg 表的 null 值。
|
||
|
||
|
||
## V4.6.7 更新说明
|
||
|
||
1. 修改了知识库UI及新的导入交互方式。
|
||
2. 优化知识库和对话的数据索引。
|
||
3. 知识库 openAPI,支持通过 [API 操作知识库](/docs/development/openapi/dataset)。
|
||
4. 新增 - 输入框变量提示。输入 { 号后将会获得可用变量提示。根据社区针对高级编排的反馈,我们计划于 2 月份的版本中,优化变量内容,支持模块的局部变量以及更多全局变量写入。
|
||
5. 优化 - 切换团队后会保存记录,下次登录时优先登录该团队。
|
||
6. 修复 - API 对话时,chatId 冲突问题。
|
||
7. 修复 - Iframe 嵌入网页可能导致的 window.onLoad 冲突。
|
||
|
||
# V4.6.8(需要初始化)
|
||
## FastGPT V4.6.8更新说明
|
||
|
||
## docker 部署 - 手动更新 Mongo
|
||
|
||
1. 修改 docker-compose.yml 的mongo部分,补上`command`和`entrypoint`
|
||
|
||
```yml
|
||
mongo:
|
||
image: mongo:5.0.18
|
||
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/mongo:5.0.18 # 阿里云
|
||
container_name: mongo
|
||
ports:
|
||
- 27017:27017
|
||
networks:
|
||
- fastgpt
|
||
command: mongod --keyFile /data/mongodb.key --replSet rs0
|
||
environment:
|
||
# 这里密码注意要和以前的一致
|
||
- MONGO_INITDB_ROOT_USERNAME=username
|
||
- MONGO_INITDB_ROOT_PASSWORD=password
|
||
volumes:
|
||
- ./mongo/data:/data/db
|
||
entrypoint:
|
||
- bash
|
||
- -c
|
||
- |
|
||
openssl rand -base64 128 > /data/mongodb.key
|
||
chmod 400 /data/mongodb.key
|
||
chown 999:999 /data/mongodb.key
|
||
echo 'const isInited = rs.status().ok === 1
|
||
if(!isInited){
|
||
rs.initiate({
|
||
_id: "rs0",
|
||
members: [
|
||
{ _id: 0, host: "mongo:27017" }
|
||
]
|
||
})
|
||
}' > /data/initReplicaSet.js
|
||
# 启动MongoDB服务
|
||
exec docker-entrypoint.sh "$@" &
|
||
|
||
# 等待MongoDB服务启动
|
||
until mongo -u myusername -p mypassword --authenticationDatabase admin --eval "print('waited for connection')" > /dev/null 2>&1; do
|
||
echo "Waiting for MongoDB to start..."
|
||
sleep 2
|
||
done
|
||
|
||
# 执行初始化副本集的脚本
|
||
mongo -u myusername -p mypassword --authenticationDatabase admin /data/initReplicaSet.js
|
||
|
||
# 等待docker-entrypoint.sh脚本执行的MongoDB服务进程
|
||
wait $!
|
||
```
|
||
|
||
2. 重启 MongoDB
|
||
|
||
```bash
|
||
# 重启 Mongo
|
||
docker-compose down
|
||
docker-compose up -d
|
||
```
|
||
|
||
## Sealos 部署 - 无需更新 Mongo
|
||
|
||
## 修改配置文件
|
||
|
||
去除了重复的模型配置,LLM模型都合并到一个属性中:[点击查看最新的配置文件](/docs/development/configuration/)
|
||
|
||
## 商业版初始化
|
||
|
||
商业版用户需要执行一个初始化,格式化团队信息。
|
||
|
||
发起 1 个 HTTP 请求 ({{rootkey}} 替换成环境变量里的 `rootkey`,{{host}} 替换成商业版域名)
|
||
|
||
```bash
|
||
curl --location --request POST 'https://{{host}}/api/init/v468' \
|
||
--header 'rootkey: {{rootkey}}' \
|
||
--header 'Content-Type: application/json'
|
||
```
|
||
|
||
会初始化计费系统,内部使用可把免费的存储拉大。
|
||
|
||
## V4.6.8 更新说明
|
||
|
||
1. 新增 - 知识库搜索合并模块。
|
||
2. 新增 - 新的 Http 模块,支持更加灵活的参数传入。同时支持了输入输出自动数据类型转化,例如:接口输出的 JSON 类型会自动转成字符串类型,直接给其他模块使用。此外,还补充了一些例子,可在文档中查看。
|
||
3. 优化 - 内容补全。将内容补全内置到【知识库搜索】中,并实现了一次内容补全,即可完成“指代消除”和“问题扩展”。FastGPT知识库搜索详细流程可查看:[知识库搜索介绍](/docs/guide/dashboard/workflow/dataset_search/)
|
||
4. 优化 - LLM 模型配置,不再区分对话、分类、提取模型。同时支持模型的默认参数,避免不同模型参数冲突,可通过`defaultConfig`传入默认的配置。
|
||
5. 优化 - 流响应,参考了`ChatNextWeb`的流,更加丝滑。此外,之前提到的乱码、中断,刷新后又正常了,可能会修复)
|
||
6. 修复 - 语音输入文件无法上传。
|
||
7. 修复 - 对话框重新生成无法使用。
|
||
|
||
# V4.6.9(包含升级脚本)
|
||
## FastGPT V4.6.9更新说明
|
||
|
||
## 修改商业版环境变量
|
||
|
||
增加 oneapi 地址和令牌。
|
||
|
||
```
|
||
OPENAI_BASE_URL=http://oneapi:3000/v1
|
||
CHAT_API_KEY=sk-fastgpt
|
||
```
|
||
|
||
## 初始化脚本
|
||
|
||
从任意终端,发起 1 个 HTTP 请求。其中 {{rootkey}} 替换成环境变量里的 `rootkey`;{{host}} 替换成自己域名
|
||
|
||
```bash
|
||
curl --location --request POST 'https://{{host}}/api/admin/initv469' \
|
||
--header 'rootkey: {{rootkey}}' \
|
||
--header 'Content-Type: application/json'
|
||
```
|
||
|
||
1. 重置计量表。
|
||
2. 执行脏数据清理(清理无效的文件、清理无效的图片、清理无效的知识库集合、清理无效的向量)
|
||
|
||
## 外部接口更新
|
||
|
||
1. 由于计费系统变更,[分享链接对话上报接口](/docs/development/openapi/share/#5-编写对话结果上报接口可选)需要做一些调整,price字段被totalPoints字段取代。inputToken和outputToken不再提供,只提供`token`字段(总token数量)。
|
||
|
||
## V4.6.9 更新说明
|
||
|
||
1. 商业版新增 - 知识库新增“增强处理”训练模式,可生成更多类型索引。
|
||
2. 新增 - 完善了HTTP模块的变量提示。
|
||
3. 新增 - HTTP模块支持OpenAI单接口导入。
|
||
4. 新增 - 全局变量支持增加外部变量。可通过分享链接的Query或 API 的 variables 参数传入。
|
||
5. 新增 - 内容提取模块增加默认值。
|
||
6. 优化 - 问题补全。增加英文类型。同时可以设置为单独模块,方便复用。
|
||
7. 优化 - 重写了计量模式
|
||
8. 优化 - Token 过滤历史记录,保持偶数条,防止部分模型报错。
|
||
9. 优化 - 分享链接SEO,可直接展示应用名和头像。
|
||
10. 修复 - 标注功能。
|
||
11. 修复 - qa生成线程计数错误。
|
||
12. 修复 - 问题分类连线类型错误
|
||
|
||
# V4.7(需要初始化)
|
||
## FastGPT V4.7更新说明
|
||
|
||
## 1. 修改配置文件
|
||
|
||
增加一些 Boolean 值,用于决定不同功能块可以使用哪些模型,同时增加了模型的 logo:[点击查看最新的配置文件](/docs/development/configuration/)
|
||
|
||
## 2. 初始化脚本
|
||
|
||
升级完镜像后。从任意终端,发起 1 个 HTTP 请求。其中 {{rootkey}} 替换成环境变量里的 `rootkey`;{{host}} 替换成自己域名
|
||
|
||
```bash
|
||
curl --location --request POST 'https://{{host}}/api/admin/initv47' \
|
||
--header 'rootkey: {{rootkey}}' \
|
||
--header 'Content-Type: application/json'
|
||
```
|
||
|
||
脚本功能:
|
||
1. 初始化插件的 parentId
|
||
|
||
## 3. 升级 ReRank 模型
|
||
|
||
4.7对ReRank模型进行了格式变动,兼容 cohere 的格式,可以直接使用 cohere 提供的 API。如果是本地的 ReRank 模型,需要修改镜像为:`registry.cn-hangzhou.aliyuncs.com/fastgpt/bge-rerank-base:v0.1` 。
|
||
|
||
cohere的重排模型对中文不是很好,感觉不如 bge 的好用,接入教程如下:
|
||
|
||
1. 申请 Cohere 官方 Key: https://dashboard.cohere.com/api-keys
|
||
2. 修改 FastGPT 配置文件
|
||
|
||
```json
|
||
{
|
||
"reRankModels": [
|
||
{
|
||
"model": "rerank-multilingual-v2.0", // 这里的 model 需要对应 cohere 的模型名
|
||
"name": "检索重排", // 随意
|
||
"requestUrl": "https://api.cohere.ai/v1/rerank",
|
||
"requestAuth": "Coherer上申请的key"
|
||
}
|
||
]
|
||
}
|
||
```
|
||
|
||
|
||
## V4.7 更新说明
|
||
|
||
1. 新增 - 工具调用模块,可以让LLM模型根据用户意图,动态的选择其他模型或插件执行。
|
||
2. 新增 - 分类和内容提取支持 functionCall 模式。部分模型支持 functionCall 不支持 ToolCall,也可以使用了。需要把 LLM 模型配置文件里的 `functionCall` 设置为 `true`, `toolChoice`设置为 `false`。如果 `toolChoice` 为 true,会走 tool 模式。
|
||
3. 新增 - HTTP插件,可实现OpenAPI快速生成插件。
|
||
4. 新增 - Rerank 模型兼容 [cohere的格式](https://docs.cohere.com/reference/rerank-1),可以直接使用 cohere 的 rerank 模型。
|
||
5. 新增 - Helm 安装。
|
||
6. 优化 - 高级编排性能。
|
||
7. 优化 - 抽离 Flow controller 到 packages。
|
||
8. 优化 - AI模型选择。
|
||
9. 优化 - 手动输入知识库弹窗。
|
||
10. 优化 - 变量输入弹窗。
|
||
11. 优化 - docker 部署,自动初始化副本集。
|
||
12. 优化 - 浏览器读取文件自动推断编码,减少乱码情况。
|
||
13. 修复 - 开源版重排选不上。
|
||
14. 修复 - http 请求 body,不使用时,传入undefined。(会造成部分GET请求失败)
|
||
15. 新增 - 支持 http url 使用变量。
|
||
16. 修复 - 469 的提取的提示词容易造成幻觉。
|
||
17. 修复 - PG HNSW索引未实际生效问题,本次更新后,搜索速度大幅度提升(但是可能会出现精度损失,如果出现精度损失需要参考PgVector文档,对索引进行调整)。详细见:https://github.com/pgvector/pgvector?tab=readme-ov-file#troubleshooting
|
||
18. 修复Safari浏览器语音输入问题。
|
||
19. 修复 - 自定义分割规则可输入正则特殊字符(之前输入的话,会导致前端崩溃)
|
||
|
||
# V4.7.1(包含升级脚本)
|
||
## FastGPT V4.7.1 更新说明
|
||
|
||
## 初始化脚本
|
||
|
||
从任意终端,发起 1 个 HTTP 请求。其中 {{rootkey}} 替换成环境变量里的 `rootkey`;{{host}} 替换成FastGPT的域名。
|
||
|
||
```bash
|
||
curl --location --request POST 'https://{{host}}/api/admin/clearInvalidData' \
|
||
--header 'rootkey: {{rootkey}}' \
|
||
--header 'Content-Type: application/json'
|
||
```
|
||
|
||
该请求会执行脏数据清理(清理无效的文件、清理无效的图片、清理无效的知识库集合、清理无效的向量)
|
||
|
||
|
||
## 修改配置文件
|
||
|
||
增加了Laf环境配置:[点击查看最新的配置文件](/docs/development/configuration/)
|
||
|
||
|
||
## V4.7.1 更新说明
|
||
|
||
1. 新增 - 语音输入完整配置。支持选择是否打开语音输入(包括分享页面),支持语音输入后自动发送,支持语音输入后自动语音播放(流式)。
|
||
2. 新增 - pptx 和 xlsx 文件读取。但所有文件读取都放服务端,会消耗更多的服务器资源,以及无法在上传时预览更多内容。
|
||
3. 新增 - 集成 Laf 云函数,可以读取 Laf 账号中的云函数作为 HTTP 模块。
|
||
4. 新增 - 定时器,清理垃圾数据。(采用小范围清理,会清理最近n个小时的,所以请保证服务持续运行,长时间不允许,可以继续执行 clearInvalidData 的接口进行全量清理。)
|
||
5. 商业版新增 - 后台配置系统通知。
|
||
6. 优化 - 支持ip模式导出知识库。
|
||
7. 修改 - csv导入模板,取消 header 校验,自动获取前两列。
|
||
8. 修复 - 工具调用模块连线数据类型校验错误。
|
||
9. 修复 - 自定义索引输入时,解构数据失败。
|
||
10. 修复 - rerank 模型数据格式。
|
||
11. 修复 - 问题补全历史记录BUG
|
||
12. 修复 - 分享页面特殊情况下加载缓慢问题(由于ssr时候数据库不会触发连接)
|
||
|
||
# V4.8
|
||
## FastGPT V4.8 更新说明
|
||
|
||
## 新工作流
|
||
|
||
FastGPT workflow V2上线,支持更加简洁的工作流模式。
|
||
|
||
|
||
{{% alert icon="🤖 " context="success" %}}
|
||
**由于工作流差异较大,不少地方需要手动重新构建。请依次重建插件和应用**
|
||
|
||
简易尽快更新工作流,避免未来持续迭代后导致无法兼容。
|
||
{{% /alert %}}
|
||
|
||
|
||
给应用和插件增加了 version 的字段,用于标识是旧工作流还是新工作流。当你更新 4.8 后,保存和新建的工作流均为新版,旧版工作流会有一个重置的弹窗提示。并且,如果是通过 API 和 分享链接 调用的工作流,仍可以正常使用,直到你下次保存它们。
|
||
|
||
## 商业版配置更新
|
||
|
||
商业版用户如果配置了邮件验证码,需要在管理端 -> 项目配置 -> 登录配置 -> 邮箱登录配置 -> 修改 **邮箱服务SMTP地址**,之前只能配置别名,现在可以配置自定义的地址。下面是一组别名和实际地址关系:
|
||
|
||
qq: smtp.qq.com
|
||
gmail: smtp.gmail.com
|
||
|
||
## V4.8 更新说明
|
||
|
||
1. 重构 - 工作流
|
||
2. 新增 - 判断器。支持 if elseIf else 判断。 @newfish-cmyk (preview版本的if else节点需要删除重建)
|
||
3. 新增 - 变量更新节点。支持更新运行中工作流输出变量,或更新全局变量。@newfish-cmyk
|
||
4. 新增 - 工作流自动保存和版本管理。
|
||
5. 新增 - 工作流 Debug 模式,可以调试单个节点或者逐步调试工作流。
|
||
6. 新增 - 定时执行应用。可轻松实现定时任务。
|
||
7. 新增 - 插件自定义输入优化,可以渲染输入组件。
|
||
8. 新增 - 分享链接发送对话前 hook https://github.com/labring/FastGPT/pull/1252 @gaord
|
||
9. 优化 - 工作流连线,可以四向连接,方便构建循环工作流。
|
||
10. 优化 - 工作流上下文传递,性能🚀。
|
||
11. 优化 - ctrl和alt+enter换行,换行符位置不正确。
|
||
12. 优化 - chat中存储变量配置。避免修改变量后,影响旧的对话。
|
||
13. 优化 - 简易模式,更新配置后自动更新调试框内容,无需保存。
|
||
14. 优化 - worker进程管理,并将计算 Token 任务分配给 worker 进程。
|
||
15. 优化 - 工具调用支持指定字段数据类型(string, boolean, number) https://github.com/labring/FastGPT/issues/1236
|
||
16. 优化 - completions接口size限制 https://github.com/labring/FastGPT/issues/1241
|
||
17. 优化 - Node api 中间件。优化 api 端代码。@c121914yu
|
||
18. 优化 - 对话记录保持为偶数进行截取,避免部分模型不支持奇数的历史记录,最大长度增加到50轮。 https://github.com/labring/FastGPT/issues/1384
|
||
19. 优化 - HTTP节点错误后终止进程 https://github.com/labring/FastGPT/issues/1290
|
||
20. 修复 - 工具调用时候,name不能是数字开头(随机数有概率数字开头)@c121914yu
|
||
21. 修复 - 分享链接, query 全局变量会被缓存。 @c121914yu
|
||
22. 修复 - 工具调用字段兼容。 https://github.com/labring/FastGPT/issues/1253
|
||
23. 修复 - HTTP 模块url光标问题 https://github.com/labring/FastGPT/issues/1334 @maquannene
|
||
|
||
# V4.8.1(包含升级脚本)
|
||
## FastGPT V4.8.1 更新说明
|
||
|
||
## 初始化脚本
|
||
|
||
从任意终端,发起 1 个 HTTP 请求。其中 {{rootkey}} 替换成环境变量里的 `rootkey`;{{host}} 替换成FastGPT的域名。
|
||
|
||
```bash
|
||
curl --location --request POST 'https://{{host}}/api/admin/initv481' \
|
||
--header 'rootkey: {{rootkey}}' \
|
||
--header 'Content-Type: application/json'
|
||
```
|
||
|
||
由于之前集合名不规范,该初始化会重置表名。请在初始化前,确保 dataset.trainings 表没有数据。
|
||
最好更新该版本时,暂停所有进行中业务,再进行初始化,避免数据冲突。
|
||
|
||
## 执行脏数据清理
|
||
|
||
从任意终端,发起 1 个 HTTP 请求。其中 {{rootkey}} 替换成环境变量里的 `rootkey`;{{host}} 替换成FastGPT的域名。
|
||
|
||
```bash
|
||
curl --location --request POST 'https://{{host}}/api/admin/clearInvalidData' \
|
||
--header 'rootkey: {{rootkey}}' \
|
||
--header 'Content-Type: application/json'
|
||
```
|
||
|
||
初始化完后,可以执行这个命令。之前定时清理的定时器有些问题,部分数据没被清理,可以手动执行清理。
|
||
|
||
## V4.8.1 更新说明
|
||
|
||
使用 Chat api 接口需要注意,增加了 event: updateVariables 事件,用于更新变量。
|
||
|
||
[点击查看升级说明](https://github.com/labring/FastGPT/releases/tag/v4.8.1)
|
||
|
||
# V4.8.10(包含升级脚本)
|
||
## FastGPT V4.8.10 更新说明
|
||
|
||
## 更新指南
|
||
|
||
### 1. 做好数据备份
|
||
|
||
|
||
### 2. 商业版 —— 修改环境变量
|
||
|
||
1. 需要给`fastgpt-pro`镜像,增加沙盒的环境变量:`SANDBOX_URL=http://xxxxx:3000`
|
||
2. 给`fastgpt-pro`镜像和`fastgpt`镜像增加环境变量,以便更好的存储系统日志:
|
||
|
||
```
|
||
LOG_LEVEL=debug
|
||
STORE_LOG_LEVEL=warn
|
||
```
|
||
|
||
### 3. 修改镜像tag
|
||
|
||
- 更新 FastGPT 镜像 tag: v4.8.10
|
||
- 更新 FastGPT 商业版镜像 tag: v4.8.10
|
||
- Sandbox 镜像,可以不更新
|
||
|
||
## 4. 执行初始化
|
||
|
||
从任意终端,发起 1 个 HTTP 请求。其中 {{rootkey}} 替换成环境变量里的 `rootkey`;{{host}} 替换成**FastGPT 域名**。
|
||
|
||
```bash
|
||
curl --location --request POST 'https://{{host}}/api/admin/initv4810' \
|
||
--header 'rootkey: {{rootkey}}' \
|
||
--header 'Content-Type: application/json'
|
||
```
|
||
|
||
1. 初始化发布记录版本标记
|
||
2. 初始化开票记录
|
||
|
||
-------
|
||
|
||
## V4.8.10 更新说明
|
||
|
||
完整内容请见:[4.8.10 release](https://github.com/labring/FastGPT/releases/tag/v4.8.10)
|
||
|
||
1. 新增 - 模板市场。
|
||
2. 新增 - 工作流节点拖动自动对齐吸附。
|
||
3. 新增 - 用户选择节点(Debug 模式暂未支持)。
|
||
4. 新增 - 工作流增加 uid 全局变量。
|
||
5. 新增 - 工作流撤销和重做。
|
||
6. 新增 - 工作流本次编辑记录,取代自动保存。
|
||
7. 新增 - 工作流版本支持重命名。
|
||
8. 新增 - 工作流的“应用调用”节点弃用,迁移成单独节点,与插件使用方式相同,同时可以传递全局变量和用户上传的文件。
|
||
9. 新增 - 插件增加使用说明配置。
|
||
10. 新增 - 插件自定义输入支持单选框。
|
||
11. 新增 - HTTP 节点支持 text/plain 模式。
|
||
12. 新增 - HTTP模块支持超时配置、支持更多的 Body 类型,params 和 headers 支持新的变量选择模式。
|
||
13. 新增 - 工作流导出导入,支持直接导出和导入 JSON 文件,便于交流。
|
||
14. 新增 - 发送验证码安全校验。
|
||
15. 商业版新增 - 飞书机器人接入。
|
||
16. 商业版新增 - 公众号接入接入。
|
||
17. 商业版新增 - 自助开票申请。
|
||
18. 商业版新增 - SSO 定制。
|
||
19. 优化 - 工作流循环校验,避免 skip 循环空转。同时支持分支完全并发执行。
|
||
20. 优化 - 工作流嵌套执行,参数可能存在的污染问题。
|
||
21. 优化 - 部分全局变量,增加数据类型约束。
|
||
22. 优化 - 节点选择,避免切换 tab 时候,path 加载报错。
|
||
23. 优化 - 最新 React Markdown 组件,支持 Base64 图片。
|
||
24. 优化 - 对话框性能问题。
|
||
25. 优化 - 单选框打开后自动滚动到选中的位置。
|
||
26. 优化 - 知识库集合禁用,目录禁用会递归修改其下所有 children 的禁用状态。
|
||
27. 优化 - SSE 响应代码优化。
|
||
28. 优化 - 无 SSL 证书情况下,优化复制。
|
||
29. 优化 - 知识库列表 UI。
|
||
30. 优化 - 知识库详情页 UI。
|
||
31. 优化 - 支持无网络配置情况下运行。
|
||
32. 优化 - 调整.env.template关于mongodb的说明,使得更易于理解。
|
||
33. 优化 - 新的支付模式。
|
||
34. 优化 - 用户默认头像。
|
||
35. 修复 - Prompt 模式调用工具,stream=false 模式下,会携带 0: 开头标记。
|
||
36. 修复 - 对话日志鉴权问题:仅为 APP 管理员的用户,无法查看对话日志详情。
|
||
37. 修复 - 选择 Milvus 部署时,无法导出知识库。
|
||
38. 修复 - 创建 APP 副本,无法复制系统配置。
|
||
39. 修复 - 图片识别模式下,自动解析图片链接正则不够严谨问题。
|
||
40. 修复 - 内容提取的数据类型与输出数据类型未一致。
|
||
41. 修复 - 工作流运行时间统计错误。
|
||
42. 修复 - stream 模式下,工具调用有可能出现 undefined。
|
||
43. 修复 - reranker typo。
|
||
44. 修复 - home host typo。
|
||
45. 修复 - i18n display。
|
||
46. 修复 - 全局变量可重复定义 key。
|
||
47. 修复 - 全局变量在 Debug 模式下不可持久化。
|
||
48. 修复 - 全局变量在 API 中无法持久化。
|
||
49. 修复 - OpenAPI,detail=false模式下,不应该返回 tool 调用结果,仅返回文字。(可解决 cow 不适配问题)。
|
||
50. 修复 - 知识库标签重复加载。
|
||
51. 修复 - 网络链接重新获取时,自定义分割符不生效。
|
||
52. 修复 - 插件运行时,会传递额外的全局变量,可能造成插件内变量污染。
|
||
53. 文档 - qa docs。
|
||
54. 文档 - Update feishu.md。
|
||
55. 文档 - update baseURL。
|
||
|
||
# V4.8.11(商业版初始化)
|
||
## FastGPT V4.8.11 更新说明
|
||
|
||
## 更新指南
|
||
|
||
### 1. 做好数据备份
|
||
|
||
### 2. 修改配置文件
|
||
|
||
如需增加 openai o1 模型,可添加如下配置:
|
||
|
||
```json
|
||
{
|
||
"model": "o1-mini",
|
||
"name": "o1-mini",
|
||
"avatar": "/imgs/model/openai.svg",
|
||
"maxContext": 125000,
|
||
"maxResponse": 65000,
|
||
"quoteMaxToken": 120000,
|
||
"maxTemperature": 1.2,
|
||
"charsPointsPrice": 0,
|
||
"censor": false,
|
||
"vision": false,
|
||
"datasetProcess": true,
|
||
"usedInClassify": true,
|
||
"usedInExtractFields": true,
|
||
"usedInToolCall": true,
|
||
"toolChoice": false,
|
||
"functionCall": false,
|
||
"customCQPrompt": "",
|
||
"customExtractPrompt": "",
|
||
"defaultSystemChatPrompt": "",
|
||
"defaultConfig": {
|
||
"temperature": 1
|
||
}
|
||
},
|
||
{
|
||
"model": "o1-preview",
|
||
"name": "o1-preview",
|
||
"avatar": "/imgs/model/openai.svg",
|
||
"maxContext": 125000,
|
||
"maxResponse": 32000,
|
||
"quoteMaxToken": 120000,
|
||
"maxTemperature": 1.2,
|
||
"charsPointsPrice": 0,
|
||
"censor": false,
|
||
"vision": false,
|
||
"datasetProcess": true,
|
||
"usedInClassify": true,
|
||
"usedInExtractFields": true,
|
||
"usedInToolCall": true,
|
||
"toolChoice": false,
|
||
"functionCall": false,
|
||
"customCQPrompt": "",
|
||
"customExtractPrompt": "",
|
||
"defaultSystemChatPrompt": "",
|
||
"defaultConfig": {
|
||
"temperature": 1
|
||
}
|
||
}
|
||
```
|
||
|
||
-------
|
||
|
||
### 3. 修改镜像 tag 并重启
|
||
|
||
- 更新 FastGPT 镜像 tag: v4.8.11-fix
|
||
- 更新 FastGPT 商业版镜像 tag: v4.8.11
|
||
- 更新 FastGPT Sandbox 镜像 tag: v4.8.11
|
||
|
||
### 4. 商业版初始化
|
||
|
||
从任意终端,发起 1 个 HTTP 请求。其中 {{rootkey}} 替换成环境变量里的 `rootkey`;{{host}} 替换成**FastGPT 商业版域名**。
|
||
|
||
```bash
|
||
curl --location --request POST 'https://{{host}}/api/admin/init/4811' \
|
||
--header 'rootkey: {{rootkey}}' \
|
||
--header 'Content-Type: application/json'
|
||
```
|
||
|
||
会初始化团队成员组。
|
||
|
||
## V4.8.11 更新说明
|
||
|
||
1. 新增 - 表单输入节点,允许用户在工作流中让用户输入一些信息。
|
||
2. 新增 - 循环运行节点,可传入数组进行批量调用,目前最多支持 50 长度的数组串行执行。
|
||
3. 新增 - 节点支持折叠。
|
||
4. 新增 - 简易模式支持新的历史记录模式,可记录本地变更记录。
|
||
5. 新增 - 聊天记录滚动加载,不再只加载 30 条。
|
||
6. 新增 - 工作流增加触摸板优先模式,可以通过工作流右下角按键进行切换。
|
||
7. 新增 - 沙盒增加字符串转 base64 全局方法(全局变量 strToBase64)。
|
||
8. 新增 - 支持 Openai o1 模型,需增加模型的 `defaultConfig` 配置,覆盖 `temperature`、`max_tokens` 和 `stream`配置,o1 不支持 stream 模式。
|
||
9. 新增 - AI 对话节点知识库引用,支持配置 role=system 和 role=user,已配置的过自定义提示词的节点将会保持 user 模式,其余用户将转成 system 模式。
|
||
10. 新增 - 插件支持上传系统文件。
|
||
11. 新增 - 插件输出,支持指定字段作为工具响应。
|
||
12. 新增 - 支持工作流嵌套子应用时,可以设置`非流模式`,同时简易模式也可以选择工作流作为插件了,简易模式调用子应用时,都将强制使用非流模式。
|
||
13. 新增 - 调试模式下,子应用调用,支持返回详细运行数据。
|
||
14. 新增 - 保留所有模式下子应用嵌套调用的日志。
|
||
15. 新增 - 对话日志显示成员。
|
||
16. 新增 - 商业版支持后台配置 AI 生成文案提示。
|
||
17. 新增 - Jest 单测框架。
|
||
18. 新增 - 工具调用参数节点,可以配合工具调用完全自由声明参数。
|
||
19. 新增 - BI 图表插件。
|
||
20. 新增 - Surya OCR 识别模块示例。
|
||
21. 新增 - 工作流右键新增注释。
|
||
22. 商业版新增 - 团队成员组。
|
||
23. 优化 - 工作流嵌套层级限制 20 层,避免因编排不合理导致的无限死循环。
|
||
24. 优化 - 工作流 handler 性能优化。
|
||
25. 优化 - 工作流快捷键,避免调试测试时也会触发复制和回退。
|
||
26. 优化 - 工作流复制时,名字去掉多余“#”。
|
||
27. 优化 - 流输出,切换浏览器 Tab 后仍可以继续输出。
|
||
28. 优化 - 完善外部文件知识库相关 API 。
|
||
29. 优化 - 修改 config.json 的地址。
|
||
30. 优化 - 正确处理//开头的超链接。
|
||
31. 优化 - 工作流 Textarea 滚轮可以正常滚动而不是缩放。
|
||
32. 优化 - 去除部分输入框前后空格。
|
||
33. 优化 - 工作流返回时,跳转到上一次记忆的 Tab 。
|
||
34. 优化 - 工作流画布禁止触摸板缩放浏览器。
|
||
35. 优化 - 工作流部分节点会自动选择用户问题作为初始值。
|
||
36. 优化 - Prompt Editor 支持动态增高。
|
||
37. 优化 - 自动补全工具描述。
|
||
38. 优化 - 文档说明 configuration.md 。
|
||
39. 优化 - IOS safari 浏览器语音输入不准确。
|
||
40. 修复 - 知识库选择权限问题。
|
||
41. 修复 - 空 chatId 发起对话,首轮携带用户选择时会异常。
|
||
42. 修复 - createDataset 接口,intro 未赋值。
|
||
43. 修复 - 对话框渲染性能问题。
|
||
44. 修复 - Rerank 文档地址。
|
||
45. 修复 - Stream 模式下使用 toolChoice,toolCall 的function 和type 可能为 null 。
|
||
46. 修复 - 站点同步自定义分割符未同步。
|
||
47. 修复 - 工具调用历史记录存储问题。
|
||
48. 修复 - 对话页面可能无限重定向。
|
||
49. 修复 - 全局变量在工具调用中未持久传递。
|
||
|
||
# V4.8.12(包含升级脚本)
|
||
## FastGPT V4.8.12 更新说明
|
||
|
||
## 更新指南
|
||
|
||
### 1. 做好数据备份
|
||
|
||
### 2. 修改镜像
|
||
|
||
- 更新 FastGPT 镜像 tag: v4.8.12-fix
|
||
- 更新 FastGPT 管理端镜像 tag: v4.8.12 (fastgpt-pro镜像)
|
||
- Sandbox 镜像,可以不更新
|
||
|
||
|
||
### 3. 商业版执行初始化
|
||
|
||
从任意终端,发起 1 个 HTTP 请求。其中 {{rootkey}} 替换成环境变量里的 `rootkey`;{{host}} 替换成**FastGPT 管理端域名**。
|
||
|
||
```bash
|
||
curl --location --request POST 'https://{{host}}/api/admin/init/4812' \
|
||
--header 'rootkey: {{rootkey}}' \
|
||
--header 'Content-Type: application/json'
|
||
```
|
||
|
||
会初始化应用和知识库的成员组数据。
|
||
|
||
### 4. 重构 Milvus 数据
|
||
|
||
由于 js int64 精度丢失问题,之前私有化使用 milvus 或者 zilliz 的用户,如果存在数据精度丢失的问题,需要重构 Milvus 数据。(可以查看 dataset_datas 表中,indexes 中的 dataId 是否末尾精度丢失)。使用 PG 的用户不需要操作。
|
||
|
||
从任意终端,发起 1 个 HTTP 请求。其中 {{rootkey}} 替换成环境变量里的 `rootkey`;{{host}} 替换成**FastGPT 主域名**。
|
||
|
||
```bash
|
||
curl --location --request POST 'https://{{host}}/api/admin/resetMilvus' \
|
||
--header 'rootkey: {{rootkey}}' \
|
||
--header 'Content-Type: application/json'
|
||
```
|
||
|
||
## 更新说明
|
||
|
||
1. 新增 - 全局变量支持数字类型,支持配置默认值和部分输入框参数。
|
||
2. 新增 - 插件自定义输入,文本输入框、数字输入框、选择框、开关,默认都支持作为变量引用。
|
||
3. 新增 - FE_DOMAIN 环境变量,配置该环境变量后,上传文件/图片会补全后缀后得到完整地址。(可解决 docx 文件图片链接,有时模型会伪造图片域名)
|
||
4. 新增 - 工具调用支持使用交互节点
|
||
5. 新增 - Debug 模式支持输入全局变量
|
||
6. 新增 - chat OpenAPI 文档
|
||
7. 新增 - wiki 搜索插件
|
||
8. 新增 - Google 搜索插件
|
||
9. 新增 - 数据库连接和操作插件
|
||
10. 新增 - Cookie 隐私协议提示
|
||
11. 新增 - HTTP 节点支持 JSONPath 表达式
|
||
12. 新增 - 应用和知识库支持成员组配置权限
|
||
13. 优化 - 循环节点支持选择外部节点的变量
|
||
14. 优化 - Docx 文件读取中, HTML to Markdown 优化,提高速度和大幅度降低内存消耗。
|
||
15. 修复 - 文件后缀判断,去除 query 影响。
|
||
16. 修复 - AI 响应为空时,会造成 LLM 历史记录合并。
|
||
17. 修复 - 用户交互节点未阻塞流程。
|
||
18. 修复 - 新建 APP,有时候会导致空指针报错。
|
||
19. 修复 - 拥有多个循环节点时,错误运行。
|
||
20. 修复 - 循环节点中修改变量,无法传递。
|
||
21. 修复 - 非 stream 模式,嵌套子应用/插件执行时无法获取子应用响应。
|
||
22. 修复 - 数据分块策略,同时将每个 Markdown 独立分块。
|
||
|
||
# V4.8.13
|
||
## FastGPT V4.8.13 更新说明
|
||
|
||
## 更新指南
|
||
|
||
### 1. 做好数据备份
|
||
|
||
### 2. 修改镜像
|
||
|
||
- 更新 FastGPT 镜像 tag: v4.8.13-fix
|
||
- 更新 FastGPT 商业版镜像 tag: v4.8.13-fix (fastgpt-pro镜像)
|
||
- Sandbox 镜像,可以不更新
|
||
|
||
### 3. 添加环境变量
|
||
|
||
- 给 fastgpt 和 fastgpt-pro 镜像添加环境变量:`FE_DOMAIN=http://xx.com`,值为 fastgpt 前端访问地址,注意后面不要加`/`。可以自动补齐相对文件地址的前缀。
|
||
|
||
### 4. 调整文件上传编排
|
||
|
||
虽然依然兼容旧版的文件上传编排,但是未来两个版本内将会去除兼容代码,请尽快调整编排,以适应最新的文件上传逻辑。尤其是嵌套应用的文件传递,未来将不会自动传递,必须手动指定传递的文件。具体内容可参考: [文件上传变更](/docs/guide/course/fileinput/#4813%E7%89%88%E6%9C%AC%E8%B5%B7%E5%85%B3%E4%BA%8E%E6%96%87%E4%BB%B6%E4%B8%8A%E4%BC%A0%E7%9A%84%E6%9B%B4%E6%96%B0)
|
||
|
||
## 更新说明
|
||
|
||
1. 新增 - 数组变量选择支持多选,可以选多个数组或对应的单一数据类型,会自动按选择顺序进行合并。
|
||
2. 新增 - 文件上传方案调整,AI对话和工具调用节点直接支持接收文件链接,并且会强制加入提示词,无需由模型决策调用。插件自定义变量支持文件上传类型,取代全局文件。
|
||
3. 新增 - 对话记录增加时间显示。
|
||
4. 新增 - 工作流校验错误时,跳转至错误节点。
|
||
5. 新增 - 循环节点增加下标值。
|
||
6. 新增 - 部分对话错误提醒增加翻译。
|
||
7. 新增 - 对话输入框支持拖拽文件上传,可直接拖文件到输入框中。
|
||
8. 新增 - 对话日志,来源可显示分享链接/API具体名称
|
||
9. 新增 - 分享链接支持配置是否展示实时运行状态。
|
||
10. 优化 - 合并多个 system 提示词成 1 个,避免部分模型不支持多个 system 提示词。
|
||
11. 优化 - 知识库上传文件,优化报错提示。
|
||
12. 优化 - 全文检索语句,减少一轮子查询。
|
||
13. 优化 - 修改 findLast 为 [...array].reverse().find,适配旧版浏览器。
|
||
14. 优化 - Markdown 组件自动空格,避免分割 url 中的中文。
|
||
15. 优化 - 工作流上下文拆分,性能优化。
|
||
16. 优化 - 语音播报,不支持 mediaSource 的浏览器可等待完全生成语音后输出。
|
||
17. 优化 - 对话引导 csv 读取,自动识别编码
|
||
18. 优化 - csv 导入问题引导可能乱码
|
||
19. 修复 - Dockerfile pnpm install 支持代理。。
|
||
20. 修复 - Dockerfile pnpm install 支持代理。
|
||
21. 修复 - BI 图表生成无法写入文件。同时优化其解析,支持数字类型数组。
|
||
22. 修复 - 分享链接首次加载时,标题显示不正确。
|
||
|
||
# V4.8.14
|
||
## FastGPT V4.8.14 更新说明
|
||
|
||
## 更新指南
|
||
|
||
### 1. 做好数据备份
|
||
|
||
### 2. 修改镜像
|
||
|
||
- 更新 FastGPT 镜像 tag: v4.8.14-fix
|
||
- 更新 FastGPT 商业版镜像 tag: v4.8.14 (fastgpt-pro镜像)
|
||
- Sandbox 镜像,可以不更新
|
||
|
||
milvus版本使用:v4.8.14-milvus-fix 镜像。
|
||
|
||
## 新功能预览
|
||
|
||
### 自动触发工作流
|
||
|
||
可以允许你配置用户加载对话时,自动触发一次工作流。可以用于一些 CRM 系统,可以快速的引导用户使用,无需等待用户主动触发。
|
||
|
||
| | |
|
||
| --- | --- |
|
||
|  |  |
|
||
|
||
|
||
## 完整更新内容
|
||
|
||
1. 新增 - 工作流支持进入聊天框/点击开始对话后,自动触发一轮对话。
|
||
2. 新增 - 重写 chatContext,对话测试也会有日志,并且刷新后不会丢失对话。
|
||
3. 新增 - 分享链接支持配置是否允许查看原文。
|
||
4. 新增 - 新的 doc2x 插件。
|
||
5. 新增 - 繁体中文。
|
||
6. 新增 - 分析链接和 chat api 支持传入自定义 uid。
|
||
7. 商业版新增 - 微软 oauth 登录
|
||
8. 优化 - 工作流 ui 细节。
|
||
9. 优化 - 应用编辑记录采用 diff 存储,避免浏览器溢出。
|
||
10. 优化 - 代码入口,增加 register 入口,无需等待首次访问才执行。
|
||
11. 优化 - 工作流检查,增加更多缺失值检查。
|
||
12. 优化 - 增加知识库训练最大重试次数限制。
|
||
13. 优化 - 图片路径问题和示意图任务
|
||
14. 优化 - Milvus description
|
||
15. 修复 - 分块策略,四级标题会被丢失。 同时新增了五级标题的支持。
|
||
16. 修复 - MongoDB 知识库集合唯一索引。
|
||
17. 修复 - 反选知识库引用后可能会报错。
|
||
18. 修复 - 简易模式转工作流,不是使用最新编辑记录进行转移。
|
||
19. 修复 - 表单输入的说明文字不显示。
|
||
20. 修复 - API 无法使用 base64 图片。
|
||
|
||
# V4.8.15(包含升级脚本)
|
||
## FastGPT V4.8.15 更新说明
|
||
|
||
## 新功能预览
|
||
|
||
### API 知识库
|
||
|
||
| | |
|
||
| --- | --- |
|
||
|  |  |
|
||
|
||
### HTML 渲染
|
||
|
||
| 源码模式 | 预览模式 | 全屏模式 |
|
||
| --- | --- | --- |
|
||
|  |  |  |
|
||
|
||
## 升级指南
|
||
|
||
- 更新 fastgpt 镜像 tag: v4.8.15-fix3
|
||
- 更新 fastgpt-pro 商业版镜像 tag: v4.8.15
|
||
- Sandbox 镜像,可以不更新
|
||
|
||
|
||
## 运行升级脚本
|
||
|
||
从任意终端,发起 1 个 HTTP 请求。其中 {{rootkey}} 替换成环境变量里的 `rootkey`;{{host}} 替换成**FastGPT 域名**。
|
||
|
||
```bash
|
||
curl --location --request POST 'https://{{host}}/api/admin/initv4815' \
|
||
--header 'rootkey: {{rootkey}}' \
|
||
--header 'Content-Type: application/json'
|
||
```
|
||
|
||
会重置应用定时执行的字段,把 null 去掉,减少索引大小。
|
||
|
||
----
|
||
|
||
从任意终端,发起 1 个 HTTP 请求。其中 {{rootkey}} 替换成环境变量里的 `rootkey`;{{host}} 替换成**fastgpt-pro域名**。
|
||
|
||
```bash
|
||
curl --location --request POST 'https://{{host}}/api/admin/init/refreshFreeUser' \
|
||
--header 'rootkey: {{rootkey}}' \
|
||
--header 'Content-Type: application/json'
|
||
```
|
||
|
||
重新计算一次免费版用户的时长,之前有版本升级时没有重新计算时间,导致会误发通知。
|
||
|
||
|
||
## 完整更新内容
|
||
|
||
1. 新增 - API 知识库, 见 [API 知识库介绍](/docs/guide/knowledge_base/api_dataset/),外部文件库会被弃用。
|
||
2. 新增 - 工具箱页面,展示所有可用的系统资源。商业版后台可更便捷的配置系统插件和自定义分类。
|
||
3. 新增 - Markdown 中,HTML代码会被额外渲染,可以选择预览模式,会限制所有 script 脚本,仅做展示。
|
||
4. 新增 - 自定义系统级文件解析服务, 见 [接入 Marker PDF 文档解析](/docs/development/custom-models/marker/)
|
||
5. 新增 - 集合直接重新调整参数,无需删除再导入。
|
||
6. 新增 - 商业版后台支持配置侧边栏跳转链接。
|
||
7. 优化 - base64 图片截取判断。
|
||
8. 优化 - i18n cookie 判断。
|
||
9. 优化 - 支持 Markdown 文本分割时,只有标题,无内容。
|
||
10. 优化 - 字符串变量替换,未赋值的变量会转成 undefined,而不是保留原来 id 串。
|
||
11. 优化 - 全局变量默认值在 API 生效,并且自定义变量支持默认值。
|
||
12. 优化 - 增加 HTTP Body 的 JSON 解析,正则将 undefined 转 null,减少 Body 解析错误。
|
||
13. 优化 - 定时执行增加运行日志,增加重试,减少报错概率。
|
||
14. 修复 - 分享链接点赞鉴权问题。
|
||
15. 修复 - 对话页面切换自动执行应用时,会误触发非自动执行应用。
|
||
16. 修复 - 语言播放鉴权问题。
|
||
17. 修复 - 插件应用知识库引用上限始终为 3000
|
||
18. 修复 - 工作流编辑记录存储上限,去掉本地存储,增加异常离开时,强制自动保存。
|
||
19. 修复 - 工作流特殊变量替换问题。($开头的字符串无法替换)
|
||
|
||
# V4.8.16(更新配置文件)
|
||
## FastGPT V4.8.16 更新说明
|
||
|
||
## 更新指南
|
||
|
||
### 1. 更新镜像:
|
||
|
||
- 更新 fastgpt 镜像 tag: v4.8.16
|
||
- 更新 fastgpt-pro 商业版镜像 tag: v4.8.16
|
||
- Sandbox 镜像 tag: v4.8.16
|
||
|
||
### 2. 更新配置文件
|
||
|
||
参考最新的[配置文件](/docs/development/configuration/),更新 `config.json` 或 admin 中模型文件配置。给 LLMModel 和 VectorModel 增加 `provider` 字段,以便进行模型分类。例如:
|
||
|
||
```json
|
||
{
|
||
"provider": "OpenAI", // 这是新增的
|
||
"model": "gpt-4o",
|
||
"name": "gpt-4o",
|
||
"maxContext": 125000,
|
||
"maxResponse": 4000,
|
||
"quoteMaxToken": 120000,
|
||
"maxTemperature": 1.2,
|
||
"charsPointsPrice": 0,
|
||
"censor": false,
|
||
"vision": true,
|
||
"datasetProcess": true,
|
||
"usedInClassify": true,
|
||
"usedInExtractFields": true,
|
||
"usedInToolCall": true,
|
||
"usedInQueryExtension": true,
|
||
"toolChoice": true,
|
||
"functionCall": false,
|
||
"customCQPrompt": "",
|
||
"customExtractPrompt": "",
|
||
"defaultSystemChatPrompt": "",
|
||
"defaultConfig": {},
|
||
"fieldMap": {}
|
||
}
|
||
```
|
||
|
||
|
||
|
||
## 完整更新内容
|
||
|
||
1. 新增 - SearXNG 搜索插件[点击查看教程](/docs/guide/plugins/searxng_plugin_guide/)
|
||
2. 新增 - 商业版支持 API 知识库和链接集合定时同步。
|
||
3. 新增 - 猜你想问支持选择模型和自定义提示词。
|
||
4. 新增 - 钉钉和企微机器人 webhook 插件。
|
||
5. 新增 - 商业版支持钉钉 SSO 登录配置。[点击查看教程](/docs/guide/admin/sso_dingtalk/)
|
||
6. 新增 - 商业版支持飞书和语雀知识库导入。[点击查看教程](/docs/guide/knowledge_base/lark_dataset/)
|
||
7. 新增 - sandbox 新增 createHmac 加密全局方法。
|
||
8. 新增 - 工作流右键支持全部折叠。
|
||
9. 优化 - 模型选择器。
|
||
10. 优化 - SSR 渲染,预判断是移动端还是 pc 端,减少页面抖动。
|
||
11. 优化 - 工作流/简易模式变量初始化代码,去除监听初始化,避免因渲染顺序不一致导致的失败。
|
||
12. 优化 - 工作流获取数据类型不一致数据时,增加类型转化,避免 undefined。
|
||
13. 修复 - 无法自动切换默认语言。增加分享链接,强制执行一次切换默认语言。
|
||
14. 修复 - 数组选择器自动兼容 4.8.13 以前的数据。
|
||
15. 修复 - 站点同步知识库,链接同步时未使用选择器。
|
||
16. 修复 - 简易模式转工作流,没有把系统配置项转化。
|
||
17. 修复 - 插件独立运行,变量初始值未赋上。
|
||
18. 修复 - 工作流使用弹窗组件时,关闭弹窗后,有时候会出现页面偏移。
|
||
19. 修复 - 插件调试时,日志未保存插件输入参数。
|
||
20. 修复 - 部分模板市场模板
|
||
21. 修复 - 设置NEXT_PUBLIC_BASE_URL时,图片文件读取URL不正确
|
||
|
||
# V4.8.17(包含升级脚本)
|
||
## FastGPT V4.8.17 更新说明
|
||
|
||
## 更新指南
|
||
|
||
### 1. 更新镜像:
|
||
|
||
- 更新 fastgpt 镜像 tag: v4.8.17-fix-title
|
||
- 更新 fastgpt-pro 商业版镜像 tag: v4.8.17
|
||
- Sandbox 镜像无需更新
|
||
|
||
|
||
### 2. 运行升级脚本
|
||
|
||
从任意终端,发起 1 个 HTTP 请求。其中 {{rootkey}} 替换成环境变量里的 `rootkey`;{{host}} 替换成**FastGPT 域名**。
|
||
|
||
```bash
|
||
curl --location --request POST 'https://{{host}}/api/admin/initv4817' \
|
||
--header 'rootkey: {{rootkey}}' \
|
||
--header 'Content-Type: application/json'
|
||
```
|
||
|
||
会将用户绑定的 OpenAI 账号移动到团队中。
|
||
|
||
|
||
## 调整 completions 接口返回值
|
||
|
||
/api/v1/chat/completions 接口返回值调整,对话节点、工具节点等使用到模型的节点,将不再返回 `tokens` 字段,改为返回 `inputTokens` 和 `outputTokens` 字段,分别表示输入和输出的 Token 数量。
|
||
|
||
## 完整更新内容
|
||
|
||
1. 新增 - 简易模式工具调用支持数组类型插件。
|
||
2. 新增 - 工作流增加异常离开自动保存,避免工作流丢失。
|
||
3. 新增 - LLM 模型参数支持关闭 max_tokens 和 temperature。
|
||
4. 新增 - 商业版支持后台配置模板市场。
|
||
5. 新增 - 商业版支持后台配置自定义工作流变量,用于与业务系统鉴权打通。
|
||
6. 新增 - 搜索测试接口支持问题优化。
|
||
7. 新增 - 工作流中 Input Token 和 Output Token 分开记录展示。并修复部分请求未记录输出 Token 计费问题。
|
||
8. 优化 - Markdown 大小测试,超出 20 万字符不使用 Markdown 组件,避免崩溃。
|
||
9. 优化 - 知识库搜索参数,滑动条支持输入模式,可以更精准的控制。
|
||
10. 优化 - 可用模型展示UI。
|
||
11. 优化 - Mongo 查询语句,增加 virtual 字段。
|
||
12. 修复 - 文件返回接口缺少 Content-Length 头,导致通过非同源文件上传时,阿里 vision 模型无法识别图片。
|
||
13. 修复 - 去除判断器两端字符串隐藏换行符,避免判断器失效。
|
||
14. 修复 - 变量更新节点,手动输入更新内容时候,非字符串类型数据类型无法自动转化。
|
||
15. 修复 - 豆包模型无法工具调用。
|
||
|
||
# V4.8.18(包含升级脚本)
|
||
## FastGPT V4.8.18 更新说明
|
||
|
||
## 更新指南
|
||
|
||
### 1. 更新镜像:
|
||
|
||
- 更新 fastgpt 镜像 tag: v4.8.18-fix
|
||
- 更新 fastgpt-pro 商业版镜像 tag: v4.8.18-fix
|
||
- Sandbox 镜像无需更新
|
||
|
||
### 2. 运行升级脚本
|
||
|
||
从任意终端,发起 1 个 HTTP 请求。其中 {{rootkey}} 替换成环境变量里的 `rootkey`;{{host}} 替换成**FastGPT 域名**。
|
||
|
||
```bash
|
||
curl --location --request POST 'https://{{host}}/api/admin/initv4818' \
|
||
--header 'rootkey: {{rootkey}}' \
|
||
--header 'Content-Type: application/json'
|
||
```
|
||
|
||
会迁移全文检索表,时间较长,迁移期间全文检索会失效,日志中会打印已经迁移的数据长度。
|
||
|
||
|
||
## 完整更新内容
|
||
|
||
1. 新增 - 支持通过 JSON 配置直接创建应用。
|
||
2. 新增 - 支持通过 CURL 脚本快速创建 HTTP 插件。
|
||
3. 新增 - 商业版支持部门架构权限模式。
|
||
4. 新增 - 支持配置自定跨域安全策略,默认全开。
|
||
5. 新增 - 补充私有部署,模型问题排查文档。
|
||
6. 优化 - HTTP Body 增加特殊处理,解决字符串变量带换行时无法解析问题。
|
||
7. 优化 - 分享链接随机生成用户头像。
|
||
8. 优化 - 图片上传安全校验。并增加头像图片唯一存储,确保不会累计存储。
|
||
9. 优化 - Mongo 全文索引表分离。
|
||
10. 优化 - 知识库检索查询语句合并,同时减少查库数量。
|
||
11. 优化 - 文件编码检测,减少 CSV 文件乱码概率。
|
||
12. 优化 - 异步读取文件内容,减少进程阻塞。
|
||
13. 优化 - 文件阅读,HTML 直接下载,不允许在线阅读。
|
||
14. 修复 - HTML 文件上传,base64 图片无法自动转图片链接。
|
||
15. 修复 - 插件计费错误。
|
||
|
||
# V4.8.19(包含升级脚本)
|
||
## FastGPT V4.8.19 更新说明
|
||
|
||
## 更新指南
|
||
|
||
### 1. 更新镜像:
|
||
|
||
- 更新 fastgpt 镜像 tag: v4.8.19-beta
|
||
- 更新 fastgpt-pro 商业版镜像 tag: v4.8.19-beta
|
||
- Sandbox 镜像无需更新
|
||
|
||
### 2. 运行升级脚本
|
||
|
||
从任意终端,发起 1 个 HTTP 请求。其中 {{rootkey}} 替换成环境变量里的 `rootkey`;{{host}} 替换成**FastGPT 域名**。
|
||
|
||
```bash
|
||
curl --location --request POST 'https://{{host}}/api/admin/initv4819' \
|
||
--header 'rootkey: {{rootkey}}' \
|
||
--header 'Content-Type: application/json'
|
||
```
|
||
|
||
迁移用户表的头像到成员表中。
|
||
|
||
## 完整更新内容
|
||
|
||
1. 新增 - 工作流知识库检索支持按知识库权限进行过滤。
|
||
2. 新增 - 飞书/语雀知识库查看原文。
|
||
3. 新增 - 流程等待插件,可以等待 n 毫秒后继续执行流程。
|
||
4. 新增 - 飞书机器人接入,支持配置私有化飞书地址。
|
||
5. 优化 - 成员列表分页加载。
|
||
6. 优化 - 统一分页加载代码。
|
||
7. 优化 - 对话页面加载时,可配置是否为独立页面。
|
||
8. 优化 - 成员头像迁移,移动到成员表。
|
||
9. 修复 - 语雀文件库导入时,嵌套文件内容无法展开的问题。
|
||
10. 修复 - 工作流编排中,LLM 参数无法关闭问题。
|
||
11. 修复 - 工作流编排中,代码运行节点还原模板问题。
|
||
12. 修复 - HTTP 接口适配对象字符串解析。
|
||
13. 修复 - 通过 API 上传文件(localFile)接口,图片过期标记未清除。
|
||
14. 修复 - 工作流导入编排时,number input 类型无法覆盖。
|
||
15. 修复 - 部分模型提供商 logo 无法正常显示。
|
||
|
||
# V4.8.2
|
||
## FastGPT V4.8.2 更新说明
|
||
|
||
## Sealos 升级说明
|
||
|
||
1. 在应用管理中新建一个应用,镜像为:registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt-sandbox:v4.8.1
|
||
2. 无需外网访问地址,端口号为3000
|
||
3. 部署完后,复制应用的内网地址
|
||
4. 点击变更`FastGPT - 修改环境变量,增加下面的环境变量即可
|
||
|
||
```
|
||
SANDBOX_URL=内网地址
|
||
```
|
||
|
||
## Docker 部署
|
||
|
||
可以拉取最新 [docker-compose.yml](https://github.com/labring/FastGPT/blob/main/deploy/docker/docker-compose.yml) 文件参考
|
||
|
||
1. 新增一个容器 `sandbox`
|
||
2. fastgpt 和 fastgpt-pro(商业版) 容器新增环境变量: `SANDBOX_URL`
|
||
3. sandbox 简易不要开启外网访问,未做凭证校验。
|
||
|
||
## V4.8.2 更新说明
|
||
|
||
1. 新增 - js代码运行节点(更完整的type提醒,后续继续完善)
|
||
2. 新增 - 内容提取节点支持数据类型选择
|
||
3. 修复 - 新增的站点同步无法使用
|
||
4. 修复 - 定时任务无法输入内容
|
||
|
||
# V4.8.20(包含升级脚本)
|
||
## FastGPT V4.8.20 更新说明
|
||
|
||
## 更新指南
|
||
|
||
### 1. 做好数据库备份
|
||
|
||
### 2. 更新环境变量
|
||
|
||
如果有很早版本用户,配置了`ONEAPI_URL`的,需要统一改成`OPENAI_BASE_URL`
|
||
|
||
### 3. 更新镜像:
|
||
|
||
- 更新 fastgpt 镜像 tag: v4.8.20-fix2
|
||
- 更新 fastgpt-pro 商业版镜像 tag: v4.8.20-fix2
|
||
- Sandbox 镜像无需更新
|
||
|
||
### 4. 运行升级脚本
|
||
|
||
从任意终端,发起 1 个 HTTP 请求。其中 {{rootkey}} 替换成环境变量里的 `rootkey`;{{host}} 替换成**FastGPT 域名**。
|
||
|
||
```bash
|
||
curl --location --request POST 'https://{{host}}/api/admin/initv4820' \
|
||
--header 'rootkey: {{rootkey}}' \
|
||
--header 'Content-Type: application/json'
|
||
```
|
||
|
||
脚本会自动把原配置文件的模型加载到新版模型配置中。
|
||
|
||
## 完整更新内容
|
||
|
||
1. 新增 - 可视化模型参数配置,取代原配置文件配置模型。预设超过 100 个模型配置。同时支持所有类型模型的一键测试。(预计下个版本会完全支持在页面上配置渠道)。[点击查看模型配置方案](/docs/development/modelconfig/intro/)
|
||
2. 新增 - DeepSeek resoner 模型支持输出思考过程。
|
||
3. 新增 - 使用记录导出和仪表盘。
|
||
4. 新增 - markdown 语法扩展,支持音视频(代码块 audio 和 video)。
|
||
5. 新增 - 调整 max_tokens 计算逻辑。优先保证 max_tokens 为配置值,如超出最大上下文,则减少历史记录。例如:如果申请 8000 的 max_tokens,则上下文长度会减少 8000。
|
||
6. 优化 - 问题优化增加上下文过滤,避免超出上下文。
|
||
7. 优化 - 页面组件抽离,减少页面组件路由。
|
||
8. 优化 - 全文检索,忽略大小写。
|
||
9. 优化 - 问答生成和增强索引改成流输出,避免部分模型超时。
|
||
10. 优化 - 自动给 assistant 空 content,补充 null,同时合并连续的 text assistant,避免部分模型抛错。
|
||
11. 优化 - 调整图片 Host, 取消上传时补充 FE_DOMAIN,改成发送对话前补充,避免替换域名后原图片无法正常使用。
|
||
12. 修复 - 部分场景成员列表无法触底加载。
|
||
13. 修复 - 工作流递归执行,部分条件下无法正常运行。
|
||
|
||
# V4.8.21
|
||
## FastGPT V4.8.21 更新说明
|
||
|
||
## 更新指南
|
||
|
||
### 1. 做好数据库备份
|
||
|
||
### 2. 更新镜像:
|
||
|
||
- 更新 fastgpt 镜像 tag: v4.8.21-fix
|
||
- 更新 fastgpt-pro 商业版镜像 tag: v4.8.21-fix
|
||
- Sandbox 镜像无需更新
|
||
|
||
## 完整更新内容
|
||
|
||
1. 新增 - 弃用/已删除的插件提示。
|
||
2. 新增 - 对话日志按来源分类、标题检索、导出功能。
|
||
3. 新增 - 全局变量支持拖拽排序。
|
||
4. 新增 - LLM 模型支持 top_p, response_format, json_schema 参数。
|
||
5. 新增 - Doubao1.5 模型预设。阿里 embedding3 预设。
|
||
6. 新增 - 向量模型支持归一化配置,以便适配未归一化的向量模型,例如 Doubao 的 embedding 模型。
|
||
6. 新增 - AI 对话节点,支持输出思考过程结果,可用于其他节点引用。
|
||
7. 优化 - 网站嵌入式聊天窗口,增加窗口位置适配。
|
||
8. 优化 - 模型未配置时错误提示。
|
||
9. 优化 - 适配非 Stream 模式思考输出。
|
||
10. 优化 - 增加 TTS voice 未配置时的空指针保护。
|
||
11. 优化 - Markdown 链接解析分割规则,改成严格匹配模式,牺牲兼容多种情况,减少误解析。
|
||
12. 优化 - 减少未登录用户的数据获取范围,提高系统隐私性。
|
||
13. 修复 - 简易模式,切换到其他非视觉模型时候,会强制关闭图片识别。
|
||
14. 修复 - o1,o3 模型,在测试时候字段映射未生效导致报错。
|
||
15. 修复 - 公众号对话空指针异常。
|
||
16. 修复 - 多个音频/视频文件展示异常。
|
||
17. 修复 - 分享链接鉴权报错后无限循环。
|
||
|
||
# V4.8.22(包含升级脚本)
|
||
## FastGPT V4.8.22 更新说明
|
||
|
||
## 🌟更新指南
|
||
|
||
### 1. 做好数据库备份
|
||
|
||
### 2. 更新镜像:
|
||
|
||
- 更新 fastgpt 镜像 tag: v4.8.22
|
||
- 更新 fastgpt-pro 商业版镜像 tag: v4.8.22
|
||
- Sandbox 镜像无需更新
|
||
|
||
### 3. 运行升级脚本
|
||
|
||
仅商业版,并提供 Saas 服务的用户需要运行该升级脚本。
|
||
|
||
从任意终端,发起 1 个 HTTP 请求。其中 {{rootkey}} 替换成环境变量里的 `rootkey`;{{host}} 替换成**FastGPT 域名**。
|
||
|
||
```bash
|
||
curl --location --request POST 'https://{{host}}/api/admin/initv4822' \
|
||
--header 'rootkey: {{rootkey}}' \
|
||
--header 'Content-Type: application/json'
|
||
```
|
||
|
||
会迁移联系方式到对应用户表中。
|
||
|
||
## 🚀 新增内容
|
||
|
||
1. AI 对话节点解析 `<think></think>` 标签内容作为思考链,便于各类模型进行思考链输出。需主动开启模型输出思考。
|
||
2. 对话 API 优化,无论是否传递 chatId,都会保存对话日志。未传递 chatId,则随机生成一个 chatId 来进行存储。
|
||
3. ppio 模型提供商
|
||
|
||
## ⚙️ 优化
|
||
|
||
1. 模型未配置时提示,减少冲突提示。
|
||
2. 使用记录代码。
|
||
3. 内容提取节点,字段描述过长时换行。同时修改其输出名用 key,而不是 description。
|
||
4. 团队管理交互。
|
||
5. 对话接口,非流响应,增加报错字段。
|
||
|
||
## 🐛 修复
|
||
|
||
1. 思考内容未进入到输出 Tokens.
|
||
2. 思考链流输出时,有时与正文顺序偏差。
|
||
3. API 调用工作流,如果传递的图片不支持 Head 检测时,图片会被过滤。已增加该类错误检测,避免被错误过滤。
|
||
4. 模板市场部分模板错误。
|
||
5. 免登录窗口无法正常判断语言识别是否开启。
|
||
6. 对话日志导出,未兼容 sub path。
|
||
7. 切换团队时未刷新成员列表
|
||
8. list 接口在联查 member 时,存在空指针可能性。
|
||
9. 工作流基础节点无法升级。
|
||
10. 向量检索结果未去重。
|
||
11. 用户选择节点无法正常连线。
|
||
12. 对话记录保存时,source 未正常记录。
|
||
|
||
# V4.8.23
|
||
## FastGPT V4.8.23 更新说明
|
||
|
||
## 更新指南
|
||
|
||
### 1. 做好数据库备份
|
||
|
||
### 2. 更新镜像:
|
||
|
||
- 更新 fastgpt 镜像 tag: v4.8.23-fix
|
||
- 更新 fastgpt-pro 商业版镜像 tag: v4.8.23-fix
|
||
- Sandbox 镜像无需更新
|
||
|
||
### 3. 运行升级脚本
|
||
|
||
从任意终端,发起 1 个 HTTP 请求。其中 {{rootkey}} 替换成环境变量里的 `rootkey`;{{host}} 替换成**FastGPT 域名**。
|
||
|
||
```bash
|
||
curl --location --request POST 'https://{{host}}/api/admin/initv4823' \
|
||
--header 'rootkey: {{rootkey}}' \
|
||
--header 'Content-Type: application/json'
|
||
```
|
||
|
||
脚本会清理一些知识库脏数据,主要是多余的全文索引。
|
||
|
||
## 🚀 新增内容
|
||
|
||
1. 增加默认“知识库文本理解模型”配置
|
||
2. AI proxy V1版,可替换 OneAPI使用,同时提供完整模型调用日志,便于排查问题。
|
||
3. 增加工单入口支持。
|
||
|
||
## ⚙️ 优化
|
||
|
||
1. 模型配置表单,增加必填项校验。
|
||
2. 集合列表数据统计方式,提高大数据量统计性能。
|
||
3. 优化数学公式,转义 Latex 格式成 Markdown 格式。
|
||
4. 解析文档图片,图片太大时,自动忽略。
|
||
5. 时间选择器,当天开始时间自动设0,结束设置设 23:59:59,避免 UI 与实际逻辑偏差。
|
||
6. 升级 mongoose 库版本依赖。
|
||
|
||
## 🐛 修复
|
||
|
||
1. 标签过滤时,子文件夹未成功过滤。
|
||
2. 暂时移除 md 阅读优化,避免链接分割错误。
|
||
3. 离开团队时,未刷新成员列表。
|
||
4. PPTX 编码错误,导致解析失败。
|
||
5. 删除知识库单条数据时,全文索引未跟随删除。
|
||
6. 修复 Mongo Dataset text 索引在查询数据时未生效。
|
||
|
||
# V4.8.3
|
||
## FastGPT V4.8.3 更新说明
|
||
|
||
## 升级指南
|
||
|
||
- fastgpt 镜像 tag 修改成 v4.8.3
|
||
- fastgpt-sandbox 镜像 tag 修改成 v4.8.3
|
||
- 商业版镜像 tag 修改成 v4.8.3
|
||
|
||
## V4.8.3 更新说明
|
||
|
||
1. 新增 - 支持 Milvus 数据库, 可参考最新的 [docker-compose-milvus.yml](https://github.com/labring/FastGPT/blob/main/deploy/docker/docker-compose-milvus.yml).
|
||
2. 新增 - 给 chat 接口 empty answer 增加 log,便于排查模型问题。
|
||
3. 新增 - ifelse判断器,字符串支持正则。
|
||
4. 新增 - 代码运行支持 console.log 输出调试。
|
||
5. 修复 - 变量更新在 Debug 模式下出错。
|
||
|
||
# V4.8.4(包含升级脚本)
|
||
## FastGPT V4.8.4 更新说明
|
||
|
||
## 升级指南
|
||
|
||
### 1. 修改镜像
|
||
|
||
- fastgpt 镜像 tag 修改成 v4.8.4
|
||
- fastgpt-sandbox 镜像 tag 修改成 v4.8.4 (选择性,无变更)
|
||
- 商业版镜像 tag 修改成 v4.8.4
|
||
|
||
### 2. 商业版用户执行初始化
|
||
|
||
从任意终端,发起 1 个 HTTP 请求。其中 {{rootkey}} 替换成环境变量里的 `rootkey`;{{host}} 替换成**FastGPT 商业版的域名**。
|
||
|
||
```bash
|
||
curl --location --request POST 'https://{{host}}/api/admin/init/484' \
|
||
--header 'rootkey: {{rootkey}}' \
|
||
--header 'Content-Type: application/json'
|
||
```
|
||
|
||
## V4.8.4 更新说明
|
||
|
||
1. 新增 - 应用使用新权限系统。
|
||
2. 新增 - 应用支持文件夹。
|
||
3. 优化 - 文本分割增加连续换行、制表符清除,避免大文本性能问题。
|
||
4. 重要修复 - 修复系统插件运行池数据污染问题,由于从内存获取,会导致全局污染。
|
||
5. 修复 - Debug 模式下,相同 source 和 target 内容,导致连线显示异常。
|
||
6. 修复 - 定时执行初始化错误。
|
||
7. 修复 - 应用调用传参异常。
|
||
8. 修复 - ctrl + cv 复杂节点时,nodeId错误。
|
||
9. 调整组件库全局theme。
|
||
|
||
# V4.8.5(包含升级脚本)
|
||
## FastGPT V4.8.5 更新说明
|
||
|
||
## 升级指南
|
||
|
||
### 1. 做好数据库备份
|
||
|
||
### 2. 修改镜像
|
||
|
||
- fastgpt 镜像 tag 修改成 v4.8.5
|
||
- 商业版镜像 tag 修改成 v4.8.5
|
||
|
||
### 3. 执行初始化
|
||
|
||
从任意终端,发起 1 个 HTTP 请求。其中 {{rootkey}} 替换成环境变量里的 `rootkey`;{{host}} 替换成**FastGPT 域名**。
|
||
|
||
```bash
|
||
curl --location --request POST 'https://{{host}}/api/admin/initv485' \
|
||
--header 'rootkey: {{rootkey}}' \
|
||
--header 'Content-Type: application/json'
|
||
```
|
||
|
||
会把插件的数据表合并到应用中,插件表不会删除。
|
||
|
||
------
|
||
|
||
**商业版用户执行额外的初始化**
|
||
|
||
从任意终端,发起 1 个 HTTP 请求。其中 {{rootkey}} 替换成环境变量里的 `rootkey`;{{host}} 替换成**FastGPT 商业版的域名**:
|
||
|
||
```bash
|
||
curl --location --request POST 'https://{{host}}/api/admin/init/485' \
|
||
--header 'rootkey: {{rootkey}}' \
|
||
--header 'Content-Type: application/json'
|
||
```
|
||
|
||
会重置知识库权限系统。
|
||
|
||
## V4.8.5 更新说明
|
||
|
||
1. 新增 - 合并插件和应用,统一成工作台
|
||
2. 新增 - 应用创建副本功能
|
||
3. 新增 - 应用创建模板
|
||
4. 新增 - 支持代码运行结果作为工具输出。
|
||
5. 新增 - Markdown 图片输出,支持移动端放大缩放。
|
||
6. 优化 - 原文件编码存取
|
||
7. 优化 - 知识库删除后,简易模式会过滤掉删除的知识库,避免错误判断。
|
||
8. 优化 - 文件夹读取,支持单个文件夹超出 100 个文件
|
||
9. 优化 - 问答拆分/手动录入,当有`a`字段时,自动将`q`作为补充索引。
|
||
10. 优化 - 对话框页面代码
|
||
11. 优化 - 工作流新节点自动增加序号名
|
||
12. 修复 - 定时任务无法实际关闭
|
||
13. 修复 - 输入引导特殊字符导致正则报错
|
||
14. 修复 - 文件包含特殊字符`%`,且为转义时会导致页面崩溃
|
||
15. 修复 - 自定义输入选择知识库引用时页面崩溃
|
||
|
||
# V4.8.6(包含升级脚本)
|
||
## FastGPT V4.8.6 更新说明
|
||
|
||
## 升级指南
|
||
|
||
### 1. 做好数据库备份
|
||
|
||
### 2. 修改镜像
|
||
|
||
- fastgpt 镜像 tag 修改成 v4.8.6
|
||
- fastgpt-sandbox 镜像 tag 修改成 v4.8.6
|
||
- 商业版镜像 tag 修改成 v4.8.6
|
||
|
||
### 3. 执行初始化
|
||
|
||
从任意终端,发起 1 个 HTTP 请求。其中 {{rootkey}} 替换成环境变量里的 `rootkey`;{{host}} 替换成**FastGPT 域名**。
|
||
|
||
```bash
|
||
curl --location --request POST 'https://{{host}}/api/admin/initv486' \
|
||
--header 'rootkey: {{rootkey}}' \
|
||
--header 'Content-Type: application/json'
|
||
```
|
||
|
||
会初始化应用的继承权限
|
||
|
||
-------
|
||
|
||
## V4.8.6 更新说明
|
||
|
||
1. 新增 - 应用权限继承
|
||
2. 新增 - 知识库支持单个集合禁用功能
|
||
3. 新增 - 系统插件模式变更,新增链接读取和数学计算器插件,正式版会更新如何自定义系统插件
|
||
4. 新增 - 代码沙盒运行参数
|
||
5. 新增 - AI对话时隐藏头部的功能,主要是适配移动端
|
||
6. 优化 - 文件读取,Mongo 默认使用从节点,减轻主节点压力
|
||
7. 优化 - 提示词模板
|
||
8. 优化 - Mongo model 重复加载
|
||
9. 修复 - 创建链接集合未返回 id
|
||
10. 修复 - 文档接口说明
|
||
11. 修复 - api system 提示合并
|
||
12. 修复 - 团队插件目录内的内容无法加载
|
||
13. 修复 - 知识库集合目录面包屑无法加载
|
||
14. 修复 - Markdown 导出对话异常
|
||
15. 修复 - 提示模板结束标签错误
|
||
16. 修复 - 文档描述
|
||
|
||
# V4.8.7
|
||
## FastGPT V4.8.7 更新说明
|
||
|
||
## 升级指南
|
||
|
||
### 1. 做好数据库备份
|
||
|
||
### 2. 修改镜像
|
||
|
||
- fastgpt 镜像 tag 修改成 v4.8.7
|
||
- 商业版镜像 tag 修改成 v4.8.7
|
||
|
||
-------
|
||
|
||
## V4.8.7 更新说明
|
||
|
||
1. 新增 - 插件支持独立运行,发布和日志查看
|
||
2. 新增 - 应用搜索
|
||
3. 优化 - 对话框代码
|
||
4. 优化 - 升级 Dockerfile node 和 pnpm 版本
|
||
5. 优化 - local 域名部署,也可以正常使用 vision 模式
|
||
6. 修复 - 简易模式无法变更全局变量
|
||
7. 修复 - gpt4o 无法同时使用工具和图片
|
||
|
||
# V4.8.8(包含升级脚本)
|
||
## FastGPT V4.8.8 更新说明
|
||
|
||
## 升级指南
|
||
|
||
### 1. 做好数据库备份
|
||
|
||
### 2. 修改镜像
|
||
|
||
- fastgpt 镜像 tag 修改成 v4.8.8-fix2
|
||
- 商业版镜像 tag 修改成 v4.8.8
|
||
|
||
### 3. 执行初始化
|
||
|
||
从任意终端,发起 1 个 HTTP 请求。其中 {{rootkey}} 替换成环境变量里的 `rootkey`;{{host}} 替换成**FastGPT 域名**。
|
||
|
||
```bash
|
||
curl --location --request POST 'https://{{host}}/api/admin/initv488' \
|
||
--header 'rootkey: {{rootkey}}' \
|
||
--header 'Content-Type: application/json'
|
||
```
|
||
|
||
会初始化知识库的继承权限
|
||
|
||
-------
|
||
|
||
## V4.8.8 更新说明
|
||
|
||
[点击查看完整更新](https://github.com/labring/FastGPT/releases/tag/v4.8.8)
|
||
|
||
1. 新增 - 重构系统插件的结构。允许向开源社区 PR 系统插件,具体可见: [如何向 FastGPT 社区提交系统插件](https://fael3z0zfze.feishu.cn/wiki/ERZnw9R26iRRG0kXZRec6WL9nwh)。
|
||
2. 新增 - DuckDuckGo 系统插件。
|
||
3. 新增 - 飞书 webhook 系统插件。
|
||
4. 新增 - 修改变量填写方式。提示词输入框以以及工作流中所有 Textarea 输入框,支持输入 / 唤起变量选择,可直接选择所有上游输出值,无需动态引入。
|
||
5. 商业版新增 - 知识库权限继承。
|
||
6. 优化 - 移动端快速切换应用交互。
|
||
7. 优化 - 节点图标。
|
||
8. 优化 - 对话框引用增加额外复制案件,便于复制。增加引用内容折叠。
|
||
9. 优化 - OpenAI sdk 升级,并自定义了 whisper 模型接口(未仔细查看 sdk 实现,但 sdk 中 whisper 接口,似乎无法适配一般 fastapi 接口)
|
||
10. 修复 - Permission 表声明问题。
|
||
11. 修复 - 并行执行节点,运行时间未正确记录。
|
||
12. 修复 - 运行详情未正确展示嵌套节点信息。
|
||
13. 修复 - 简易模式,首次进入,无法正确获取知识库配置。
|
||
14. 修复 - Log debug level 配置无效。
|
||
15. 修复 - 插件独立运行时,会将插件输入的值进行变量替换,可能导致后续节点变量异常。
|
||
|
||
# V4.8.9(需要初始化)
|
||
## FastGPT V4.8.9 更新说明
|
||
|
||
## 升级指南
|
||
|
||
### 1. 做好数据库备份
|
||
|
||
### 2. 修改镜像
|
||
|
||
- 更新 FastGPT 镜像 tag: v4.8.9
|
||
- 更新 FastGPT 商业版镜像 tag: v4.8.9
|
||
- Sandbox 镜像,可以不更新
|
||
|
||
### 3. 商业版执行初始化
|
||
|
||
从任意终端,发起 1 个 HTTP 请求。其中 {{rootkey}} 替换成环境变量里的 `rootkey`;{{host}} 替换成**FastGPT 商业版域名**。
|
||
|
||
```bash
|
||
curl --location --request POST 'https://{{host}}/api/admin/init/489' \
|
||
--header 'rootkey: {{rootkey}}' \
|
||
--header 'Content-Type: application/json'
|
||
```
|
||
|
||
会初始化多租户的通知方式,仅内部使用的,无需执行。
|
||
|
||
-------
|
||
|
||
## V4.8.9 更新说明
|
||
|
||
1. 新增 - 文件上传配置,不再依赖视觉模型决定是否可上传图片,而是通过系统配置决定。
|
||
2. 新增 - AI 对话节点和工具调用支持选择“是否开启图片识别”,开启后会自动获取对话框上传的图片和“用户问题”中的图片链接。
|
||
3. 新增 - 文档解析节点。
|
||
4. 商业版新增 - 团队通知账号绑定,用于接收重要信息。
|
||
5. 商业版新增 - 知识库集合标签功能,可以对知识库进行标签管理。
|
||
6. 商业版新增 - 知识库搜索节点支持标签过滤和创建时间过滤。
|
||
7. 商业版新增 - 转移 App owner 权限。
|
||
8. 新增 - 删除所有对话引导内容。
|
||
9. 新增 - QA 拆分支持自定义 chunk 大小,并优化 gpt4o-mini 拆分时,chunk 太大导致生成内容很少的问题。
|
||
10. 优化 - 对话框信息懒加载,减少网络传输。
|
||
11. 优化 - 清除选文件缓存,支持重复选择同一个文件。
|
||
12. 修复 - 知识库上传文件,网络不稳定或文件较多情况下,进度无法到 100%。
|
||
13. 修复 - 删除应用后回到聊天选择最后一次对话的应用为删除的应用时提示无该应用问题。
|
||
14. 修复 - 插件动态变量配置默认值时,无法正常显示默认值。
|
||
15. 修复 - 工具调用温度和最大回复值未生效。
|
||
16. 修复 - 函数调用模式,assistant role 中,GPT 模型必须传入 content 参数。(不影响大部分模型,目前基本都改用用 ToolChoice 模式,FC 模式已弃用)。
|
||
17. 修复 - 知识库文件上传进度更新可能异常。
|
||
18. 修复 - 知识库 rebuilding 时候,页面总是刷新到第一页。
|
||
19. 修复 - 知识库 list openapi 鉴权问题。
|
||
20. 修复 - 分享链接,新对话无法反馈。
|
||
|
||
# V4.9.0(包含升级脚本)
|
||
## FastGPT V4.9.0 更新说明
|
||
|
||
## 更新指南
|
||
|
||
### 1. 做好数据库备份
|
||
|
||
### 2. 更新镜像和 PG 容器
|
||
|
||
- 更新 FastGPT 镜像 tag: v4.9.0
|
||
- 更新 FastGPT 商业版镜像 tag: v4.9.0
|
||
- Sandbox 镜像,可以不更新
|
||
- 更新 PG 容器为 v0.8.0-pg15, 可以查看[最新的 yml](https://raw.githubusercontent.com/labring/FastGPT/main/deploy/docker/docker-compose-pgvector.yml)
|
||
|
||
### 3. 替换 OneAPI(可选)
|
||
|
||
如果需要使用 [AI Proxy](https://github.com/labring/aiproxy) 替换 OneAPI 的用户可执行该步骤。
|
||
|
||
#### 1. 修改 yml 文件
|
||
|
||
参考[最新的 yml](https://raw.githubusercontent.com/labring/FastGPT/main/deploy/docker/docker-compose-pgvector.yml) 文件。里面已移除 OneAPI 并添加了 AIProxy配置。包含一个服务和一个 PgSQL 数据库。将 `aiproxy` 的配置`追加`到 OneAPI 的配置后面(先不要删除 OneAPI,有一个初始化会自动同步 OneAPI 的配置)
|
||
|
||
{{% details title="AI Proxy Yml 配置" closed="true" %}}
|
||
|
||
```
|
||
# AI Proxy
|
||
aiproxy:
|
||
image: 'ghcr.io/labring/aiproxy:latest'
|
||
container_name: aiproxy
|
||
restart: unless-stopped
|
||
depends_on:
|
||
aiproxy_pg:
|
||
condition: service_healthy
|
||
networks:
|
||
- fastgpt
|
||
environment:
|
||
# 对应 fastgpt 里的AIPROXY_API_TOKEN
|
||
- ADMIN_KEY=aiproxy
|
||
# 错误日志详情保存时间(小时)
|
||
- LOG_DETAIL_STORAGE_HOURS=1
|
||
# 数据库连接地址
|
||
- SQL_DSN=postgres://postgres:aiproxy@aiproxy_pg:5432/aiproxy
|
||
# 最大重试次数
|
||
- RETRY_TIMES=3
|
||
# 不需要计费
|
||
- BILLING_ENABLED=false
|
||
# 不需要严格检测模型
|
||
- DISABLE_MODEL_CONFIG=true
|
||
healthcheck:
|
||
test: ['CMD', 'curl', '-f', 'http://localhost:3000/api/status']
|
||
interval: 5s
|
||
timeout: 5s
|
||
retries: 10
|
||
aiproxy_pg:
|
||
image: pgvector/pgvector:0.8.0-pg15 # docker hub
|
||
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/pgvector:v0.8.0-pg15 # 阿里云
|
||
restart: unless-stopped
|
||
container_name: aiproxy_pg
|
||
volumes:
|
||
- ./aiproxy_pg:/var/lib/postgresql/data
|
||
networks:
|
||
- fastgpt
|
||
environment:
|
||
TZ: Asia/Shanghai
|
||
POSTGRES_USER: postgres
|
||
POSTGRES_DB: aiproxy
|
||
POSTGRES_PASSWORD: aiproxy
|
||
healthcheck:
|
||
test: ['CMD', 'pg_isready', '-U', 'postgres', '-d', 'aiproxy']
|
||
interval: 5s
|
||
timeout: 5s
|
||
retries: 10
|
||
```
|
||
|
||
{{% /details %}}
|
||
|
||
#### 2. 增加 FastGPT 环境变量:
|
||
|
||
修改 yml 文件中,fastgpt 容器的环境变量:
|
||
|
||
```
|
||
# AI Proxy 的地址,如果配了该地址,优先使用
|
||
- AIPROXY_API_ENDPOINT=http://aiproxy:3000
|
||
# AI Proxy 的 Admin Token,与 AI Proxy 中的环境变量 ADMIN_KEY
|
||
- AIPROXY_API_TOKEN=aiproxy
|
||
```
|
||
|
||
#### 3. 重载服务
|
||
|
||
`docker-compose down` 停止服务,然后 `docker-compose up -d` 启动服务,此时会追加 `aiproxy` 服务,并修改 FastGPT 的配置。
|
||
|
||
#### 4. 执行OneAPI迁移AI proxy脚本
|
||
|
||
- 可联网方案:
|
||
|
||
```bash
|
||
# 进入 aiproxy 容器
|
||
docker exec -it aiproxy sh
|
||
# 安装 curl
|
||
apk add curl
|
||
# 执行脚本
|
||
curl --location --request POST 'http://localhost:3000/api/channels/import/oneapi' \
|
||
--header 'Authorization: Bearer aiproxy' \
|
||
--header 'Content-Type: application/json' \
|
||
--data-raw '{
|
||
"dsn": "mysql://root:oneapimmysql@tcp(mysql:3306)/oneapi"
|
||
}'
|
||
# 返回 {"data":[],"success":true} 代表成功
|
||
```
|
||
|
||
- 无法联网时,可打开`aiproxy`的外网暴露端口,然后在本地执行脚本。
|
||
|
||
aiProxy 暴露端口:3003:3000,修改后重新 `docker-compose up -d` 启动服务。
|
||
|
||
```bash
|
||
# 在终端执行脚本
|
||
curl --location --request POST 'http://localhost:3003/api/channels/import/oneapi' \
|
||
--header 'Authorization: Bearer aiproxy' \
|
||
--header 'Content-Type: application/json' \
|
||
--data-raw '{
|
||
"dsn": "mysql://root:oneapimmysql@tcp(mysql:3306)/oneapi"
|
||
}'
|
||
# 返回 {"data":[],"success":true} 代表成功
|
||
```
|
||
|
||
- 如果不熟悉 docker 操作,建议不要走脚本迁移,直接删除 OneAPI 所有内容,然后手动重新添加渠道。
|
||
|
||
#### 5. 进入 FastGPT 检查`AI Proxy` 服务是否正常启动。
|
||
|
||
登录 root 账号后,在`账号-模型提供商`页面,可以看到多出了`模型渠道`和`调用日志`两个选项,打开模型渠道,可以看到之前 OneAPI 的渠道,说明迁移完成,此时可以手动再检查下渠道是否正常。
|
||
|
||
#### 6. 删除 OneAPI 服务
|
||
|
||
```bash
|
||
# 停止服务,或者针对性停止 OneAPI 和其 Mysql
|
||
docker-compose down
|
||
# yml 文件中删除 OneAPI 和其 Mysql 依赖
|
||
# 重启服务
|
||
docker-compose up -d
|
||
```
|
||
|
||
### 4. 运行 FastGPT 升级脚本
|
||
|
||
从任意终端,发起 1 个 HTTP 请求。其中 {{rootkey}} 替换成环境变量里的 `rootkey`;{{host}} 替换成**FastGPT 域名**。
|
||
|
||
```bash
|
||
curl --location --request POST 'https://{{host}}/api/admin/initv490' \
|
||
--header 'rootkey: {{rootkey}}' \
|
||
--header 'Content-Type: application/json'
|
||
```
|
||
|
||
**脚本功能**
|
||
|
||
1. 升级 PG Vector 插件版本
|
||
2. 全量更新知识库集合字段。
|
||
3. 全量更新知识库数据中,index 的 type 类型。(时间较长,最后可能提示 timeout,可忽略,数据库不崩都会一直增量执行)
|
||
|
||
## 兼容 & 弃用
|
||
|
||
1. 弃用 - 之前私有化部署的自定义文件解析方案,请同步更新到最新的配置方案。[点击查看 PDF 增强解析配置](/docs/development/configuration/#使用-doc2x-解析-pdf-文件)
|
||
2. 弃用 - 弃用旧版本地文件上传 API:/api/core/dataset/collection/create/file(以前仅商业版可用的 API,该接口已放切换成:/api/core/dataset/collection/create/localFile)
|
||
3. 停止维护,即将弃用 - 外部文件库相关 API,可通过 API 文件库替代。
|
||
4. API更新 - 上传文件至知识库、创建连接集合、API 文件库、推送分块数据等带有 `trainingType` 字段的接口,`trainingType`字段未来仅支持`chunk`和`QA`两种模式。增强索引模式将设置单独字段:`autoIndexes`,目前仍有适配旧版`trainingType=auto`代码,但请尽快变更成新接口类型。具体可见:[知识库 OpenAPI 文档](/docs/development/openapi/dataset.md)
|
||
|
||
## 🚀 新增内容
|
||
|
||
1. PDF增强解析交互添加到页面上。同时内嵌 Doc2x 服务,可直接使用 Doc2x 服务解析 PDF 文件。
|
||
2. 图片自动标注,同时修改知识库文件上传部分数据逻辑和交互。
|
||
3. pg vector 插件升级 0.8.0 版本,引入迭代搜索,减少部分数据无法被检索的情况。
|
||
4. 新增 qwen-qwq 系列模型配置。
|
||
|
||
## ⚙️ 优化
|
||
|
||
1. 知识库数据不再限制索引数量,可无限自定义。同时可自动更新输入文本的索引,不影响自定义索引。
|
||
2. Markdown 解析,增加链接后中文标点符号检测,增加空格。
|
||
3. Prompt 模式工具调用,支持思考模型。同时优化其格式检测,减少空输出的概率。
|
||
4. Mongo 文件读取流合并,减少计算量。同时优化存储 chunks,极大提高大文件读取速度。50M PDF 读取时间提高 3 倍。
|
||
5. HTTP Body 适配,增加对字符串对象的适配。
|
||
|
||
## 🐛 修复
|
||
|
||
1. 增加网页抓取安全链接校验。
|
||
2. 批量运行时,全局变量未进一步传递到下一次运行中,导致最终变量更新错误。
|
||
|
||
# V4.9.1
|
||
## FastGPT V4.9.1 更新说明
|
||
|
||
## 更新指南
|
||
|
||
### 1. 做好数据库备份
|
||
|
||
### 2. 更新镜像
|
||
|
||
- 更新 FastGPT 镜像 tag: v4.9.1-fix2
|
||
- 更新 FastGPT 商业版镜像 tag: v4.9.1-fix2
|
||
- Sandbox 镜像,可以不更新
|
||
- AIProxy 镜像修改为: registry.cn-hangzhou.aliyuncs.com/labring/aiproxy:v0.1.3
|
||
|
||
### 3. 执行升级脚本
|
||
|
||
从任意终端,发起 1 个 HTTP 请求。其中 {{rootkey}} 替换成环境变量里的 `rootkey`;{{host}} 替换成**FastGPT 域名**。
|
||
|
||
```bash
|
||
curl --location --request POST 'https://{{host}}/api/admin/initv491' \
|
||
--header 'rootkey: {{rootkey}}' \
|
||
--header 'Content-Type: application/json'
|
||
```
|
||
|
||
**脚本功能**
|
||
|
||
重新使用最新的 jieba 分词库进行分词处理。时间较长,可以从日志里查看进度。
|
||
|
||
## 🚀 新增内容
|
||
|
||
1. 商业版支持单团队模式,更好的管理内部成员。
|
||
2. 知识库分块阅读器。
|
||
3. API 知识库支持 PDF 增强解析。
|
||
4. 邀请团队成员,改为邀请链接模式。
|
||
5. 支持混合检索权重设置。
|
||
6. 支持重排模型选择和权重设置,同时调整了知识库搜索权重计算方式,改成 搜索权重 + 重排权重,而不是向量检索权重+全文检索权重+重排权重。会对检索结果有一定影响,可以通过调整相关权重来进行数据适配。
|
||
|
||
## ⚙️ 优化
|
||
|
||
1. 知识库数据输入框交互
|
||
2. 应用拉取绑定知识库数据交由后端处理。
|
||
3. 增加依赖包安全版本检测,并升级部分依赖包。
|
||
4. 模型测试代码。
|
||
5. 优化思考过程解析逻辑:只要配置了模型支持思考,均会解析 <think> 标签,不会因为对话时,关闭思考而不解析。
|
||
6. 载入最新 jieba 分词库,增强全文检索分词效果。
|
||
|
||
## 🐛 修复
|
||
|
||
1. 最大响应 tokens 提示显示错误的问题。
|
||
2. HTTP Node 中,字符串包含换行符时,会解析失败。
|
||
3. 知识库问题优化中,未传递历史记录。
|
||
4. 错误提示翻译缺失。
|
||
5. 内容提取节点,array 类型 schema 错误。
|
||
6. 模型渠道测试时,实际未指定渠道测试。
|
||
7. 新增自定义模型时,会把默认模型字段也保存,导致默认模型误判。
|
||
8. 修复 promp 模式工具调用,未判空思考链,导致 UI 错误展示。
|
||
9. 编辑应用信息导致头像丢失。
|
||
10. 分享链接标题会被刷新掉。
|
||
11. 计算 parentPath 时,存在鉴权失败清空。
|
||
|
||
# V4.9.2
|
||
## FastGPT V4.9.2 更新说明
|
||
|
||
## 更新指南
|
||
|
||
可直接升级v4.9.3,v4.9.2存在一个工作流数据类型转化错误。
|
||
|
||
### 1. 做好数据库备份
|
||
|
||
### 2. SSO 迁移
|
||
|
||
使用了 SSO 或成员同步的商业版用户,并且是对接`钉钉`、`企微`的,需要迁移已有的 SSO 相关配置:
|
||
|
||
参考:[SSO & 外部成员同步](/docs/guide/admin/sso)中的配置进行`sso-service`的部署和配置。
|
||
|
||
1. 先将原商业版后台中的相关配置项复制备份出来(以企微为例,将 AppId, Secret 等复制出来)再进行镜像升级。
|
||
2. 参考上述文档,部署 SSO 服务,配置相关的环境变量
|
||
3. 如果原先使用企微组织架构同步的用户,升级完镜像后,需要在商业版后台切换团队模式为“同步模式”
|
||
|
||
### 3. 配置参数变更
|
||
|
||
修改`config.json`文件中`systemEnv.pgHNSWEfSearch`参数名,改成`hnswEfSearch`。
|
||
商业版用户升级镜像后,直接在后台`系统配置-基础配置`中进行变更。
|
||
|
||
### 4. 更新镜像
|
||
|
||
- 更新 FastGPT 镜像 tag: v4.9.2
|
||
- 更新 FastGPT 商业版镜像 tag: v4.9.2
|
||
- Sandbox 镜像,可以不更新
|
||
- AIProxy 镜像修改为: registry.cn-hangzhou.aliyuncs.com/labring/aiproxy:v0.1.4
|
||
|
||
## 重要更新
|
||
|
||
- 知识库导入数据 API 变更,增加`chunkSettingMode`,`chunkSplitMode`,`indexSize`可选参数,具体可参考 [知识库导入数据 API](/docs/development/openapi/dataset) 文档。
|
||
|
||
## 🚀 新增内容
|
||
|
||
1. 知识库分块优化:支持单独配置分块大小和索引大小,允许进行超大分块,以更大的输入 Tokens 换取完整分块。
|
||
2. 知识库分块增加自定义分隔符预设值,同时支持自定义换行符分割。
|
||
3. 外部变量改名:自定义变量。 并且支持在测试时调试,在分享链接中,该变量直接隐藏。
|
||
4. 集合同步时,支持同步修改标题。
|
||
5. 团队成员管理重构,抽离主流 IM SSO(企微、飞书、钉钉),并支持通过自定义 SSO 接入 FastGPT。同时完善与外部系统的成员同步。
|
||
6. 支持 `oceanbase` 向量数据库。填写环境变量`OCEANBASE_URL`即可。
|
||
7. 基于 mistral-ocr 的 PDF 解析示例。
|
||
8. 基于 miner-u 的 PDF 解析示例。
|
||
|
||
## ⚙️ 优化
|
||
|
||
1. 导出对话日志时,支持导出成员名。
|
||
2. 邀请链接交互。
|
||
3. 无 SSL 证书时复制失败,会提示弹窗用于手动复制。
|
||
4. FastGPT 未内置 ai proxy 渠道时,也能正常展示其名称。
|
||
5. 升级 nextjs 版本至 14.2.25。
|
||
6. 工作流节点数组字符串类型,自动适配 string 输入。
|
||
7. 工作流节点数组类型,自动进行 JSON parse 解析 string 输入。
|
||
8. AI proxy 日志优化,去除重试失败的日志,仅保留最后一份错误日志。
|
||
9. 个人信息和通知展示优化。
|
||
10. 模型测试 loading 动画优化。
|
||
11. 分块算法小调整:
|
||
* 跨处理符号之间连续性更强。
|
||
* 代码块分割时,用 LLM 模型上下文作为分块大小,尽可能保证代码块完整性。
|
||
* 表格分割时,用 LLM 模型上下文作为分块大小,尽可能保证表格完整性。
|
||
|
||
## 🐛 修复
|
||
|
||
1. 飞书和语雀知识库无法同步。
|
||
2. 渠道测试时,如果配置了模型自定义请求地址,会走自定义请求地址,而不是渠道请求地址。
|
||
3. 语音识别模型测试未启用的模型时,无法正常测试。
|
||
4. 管理员配置系统插件时,如果插件包含其他系统应用,无法正常鉴权。
|
||
5. 移除 TTS 自定义请求地址时,必须需要填 requestAuth 字段。
|
||
|
||
# V4.9.3
|
||
## FastGPT V4.9.3 更新说明
|
||
|
||
## 更新指南
|
||
|
||
### 1. 做好数据库备份
|
||
|
||
### 2. 更新镜像
|
||
|
||
- 更新 FastGPT 镜像 tag: v4.9.3
|
||
- 更新 FastGPT 商业版镜像 tag: v4.9.3
|
||
- Sandbox 镜像tag: v4.9.3
|
||
- AIProxy 镜像tag: v0.1.5
|
||
|
||
|
||
## 🚀 新增内容
|
||
|
||
1. 工作流 debug 模式支持交互节点。
|
||
2. 代码运行支持 Python3 代码。
|
||
|
||
## 🐛 修复
|
||
|
||
1. 工作流格式转化异常。
|
||
|
||
# V4.9.4
|
||
## FastGPT V4.9.4 更新说明
|
||
|
||
## 升级指南
|
||
|
||
### 1. 做好数据备份
|
||
|
||
### 2. 安装 Redis
|
||
|
||
* docker 部署的用户,参考最新的 `docker-compose.yml` 文件增加 Redis 配置。增加一个 redis 容器,并配置`fastgpt`,`fastgpt-pro`的环境变量,增加 `REDIS_URL` 环境变量。
|
||
* Sealos 部署的用户,在数据库里新建一个`redis`数据库,并复制`内网地址的 connection` 作为 `redis` 的链接串。然后配置`fastgpt`,`fastgpt-pro`的环境变量,增加 `REDIS_URL` 环境变量。
|
||
|
||
| | | |
|
||
| --- | --- | --- |
|
||
|  |  |  |
|
||
|
||
### 3. 更新镜像 tag
|
||
|
||
- 更新 FastGPT 镜像 tag: v4.9.4
|
||
- 更新 FastGPT 商业版镜像 tag: v4.9.4
|
||
- Sandbox 无需更新
|
||
- AIProxy 无需更新
|
||
|
||
### 4. 执行升级脚本
|
||
|
||
该脚本仅需商业版用户执行。
|
||
|
||
从任意终端,发起 1 个 HTTP 请求。其中 {{rootkey}} 替换成环境变量里的 `rootkey`;{{host}} 替换成**FastGPT 域名**。
|
||
|
||
```bash
|
||
curl --location --request POST 'https://{{host}}/api/admin/initv494' \
|
||
--header 'rootkey: {{rootkey}}' \
|
||
--header 'Content-Type: application/json'
|
||
```
|
||
|
||
**脚本功能**
|
||
|
||
1. 更新站点同步定时器
|
||
|
||
## 🚀 新增内容
|
||
|
||
1. 集合数据训练状态展示
|
||
2. SMTP 发送邮件插件
|
||
3. BullMQ 消息队列。
|
||
4. 利用 redis 进行部分数据缓存。
|
||
5. 站点同步支持配置训练参数和增量同步。
|
||
6. AI 对话/工具调用,增加返回模型 finish_reason 字段,便于追踪模型输出中断原因。
|
||
7. 移动端语音输入交互调整
|
||
|
||
## ⚙️ 优化
|
||
|
||
1. Admin 模板渲染调整。
|
||
2. 支持环境变量配置对话文件过期时间。
|
||
3. MongoDB log 库可独立部署。
|
||
|
||
## 🐛 修复
|
||
|
||
1. 搜索应用/知识库时,无法点击目录进入下一层。
|
||
2. 重新训练时,参数未成功初始化。
|
||
3. package/service 部分请求在多 app 中不一致。
|
||
|
||
# V4.9.5
|
||
## FastGPT V4.9.5 更新说明
|
||
|
||
## 升级指南
|
||
### 1. 做好数据备份
|
||
|
||
### 2. 更新镜像 tag
|
||
|
||
- 更新 FastGPT 镜像 tag: v4.9.5
|
||
- 更新 FastGPT 商业版镜像 tag: v4.9.5
|
||
- Sandbox 无需更新
|
||
- AIProxy 无需更新
|
||
|
||
## 🚀 新增内容
|
||
|
||
1. 团队成员权限细分,可分别控制是否可创建在根目录应用/知识库以及 API Key
|
||
2. 支持交互节点在嵌套工作流中使用。
|
||
3. 团队成员操作日志。
|
||
4. 用户输入节点支持多选框。
|
||
|
||
## ⚙️ 优化
|
||
|
||
1. 繁体中文翻译。
|
||
2. Arm 镜像打包
|
||
|
||
|
||
## 🐛 修复
|
||
|
||
1. password 检测规则错误。
|
||
2. 分享链接无法隐藏知识库检索结果。
|
||
3. IOS 低版本正则兼容问题。
|
||
4. 修复问答提取队列错误后,计数器未清零问题,导致问答提取队列失效。
|
||
5. Debug 模式交互节点下一步可能造成死循环。
|
||
|
||
# V4.9.6(进行中)
|
||
## FastGPT V4.9.6 更新说明
|
||
|
||
## 🚀 新增内容
|
||
|
||
1. 以 MCP 方式对外提供应用调用。
|
||
2. 支持以 MCP SSE 协议创建工具。
|
||
3. 批量执行节点支持交互节点,可实现每一轮循环都人工参与。
|
||
4. 增加工作台二级菜单,合并工具箱。
|
||
5. 增加 grok3、GPT4.1、o系列、Gemini2.5 模型系统配置。
|
||
|
||
## ⚙️ 优化
|
||
|
||
1. 工作流数据类型转化鲁棒性和兼容性增强。
|
||
2. Python sandbox 代码,支持大数据输入。
|
||
3. 路径组件支持配置最后一步是否可点击。
|
||
4. 知识库工具调用结果,自动补充图片域名。
|
||
5. Github action runner 升级成 unbuntu24
|
||
6. 去除飞书、公众号等三方渠道,回复时,可能前后多一个换行的问题。
|
||
|
||
## 🐛 修复
|
||
|
||
1. 修复子工作流包含交互节点时,未成功恢复子工作流所有数据。
|
||
2. completion v1 接口,未接受 interactive 参数,导致 API 调用失败。
|
||
3. 连续工具调用,上下文截断异常
|
||
|
||
# 升级说明
|
||
## FastGPT 升级说明
|
||
|
||
FastGPT 升级包括两个步骤:
|
||
|
||
1. 镜像升级
|
||
2. 执行升级初始化脚本
|
||
|
||
|
||
|
||
## 镜像名
|
||
|
||
**git版**
|
||
- FastGPT 主镜像:ghcr.io/labring/fastgpt:latest
|
||
- 商业版镜像:ghcr.io/c121914yu/fastgpt-pro:latest
|
||
- Admin 镜像:ghcr.io/c121914yu/fastgpt-admin:latest
|
||
|
||
**阿里云**
|
||
- FastGPT 主镜像: registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt
|
||
- 商业版镜像:ghcr:registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt-pro
|
||
- Admin 镜像: registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt-admin
|
||
|
||
镜像由镜像名和`Tag`组成,例如: registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt:v4.6.1 代表`4.6.3`版本镜像,具体可以看 docker hub, github 仓库。
|
||
|
||
## Sealos 修改镜像
|
||
|
||
1. 打开 [Sealos Cloud](https://cloud.sealos.io?uid=fnWRt09fZP), 找到桌面上的应用管理
|
||
|
||

|
||
|
||
2. 选择对应的应用 - 点击右边三个点 - 变更
|
||
|
||

|
||
|
||
3. 修改镜像 - 确认变更
|
||
|
||
如果要修改配置文件,可以拉到下面的`配置文件`进行修改。
|
||
|
||

|
||
|
||
## Docker-Compose 修改镜像
|
||
|
||
直接修改`yml`文件中的`image: `即可。随后执行:
|
||
|
||
```bash
|
||
docker-compose pull
|
||
docker-compose up -d
|
||
```
|
||
|
||
## 执行升级初始化脚本
|
||
|
||
镜像更新完后,可以查看文档中的`版本介绍`,通常需要执行升级脚本的版本都会标明`包含升级脚本`,打开对应的文档,参考说明执行**升级脚本**即可,大部分时候都是需要发送一个`POST`请求。
|
||
|
||
|
||
## QA
|
||
|
||
### 为什么需要执行升级脚本
|
||
|
||
数据表出现大幅度变更,无法通过设置默认值,或复杂度较高时,会通过升级脚本来更新部分数据表字段。
|
||
严格按初始化步骤进行操作,不会造成旧数据丢失。但在初始化过程中,如果数据量大,需要初始化的时间较长,这段时间可能会造成服务无法正常使用。
|
||
|
||
### {{host}} 是什么
|
||
|
||
{{}} 代表变量, {{host}}代表一个名为 host 的变量。指的是你服务器的域名或 IP。
|
||
|
||
Sealos 中,你可以在下图中找到你的域名:
|
||
|
||

|
||
|
||
|
||
### 如何获取 rootkey
|
||
|
||
从`docker-compose.yml`中的`environment`中获取,对应的是`ROOT_KEY`的值。
|
||
|
||
sealos 中可以从上图左侧的环境变量中获取。
|
||
|
||
### 如何跨版本升级!!
|
||
|
||
建议逐一版本升级,防止脏数据。例如,当前版本是4.4.7,需要升级到4.6。
|
||
|
||
1. 修改镜像到4.5,执行初始化
|
||
2. 修改镜像到4.5.1,执行初始化
|
||
3. 修改镜像到4.5.2,执行初始化
|
||
4. 修改镜像到4.6,执行初始化
|
||
5. .....
|
||
|
||
逐一升级
|
||
|
||
# 应用使用问题
|
||
## FastGPT 常见应用使用问题,包括简易应用、工作流和插件
|
||
|
||
## 多轮对话中如何使连续问题被问题分类节点正确的归类
|
||
|
||
问题分类节点具有获取上下文信息的能力,当处理两个关联性较大的问题时,模型的判断准确性往往依赖于这两个问题之间的联系和模型的能力。例如,当用户先问“我该如何使用这个功能?”接着又询问“这个功能有什么限制?”时,模型借助上下文信息,就能够更精准地理解并响应。
|
||
|
||
但是,当连续问题之间的关联性较小,模型判断的准确度可能会受到限制。在这种情况下,我们可以引入全局变量的概念来记录分类结果。在后续的问题分类阶段,首先检查全局变量是否存有分类结果。如果有,那么直接沿用该结果;若没有,则让模型自行判断。
|
||
|
||
建议:构建批量运行脚本进行测试,评估问题分类的准确性。
|
||
|
||
## 定时执行的时机问题
|
||
|
||
系统编排配置中的定时执行,如果用户打开分享的连接,停留在那个页面,定时执行触发问题:
|
||
|
||
定时执行会在应用发布后生效,会在后台生效。
|
||
|
||
## V4.8.18-FIX2中提到“ 1. 修复 HTTP 节点, {{}} 格式引用变量兼容问题。建议尽快替换 / 模式取变量, {{}} 语法已弃用。”替换{{}}引用格式是仅仅只有在http节点,还是所有节点的都会有影响?
|
||
|
||
只有 http 节点用到这个语法。
|
||
|
||
## 工作流类型的应用在运行预览可以正常提问返回,但是发布免登录窗口之后有问题。
|
||
|
||
一般是没正确发布,在工作流右上角点击【保存并发布】。
|
||
|
||
## 如何解决猜你想问使用中文回答显示
|
||
|
||
注意需要更新到V4.8.17及以上,把猜你想问的提示词改成中文。
|
||

|
||
|
||
## AI对话回答要求中的Markdown语法取消
|
||
|
||
修改知识库默认提示词, 默认用的是标准模板提示词,会要求按 Markdown 输出,可以去除该要求:
|
||
|
||
| | |
|
||
| --- | --- |
|
||
|  |  |
|
||
|
||
## 应用在不同来源效果不一致
|
||
|
||
Q: 应用在调试和正式发布后,效果不一致;在 API 调用时,效果不一致。
|
||
|
||
A: 通常是由于上下文不一致导致,可以在对话日志中,找到对应的记录,并查看运行详情来进行比对。
|
||
|
||
| | | |
|
||
| --- | --- | --- |
|
||
|  |  |  |
|
||
在针对知识库的回答要求里有, 要给它配置提示词,不然他就是默认的,默认的里面就有该语法。
|
||
|
||
## 工作流操作:一个工作流,以一个问题分类节点开始,根据不同的分类导入到不同的分支,访问相应的知识库和AI对话,AI对话返回内容后,怎么样不进入问题分类节点,而是将问题到知识库搜索,然后把历史记录一起作为背景再次AI查询。
|
||
|
||
做个判断器,如果是初次开始对话也就是历史记录为0,就走问题分类;不为零直接走知识库和ai。
|
||
|
||
## 实时对话,设置 fastgpt 定时,比如每隔 3000MS 去拿一次 webhook发送过来的消息到AI页面
|
||
|
||
定时执行没有这么高频率的去拿信息的,想要实现在企微里面的实时对话的机器人,
|
||
目前通过低代码的工作流构建应该是不行的,只能自己写代码,然后去调用 FastGPT 的 APIKey 回复。企业微信似乎没有提供「自动监听」群聊消息的接口(或是通过 at 机器人这种触发消息推送)。应该只能发消息给应用,接收这个 https://developer.work.weixin.qq.com/document/path/90238 文档中的消息推送实现实时对话。或者是定时去拿群聊消息,通过这个文档所示的接口https://developer.work.weixin.qq.com/document/path/98914,然后用这个接口 https://developer.work.weixin.qq.com/document/path/90248 去推送消息。
|
||
|
||
## 工作流连接数据库
|
||
|
||
工作流提供该连接数据库功能,用这个数据库连接的 plugin 可以实现 text2SQL,但是相对危险,不建议做写入等操作。
|
||
|
||

|
||
|
||
## 关于循环体,协助理解循环体的循环条件和终止条件、循环的方式,循环体内参数调用后、在循环体内属于是局部作用域的参数还是全局作用域的参数
|
||
|
||
可理解为 for 函数,传一个数组,每个数据都执行一次。
|
||
|
||
## 公式无法正常显示
|
||
|
||
添加相关提示词,引导模型按 Markdown 输出公式
|
||
|
||
```bash
|
||
Latex inline: \(x^2\)
|
||
Latex block: $$e=mc^2$$
|
||
```
|
||
|
||
# 聊天框问题
|
||
## FastGPT 常见聊天框问题
|
||
|
||
## 我修改了工作台的应用,为什么在“聊天”时没有更新配置?
|
||
|
||
应用需要点击发布后,聊天才会更新应用。
|
||
|
||
## 浏览器不支持语音输入
|
||
|
||
1. 首先需要确保浏览器、电脑本身麦克风权限的开启。
|
||
2. 确认浏览器允许该站点使用麦克风,并且选择正确的麦克风来源。
|
||
3. 需有 SSL 证书的站点才可以使用麦克风。
|
||
|
||
# 知识库使用问题
|
||
## 常见知识库使用问题
|
||
|
||
## 上传的文件内容出现中文乱码
|
||
|
||
将文件另存为 UTF-8 编码格式。
|
||
|
||
## 知识库配置里的文件处理模型是什么?与索引模型有什么区别?
|
||
|
||
* **文件处理模型**:用于数据处理的【增强处理】和【问答拆分】。在【增强处理】中,生成相关问题和摘要,在【问答拆分】中执行问答对生成。
|
||
* **索引模型**:用于向量化,即通过对文本数据进行处理和组织,构建出一个能够快速查询的数据结构。
|
||
|
||
## 知识库支持Excel类文件的导入
|
||
|
||
xlsx等都可以上传的,不止支持CSV。
|
||
|
||
## 知识库tokens的计算方式
|
||
|
||
统一按gpt3.5标准。
|
||
|
||
## 误删除重排模型后,重排模型怎么加入到fastgpt
|
||
|
||

|
||
|
||
config.json文件里面配置后就可以勾选重排模型
|
||
|
||
## 线上平台上创建了应用和知识库,到期之后如果短期内不续费,数据是否会被清理。
|
||
|
||
免费版是三十天不登录后清空知识库,应用不会动。其他付费套餐到期后自动切免费版。
|
||

|
||
|
||
## 基于知识库的查询,但是问题相关的答案过多。ai回答到一半就不继续回答。
|
||
|
||
FastGPT回复长度计算公式:
|
||
|
||
最大回复=min(配置的最大回复(内置的限制),最大上下文(输入和输出的总和)-历史记录)
|
||
|
||
18K模型->输入与输出的和
|
||
|
||
输出增多->输入减小
|
||
|
||
所以可以:
|
||
|
||
1. 检查配置的最大回复(回复上限)
|
||
2. 减小输入来增大输出,即减小历史记录,在工作流其实也就是“聊天记录”
|
||
|
||
配置的最大回复:
|
||
|
||

|
||
|
||

|
||
|
||
另外私有化部署的时候,后台配模型参数,可以在配置最大上文时,预留一些空间,比如 128000 的模型,可以只配置 120000, 剩余的空间后续会被安排给输出
|
||
|
||
|
||
## 受到模型上下文的限制,有时候达不到聊天记录的轮次,连续对话字数过多就会报上下文不够的错误。
|
||
|
||
FastGPT回复长度计算公式:
|
||
|
||
最大回复=min(配置的最大回复(内置的限制),最大上下文(输入和输出的总和)-历史记录)
|
||
|
||
18K模型->输入与输出的和
|
||
|
||
输出增多->输入减小
|
||
|
||
所以可以:
|
||
|
||
1. 检查配置的最大回复(回复上限)
|
||
2. 减小输入来增大输出,即减小历史记录,在工作流其实也就是“聊天记录”
|
||
|
||
配置的最大回复:
|
||
|
||

|
||
|
||

|
||
|
||
另外,私有化部署的时候,后台配模型参数,可以在配置最大上文时,预留一些空间,比如 128000 的模型,可以只配置 120000, 剩余的空间后续会被安排给输出。
|
||
|
||
# Docker 部署问题
|
||
## FastGPT Docker 部署问题
|
||
|
||
|
||
|
||
# 报错
|
||
##
|
||
|
||
1. ### 当前分组上游负载已饱和,请稍后再试(request id:202407100753411462086782835521)
|
||
|
||
是oneapi渠道的问题,可以换个模型用or换一家中转站
|
||
|
||
1. ### 使用API时在日志中报错Connection Error
|
||
|
||
大概率是api-key填写了openapi,然后部署的服务器在国内,不能访问海外的api,可以使用中转或者反代的手段解决访问不到的问题
|
||
|
||
# 接入外部渠道
|
||
## 如何通过外部渠道与 FastGPT 集成,实现对多种平台的支持
|
||
|
||
1. ### 接入cow,图文对话无法直接显示图片
|
||
|
||
提示词给引导,不要以markdown格式输出。图片需要二开 cow 实现图片链接截取并发送。
|
||
|
||
1. ### 可以获取到用户发送问答的记录吗
|
||
|
||
在应用的对话日志里可以查看。
|
||
|
||

|
||
|
||
# 其他问题
|
||
##
|
||
|
||
## oneapi 官网是哪个
|
||
|
||
只有开源的 README,没官网,GitHub: https://github.com/songquanpeng/one-api
|
||
|
||
## 想做多用户
|
||
|
||
开源版未支持多用户,仅商业版支持。
|
||
|
||
# 积分消耗
|
||
## 了解 FastGPT 中的积分消耗机制和使用场景
|
||
|
||
1. ### 接入oneapi后,为什么还会消耗fastgpt的积分
|
||
|
||
矢量数据库检索会默认消耗。可以查看看绑定提示和使用记录。
|
||
|
||

|
||
|
||
# 私有部署常见问题
|
||
## FastGPT 私有部署常见问题
|
||
|
||
|
||
|
||
# 对话框与HTML渲染
|
||
## 如何在FastGPT中通过Markdown嵌入HTML代码块,并提供全屏、源代码切换等交互功能
|
||
|
||
| 源码模式 | 预览模式 | 全屏模式 |
|
||
| --- | --- | --- |
|
||
|  |  |  |
|
||
|
||
|
||
### 1. **设计背景**
|
||
|
||
尽管Markdown本身支持嵌入HTML标签,但由于安全问题,许多平台和环境对HTML的渲染进行了限制,特别是在渲染动态内容、交互式元素以及外部资源时。这些限制大大降低了用户在撰写和展示复杂文档时的灵活性,尤其是当需要嵌入外部HTML内容时。为了应对这一问题,我们通过使用 `iframe` 来嵌入和渲染HTML内容,并结合 `sandbox` 属性,保障了外部HTML的安全渲染。
|
||
|
||
### 2. 功能简介
|
||
|
||
该功能模块的主要目的是扩展FastGPT在Markdown渲染中的能力,支持嵌入和渲染HTML内容。由于是利用 Iframe 渲染,所以无法确认内容的高度,FastGPT 中会给 Iframe 设置一个固定高度来进行渲染。并且不支持 HTML 中执行 js 脚本。
|
||
|
||
### 3. 技术实现
|
||
|
||
本模块通过以下方式实现了HTML渲染和互动功能:
|
||
|
||
- **组件设计**:该模块通过渲染 `iframe` 类型的代码块展示HTML内容。使用自定义的 `IframeBlock` 组件,结合 `sandbox` 属性来保障嵌入内容的安全性。`sandbox` 限制了外部HTML中的行为,如禁用脚本执行、限制表单提交等,确保HTML内容的安全性。通过辅助函数与渲染Markdown内容的部分结合,处理 `iframe` 嵌入的HTML内容。
|
||
- **安全机制**:通过 `iframe` 的 `sandbox` 属性和 `referrerPolicy` 来防止潜在的安全风险。`sandbox` 属性提供了细粒度的控制,允许特定的功能(如脚本、表单、弹出窗口等)在受限的环境中执行,以确保渲染的HTML内容不会对系统造成威胁。
|
||
- **展示与互动功能**:用户可以通过不同的展示模式(如全屏、预览、源代码模式)自由切换,以便更灵活地查看和控制嵌入的HTML内容。嵌入的 `iframe` 自适应父容器的宽度,同时保证 `iframe`嵌入的内容能够适当显示。
|
||
|
||
### 4. 如何使用
|
||
|
||
你只需要通过 Markdown 代码块格式,并标记语言为 `html` 即可。例如:
|
||
|
||
```md
|
||
```html
|
||
<!DOCTYPE html>
|
||
<html lang="zh-CN">
|
||
<head>
|
||
<meta charset="UTF-8">
|
||
<meta name="viewport" content="width=device-width, initial-scale=1.0">
|
||
<meta http-equiv="X-UA-Compatible" content="ie=edge">
|
||
<title>欢迎使用FastGPT</title>
|
||
</head>
|
||
<body>
|
||
<nav>
|
||
<ul>
|
||
<li><a href="#home">首页</a></li>
|
||
<li><a href="#about">关于我们</a></li>
|
||
<li><a href="#contact">联系我们</a></li>
|
||
<li><a href="#gallery">图库</a></li>
|
||
</ul>
|
||
</nav>
|
||
</body>
|
||
</html>
|
||
|
||
```
|
||
|
||
# 知识库引用分块阅读器
|
||
## FastGPT 分块阅读器功能介绍
|
||
|
||
在企业 AI 应用落地过程中,文档知识引用的精确性和透明度一直是用户关注的焦点。FastGPT 4.9.1 版本带来的知识库分块阅读器,巧妙解决了这一痛点,让 AI 引用不再是"黑盒"。
|
||
|
||
# 为什么需要分块阅读器?
|
||
|
||
传统的 AI 对话中,当模型引用企业知识库内容时,用户往往只能看到被引用的片段,无法获取完整语境,这给内容验证和深入理解带来了挑战。分块阅读器的出现,让用户可以在对话中直接查看引用内容的完整文档,并精确定位到引用位置,实现了引用的"可解释性"。
|
||
|
||
## 传统引用体验的局限
|
||
|
||
以往在知识库中上传文稿后,当我们在工作流中输入问题时,传统的引用方式只会展示引用到的分块,无法确认分块在文章中的上下文:
|
||
|
||
| 问题 | 引用 |
|
||
| --- | --- |
|
||
|  |  |
|
||
|
||
## FastGPT 分块阅读器:精准定位,无缝阅读
|
||
|
||
而在 FastGPT 全新的分块式阅读器中,同样的知识库内容和问题,呈现方式发生了质的飞跃
|
||
|
||

|
||
|
||
当 AI 引用知识库内容时,用户只需点击引用链接,即可打开一个浮窗,呈现完整的原文内容,并通过醒目的高亮标记精确显示引用的文本片段。这既保证了回答的可溯源性,又提供了便捷的原文查阅体验。
|
||
|
||
# 核心功能
|
||
|
||
## 全文展示与定位
|
||
|
||
"分块阅读器" 让用户能直观查看AI回答引用的知识来源。
|
||
|
||
在对话界面中,当 AI 引用了知识库内容,系统会在回复下方展示出处信息。用户只需点击这些引用链接,即可打开一个优雅的浮窗,呈现完整的原文内容,并通过醒目的高亮标记精确显示 AI 引用的文本片段。
|
||
|
||
这一设计既保证了回答的可溯源性,又提供了便捷的原文查阅体验,让用户能轻松验证AI回答的准确性和相关上下文。
|
||
|
||

|
||
|
||
|
||
## 便捷引用导航
|
||
|
||
分块阅读器右上角设计了简洁实用的导航控制,用户可以通过这对按钮轻松在多个引用间切换浏览。导航区还直观显示当前查看的引用序号及总引用数量(如 "7/10"),帮助用户随时了解浏览进度和引用内容的整体规模。
|
||
|
||

|
||
|
||
## 引用质量评分
|
||
|
||
每条引用内容旁边都配有智能评分标签,直观展示该引用在所有知识片段中的相关性排名。用户只需将鼠标悬停在评分标签上,即可查看完整的评分详情,了解这段引用内容为何被AI选中以及其相关性的具体构成。
|
||
|
||

|
||
|
||
|
||
## 文档内容一键导出
|
||
|
||
分块阅读器贴心配备了内容导出功能,让有效信息不再流失。只要用户拥有相应知识库的阅读权限,便可通过简单点击将引用涉及的全文直接保存到本地设备。
|
||
|
||

|
||
|
||
# 进阶特性
|
||
|
||
## 灵活的可见度控制
|
||
|
||
FastGPT提供灵活的引用可见度设置,让知识共享既开放又安全。以免登录链接为例,管理员可精确控制外部访问者能看到的信息范围。
|
||
|
||
当设置为"仅引用内容可见"时,外部用户点击引用链接将只能查看 AI 引用的特定文本片段,而非完整原文档。如图所示,分块阅读器此时智能调整显示模式,仅呈现相关引用内容。
|
||
|
||
| | |
|
||
| --- | --- |
|
||
|  |  |
|
||
|
||
## 即时标注优化
|
||
|
||
在浏览过程中,授权用户可以直接对引用内容进行即时标注和修正,系统会智能处理这些更新而不打断当前的对话体验。所有修改过的内容会通过醒目的"已更新"标签清晰标识,既保证了引用的准确性,又维持了对话历史的完整性。
|
||
|
||
这一无缝的知识优化流程特别适合团队协作场景,让知识库能在实际使用过程中持续进化,确保AI回答始终基于最新、最准确的信息源。
|
||
|
||
## 智能文档性能优化
|
||
|
||
面对现实业务中可能包含成千上万分块的超长文档,FastGPT采用了先进的性能优化策略,确保分块阅读器始终保持流畅响应。
|
||
|
||
系统根据引用相关性排序和数据库索引进行智能加载管理,实现了"按需渲染"机制——根据索引排序和数据库 id,只有当用户实际需要查看的内容才会被加载到内存中。这意味着无论是快速跳转到特定引用,还是自然滚动浏览文档,都能获得丝滑的用户体验,不会因为文档体积庞大而出现卡顿或延迟。
|
||
|
||
这一技术优化使FastGPT能够轻松应对企业级的大规模知识库场景,让即使是包含海量信息的专业文档也能高效展示和查阅。
|
||
|
||
# SSO & 外部成员同步
|
||
## FastGPT 外部成员系统接入设计与配置
|
||
|
||
如果你不需要用到 SSO/成员同步功能,或者是只需要用 Github、google、microsoft、公众号的快速登录,可以跳过本章节。本章适合需要接入自己的成员系统或主流 办公IM 的用户。
|
||
|
||
## 介绍
|
||
|
||
为了方便地接入**外部成员系统**,FastGPT 提供一套接入外部系统的**标准接口**,以及一个 FastGPT-SSO-Service 镜像作为**适配器**。
|
||
|
||
通过这套标注接口,你可以可以实现:
|
||
|
||
1. SSO 登录。从外部系统回调后,在 FastGPT 中创建一个用户。
|
||
2. 成员和组织架构同步(下面都简称成员同步)。
|
||
|
||
**原理**
|
||
|
||
FastGPT-pro 中,有一套标准的SSO 和成员同步接口,系统会根据这套接口进行 SSO 和成员同步操作。
|
||
|
||
FastGPT-SSO-Service 是为了聚合不同来源的 SSO 和成员同步接口,将他们转成 fastgpt-pro 可识别的接口。
|
||
|
||

|
||
|
||
## 系统配置教程
|
||
|
||
### 1. 部署 SSO-service 镜像
|
||
|
||
使用 docker-compose 部署:
|
||
|
||
```yaml
|
||
fastgpt-sso:
|
||
image: registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt-sso-service:v4.9.0
|
||
container_name: fastgpt-sso
|
||
restart: always
|
||
networks:
|
||
- fastgpt
|
||
environment:
|
||
- SSO_PROVIDER=example
|
||
- AUTH_TOKEN=xxxxx # 鉴权信息,fastgpt-pro 会用到。
|
||
# 具体对接提供商的环境变量。
|
||
```
|
||
|
||
根据不同的提供商,你需要配置不同的环境变量,下面是内置的通用协议/IM:
|
||
|
||
{{< table "table-hover table-striped-columns" >}}
|
||
| 协议/功能 | SSO | 成员同步支持 |
|
||
|----------------|----------|--------------|
|
||
| 飞书 | 是 | 是 |
|
||
| 企业微信 | 是 | 是 |
|
||
| 钉钉 | 是 | 否 |
|
||
| Saml2.0 | 是 | 否 |
|
||
| Oauth2.0 | 是 | 否 |
|
||
{{< /table >}}
|
||
|
||
### 2. 配置 fastgpt-pro
|
||
|
||
#### 1. 配置环境变量
|
||
|
||
环境变量中的 `EXTERNAL_USER_SYSTEM_BASE_URL` 为内网地址,例如上述例子中的配置,环境变量应该设置为
|
||
|
||
```yaml
|
||
env:
|
||
- EXTERNAL_USER_SYSTEM_BASE_URL=http://fastgpt-sso:3000
|
||
- EXTERNAL_USER_SYSTEM_AUTH_TOKEN=xxxxx
|
||
```
|
||
|
||
#### 2. 在商业版后台配置按钮文字,图标等。
|
||
|
||
{{< table "table-hover table-striped-columns" >}}
|
||
| <div style="text-align:center">企业微信</div> | <div style="text-align:center">钉钉</div> | <div style="text-align:center">飞书</div> |
|
||
|-----------|-----------------|--------------|
|
||
|  |  |  |
|
||
{{< /table >}}
|
||
|
||
#### 3. 开启成员同步(可选)
|
||
|
||
如果需要同步外部系统的成员,可以选择开启成员同步。团队模式具体可参考:[团队模式说明文档](/docs/guide/admin/teamMode)
|
||
|
||

|
||
|
||
#### 4. 可选配置
|
||
|
||
1. 自动定时成员同步
|
||
|
||
设置 fastgpt-pro 环境变量则可开启自动成员同步
|
||
|
||
```bash
|
||
env:
|
||
- "SYNC_MEMBER_CRON=0 0 * * *" # Cron 表达式,每天 0 点执行
|
||
```
|
||
|
||
## 内置的通用协议/IM 配置示例
|
||
|
||
### 飞书
|
||
|
||
#### 1. 参数获取
|
||
|
||
App ID和App Secret
|
||
|
||
进入开发者后台,点击企业自建应用,在凭证与基础信息页面查看应用凭证。
|
||
|
||

|
||
|
||
#### 2. 权限配置
|
||
|
||
进入开发者后台,点击企业自建应用,在开发配置的权限管理页面开通权限。
|
||
|
||

|
||
|
||
对于开通用户SSO登录而言,开启用户身份权限的以下内容
|
||
|
||
1. ***获取通讯录基本信息***
|
||
2. ***获取用户基本信息***
|
||
3. ***获取用户邮箱信息***
|
||
4. ***获取用户 user ID***
|
||
|
||
对于开启企业同步相关内容而言,开启身份权限的内容与上面一致,但要注意是开启应用权限
|
||
|
||
#### 3. 重定向URL
|
||
|
||
进入开发者后台,点击企业自建应用,在开发配置的安全设置中设置重定向URL
|
||

|
||
|
||
#### 4. yml 配置示例
|
||
|
||
```bash
|
||
fastgpt-sso:
|
||
image: registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt-sso-service:v4.9.0
|
||
container_name: fastgpt-sso
|
||
restart: always
|
||
networks:
|
||
- fastgpt
|
||
environment:
|
||
- SSO_PROVIDER=example
|
||
- AUTH_TOKEN=xxxxx
|
||
# 飞书 - feishu -如果是私有化部署,这里的配置前缀可能会有变化
|
||
- SSO_PROVIDER=feishu
|
||
# oauth 接口(公开的飞书不用改)
|
||
- SSO_TARGET_URL=https://accounts.feishu.cn/open-apis/authen/v1/authorize
|
||
# 获取token 接口(公开的飞书不用改)
|
||
- FEISHU_TOKEN_URL=https://open.feishu.cn/open-apis/authen/v2/oauth/token
|
||
# 获取用户信息接口(公开的飞书不用改)
|
||
- FEISHU_GET_USER_INFO_URL=https://open.feishu.cn/open-apis/authen/v1/user_info
|
||
# 重定向地址,因为飞书获取用户信息要校验所以需要填
|
||
- FEISHU_REDIRECT_URI=xxx
|
||
#飞书APP的应用ID,一般以cli开头
|
||
- FEISHU_APP_ID=xxx
|
||
#飞书APP的应用密钥
|
||
- FEISHU_APP_SECRET=xxx
|
||
```
|
||
|
||
### 钉钉
|
||
|
||
#### 1. 参数获取
|
||
|
||
CLIENT_ID 与 CLIENT_SECRET
|
||
|
||
进入钉钉开放平台,点击应用开发,选择自己的应用进入,记录在凭证与基础信息页面下的Client ID与Client secret。
|
||

|
||
|
||
#### 2. 权限配置
|
||
|
||
进入钉钉开放平台,点击应用开发,选择自己的应用进入,在开发配置的权限管理页面操作,需要开通的权限包括:
|
||
|
||
1. ***个人手机号信息***
|
||
2. ***通讯录个人信息读权限***
|
||
3. ***获取钉钉开放接口用户访问凭证的基础权限***
|
||
|
||
#### 3. 重定向URL
|
||
|
||
进入钉钉开放平台,点击应用开发,选择自己的应用进入,在开发配置的安全设置页面操作
|
||
需要填写的内容有两个:
|
||
|
||
1. 服务器出口IP (调用钉钉服务端API的服务器IP列表)
|
||
2. 重定向URL(回调域名)
|
||
|
||
#### 4. yml 配置示例
|
||
|
||
```bash
|
||
fastgpt-sso:
|
||
image: registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt-sso-service:v4.9.0
|
||
container_name: fastgpt-sso
|
||
restart: always
|
||
networks:
|
||
- fastgpt
|
||
environment:
|
||
- SSO_PROVIDER=dingtalk
|
||
- AUTH_TOKEN=xxxxx
|
||
#oauth 接口
|
||
- SSO_TARGET_URL=https://login.dingtalk.com/oauth2/auth
|
||
#获取token 接口
|
||
- DINGTALK_TOKEN_URL=https://api.dingtalk.com/v1.0/oauth2/userAccessToken
|
||
#获取用户信息接口
|
||
- DINGTALK_GET_USER_INFO_URL=https://oapi.dingtalk.com/v1.0/contact/users/me
|
||
#钉钉APP的应用ID
|
||
- DINGTALK_CLIENT_ID=xxx
|
||
#钉钉APP的应用密钥
|
||
- DINGTALK_CLIENT_SECRET=xxx
|
||
```
|
||
|
||
### 企业微信
|
||
|
||
#### 1. 参数获取
|
||
|
||
1. 企业的 CorpID
|
||
|
||
a. 使用管理员账号登陆企业微信管理后台 `https://work.weixin.qq.com/wework_admin/loginpage_wx`
|
||
|
||
b. 点击 【我的企业】 页面,查看企业的 **企业ID**
|
||
|
||

|
||
|
||
2. 创建一个供 FastGPT 使用的内部应用:
|
||
|
||
a. 获取应用的 AgentID 和 Secret
|
||
|
||
b. 保证这个应用的可见范围为全部(也就是根部门)
|
||
|
||

|
||
|
||
|
||

|
||
|
||
3. 一个域名。并且要求:
|
||
|
||
a. 解析到可公网访问的服务器上
|
||
|
||
b. 可以在该服务的根目录地址上挂载静态文件(以便进行域名归属认证 ,按照配置处的提示进行操作,只需要挂载一个静态文件,认证后可以删除)
|
||
|
||
c. 配置网页授权,JS-SDK以及企业微信授权登陆
|
||
|
||
d. 可以在【企业微信授权登陆】页面下方设置“在工作台隐藏应用”
|
||
|
||

|
||
|
||

|
||
|
||

|
||
|
||
4. 获取 “通讯录同步助手” secret
|
||
|
||
获取通讯录,组织成员 ID 需要使用 “通讯录同步助手” secret
|
||
|
||
【安全与管理】-- 【管理工具】 -- 【通讯录同步】
|
||
|
||

|
||
|
||
5. 开启接口同步
|
||
|
||
6. 获取 Secret
|
||
|
||
7. 配置企业可信 IP
|
||
|
||

|
||
|
||
#### 2. yml 配置示例
|
||
|
||
```bash
|
||
fastgpt-sso:
|
||
image: registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt-sso-service:v4.9.0
|
||
container_name: fastgpt-sso
|
||
restart: always
|
||
networks:
|
||
- fastgpt
|
||
environment:
|
||
- AUTH_TOKEN=xxxxx
|
||
- SSO_PROVIDER=wecom
|
||
# oauth 接口,在企微终端使用
|
||
- WECOM_TARGET_URL_OAUTH=https://open.weixin.qq.com/connect/oauth2/authorize
|
||
# sso 接口,扫码
|
||
- WECOM_TARGET_URL_SSO=https://login.work.weixin.qq.com/wwlogin/sso/login
|
||
# 获取用户id(只能拿id)
|
||
- WECOM_GET_USER_ID_URL=https://qyapi.weixin.qq.com/cgi-bin/auth/getuserinfo
|
||
# 获取用户详细信息(除了名字都有)
|
||
- WECOM_GET_USER_INFO_URL=https://qyapi.weixin.qq.com/cgi-bin/auth/getuserdetail
|
||
# 获取用户信息(有名字,没其他信息)
|
||
- WECOM_GET_USER_NAME_URL=https://qyapi.weixin.qq.com/cgi-bin/user/get
|
||
# 获取组织 id 列表
|
||
- WECOM_GET_DEPARTMENT_LIST_URL=https://qyapi.weixin.qq.com/cgi-bin/department/list
|
||
# 获取用户 id 列表
|
||
- WECOM_GET_USER_LIST_URL=https://qyapi.weixin.qq.com/cgi-bin/user/list_id
|
||
# 企微 CorpId
|
||
- WECOM_CORPID=
|
||
# 企微 App 的 AgentId 一般是 1000xxx
|
||
- WECOM_AGENTID=
|
||
# 企微 App 的 Secret
|
||
- WECOM_APP_SECRET=
|
||
# 通讯录同步助手的 Secret
|
||
- WECOM_SYNC_SECRET=
|
||
```
|
||
|
||
### 标准 OAuth2.0
|
||
|
||
#### 参数需求
|
||
|
||
我们提供一套标准的 OAuth2.0 接入流程。需要三个地址:
|
||
|
||
1. 登陆鉴权地址(登陆后将 code 传入 redirect_uri)
|
||
- 需要将地址完整写好,除了 redirect_uri 以外(会自动补全)
|
||
2. 获取 access_token 的地址,请求为 GET 方法,参数 code
|
||
|
||
```bash
|
||
http://example.com/oauth/access_token?code=xxxx
|
||
```
|
||
|
||
3. 获取用户信息的地址
|
||
|
||
```bash
|
||
http://example.com/oauth/user_info
|
||
|
||
```
|
||
|
||
#### 配置示例
|
||
|
||
```bash
|
||
fastgpt-sso:
|
||
image: registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt-sso-service:v4.9.0
|
||
container_name: fastgpt-sso
|
||
restart: always
|
||
networks:
|
||
- fastgpt
|
||
environment:
|
||
# OAuth2.0
|
||
- AUTH_TOKEN=xxxxx
|
||
- SSO_PROVIDER=oauth2
|
||
# OAuth2 重定向地址
|
||
- OAUTH2_AUTHORIZE_URL=
|
||
# OAuth2 获取 AccessToken 地址
|
||
- OAUTH2_TOKEN_URL=
|
||
# OAuth2 获取用户信息地址
|
||
- OAUTH2_USER_INFO_URL=
|
||
# OAuth2 用户名字段映射(必填)
|
||
- OAUTH2_USERNAME_MAP=
|
||
# OAuth2 头像字段映射(选填)
|
||
- OAUTH2_AVATAR_MAP=
|
||
# OAuth2 成员名字段映射(选填)
|
||
- OAUTH2_MEMBER_NAME_MAP=
|
||
# OAuth2 联系方式字段映射(选填)
|
||
- OAUTH2_CONTACT_MAP=
|
||
```
|
||
|
||
## 标准接口文档
|
||
|
||
以下是 FastGPT-pro 中,SSO 和成员同步的标准接口文档,如果需要对接非标准系统,可以参考该章节进行开发。
|
||
|
||

|
||
|
||
FastGPT 提供如下标准接口支持:
|
||
|
||
1. https://example.com/login/oauth/getAuthURL 获取鉴权重定向地址
|
||
2. https://example.com/login/oauth/getUserInfo?code=xxxxx 消费 code,换取用户信息
|
||
3. https://example.com/org/list 获取组织列表
|
||
4. https://example.com/user/list 获取成员列表
|
||
|
||
### 获取 SSO 登录重定向地址
|
||
|
||
返回一个重定向登录地址,fastgpt 会自动重定向到该地址。redirect_uri 会自动拼接到该地址的 query中。
|
||
|
||
{{< tabs tabTotal="2" >}}
|
||
{{< tab tabName="请求示例" >}}
|
||
{{< markdownify >}}
|
||
|
||
```bash
|
||
curl -X GET "https://redict.example/login/oauth/getAuthURL?redirect_uri=xxx&state=xxxx" \
|
||
-H "Authorization: Bearer your_token_here" \
|
||
-H "Content-Type: application/json"
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="响应示例" >}}
|
||
{{< markdownify >}}
|
||
|
||
成功:
|
||
|
||
```JSON
|
||
{
|
||
"success": true,
|
||
"message": "",
|
||
"authURL": "https://example.com/somepath/login/oauth?redirect_uri=https%3A%2F%2Ffastgpt.cn%2Flogin%2Fprovider%0A"
|
||
}
|
||
```
|
||
|
||
失败:
|
||
|
||
```JSON
|
||
{
|
||
"success": false,
|
||
"message": "错误信息",
|
||
"authURL": ""
|
||
}
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
{{< /tabs >}}
|
||
|
||
|
||
### SSO 获取用户信息
|
||
|
||
该接口接受一个 code 参数作为鉴权,消费 code 返回用户信息。
|
||
|
||
{{< tabs tabTotal="2" >}}
|
||
{{< tab tabName="请求示例" >}}
|
||
{{< markdownify >}}
|
||
|
||
```bash
|
||
curl -X GET "https://oauth.example/login/oauth/getUserInfo?code=xxxxxx" \
|
||
-H "Authorization: Bearer your_token_here" \
|
||
-H "Content-Type: application/json"
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="响应示例" >}}
|
||
{{< markdownify >}}
|
||
|
||
成功:
|
||
```JSON
|
||
{
|
||
"success": true,
|
||
"message": "",
|
||
"username": "fastgpt-123456789",
|
||
"avatar": "https://example.webp",
|
||
"contact": "+861234567890",
|
||
"memberName": "成员名(非必填)",
|
||
}
|
||
```
|
||
|
||
失败:
|
||
```JSON
|
||
{
|
||
"success": false,
|
||
"message": "错误信息",
|
||
"username": "",
|
||
"avatar": "",
|
||
"contact": ""
|
||
}
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
{{< /tabs >}}
|
||
|
||
### 获取组织
|
||
|
||
{{< tabs tabTotal="2" >}}
|
||
{{< tab tabName="请求示例" >}}
|
||
{{< markdownify >}}
|
||
|
||
```bash
|
||
curl -X GET "https://example.com/org/list" \
|
||
-H "Authorization: Bearer your_token_here" \
|
||
-H "Content-Type: application/json"
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="响应示例" >}}
|
||
{{< markdownify >}}
|
||
|
||
⚠️注意:只能存在一个根部门。如果你的系统中存在多个根部门,需要先进行处理,加一个虚拟的根部门。返回值类型:
|
||
|
||
```ts
|
||
type OrgListResponseType = {
|
||
message?: string; // 报错信息
|
||
success: boolean;
|
||
orgList: {
|
||
id: string; // 部门的唯一 id
|
||
name: string; // 名字
|
||
parentId: string; // parentId,如果为根部门,传空字符串。
|
||
}[];
|
||
}
|
||
```
|
||
|
||
```JSON
|
||
{
|
||
"success": true,
|
||
"message": "",
|
||
"orgList": [
|
||
{
|
||
"id": "od-125151515",
|
||
"name": "根部门",
|
||
"parentId": ""
|
||
},
|
||
{
|
||
"id": "od-51516152",
|
||
"name": "子部门",
|
||
"parentId": "od-125151515"
|
||
}
|
||
]
|
||
}
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
{{< /tabs >}}
|
||
|
||
|
||
### 获取成员
|
||
|
||
|
||
{{< tabs tabTotal="2" >}}
|
||
{{< tab tabName="请求示例" >}}
|
||
{{< markdownify >}}
|
||
|
||
```bash
|
||
curl -X GET "https://example.com/user/list" \
|
||
-H "Authorization: Bearer your_token_here" \
|
||
-H "Content-Type: application/json"
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="响应示例" >}}
|
||
{{< markdownify >}}
|
||
|
||
返回值类型:
|
||
|
||
```typescript
|
||
type UserListResponseListType = {
|
||
message?: string; // 报错信息
|
||
success: boolean;
|
||
userList: {
|
||
username: string; // 唯一 id username 必须与 SSO 接口返回的用户 username 相同。并且必须携带一个前缀,例如: sync-aaaaa,和 sso 接口返回的前缀一致
|
||
memberName?: string; // 名字,作为 tmbname
|
||
avatar?: string;
|
||
contact?: string; // email or phone number
|
||
orgs?: string[]; // 人员所在组织的 ID。没有组织传 []
|
||
}[];
|
||
}
|
||
```
|
||
curl示例
|
||
|
||
```JSON
|
||
{
|
||
"success": true,
|
||
"message": "",
|
||
"userList": [
|
||
{
|
||
"username": "fastgpt-123456789",
|
||
"memberName": "张三",
|
||
"avatar": "https://example.webp",
|
||
"contact": "+861234567890",
|
||
"orgs": ["od-125151515", "od-51516152"]
|
||
},
|
||
{
|
||
"username": "fastgpt-12345678999",
|
||
"memberName": "李四",
|
||
"avatar": "",
|
||
"contact": "",
|
||
"orgs": ["od-125151515"]
|
||
}
|
||
]
|
||
|
||
}
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
{{< /tabs >}}
|
||
|
||
|
||
|
||
|
||
## 如何对接非标准系统
|
||
|
||
1. 客户自己开发:按 fastgpt 提供的标准接口进行开发,并将部署后的服务地址填入 fastgpt-pro
|
||
可以参考该模版库:[fastgpt-sso-template](https://github.com/labring/fastgpt-sso-template) 进行开发
|
||
2. 由 fastgpt 团队定制开发:
|
||
a. 提供系统的 SSO 文档、获取成员和组织的文档、以及外网测试地址。
|
||
b. 在 fastgpt-sso-service 中,增加对应的 provider 和环境变量,并编写代码来对接。
|
||
|
||
# 团队模式说明文档
|
||
## FastGPT 团队模式说明文档
|
||
|
||
## 介绍
|
||
|
||
目前支持的团队模式:
|
||
|
||
1. 多团队模式(默认模式)
|
||
2. 单团队模式(全局只有一个团队)
|
||
3. 成员同步模式(所有成员自外部同步)
|
||
|
||
<table class="table-hover table-striped-columns" style="text-align: center;">
|
||
<tr>
|
||
<th rowspan="2">团队模式</th>
|
||
<th colspan="2">短信/邮箱 注册</th>
|
||
<th colspan="2">管理员直接添加</th>
|
||
<th colspan="2">SSO 注册</th>
|
||
</tr>
|
||
<tr>
|
||
<th>是否创建默认团队</th>
|
||
<th>是否加入 Root 团队</th>
|
||
<th>是否创建默认团队</th>
|
||
<th>是否加入 Root 团队</th>
|
||
<th>是否创建默认团队</th>
|
||
<th>是否加入 Root 团队</th>
|
||
</tr>
|
||
<tr>
|
||
<td>单团队模式</td>
|
||
<td>❌</td>
|
||
<td>✅</td>
|
||
<td>❌</td>
|
||
<td>✅</td>
|
||
<td>❌</td>
|
||
<td>✅</td>
|
||
</tr>
|
||
<tr>
|
||
<td>多团队模式</td>
|
||
<td>✅</td>
|
||
<td>❌</td>
|
||
<td>✅</td>
|
||
<td>❌</td>
|
||
<td>✅</td>
|
||
<td>❌</td>
|
||
</tr>
|
||
<tr>
|
||
<td>同步模式</td>
|
||
<td>❌</td>
|
||
<td>❌</td>
|
||
<td>❌</td>
|
||
<td>✅</td>
|
||
<td>❌</td>
|
||
<td>✅</td>
|
||
</tr>
|
||
</table>
|
||
|
||
### 多团队模式(默认模式)
|
||
|
||
多团队模式下,每个用户创建时默认创建以自己为所有者的默认团队。
|
||
|
||
### 单团队模式
|
||
|
||
单团队模式是 v4.9 推出的新功能。为了简化企业进行人员和资源的管理,开启单团队模式后,所有新增的用户都不再创建自己的默认团队,而是加入 root 用户所在的团队。
|
||
|
||
### 同步模式
|
||
|
||
在完成系统配置,开启同步模式的情况下,外部成员系统的成员会自动同步到 FastGPT 中。
|
||
|
||
具体的同步方式和规则请参考 [SSO & 外部成员同步](/docs/guide/admin/sso.md)。
|
||
|
||
|
||
## 配置
|
||
|
||
在 `fastgpt-pro` 的`系统配置-成员配置`中,可以配置团队模式。
|
||
|
||

|
||
|
||
# AI 相关参数配置说明
|
||
## FastGPT AI 相关参数配置说明
|
||
|
||
在 FastGPT 的 AI 对话模块中,有一个 AI 高级配置,里面包含了 AI 模型的参数配置,本文详细介绍这些配置的含义。
|
||
|
||
| | | |
|
||
| --- | --- | --- |
|
||
|  |  |  |
|
||
|
||
## 流响应(高级编排 AI 对话 特有)
|
||
|
||
旧版名字叫做:返回 AI 内容;新版改名:流响应。
|
||
|
||
这是一个开关,打开的时候,当 AI 对话模块运行时,会将其输出的内容返回到浏览器(API响应);
|
||
如果关闭,会强制使用非流模式调用模型,并且 AI 输出的内容不会返回到浏览器,但是生成的内容仍可以通过【AI回复】进行输出。你可以将【AI回复】连接到其他模块中进行二次使用。
|
||
|
||
### 最大上下文
|
||
|
||
代表模型最多容纳的文字数量。
|
||
|
||
### 函数调用
|
||
|
||
支持函数调用的模型,在使用工具时更加准确。
|
||
|
||
### 温度
|
||
|
||
越低回答越严谨,少废话(实测下来,感觉差别不大)
|
||
|
||
### 回复上限
|
||
|
||
最大回复 token 数量。注意,是回复的Tokens!不是上下文 tokens。
|
||
|
||
通常,回复上限=min(模型允许的最大回复上限, 最大上下文-已用上下文)
|
||
|
||
所以,一般配置模型时,不会把最大上下文配置成模型实际最大上下文,而是预留预定空间给回答,例如 128k 模型,可以配置 max_context=115000
|
||
|
||
### 系统提示词
|
||
|
||
被放置在上下文数组的最前面,role 为 system,用于引导模型。
|
||
|
||
### 记忆轮数(仅简易模式)
|
||
|
||
可以配置模型支持的记忆轮数,如果模型的超出上下文,系统会自动截断,尽可能保证不超模型上下文。
|
||
|
||
所以尽管配置 30 轮对话,实际运行时候,不一定会达到 30 轮。
|
||
|
||
## 引用模板 & 引用提示词
|
||
|
||
进行知识库搜索后,你可以自定义组织检索结果构成的提示词,这个配置,仅工作流中 AI 对话节点可用。并且,只会在有引用知识库内容时才会生效。
|
||
|
||

|
||
|
||
### AI 对话消息组成
|
||
|
||
想使用明白这两个变量,首先要了解传递传递给 AI 模型的消息格式。它是一个数组,FastGPT 中这个数组的组成形式为:
|
||
|
||
```json
|
||
[
|
||
内置提示词(config.json 配置,一般为空)
|
||
系统提示词 (用户输入的提示词)
|
||
历史记录
|
||
问题(由引用提示词、引用模板和用户问题组成)
|
||
]
|
||
```
|
||
|
||
{{% alert icon="🍅" context="success" %}}
|
||
Tips: 可以通过点击上下文按键查看完整的上下文组成,便于调试。
|
||
{{% /alert %}}
|
||
|
||
### 引用模板和提示词设计
|
||
|
||
简易模式已移除该功能,仅在工作流中可配置,可点击工作流中`AI对话节点`内,知识库引用旁边的`setting icon`进行配置。随着模型的增强,这部分功能将逐步弱化。
|
||
|
||
引用模板和引用提示词通常是成对出现,引用提示词依赖引用模板。
|
||
|
||
FastGPT 知识库采用 QA 对(不一定都是问答格式,仅代表两个变量)的格式存储,在转义成字符串时候会根据**引用模板**来进行格式化。知识库包含多个可用变量: q, a, sourceId(数据的ID), index(第n个数据), source(数据的集合名、文件名),score(距离得分,0-1) 可以通过 {{q}} {{a}} {{sourceId}} {{index}} {{source}} {{score}} 按需引入。下面一个模板例子:
|
||
|
||
可以通过 [知识库结构讲解](/docs/guide/knowledge_base/dataset_engine/) 了解详细的知识库的结构。
|
||
|
||
#### 引用模板
|
||
|
||
```
|
||
{instruction:"{{q}}",output:"{{a}}",source:"{{source}}"}
|
||
```
|
||
|
||
搜索到的知识库,会自动将 q,a,source 替换成对应的内容。每条搜索到的内容,会通过 `\n` 隔开。例如:
|
||
```
|
||
{instruction:"电影《铃芽之旅》的导演是谁?",output:"电影《铃芽之旅》的导演是新海诚。",source:"手动输入"}
|
||
{instruction:"本作的主人公是谁?",output:"本作的主人公是名叫铃芽的少女。",source:""}
|
||
{instruction:"电影《铃芽之旅》男主角是谁?",output:"电影《铃芽之旅》男主角是宗像草太,由松村北斗配音。",source:""}
|
||
{instruction:"电影《铃芽之旅》的编剧是谁?22",output:"新海诚是本片的编剧。",source:"手动输入"}
|
||
```
|
||
|
||
#### 引用提示词
|
||
|
||
引用模板需要和引用提示词一起使用,提示词中可以写引用模板的格式说明以及对话的要求等。可以使用 {{quote}} 来使用 **引用模板**,使用 {{question}} 来引入问题。例如:
|
||
|
||
```
|
||
你的背景知识:
|
||
"""
|
||
{{quote}}
|
||
"""
|
||
对话要求:
|
||
1. 背景知识是最新的,其中 instruction 是相关介绍,output 是预期回答或补充。
|
||
2. 使用背景知识回答问题。
|
||
3. 背景知识无法回答问题时,你可以礼貌的的回答用户问题。
|
||
我的问题是:"{{question}}"
|
||
```
|
||
|
||
转义后则为:
|
||
```
|
||
你的背景知识:
|
||
"""
|
||
{instruction:"电影《铃芽之旅》的导演是谁?",output:"电影《铃芽之旅》的导演是新海诚。",source:"手动输入"}
|
||
{instruction:"本作的主人公是谁?",output:"本作的主人公是名叫铃芽的少女。",source:""}
|
||
{instruction:"电影《铃芽之旅》男主角是谁?",output:"电影《铃芽之旅》男主角是宗像草太,由松村北斗配音}
|
||
"""
|
||
对话要求:
|
||
1. 背景知识是最新的,其中 instruction 是相关介绍,output 是预期回答或补充。
|
||
2. 使用背景知识回答问题。
|
||
3. 背景知识无法回答问题时,你可以礼貌的的回答用户问题。
|
||
我的问题是:"{{question}}"
|
||
```
|
||
|
||
#### 总结
|
||
|
||
引用模板规定了搜索出来的内容如何组成一句话,其由 q,a,index,source 多个变量组成。
|
||
|
||
引用提示词由`引用模板`和`提示词`组成,提示词通常是对引用模板的一个描述,加上对模型的要求。
|
||
|
||
### 引用模板和提示词设计 示例
|
||
|
||
#### 通用模板与问答模板对比
|
||
|
||
我们通过一组`你是谁`的手动数据,对通用模板与问答模板的效果进行对比。此处特意打了个搞笑的答案,通用模板下 GPT35 就变得不那么听话了,而问答模板下 GPT35 依然能够回答正确。这是由于结构化的提示词,在大语言模型中具有更强的引导作用。
|
||
|
||
{{% alert icon="🍅" context="success" %}}
|
||
Tips: 建议根据不同的场景,每种知识库仅选择1类数据类型,这样有利于充分发挥提示词的作用。
|
||
{{% /alert %}}
|
||
|
||
| 通用模板配置及效果 | 问答模板配置及效果 |
|
||
| --- | --- |
|
||
|  |  |
|
||
|  |  |
|
||
|  |  |
|
||
|
||
#### 严格模板
|
||
|
||
使用非严格模板,我们随便询问一个不在知识库中的内容,模型通常会根据其自身知识进行回答。
|
||
|
||
| 非严格模板效果 | 选择严格模板 | 严格模板效果 |
|
||
| --- | --- | --- |
|
||
|  |  | |
|
||
|
||
#### 提示词设计思路
|
||
|
||
1. 使用序号进行不同要求描述。
|
||
2. 使用首先、然后、最后等词语进行描述。
|
||
3. 列举不同场景的要求时,尽量完整,不要遗漏。例如:背景知识完全可以回答、背景知识可以回答一部分、背景知识与问题无关,3种场景都说明清楚。
|
||
4. 巧用结构化提示,例如在问答模板中,利用了`instruction`和`output`,清楚的告诉模型,`output`是一个预期的答案。
|
||
5. 标点符号正确且完整。
|
||
|
||
# 对话问题引导
|
||
## FastGPT 对话问题引导
|
||
|
||

|
||
|
||
## 什么是自定义问题引导
|
||
|
||
你可以为你的应用提前预设一些问题,用户在输入时,会根据输入的内容,动态搜索这些问题作为提示,从而引导用户更快的进行提问。
|
||
|
||
你可以直接在 FastGPT 中配置词库,或者提供自定义词库接口。
|
||
|
||
## 自定义词库接口
|
||
|
||
需要保证这个接口可以被用户浏览器访问。
|
||
|
||
**请求:**
|
||
|
||
```bash
|
||
curl --location --request GET 'http://localhost:3000/api/core/chat/inputGuide/query?appId=663c75302caf8315b1c00194&searchKey=你'
|
||
```
|
||
|
||
其中 `appId` 为应用ID,`searchKey` 为搜索关键字,最多是50个字符。
|
||
|
||
**响应**
|
||
|
||
```json
|
||
{
|
||
"code": 200,
|
||
"statusText": "",
|
||
"message": "",
|
||
"data": [
|
||
"是你",
|
||
"你是谁呀",
|
||
"你好好呀",
|
||
"你好呀",
|
||
"你是谁!",
|
||
"你好"
|
||
]
|
||
}
|
||
```
|
||
|
||
data是一个数组,包含了搜索到的问题,最多只需要返回5个问题。
|
||
|
||
|
||
**参数说明:**
|
||
|
||
- appId - 应用ID
|
||
- searchKey - 搜索关键字
|
||
|
||
# 知识库集合标签
|
||
## FastGPT 知识库集合标签使用说明
|
||
|
||
知识库集合标签是 FastGPT 商业版特有功能。它允许你对知识库中的数据集合添加标签进行分类,更高效地管理知识库数据。
|
||
|
||
而进一步可以在问答中,搜索知识库时添加集合过滤,实现更精确的搜索。
|
||
|
||
| | | |
|
||
| --------------------- | --------------------- | --------------------- |
|
||
|  |  |  |
|
||
|
||
## 标签基础操作说明
|
||
|
||
在知识库详情页面,可以对标签进行管理,可执行的操作有
|
||
|
||
- 创建标签
|
||
- 修改标签名
|
||
- 删除标签
|
||
- 将一个标签赋给多个数据集合
|
||
- 给一个数据集合添加多个标签
|
||
|
||
也可以利用标签对数据集合进行筛选
|
||
|
||
## 知识库搜索-集合过滤说明
|
||
|
||
利用标签可以在知识库搜索时,通过填写「集合过滤」这一栏来实现更精确的搜索,具体的填写示例如下
|
||
|
||
```json
|
||
{
|
||
"tags": {
|
||
"$and": ["标签 1","标签 2"],
|
||
"$or": ["有 $and 标签时,and 生效,or 不生效"]
|
||
},
|
||
"createTime": {
|
||
"$gte": "YYYY-MM-DD HH:mm 格式即可,集合的创建时间大于该时间",
|
||
"$lte": "YYYY-MM-DD HH:mm 格式即可,集合的创建时间小于该时间,可和 $gte 共同使用"
|
||
}
|
||
}
|
||
```
|
||
|
||
在填写时有两个注意的点,
|
||
|
||
- 标签值可以为 `string` 类型的标签名,也可以为 `null`,而 `null` 代表着未设置标签的数据集合
|
||
- 标签过滤有 `$and` 和 `$or` 两种条件类型,在同时设置了 `$and` 和 `$or` 的情况下,只有 `$and` 会生效
|
||
|
||
# 文件输入功能介绍
|
||
## FastGPT 文件输入功能介绍
|
||
|
||
从 4.8.9 版本起,FastGPT 支持在`简易模式`和`工作流`中,配置用户上传文件、图片功能。下面先简单介绍下如何使用文件输入功能,最后是介绍下文件解析的工作原理。
|
||
|
||
|
||
## 简易模式中使用
|
||
|
||
简易模式打开文件上传后,会使用工具调用模式,也就是由模型自行决策,是否需要读取文件内容。
|
||
|
||
可以找到左侧文件上传的配置项,点击其右侧的`开启`/`关闭`按键,即可打开配置弹窗。
|
||
|
||

|
||
|
||
随后,你的调试对话框中,就会出现一个文件选择的 icon,可以点击文件选择 icon,选择你需要上传的文件。
|
||
|
||

|
||
|
||
**工作模式**
|
||
|
||
从 4.8.13 版本起,简易模式的文件读取将会强制解析文件并放入 system 提示词中,避免连续对话时,模型有时候不会主动调用读取文件的工具。
|
||
|
||
## 工作流中使用
|
||
|
||
工作流中,可以在系统配置中,找到`文件输入`配置项,点击其右侧的`开启`/`关闭`按键,即可打开配置弹窗。
|
||
|
||

|
||
|
||
在工作流中,使用文件的方式很多,最简单的就是类似下图中,直接通过工具调用接入文档解析,实现和简易模式一样的效果。
|
||
|
||
| | |
|
||
| --------------------- | --------------------- |
|
||
|  |  |
|
||
|
||
当然,你也可以在工作流中,对文档进行内容提取、内容分析等,然后将分析的结果传递给 HTTP 或者其他模块,从而实现文件处理的 SOP。
|
||
|
||

|
||
|
||
## 文档解析工作原理
|
||
|
||
不同于图片识别,LLM 模型目前没有支持直接解析文档的能力,所有的文档“理解”都是通过文档转文字后拼接 prompt 实现。这里通过几个 FAQ 来解释文档解析的工作原理,理解文档解析的原理,可以更好的在工作流中使用文档解析功能。
|
||
|
||
### 上传的文件如何存储在数据库中
|
||
|
||
FastGPT 的对话记录存储结构中,role=user 的消息,value 值会按以下结构存储:
|
||
|
||
```ts
|
||
type UserChatItemValueItemType = {
|
||
type: 'text' | 'file'
|
||
text?: {
|
||
content: string;
|
||
};
|
||
file?: {
|
||
type: 'img' | 'doc'
|
||
name?: string;
|
||
url: string;
|
||
};
|
||
};
|
||
```
|
||
|
||
也就是说,上传的图片和文档,都会以 URL 的形式存储在库中,并不会存储`解析后的文档内容`。
|
||
|
||
### 图片如何处理
|
||
|
||
文档解析节点不会处理图片,图片链接会被过滤,图片识别请直接使用支持图片识别的 LLM 模型。
|
||
|
||
### 文档解析节点如何工作
|
||
|
||
文档解析依赖文档解析节点,这个节点会接收一个`array<string>`类型的输入,对应的是文件输入的 URL;输出的是一个`string`,对应的是文档解析后的内容。
|
||
|
||
* 在文档解析节点中,只会解析`文档`类型的 URL,它是通过文件 URL 解析出来的`文名件后缀`去判断的。如果你同时选择了文档和图片,图片会被忽略。
|
||
* **文档解析节点,只会解析本轮工作流接收的文件,不会解析历史记录的文件。**
|
||
* 多个文档内容如何拼接的
|
||
|
||
按下列的模板,对多个文件进行拼接,即文件名+文件内容的形式组成一个字符串,不同文档之间通过分隔符:`\n******\n` 进行分割。
|
||
|
||
```
|
||
File: ${filename}
|
||
<Content>
|
||
${content}
|
||
</Content>
|
||
```
|
||
|
||
### AI节点中如何使用文档解析
|
||
|
||
在 AI 节点(AI对话/工具调用)中,新增了一个文档链接的输入,可以直接引用文档的地址,从而实现文档内容的引用。
|
||
|
||
它接收一个`Array<string>`类型的输入,最终这些 url 会被解析,并进行提示词拼接,放置在 role=system 的消息中。提示词模板如下:
|
||
|
||
```
|
||
将 <FilesContent></FilesContent> 中的内容作为本次对话的参考:
|
||
<FilesContent>
|
||
{{quote}}
|
||
</FilesContent>
|
||
```
|
||
|
||
# 4.8.13版本起,关于文件上传的更新
|
||
|
||
由于与 4.8.9 版本有些差异,尽管我们做了向下兼容,避免工作流立即不可用。但是请尽快的按新版本规则进行调整工作流,后续将会去除兼容性代码。
|
||
|
||
1. 简易模式中,将会强制进行文件解析,不再由模型决策是否解析,保证每次都能参考文档。
|
||
2. 文档解析:不再解析历史记录中的文件。
|
||
3. 工具调用:支持直接选择文档引用,不需要再挂载文档解析工具。会自动解析历史记录中的文件。
|
||
4. AI 对话:支持直接选择文档引用,不需要进过文档解析节点。会自动解析历史记录中的文件。
|
||
5. 插件单独运行:不再支持全局文件;插件输入支持配置文件类型,可以取代全局文件上传。
|
||
6. **工作流调用插件:不再自动传递工作流上传的文件到插件,需要手动给插件输入指定变量。**
|
||
7. **工作流调用工作流:不再自动传递工作流上传的文件到子工作流,可以手动选择需要传递的文件链接。**
|
||
|
||
# 快速上手
|
||
## 快速体验 FastGPT 基础功能
|
||
|
||
更多使用技巧,[查看视频教程](https://www.bilibili.com/video/BV1sH4y1T7s9)
|
||
|
||
## 知识库
|
||
|
||
开始前,请准备一份测试电子文档,WORD、PDF、TXT、excel、markdown 都可以,比如公司休假制度、不涉密的销售说辞、产品知识等等。
|
||
|
||
这里使用 FastGPT 中文 README 文件为例。
|
||
|
||
首先我们需要创建一个知识库。
|
||
|
||

|
||
|
||
知识库创建完之后我们需要上传一点内容。
|
||
|
||
上传内容这里有四种模式:
|
||
- 手动输入:手动输入问答对,是最精准的数据
|
||
- QA 拆分:选择文本文件,让AI自动生成问答对
|
||
- 直接分段:选择文本文件,直接将其按分段进行处理
|
||
- CSV 导入:批量导入问答对
|
||
|
||
这里,我们选择 QA 拆分,让 AI 自动生成问答,若问答质量不高,可以后期手动修改。
|
||
|
||

|
||
|
||
点击上传后我们需要等待数据处理完成,直到我们上传的文件状态为可用。
|
||
|
||

|
||
|
||
## 应用
|
||
|
||
点击「应用」按钮来新建一个应用,这里有四个模板,我们选择「知识库 + 对话引导」。
|
||
|
||

|
||
|
||
应用创建后来再应用详情页找到「知识库」模块,把我们刚刚创建的知识库添加进去。
|
||
|
||

|
||
|
||
添加完知识库后记得点击「保存并预览」,这样我们的应用就和知识库关联起来了。
|
||
|
||

|
||
|
||
然后我们就可以愉快的开始聊天啦。
|
||
|
||

|
||
|
||
# 简易模式
|
||
## 快速了解 FastGPT 工作台的简易模式
|
||
|
||
|
||
|
||
# 使用 Gapier 快速导入Agent工具
|
||
## FastGPT 使用 Gapier 快速导入Agent工具
|
||
|
||
FastGPT V4.7版本加入了工具调用,可以兼容 GPTs 的 Actions。这意味着,你可以直接导入兼容 GPTs 的 Agent 工具。
|
||
|
||
Gapier 是一个在线 GPTs Actions工具,提供了50多种现成工具,并且每天有免费额度进行测试,方便用户试用,官方地址为:[https://gapier.com/](https://gapier.com/)。
|
||
|
||

|
||
|
||
现在,我们开始把 Gapier 的工具导入到 FastGPT 中。
|
||
|
||
## 1. 创建插件
|
||
|
||
| Step1 | Step2 | Step3 |
|
||
| --- | --- | --- |
|
||
|  |  | 登录[Gapier](https://gapier.com/) 复制相关参数 <br>  |
|
||
| Step4 | Step5 | Step6 |
|
||
| 自定义请求头: Authorization<br>请求值: Bearer 复制的key <br>  |  |  |
|
||
|
||
创建完后,如果需要变更,无需重新创建,只需要修改对应参数即可,会自动做差值比较更新。
|
||
|
||

|
||
|
||
## 2. 应用绑定工具
|
||
|
||
### 简易模式
|
||
|
||
| Step1 | Step2 |
|
||
| --- | --- | --- |
|
||
|  |  |
|
||
| Step3 | Step4 |
|
||
|  |  |
|
||
|
||
### 高级编排
|
||
|
||
| Step1 | Step2 |
|
||
| --- | --- | --- |
|
||
|  |  |
|
||
| Step3 | Step4 |
|
||
|  |  |
|
||
|
||

|
||
|
||
## 3. 工具调用说明
|
||
|
||
### 不同模型的区别
|
||
|
||
不同模型调用工具采用不同的方法,有些模型支持 toolChoice 和 functionCall 效果会更好。不支持这两种方式的模型通过提示词调用,但是效果不是很好,并且为了保证顺利调用,FastGPT内置的提示词,仅支持每次调用一个工具。
|
||
|
||
具体哪些模型支持 functionCall 可以官网查看(当然,也需要OneAPI支持),同时需要调整模型配置文件中的对应字段(详细看配置字段说明)。
|
||
|
||
线上版用户,可以在模型选择时,看到是否支持函数调用的标识。
|
||
|
||

|
||
|
||
# 工作流&插件
|
||
## 快速了解 FastGPT 工作流和插件的使用
|
||
|
||
FastGPT 从 V4.0 版本开始采用新的交互方式来构建 AI 应用。使用了 Flow 节点编排(工作流)的方式来实现复杂工作流,提高可玩性和扩展性。但同时也提高了上手的门槛,有一定开发背景的用户使用起来会比较容易。
|
||
|
||
[查看视频教程](https://www.bilibili.com/video/BV1is421u7bQ/)
|
||
|
||

|
||
|
||
## 什么是节点?
|
||
|
||
在程序中,节点可以理解为一个个 Function 或者接口。可以理解为它就是一个**步骤**。将多个节点一个个拼接起来,即可一步步的去实现最终的 AI 输出。
|
||
|
||
如下图,这是一个最简单的 AI 对话。它由用流程开始和 AI 对话节点组成。
|
||
|
||

|
||
|
||
执行流程如下:
|
||
1. 用户输入问题后,【流程开始】节点执行,用户问题被保存。
|
||
2. 【AI 对话】节点执行,此节点有两个必填参数“聊天记录” “用户问题”,聊天记录的值是默认输入的6条,表示此模块上下文长度。用户问题选择的是【流程开始】模块中保存的用户问题。
|
||
3. 【AI 对话】节点根据传入的聊天记录和用户问题,调用对话接口,从而实现回答。
|
||
|
||
### 节点分类
|
||
|
||
从功能上,节点可以分为 2 类:
|
||
|
||
1. **系统节点**:用户引导(配置一些对话框信息)、用户问题(流程入口)。
|
||
2. **功能节点**:知识库搜索、AI 对话等剩余节点。(这些节点都有输入和输出,可以自由组合)。
|
||
|
||
### 节点的组成
|
||
|
||
每个节点会包含 3 个核心部分:输入、输出和触发器。
|
||
|
||

|
||
|
||
- AI模型、提示词、聊天记录、用户问题,知识库引用为输入,节点的输入可以是手动输入也可以是变量引用,变量引用的范围包括“全局变量”和之前任意一个节点的输出。
|
||
- 新的上下文和AI回复内容为输出,输出可以被之后任意节点变量引用。
|
||
- 节点的上下左右有四个“触发器”可以被用来连接,被连接的节点按顺序决定是否执行。
|
||
|
||
## 重点 - 工作流是如何运行的
|
||
|
||
FastGPT的工作流从【流程开始】节点开始执行,可以理解为从用户输入问题开始,没有**固定的出口**,是以节点运行结束作为出口,如果在一个轮调用中,所有节点都不再运行,则工作流结束。
|
||
|
||
下面我们来看下,工作流是如何运行的,以及每个节点何时被触发执行。
|
||
|
||

|
||
|
||
如上图所示节点会“被连接”也会“连接其他节点”,我们称“被连接”的那根线为前置线,“连接其他节点的线”为后置线。上图例子中【知识库搜索】模块左侧有一根前置线,右侧有一根后置线。而【AI对话】节点只有左侧一根前置线。
|
||
|
||
FastGPT工作流中的线有以下几种状态:
|
||
- `waiting`:被连接的节点等待执行。
|
||
- `active`:被连接的节点可以执行。
|
||
- `skip`:被连接的节点不需要执行跳过。
|
||
|
||
节点执行的原则:
|
||
|
||
1. 判断前置线中有没有状态为 `waiting` 的,如果有则等待。
|
||
2. 判断前置线中状态有没有状态为 `active` 如果有则执行。
|
||
3. 如果前置线中状态即没有 `waiting` 也没有 `active` 则认为此节点需要跳过。
|
||
4. 节点执行完毕后,需要根据实际情况更改后置线的状态为`active`或`skip`并且更改前置线状态为`waiting`等待下一轮执行。
|
||
|
||
让我们看一下上面例子的执行过程:
|
||
1. 【流程开始】节点执行完毕,更改后置线为`active`。
|
||
2. 【知识库搜索】节点判断前置线状态为`active`开始执行,执行完毕后更改后置线状态为`active` 前置线状态为`waiting`。
|
||
3. 【AI对话】节点判断前置线状态为`active`开始执行,流程执行结束。
|
||
|
||
## 如何连接节点
|
||
|
||
1. 为了方便连接,FastGPT 每个节点的上下左右都有连接点,左和上是前置线连接点,右和下是后置线连接点。
|
||
2. 可以点击连接线中间的 x 来删除连接线。
|
||
3. 可以左键点击选中连接线
|
||
|
||
## 如何阅读?
|
||
|
||
1. 建议从左往右阅读。
|
||
2. 从 **用户问题** 节点开始。用户问题节点,代表的是用户发送了一段文本,触发任务开始。
|
||
3. 关注【AI 对话】和【指定回复】节点,这两个节点是输出答案的地方。
|
||
|
||
## FAQ
|
||
|
||
### 想合并多个输出结果怎么实现?
|
||
|
||
1. 文本加工,可以对字符串进行合并。
|
||
2. 知识库搜索合并,可以合并多个知识库搜索结果
|
||
3. 其他结果,无法直接合并,可以考虑传入到`HTTP`节点中进行合并,使用`[Laf](https://laf.run/)`可以快速实现一个无服务器HTTP接口。
|
||
|
||
# MCP 服务
|
||
## 快速了解 FastGPT MCP server
|
||
|
||
## MCP server 介绍
|
||
|
||
MCP 协议(Model Context Protocol),是由 Anthropic 在 2024年 11 月初发布的协议。它的目的在于统一 AI 模型与外部系统之间的通信方式,从而简化 AI 模型与外部系统之间的通信问题。随着 OpenAI 官宣支持 MCP 协议,越来越多的 AI 厂商开始支持 MCP 协议。
|
||
|
||
MCP 协议主要包含 Client 和 Server 两部分。简单来说,Client 是使用 AI 模型的一方,它通过 MCP Client 可以给模型提供一些调用外部系统的能能力;Server 是提供外部系统调用的一方,也就是实际运行外部系统的一方。
|
||
|
||
FastGPT MCP Server 功能允许你选择`多个`在 FastGPT 上构建好的应用,以 MCP 协议对外提供调用 FastGPT 应用的能力。
|
||
|
||
目前 FastGPT 提供的 MCP server 为 SSE 通信协议,未来将会替换成 `HTTP streamable`。
|
||
|
||
## FastGPT 使用 MCP server
|
||
|
||
### 1. 创建 MCP server
|
||
|
||
登录 FastGPT 后,打开`工作台`,点击`MCP server`,即可进入管理页面,这里可以看到你创建的所有 MCP server,以及他们管理的应用数量。
|
||
|
||

|
||
|
||
可以自定义 MCP server 名称和选择关联的应用
|
||
|
||
| | |
|
||
|---|---|
|
||
|  |  |
|
||
|
||
### 2. 获取 MCP server 地址
|
||
|
||
创建好 MCP server 后,可以直接点击`开始使用`,即可获取 MCP server 访问地址。
|
||
|
||
| | |
|
||
|---|---|
|
||
|  |  |
|
||
|
||
#### 3. 使用 MCP server
|
||
|
||
可以在支持 MCP 协议的客户端使用这些地址,来调用 FastGPT 应用,例如:`Cursor`、`Cherry Studio`。下面以 Cursor 为例,介绍如何使用 MCP server。
|
||
|
||
打开 Cursor 配置页面,点击 MCP 即可进入 MCP 配置页面,可以点击新建 MCP server 按钮,会跳转到一个 JSON 配置文件,将第二步的`接入脚本`复制到`json 文件`中,保存文件。
|
||
|
||
此时返回 Cursor 的 MCP 管理页面,即可看到你创建的 MCP server,记得设成`enabled`状态。
|
||
|
||
| | | |
|
||
|---|---|---|
|
||
|  |  |  |
|
||
|
||
|
||
打开 Cursor 的对话框,切换成`Agent`模型,只有这个模型,cursor 才会调用 MCP server。
|
||
发送一个关于`fastgpt`的问题后,可以看到,cursor 调用了一个 MCP 工具(描述为:查询 fastgpt 知识库),也就是调用 FastGPT 应用去进行处理该问题,并返回了结果。
|
||
|
||
| | |
|
||
|---|---|
|
||
|  |  |
|
||
|
||
|
||
## 私有化部署 MCP server 问题
|
||
|
||
私有化部署版本的 FastGPT,需要升级到`v4.9.6-alpha`及以上版本才可使用 MCP server 功能。
|
||
|
||
### 修改 docker-compose.yml 文件
|
||
|
||
在`docker-compose.yml`文件中,加入`fastgpt-mcp-server`服务:
|
||
|
||
```yml
|
||
fastgpt-mcp-server:
|
||
container_name: fastgpt-mcp-server
|
||
image: ghcr.io/labring/fastgpt-mcp_server:latest
|
||
ports:
|
||
- 3005:3000
|
||
networks:
|
||
- fastgpt
|
||
restart: always
|
||
environment:
|
||
- FASTGPT_ENDPOINT=http://fastgpt:3000
|
||
```
|
||
|
||
### 修改 FastGPT 容器环境变量
|
||
|
||
修改`config.json`配置文件,增加: `"feconfigs.mcpServerProxyEndpoint": "fastgpt-mcp-server 的访问地址"`, 末尾不要携带/,例如:
|
||
```json
|
||
{
|
||
"feConfigs": {
|
||
"lafEnv": "https://laf.dev",
|
||
"mcpServerProxyEndpoint": "https://mcp.fastgpt.cn"
|
||
}
|
||
}
|
||
```
|
||
|
||
### 重启 FastGPT 容器
|
||
|
||
因为是修改的挂载文件,可以强制 down 再 up 服务。启动后,既可以在工作台看到 MCP server 服务选项。
|
||
|
||
```bash
|
||
docker-compose down
|
||
docker-compose up -d
|
||
```
|
||
|
||
# AI 对话
|
||
## FastGPT AI 对话模块介绍
|
||
|
||
## 特点
|
||
|
||
- 可重复添加
|
||
- 触发执行
|
||
- 核心模块
|
||
|
||

|
||
|
||
## 参数说明
|
||
|
||
## AI模型
|
||
|
||
可以通过 [config.json](/docs/development/configuration/) 配置可选的对话模型,通过 [one-api](/docs/development/modelconfig/one-api/) 来实现多模型接入。
|
||
|
||
点击AI模型后,可以配置模型的相关参数。
|
||
|
||

|
||
|
||

|
||
|
||
|
||
|
||
{{% alert icon="🍅" context="success" %}}
|
||
具体配置参数介绍可以参考: [AI参数配置说明](/docs/guide/course/ai_settings/)
|
||
{{% /alert %}}
|
||
|
||
# 文本内容提取
|
||
## FastGPT 内容提取模块介绍
|
||
|
||
## 特点
|
||
|
||
- 可重复添加
|
||
- 需要手动配置
|
||
- 触发执行
|
||
- function_call 模块
|
||
- 核心模块
|
||
|
||

|
||
|
||
## 功能
|
||
|
||
从文本中提取结构化数据,通常是配合 HTTP 模块实现扩展。也可以做一些直接提取操作,例如:翻译。
|
||
|
||
## 参数说明
|
||
|
||
### 提取要求描述
|
||
|
||
顾名思义,给模型设置一个目标,需要提取哪些内容。
|
||
|
||
**示例 1**
|
||
|
||
> 你是实验室预约助手,从对话中提取出姓名,预约时间,实验室号。当前时间 {{cTime}}
|
||
|
||
**示例 2**
|
||
|
||
> 你是谷歌搜索助手,从对话中提取出搜索关键词
|
||
|
||
**示例 3**
|
||
|
||
> 将我的问题直接翻译成英文,不要回答问题
|
||
|
||
### 历史记录
|
||
|
||
通常需要一些历史记录,才能更完整的提取用户问题。例如上图中需要提供姓名、时间和实验室名,用户可能一开始只给了时间和实验室名,没有提供自己的姓名。再经过一轮缺失提示后,用户输入了姓名,此时需要结合上一次的记录才能完整的提取出 3 个内容。
|
||
|
||
### 目标字段
|
||
|
||
目标字段与提取的结果相对应,从上图可以看到,每增加一个字段,输出会增加一个对应的出口。
|
||
|
||
+ **key**: 字段的唯一标识,不可重复!
|
||
+ **字段描述**:描述该字段是关于什么的,例如:姓名、时间、搜索词等等。
|
||
+ **必须**:是否强制模型提取该字段,可能提取出来是空字符串。
|
||
|
||
## 输出介绍
|
||
|
||
- **完整提取结果**: 一个 JSON 字符串,包含所有字段的提取结果。
|
||
- **目标字段提取结果**:类型均为字符串。
|
||
|
||
# 问题优化
|
||
## 问题优化模块介绍和使用
|
||
|
||
## 特点
|
||
|
||
- 可重复添加
|
||
- 有外部输入
|
||
- 触发执行
|
||
|
||

|
||
|
||
## 背景
|
||
|
||
在 RAG 中,我们需要根据输入的问题去数据库里执行 embedding 搜索,查找相关的内容,从而查找到相似的内容(简称知识库搜索)。
|
||
|
||
在搜索的过程中,尤其是连续对话的搜索,我们通常会发现后续的问题难以搜索到合适的内容,其中一个原因是知识库搜索只会使用“当前”的问题去执行。看下面的例子:
|
||
|
||

|
||
|
||
用户在提问“第二点是什么”的时候,只会去知识库里查找“第二点是什么”,压根查不到内容。实际上需要查询的是“QA结构是什么”。因此我们需要引入一个【问题优化】模块,来对用户当前的问题进行补全,从而使得知识库搜索能够搜索到合适的内容。使用补全后效果如下:
|
||
|
||

|
||
|
||
|
||
## 功能
|
||
|
||
调用 AI 去对用户当前的问题进行补全。目前主要是补全“指代”词,使得检索词更加的完善可靠,从而增强上下文连续对话的知识库搜索能力。
|
||
|
||
遇到最大的难题在于:模型对于【补全】的概念可能不清晰,且对于长上下文往往无法准确的知道应该如何补全。
|
||
|
||
## 示例
|
||
|
||
- [接入谷歌搜索](/docs/use-cases/app-cases/google_search/)
|
||
|
||
# 自定义反馈
|
||
## 自定义反馈模块介绍
|
||
|
||
该模块为临时模块,后续会针对该模块进行更全面的设计。
|
||
|
||
## 特点
|
||
|
||
- 可重复添加
|
||
- 无外部输入
|
||
- 自动执行
|
||
|
||
|
||
| | |
|
||
| --------------------- | --------------------- |
|
||
|  |  |
|
||
|  |  |
|
||
|
||
|
||
## 介绍
|
||
|
||
自定义反馈模块,可以为你的对话增加一个反馈标记,从而方便在后台更好的分析对话的数据。
|
||
|
||
在调试模式下,不会记录反馈内容,而是直接提示: `自动反馈测试: 反馈内容`。
|
||
|
||
在对话模式(对话、分享窗口、带 chatId 的 API 调用)时,会将反馈内容记录到对话日志中。(会延迟60s记录)
|
||
|
||
## 作用
|
||
|
||
自定义反馈模块的功能类似于程序开发的`埋点`,便于你观测的对话中的数据。
|
||
|
||
# 知识库搜索
|
||
## FastGPT AI 知识库搜索模块介绍
|
||
|
||
知识库搜索具体参数说明,以及内部逻辑请移步:[FastGPT知识库搜索方案](/docs/guide/knowledge_base/rag/)
|
||
|
||
## 特点
|
||
|
||
- 可重复添加(复杂编排时防止线太乱,可以更美观)
|
||
- 有外部输入
|
||
- 有静态配置
|
||
- 触发执行
|
||
- 核心模块
|
||
|
||

|
||
|
||
## 参数说明
|
||
|
||
### 输入 - 关联的知识库
|
||
|
||
可以选择一个或多个**相同向量模型**的知识库,用于向量搜索。
|
||
|
||
### 输入 - 搜索参数
|
||
|
||
[点击查看参数介绍](/docs/guide/knowledge_base/dataset_engine/#搜索参数)
|
||
|
||
### 输出 - 引用内容
|
||
|
||
以数组格式输出引用,长度可以为 0。意味着,即使没有搜索到内容,这个输出链路也会走通。
|
||
|
||
# 文档解析
|
||
## FastGPT 文档解析模块介绍
|
||
|
||
| | |
|
||
| --- | --- |
|
||
|  |  |
|
||
|
||
开启文件上传后,可使用文档解析组件。
|
||
|
||
## 功能
|
||
|
||
## 作用
|
||
|
||
# 表单输入
|
||
## FastGPT 表单输入模块介绍
|
||
|
||
## 特点
|
||
|
||
- 用户交互
|
||
- 可重复添加
|
||
- 触发执行
|
||
|
||

|
||
|
||
## 功能
|
||
|
||
「表单输入」节点属于用户交互节点,当触发这个节点时,对话会进入“交互”状态,会记录工作流的状态,等用户完成交互后,继续向下执行工作流
|
||
|
||

|
||
|
||
比如上图中的例子,当触发表单输入节点时,对话框隐藏,对话进入“交互状态”
|
||
|
||

|
||
|
||
当用户填完必填的信息并点击提交后,节点能够收集用户填写的表单信息,传递到后续的节点中使用
|
||
|
||
## 作用
|
||
|
||
能够精准收集需要的用户信息,再根据用户信息进行后续操作
|
||
|
||
# HTTP 请求
|
||
## FastGPT HTTP 模块介绍
|
||
|
||
## 特点
|
||
|
||
- 可重复添加
|
||
- 手动配置
|
||
- 触发执行
|
||
- 核中核模块
|
||
|
||

|
||
|
||
## 介绍
|
||
|
||
HTTP 模块会向对应的地址发送一个 `HTTP` 请求,实际操作与 Postman 和 ApiFox 这类直流工具使用差不多。
|
||
|
||
- Params 为路径请求参数,GET请求中用的居多。
|
||
- Body 为请求体,POST/PUT请求中用的居多。
|
||
- Headers 为请求头,用于传递一些特殊的信息。
|
||
- 自定义变量中可以接收前方节点的输出作为变量
|
||
- 3 种数据中均可以通过 `{{}}` 来引用变量。
|
||
- url 也可以通过 `{{}}` 来引用变量。
|
||
- 变量来自于`全局变量`、`系统变量`、`前方节点输出`
|
||
|
||
## 参数结构
|
||
|
||
### 系统变量说明
|
||
|
||
你可以将鼠标放置在`请求参数`旁边的问号中,里面会提示你可用的变量。
|
||
|
||
- appId: 应用的ID
|
||
- chatId: 当前对话的ID,测试模式下不存在。
|
||
- responseChatItemId: 当前对话中,响应的消息ID,测试模式下不存在。
|
||
- variables: 当前对话的全局变量。
|
||
- cTime: 当前时间。
|
||
- histories: 历史记录(默认最多取10条,无法修改长度)
|
||
|
||
### Params, Headers
|
||
|
||
不多描述,使用方法和Postman, ApiFox 基本一致。
|
||
|
||
可通过 {{key}} 来引入变量。例如:
|
||
|
||
| key | value |
|
||
| --- | --- |
|
||
| appId | {{appId}} |
|
||
| Authorization | Bearer {{token}} |
|
||
|
||
### Body
|
||
|
||
只有特定请求类型下会生效。
|
||
|
||
可以写一个`自定义的 Json`,并通过 {{key}} 来引入变量。例如:
|
||
|
||
{{< tabs tabTotal="3" >}}
|
||
{{< tab tabName="假设有一组变量" >}}
|
||
{{< markdownify >}}
|
||
|
||
```json
|
||
{
|
||
"string": "字符串",
|
||
"number": 123,
|
||
"boolean": true,
|
||
"array": [1, 2, 3],
|
||
"obj": {
|
||
"name": "FastGPT",
|
||
"url": "https://tryfastgpt.ai"
|
||
}
|
||
}
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
{{< tab tabName="Http 模块中的Body声明" >}}
|
||
{{< markdownify >}}
|
||
|
||
注意,在 Body 中,你如果引用`字符串`,则需要加上`""`,例如:`"{{string}}"`。
|
||
|
||
```json
|
||
{
|
||
"string": "{{string}}",
|
||
"token": "Bearer {{string}}",
|
||
"number": {{number}},
|
||
"boolean": {{boolean}},
|
||
"array": [{{number}}, "{{string}}"],
|
||
"array2": {{array}},
|
||
"object": {{obj}}
|
||
}
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
{{< tab tabName="最终得到的解析" >}}
|
||
{{< markdownify >}}
|
||
|
||
```json
|
||
{
|
||
"string": "字符串",
|
||
"token": "Bearer 字符串",
|
||
"number": 123,
|
||
"boolean": true,
|
||
"array": [123, "字符串"],
|
||
"array2": [1, 2, 3],
|
||
"object": {
|
||
"name": "FastGPT",
|
||
"url": "https://tryfastgpt.ai"
|
||
}
|
||
}
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
{{< /tabs >}}
|
||
|
||
### 如何获取返回值
|
||
|
||
从图中可以看出,FastGPT可以添加多个返回值,这个返回值并不代表接口的返回值,而是代表`如何解析接口返回值`,可以通过 `JSON path` 的语法,来`提取`接口响应的值。
|
||
|
||
语法可以参考: https://github.com/JSONPath-Plus/JSONPath?tab=readme-ov-file
|
||
|
||
{{< tabs tabTotal="2" >}}
|
||
{{< tab tabName="接口响应示例" >}}
|
||
{{< markdownify >}}
|
||
|
||
```json
|
||
{
|
||
"message": "测试",
|
||
"data":{
|
||
"user": {
|
||
"name": "xxx",
|
||
"age": 12
|
||
},
|
||
"list": [
|
||
{
|
||
"name": "xxx",
|
||
"age": 50
|
||
},
|
||
[{ "test": 22 }]
|
||
],
|
||
"psw": "xxx"
|
||
}
|
||
}
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
{{< tab tabName="提取示例" >}}
|
||
{{< markdownify >}}
|
||
|
||
```json
|
||
{
|
||
"$.message": "测试",
|
||
"$.data.user": { "name": "xxx", "age": 12 },
|
||
"$.data.user.name": "xxx",
|
||
"$.data.user.age": 12,
|
||
"$.data.list": [ { "name": "xxx", "age": 50 }, [{ "test": 22 }] ],
|
||
"$.data.list[0]": { "name": "xxx", "age": 50 },
|
||
"$.data.list[0].name": "xxx",
|
||
"$.data.list[0].age": 50,
|
||
"$.data.list[1]": [ { "test": 22 } ],
|
||
"$.data.list[1][0]": { "test": 22 },
|
||
"$.data.list[1][0].test": 22,
|
||
"$.data.psw": "xxx"
|
||
}
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
{{< /tabs >}}
|
||
|
||
|
||
你可以配置对应的`key`来从`FastGPT 转化后的格式`获取需要的值,该规则遵守 JS 的对象取值规则。例如:
|
||
|
||
1. 获取`message`的内容,那么你可以配置`message`的`key`为`message`,这样就可以获取到`message`的内容。
|
||
2. 获取`user的name`,则`key`可以为:`data.user.name`。
|
||
3. 获取list中第二个元素,则`key`可以为:`data.list[1]`,然后输出类型选择字符串,则获自动获取到`[ { "test": 22 } ]`的`json`字符串。
|
||
|
||
### 自动格式化输出
|
||
|
||
FastGPT v4.6.8 后,加入了出参格式化功能,主要以`json`格式化成`字符串`为主。如果你的输出类型选择了`字符串`,则会将`HTTP`对应`key`的值,转成`json`字符串进行输出。因此,未来你可以直接从`HTTP`接口输出内容至`文本加工`中,然后拼接适当的提示词,最终输入给`AI对话`。
|
||
|
||
|
||
{{% alert context="warning" %}}
|
||
HTTP模块非常强大,你可以对接一些公开的API,来提高编排的功能。
|
||
|
||
如果你不想额外部署服务,可以使用 [Laf](https://laf.dev/) 来快速开发上线接口,即写即发,无需部署。
|
||
{{% /alert %}}
|
||
|
||
## laf 对接 HTTP 示例
|
||
|
||
|
||
下面是在 Laf 编写的 POST 请求示例:
|
||
|
||
```ts
|
||
import cloud from '@lafjs/cloud'
|
||
const db = cloud.database()
|
||
|
||
type RequestType = {
|
||
appId: string;
|
||
appointment: string;
|
||
action: 'post' | 'delete' | 'put' | 'get'
|
||
}
|
||
|
||
export default async function (ctx: FunctionContext) {
|
||
try {
|
||
// 从 body 中获取参数
|
||
const { appId, appointment, action } = ctx.body as RequestType
|
||
|
||
const parseBody = JSON.parse(appointment)
|
||
if (action === 'get') {
|
||
return await getRecord(parseBody)
|
||
}
|
||
if (action === 'post') {
|
||
return await createRecord(parseBody)
|
||
}
|
||
if (action === 'put') {
|
||
return await putRecord(parseBody)
|
||
}
|
||
if (action === 'delete') {
|
||
return await removeRecord(parseBody)
|
||
}
|
||
|
||
|
||
return {
|
||
response: "异常"
|
||
}
|
||
} catch (err) {
|
||
return {
|
||
response: "异常"
|
||
}
|
||
}
|
||
}
|
||
```
|
||
|
||
## 作用
|
||
|
||
通过 HTTP 模块你可以无限扩展,比如:
|
||
- 操作数据库
|
||
- 调用外部数据源
|
||
- 执行联网搜索
|
||
- 发送邮箱
|
||
- ....
|
||
|
||
|
||
## 相关示例
|
||
|
||
- [谷歌搜索](/docs/use-cases/app-cases/google_search/)
|
||
- [发送飞书webhook](/docs/use-cases/app-cases/feishu_webhook/)
|
||
- [实验室预约(操作数据库)](/docs/use-cases/app-cases/lab_appointment/)
|
||
|
||
# 知识库搜索引用合并
|
||
## FastGPT 知识库搜索引用合并模块介绍
|
||
|
||

|
||
|
||
## 作用
|
||
|
||
将多个知识库搜索结果合并成一个结果进行输出,并会通过 RRF 进行重新排序(根据排名情况),并且支持最大 tokens 过滤。
|
||
|
||
## 使用方法
|
||
|
||
AI对话只能接收一个知识库引用内容。因此,如果调用了多个知识库,无法直接引用所有知识库(如下图)
|
||
|
||

|
||
|
||
使用**知识库搜索引用合并**,可以把多个知识库的搜索结果合在一起。
|
||
|
||

|
||
|
||
## 可用例子:
|
||
|
||
1. 经过问题分类后对不同知识库进行检索,然后统一给一个 AI 进行回答,此时可以用到合并,不需要每个分支都添加一个 AI 对话。
|
||
|
||
# Laf 函数调用
|
||
## FastGPT Laf 函数调用模块介绍
|
||
|
||

|
||
|
||
## 介绍
|
||
|
||
`Laf 函数调用`模块可以调用 Laf 账号下的云函数,其工作原理与 HTTP 模块相同,有以下特殊特征:
|
||
|
||
- 只能使用 POST 请求
|
||
- 请求自带系统参数 systemParams,无需通过变量传递。
|
||
|
||
## 绑定 Laf 账号
|
||
|
||
要调用 Laf 云函数,首先需要绑定 Laf 账号和应用,并且在应用中创建云函数。
|
||
|
||
Laf 提供了 PAT(访问凭证) 来实现 Laf 平台外的快捷登录,可以访问 [Laf 文档](https://doc.Laf.run/zh/cli/#%E7%99%BB%E5%BD%95)查看详细如何获取 PAT。
|
||
|
||
在获取到 PAT 后,我们可以进入 FastGPT 的`账号页`或是在高级编排中的 `Laf模块` 对 Laf 账号进行绑定。Laf 账号是团队共享的,仅团队管理员可配置。
|
||
|
||
填入 PAT 验证后,选择需要绑定的应用(应用需要是 Running 状态),即可调用该应用下的云函数。
|
||
|
||

|
||
|
||
## 编写云函数
|
||
|
||
Laf 云函数拥有根据 interface 自动生成 OpenAPI 的能力,可以参照下面的代码编写云函数,以便自动生成 OpenAPI 文档。
|
||
|
||
`Laf模块`可以根据 OpenAPI 文档,自动识别出入参,无需手动添加数据类型。如果不会写 TS,可忽略,手动在 FastGPT 中添加参数即可。
|
||
|
||
```ts
|
||
import cloud from '@lafjs/cloud'
|
||
|
||
interface IRequestBody { // 自定义入参,FastGPT 传入的均为POST请求。
|
||
data1: string // 必填参数
|
||
data2?: string // 可选参数
|
||
}
|
||
|
||
interface RequestProps extends IRequestBody { // 完整入参,这个无需改动。
|
||
systemParams: { // 这是FastGPT默认会传递过来的参数
|
||
appId: string,
|
||
variables: string,
|
||
histories: string,
|
||
cTime: string,
|
||
chatId: string,
|
||
responseChatItemId: string
|
||
}
|
||
}
|
||
|
||
interface IResponse { // 响应内容
|
||
message: string // 必返回的参数
|
||
msg?: string; // 可选的返回参数
|
||
}
|
||
|
||
export default async function (ctx: FunctionContext): Promise<IResponse> {
|
||
const {
|
||
data1,
|
||
data2,
|
||
systemParams
|
||
}: RequestProps = ctx.body;
|
||
|
||
console.log({
|
||
data1,
|
||
data2,
|
||
systemParams
|
||
});
|
||
|
||
return {
|
||
message: 'ok',
|
||
msg: 'msg'
|
||
};
|
||
}
|
||
```
|
||
|
||
当然,你也可以在 Laf 平台上选择 fastgpt_template,快速生成该函数模板。
|
||
|
||
具体操作可以是,进入 Laf 的函数页面,新建函数(注意 fastgpt 只会调用 post 请求的函数),然后复制上面的代码或者点击更多模板搜索“fastgpt”,使用下面的模板
|
||
|
||

|
||
|
||
## FastGPT 中使用
|
||
|
||
在选择函数后,可以通过点击“同步参数”,自动同步云函数的参数到 FastGPT 中。当然也可以手动添加,手动修改后的参数不会被“同步参数”修改。
|
||
|
||

|
||
|
||
## 使用注意事项
|
||
|
||
### 调用报错
|
||
|
||
先在 laf 中调试函数,看是否正常调用。可以通过 console.log,打印入参,将入参放在 Laf 测试页面的 Body 中进行测试。
|
||
|
||
# 批量运行
|
||
## FastGPT 批量运行节点介绍和使用
|
||
|
||
## 节点概述
|
||
|
||
【**批量运行**】节点是 FastGPT V4.8.11 版本新增的一个重要功能模块。它允许工作流对数组类型的输入数据进行迭代处理,每次处理数组中的一个元素,并自动执行后续节点,直到完成整个数组的处理。
|
||
|
||
这个节点的设计灵感来自编程语言中的循环结构,但以可视化的方式呈现。
|
||
|
||

|
||
|
||
> 在程序中,节点可以理解为一个个 Function 或者接口。可以理解为它就是一个**步骤**。将多个节点一个个拼接起来,即可一步步的去实现最终的 AI 输出。
|
||
|
||
【**批量运行**】节点本质上也是一个 Function,它的主要职责是自动化地重复执行特定的工作流程。
|
||
|
||
## 核心特性
|
||
|
||
1. **数组批量处理**
|
||
- 支持输入数组类型数据
|
||
- 自动遍历数组元素
|
||
- 保持处理顺序
|
||
- 支持并行处理 (性能优化)
|
||
|
||
2. **自动迭代执行**
|
||
- 自动触发后续节点
|
||
- 支持条件终止
|
||
- 支持循环计数
|
||
- 维护执行上下文
|
||
|
||
3. **与其他节点协同**
|
||
- 支持与 AI 对话节点配合
|
||
- 支持与 HTTP 节点配合
|
||
- 支持与内容提取节点配合
|
||
- 支持与判断器节点配合
|
||
|
||
## 应用场景
|
||
|
||
【**批量运行**】节点的主要作用是通过自动化的方式扩展工作流的处理能力,使 FastGPT 能够更好地处理批量任务和复杂的数据处理流程。特别是在处理大规模数据或需要多轮迭代的场景下,批量运行节点能显著提升工作流的效率和自动化程度。
|
||
|
||
【**批量运行**】节点特别适合以下场景:
|
||
|
||
1. **批量数据处理**
|
||
- 批量翻译文本
|
||
- 批量总结文档
|
||
- 批量生成内容
|
||
|
||
2. **数据流水线处理**
|
||
- 对搜索结果逐条分析
|
||
- 对知识库检索结果逐条处理
|
||
- 对 HTTP 请求返回的数组数据逐项处理
|
||
|
||
3. **递归或迭代任务**
|
||
- 长文本分段处理
|
||
- 多轮优化内容
|
||
- 链式数据处理
|
||
|
||
## 使用方法
|
||
|
||
### 输入参数设置
|
||
|
||
【**批量运行**】节点需要配置两个核心输入参数:
|
||
|
||
1. **数组 (必填)**:接收一个数组类型的输入,可以是:
|
||
- 字符串数组 (`Array<string>`)
|
||
- 数字数组 (`Array<number>`)
|
||
- 布尔数组 (`Array<boolean>`)
|
||
- 对象数组 (`Array<object>`)
|
||
|
||
2. **循环体 (必填)**:定义每次循环需要执行的节点流程,包含:
|
||
- 循环体开始:标记循环开始的位置。
|
||
- 循环体结束:标记循环结束的位置,并可选择输出结果变量。
|
||
|
||
### 循环体配置
|
||
|
||

|
||
|
||
1. 在循环体内部,可以添加任意类型的节点,如:
|
||
- AI 对话节点
|
||
- HTTP 请求节点
|
||
- 内容提取节点
|
||
- 文本加工节点等
|
||
|
||
2. 循环体结束节点配置:
|
||
- 通过下拉菜单选择要输出的变量
|
||
- 该变量将作为当前循环的结果被收集
|
||
- 所有循环的结果将组成一个新的数组作为最终输出
|
||
|
||
## 场景示例
|
||
|
||
### 批量处理数组
|
||
|
||
假设我们有一个包含多个文本的数组,需要对每个文本进行 AI 处理。这是批量运行节点最基础也最常见的应用场景。
|
||
|
||
#### 实现步骤
|
||
|
||
1. 准备输入数组
|
||
|
||

|
||
|
||
使用【代码运行】节点创建测试数组:
|
||
|
||
```javascript
|
||
const texts = [
|
||
"这是第一段文本",
|
||
"这是第二段文本",
|
||
"这是第三段文本"
|
||
];
|
||
return { textArray: texts };
|
||
```
|
||
|
||
2. 配置批量运行节点
|
||
|
||

|
||
|
||
- 数组输入:选择上一步代码运行节点的输出变量 `textArray`。
|
||
- 循环体内添加一个【AI 对话】节点,用于处理每个文本。这里我们输入的 prompt 为:`请将这段文本翻译成英文`。
|
||
- 再添加一个【指定回复】节点,用于输出翻译后的文本。
|
||
- 循环体结束节点选择输出变量为 AI 回复内容。
|
||
|
||
#### 运行流程
|
||
|
||

|
||
|
||
1. 【代码运行】节点执行,生成测试数组
|
||
2. 【批量运行】节点接收数组,开始遍历
|
||
3. 对每个数组元素:
|
||
- 【AI 对话】节点处理当前元素
|
||
- 【指定回复】节点输出翻译后的文本
|
||
- 【循环体结束】节点收集处理结果
|
||
4. 完成所有元素处理后,输出结果数组
|
||
|
||
### 长文本翻译
|
||
|
||
在处理长文本翻译时,我们经常会遇到以下挑战:
|
||
|
||
- 文本长度超出 LLM 的 token 限制
|
||
- 需要保持翻译风格的一致性
|
||
- 需要维护上下文的连贯性
|
||
- 翻译质量需要多轮优化
|
||
|
||
【**批量运行**】节点可以很好地解决这些问题。
|
||
|
||
#### 实现步骤
|
||
|
||
1. 文本预处理与分段
|
||
|
||

|
||
|
||
使用【代码运行】节点进行文本分段,代码如下:
|
||
|
||
```javascript
|
||
const MAX_HEADING_LENGTH = 7; // 最大标题长度
|
||
const MAX_HEADING_CONTENT_LENGTH = 200; // 最大标题内容长度
|
||
const MAX_HEADING_UNDERLINE_LENGTH = 200; // 最大标题下划线长度
|
||
const MAX_HTML_HEADING_ATTRIBUTES_LENGTH = 100; // 最大HTML标题属性长度
|
||
const MAX_LIST_ITEM_LENGTH = 200; // 最大列表项长度
|
||
const MAX_NESTED_LIST_ITEMS = 6; // 最大嵌套列表项数
|
||
const MAX_LIST_INDENT_SPACES = 7; // 最大列表缩进空格数
|
||
const MAX_BLOCKQUOTE_LINE_LENGTH = 200; // 最大块引用行长度
|
||
const MAX_BLOCKQUOTE_LINES = 15; // 最大块引用行数
|
||
const MAX_CODE_BLOCK_LENGTH = 1500; // 最大代码块长度
|
||
const MAX_CODE_LANGUAGE_LENGTH = 20; // 最大代码语言长度
|
||
const MAX_INDENTED_CODE_LINES = 20; // 最大缩进代码行数
|
||
const MAX_TABLE_CELL_LENGTH = 200; // 最大表格单元格长度
|
||
const MAX_TABLE_ROWS = 20; // 最大表格行数
|
||
const MAX_HTML_TABLE_LENGTH = 2000; // 最大HTML表格长度
|
||
const MIN_HORIZONTAL_RULE_LENGTH = 3; // 最小水平分隔线长度
|
||
const MAX_SENTENCE_LENGTH = 400; // 最大句子长度
|
||
const MAX_QUOTED_TEXT_LENGTH = 300; // 最大引用文本长度
|
||
const MAX_PARENTHETICAL_CONTENT_LENGTH = 200; // 最大括号内容长度
|
||
const MAX_NESTED_PARENTHESES = 5; // 最大嵌套括号数
|
||
const MAX_MATH_INLINE_LENGTH = 100; // 最大行内数学公式长度
|
||
const MAX_MATH_BLOCK_LENGTH = 500; // 最大数学公式块长度
|
||
const MAX_PARAGRAPH_LENGTH = 1000; // 最大段落长度
|
||
const MAX_STANDALONE_LINE_LENGTH = 800; // 最大独立行长度
|
||
const MAX_HTML_TAG_ATTRIBUTES_LENGTH = 100; // 最大HTML标签属性长度
|
||
const MAX_HTML_TAG_CONTENT_LENGTH = 1000; // 最大HTML标签内容长度
|
||
const LOOKAHEAD_RANGE = 100; // 向前查找句子边界的字符数
|
||
|
||
const AVOID_AT_START = `[\\s\\]})>,']`; // 避免在开头匹配的字符
|
||
const PUNCTUATION = `[.!?…]|\\.{3}|[\\u2026\\u2047-\\u2049]|[\\p{Emoji_Presentation}\\p{Extended_Pictographic}]`; // 标点符号
|
||
const QUOTE_END = `(?:'(?=\`)|''(?=\`\`))`; // 引号结束
|
||
const SENTENCE_END = `(?:${PUNCTUATION}(?<!${AVOID_AT_START}(?=${PUNCTUATION}))|${QUOTE_END})(?=\\S|$)`; // 句子结束
|
||
const SENTENCE_BOUNDARY = `(?:${SENTENCE_END}|(?=[\\r\\n]|$))`; // 句子边界
|
||
const LOOKAHEAD_PATTERN = `(?:(?!${SENTENCE_END}).){1,${LOOKAHEAD_RANGE}}${SENTENCE_END}`; // 向前查找句子结束的模式
|
||
const NOT_PUNCTUATION_SPACE = `(?!${PUNCTUATION}\\s)`; // 非标点符号空格
|
||
const SENTENCE_PATTERN = `${NOT_PUNCTUATION_SPACE}(?:[^\\r\\n]{1,{MAX_LENGTH}}${SENTENCE_BOUNDARY}|[^\\r\\n]{1,{MAX_LENGTH}}(?=${PUNCTUATION}|$ {QUOTE_END})(?:${LOOKAHEAD_PATTERN})?)${AVOID_AT_START}*`; // 句子模式
|
||
|
||
const regex = new RegExp(
|
||
"(" +
|
||
// 1. Headings (Setext-style, Markdown, and HTML-style, with length constraints)
|
||
`(?:^(?:[#*=-]{1,${MAX_HEADING_LENGTH}}|\\w[^\\r\\n]{0,${MAX_HEADING_CONTENT_LENGTH}}\\r?\\n[-=]{2,${MAX_HEADING_UNDERLINE_LENGTH}}|<h[1-6][^>] {0,${MAX_HTML_HEADING_ATTRIBUTES_LENGTH}}>)[^\\r\\n]{1,${MAX_HEADING_CONTENT_LENGTH}}(?:</h[1-6]>)?(?:\\r?\\n|$))` +
|
||
"|" +
|
||
// New pattern for citations
|
||
`(?:\\[[0-9]+\\][^\\r\\n]{1,${MAX_STANDALONE_LINE_LENGTH}})` +
|
||
"|" +
|
||
// 2. List items (bulleted, numbered, lettered, or task lists, including nested, up to three levels, with length constraints)
|
||
`(?:(?:^|\\r?\\n)[ \\t]{0,3}(?:[-*+•]|\\d{1,3}\\.\\w\\.|\\[[ xX]\\])[ \\t]+${SENTENCE_PATTERN.replace(/{MAX_LENGTH}/g, String (MAX_LIST_ITEM_LENGTH))}` +
|
||
`(?:(?:\\r?\\n[ \\t]{2,5}(?:[-*+•]|\\d{1,3}\\.\\w\\.|\\[[ xX]\\])[ \\t]+${SENTENCE_PATTERN.replace(/{MAX_LENGTH}/g, String (MAX_LIST_ITEM_LENGTH))}){0,${MAX_NESTED_LIST_ITEMS}}` +
|
||
`(?:\\r?\\n[ \\t]{4,${MAX_LIST_INDENT_SPACES}}(?:[-*+•]|\\d{1,3}\\.\\w\\.|\\[[ xX]\\])[ \\t]+${SENTENCE_PATTERN.replace(/{MAX_LENGTH}/g, String (MAX_LIST_ITEM_LENGTH))}){0,${MAX_NESTED_LIST_ITEMS}})?)` +
|
||
"|" +
|
||
// 3. Block quotes (including nested quotes and citations, up to three levels, with length constraints)
|
||
`(?:(?:^>(?:>|\\s{2,}){0,2}${SENTENCE_PATTERN.replace(/{MAX_LENGTH}/g, String(MAX_BLOCKQUOTE_LINE_LENGTH))}\\r?\\n?){1,$ {MAX_BLOCKQUOTE_LINES}})` +
|
||
"|" +
|
||
// 4. Code blocks (fenced, indented, or HTML pre/code tags, with length constraints)
|
||
`(?:(?:^|\\r?\\n)(?:\`\`\`|~~~)(?:\\w{0,${MAX_CODE_LANGUAGE_LENGTH}})?\\r?\\n[\\s\\S]{0,${MAX_CODE_BLOCK_LENGTH}}?(?:\`\`\`|~~~)\\r?\\n?` +
|
||
`|(?:(?:^|\\r?\\n)(?: {4}|\\t)[^\\r\\n]{0,${MAX_LIST_ITEM_LENGTH}}(?:\\r?\\n(?: {4}|\\t)[^\\r\\n]{0,${MAX_LIST_ITEM_LENGTH}}){0,$ {MAX_INDENTED_CODE_LINES}}\\r?\\n?)` +
|
||
`|(?:<pre>(?:<code>)?[\\s\\S]{0,${MAX_CODE_BLOCK_LENGTH}}?(?:</code>)?</pre>))` +
|
||
"|" +
|
||
// 5. Tables (Markdown, grid tables, and HTML tables, with length constraints)
|
||
`(?:(?:^|\\r?\\n)(?:\\|[^\\r\\n]{0,${MAX_TABLE_CELL_LENGTH}}\\|(?:\\r?\\n\\|[-:]{1,${MAX_TABLE_CELL_LENGTH}}\\|){0,1}(?:\\r?\\n\\|[^\\r\\n]{0,$ {MAX_TABLE_CELL_LENGTH}}\\|){0,${MAX_TABLE_ROWS}}` +
|
||
`|<table>[\\s\\S]{0,${MAX_HTML_TABLE_LENGTH}}?</table>))` +
|
||
"|" +
|
||
// 6. Horizontal rules (Markdown and HTML hr tag)
|
||
`(?:^(?:[-*_]){${MIN_HORIZONTAL_RULE_LENGTH},}\\s*$|<hr\\s*/?>)` +
|
||
"|" +
|
||
// 10. Standalone lines or phrases (including single-line blocks and HTML elements, with length constraints)
|
||
`(?!${AVOID_AT_START})(?:^(?:<[a-zA-Z][^>]{0,${MAX_HTML_TAG_ATTRIBUTES_LENGTH}}>)?${SENTENCE_PATTERN.replace(/{MAX_LENGTH}/g, String (MAX_STANDALONE_LINE_LENGTH))}(?:</[a-zA-Z]+>)?(?:\\r?\\n|$))` +
|
||
"|" +
|
||
// 7. Sentences or phrases ending with punctuation (including ellipsis and Unicode punctuation)
|
||
`(?!${AVOID_AT_START})${SENTENCE_PATTERN.replace(/{MAX_LENGTH}/g, String(MAX_SENTENCE_LENGTH))}` +
|
||
"|" +
|
||
// 8. Quoted text, parenthetical phrases, or bracketed content (with length constraints)
|
||
"(?:" +
|
||
`(?<!\\w)\"\"\"[^\"]{0,${MAX_QUOTED_TEXT_LENGTH}}\"\"\"(?!\\w)` +
|
||
`|(?<!\\w)(?:['\"\`'"])[^\\r\\n]{0,${MAX_QUOTED_TEXT_LENGTH}}\\1(?!\\w)` +
|
||
`|(?<!\\w)\`[^\\r\\n]{0,${MAX_QUOTED_TEXT_LENGTH}}'(?!\\w)` +
|
||
`|(?<!\\w)\`\`[^\\r\\n]{0,${MAX_QUOTED_TEXT_LENGTH}}''(?!\\w)` +
|
||
`|\\([^\\r\\n()]{0,${MAX_PARENTHETICAL_CONTENT_LENGTH}}(?:\\([^\\r\\n()]{0,${MAX_PARENTHETICAL_CONTENT_LENGTH}}\\)[^\\r\\n()]{0,$ {MAX_PARENTHETICAL_CONTENT_LENGTH}}){0,${MAX_NESTED_PARENTHESES}}\\)` +
|
||
`|\\[[^\\r\\n\\[\\]]{0,${MAX_PARENTHETICAL_CONTENT_LENGTH}}(?:\\[[^\\r\\n\\[\\]]{0,${MAX_PARENTHETICAL_CONTENT_LENGTH}}\\][^\\r\\n\\[\\]]{0,$ {MAX_PARENTHETICAL_CONTENT_LENGTH}}){0,${MAX_NESTED_PARENTHESES}}\\]` +
|
||
`|\\$[^\\r\\n$]{0,${MAX_MATH_INLINE_LENGTH}}\\$` +
|
||
`|\`[^\`\\r\\n]{0,${MAX_MATH_INLINE_LENGTH}}\`` +
|
||
")" +
|
||
"|" +
|
||
// 9. Paragraphs (with length constraints)
|
||
`(?!${AVOID_AT_START})(?:(?:^|\\r?\\n\\r?\\n)(?:<p>)?${SENTENCE_PATTERN.replace(/{MAX_LENGTH}/g, String(MAX_PARAGRAPH_LENGTH))}(?:</p>)?(?=\\r? \\n\\r?\\n|$))` +
|
||
"|" +
|
||
// 11. HTML-like tags and their content (including self-closing tags and attributes, with length constraints)
|
||
`(?:<[a-zA-Z][^>]{0,${MAX_HTML_TAG_ATTRIBUTES_LENGTH}}(?:>[\\s\\S]{0,${MAX_HTML_TAG_CONTENT_LENGTH}}?</[a-zA-Z]+>|\\s*/>))` +
|
||
"|" +
|
||
// 12. LaTeX-style math expressions (inline and block, with length constraints)
|
||
`(?:(?:\\$\\$[\\s\\S]{0,${MAX_MATH_BLOCK_LENGTH}}?\\$\\$)|(?:\\$[^\\$\\r\\n]{0,${MAX_MATH_INLINE_LENGTH}}\\$))` +
|
||
"|" +
|
||
// 14. Fallback for any remaining content (with length constraints)
|
||
`(?!${AVOID_AT_START})${SENTENCE_PATTERN.replace(/{MAX_LENGTH}/g, String(MAX_STANDALONE_LINE_LENGTH))}` +
|
||
")",
|
||
"gmu"
|
||
);
|
||
|
||
function main({text}){
|
||
const chunks = [];
|
||
let currentChunk = '';
|
||
const tokens = countToken(text)
|
||
|
||
const matches = text.match(regex);
|
||
if (matches) {
|
||
matches.forEach((match) => {
|
||
if (currentChunk.length + match.length <= 1000) {
|
||
currentChunk += match;
|
||
} else {
|
||
if (currentChunk) {
|
||
chunks.push(currentChunk);
|
||
}
|
||
currentChunk = match;
|
||
}
|
||
});
|
||
if (currentChunk) {
|
||
chunks.push(currentChunk);
|
||
}
|
||
}
|
||
|
||
return {chunks, tokens};
|
||
}
|
||
```
|
||
|
||
这里我们用到了 [Jina AI 开源的一个强大的正则表达式](https://x.com/JinaAI_/status/1823756993108304135),它能利用所有可能的边界线索和启发式方法来精确切分文本。
|
||
|
||
2. 配置批量运行节点
|
||
|
||

|
||
|
||
- 数组输入:选择上一步代码运行节点的输出变量 `chunks`。
|
||
- 循环体内添加一个【代码运行】节点,对源文本进行格式化。
|
||
- 添加一个【搜索词库】节点,将专有名词的词库作为知识库,在翻译前进行搜索。
|
||
- 添加一个【AI 对话】节点,使用 CoT 思维链,让 LLM 显式地、系统地生成推理链条,展示翻译的完整思考过程。
|
||
- 添加一个【代码运行】节点,将【AI 对话】节点最后一轮的翻译结果提取出来。
|
||
- 添加一个【指定回复】节点,输出翻译后的文本。
|
||
- 循环体结束节点选择输出变量为【取出翻译文本】的输出变量 `result`。
|
||
|
||
# 问题分类
|
||
## FastGPT 问题分类模块介绍
|
||
|
||
## 特点
|
||
|
||
- 可重复添加
|
||
- 有外部输入
|
||
- 需要手动配置
|
||
- 触发执行
|
||
- function_call 模块
|
||
|
||

|
||
|
||
## 功能
|
||
|
||
可以将用户的问题进行分类,分类后执行不同操作。在一些较模糊的场景中,分类效果不是很明显。
|
||
|
||
## 参数说明
|
||
|
||
### 系统提示词
|
||
|
||
被放置在对话最前面,可用于补充说明分类内容的定义。例如问题会被分为:
|
||
|
||
1. 打招呼
|
||
2. Laf 常见问题
|
||
3. 其他问题
|
||
|
||
由于 Laf 不是一个明确的东西,需要给它一个定义,此时提示词里可以填入 Laf 的定义:
|
||
|
||
```
|
||
Laf 是云开发平台,可以快速的开发应用
|
||
Laf 是一个开源的 BaaS 开发平台(Backend as a Service)
|
||
Laf 是一个开箱即用的 serverless 开发平台
|
||
Laf 是一个集「函数计算」、「数据库」、「对象存储」等于一身的一站式开发平台
|
||
Laf 可以是开源版的腾讯云开发、开源版的 Google Firebase、开源版的 UniCloud
|
||
```
|
||
|
||
### 聊天记录
|
||
|
||
适当增加一些聊天记录,可以联系上下文进行分类。
|
||
|
||
### 用户问题
|
||
|
||
用户输入的内容。
|
||
|
||
### 分类内容
|
||
|
||
依然以这 3 个分类为例,可以看到最终组成的 Function。其中返回值由系统随机生成,不需要关心。
|
||
|
||
1. 打招呼
|
||
2. Laf 常见问题
|
||
3. 其他问题
|
||
|
||
```js
|
||
const agentFunction = {
|
||
name: agentFunName,
|
||
description: '判断用户问题的类型属于哪方面,返回对应的枚举字段',
|
||
parameters: {
|
||
type: 'object',
|
||
properties: {
|
||
type: {
|
||
type: 'string',
|
||
description: `打招呼,返回: abc;Laf 常见问题,返回:vvv;其他问题,返回:aaa`
|
||
enum: ["abc","vvv","aaa"]
|
||
}
|
||
},
|
||
required: ['type']
|
||
}
|
||
};
|
||
```
|
||
|
||
上面的 Function 必然会返回 `type = abc,vvv,aaa` 其中一个值,从而实现分类判断。
|
||
|
||
# 指定回复
|
||
## FastGPT 指定回复模块介绍
|
||
|
||
## 特点
|
||
|
||
- 可重复添加(防止复杂编排时线太乱,重复添加可以更美观)
|
||
- 可手动输入
|
||
- 可外部输入
|
||
- 会输出结果给客户端
|
||
|
||
指定回复模块通常用户特殊状态回复,回复内容有两种:
|
||
|
||
1. 一种是手动输入固定内容。
|
||
2. 一种是通过变量引用。
|
||
|
||
{{< figure
|
||
src="/imgs/specialreply.png"
|
||
alt=""
|
||
caption="图 1"
|
||
>}}
|
||
|
||
# 代码运行
|
||
## FastGPT 代码运行节点介绍
|
||
|
||

|
||
|
||
## 功能
|
||
|
||
可用于执行一段简单的 js 代码,用于进行一些复杂的数据处理。代码运行在沙盒中,无法进行网络请求、dom和异步操作。如需复杂操作,需外挂 HTTP 实现。
|
||
|
||
**注意事项**
|
||
|
||
- 私有化用户需要部署`fastgpt-sandbox` 镜像,并配置`SANDBOX_URL`环境变量。
|
||
- 沙盒最大运行 10s, 32M 内存限制。
|
||
|
||
|
||
## 变量输入
|
||
|
||
可在自定义输入中添加代码运行需要的变量,在代码的 main 函数中,可解构出相同名字的变量。
|
||
|
||
如上图,自定义输入中有 data1 和 data2 两个变量,main 函数中可以解构出相同名字的变量。
|
||
|
||
## 结果输出
|
||
|
||
务必返回一个 object 对象
|
||
|
||
自定义输出中,可以添加变量名来获取 object 对应 key 下的值。例如上图中,返回了一个对象:
|
||
|
||
```json
|
||
{
|
||
result: data1,
|
||
data2
|
||
}
|
||
```
|
||
|
||
他有 2 个 key:result和 data2(js 缩写,key=data2,value=data2)。这时候自定义输出中就可以添加 2 个变量来获取对应 key 下的 value。
|
||
|
||
## 内置 JS 全局变量
|
||
|
||
### delay 延迟
|
||
|
||
延迟 1 秒后返回
|
||
|
||
```js
|
||
async function main({data1, data2}){
|
||
await delay(1000)
|
||
return {
|
||
result: "111"
|
||
}
|
||
}
|
||
```
|
||
|
||
### countToken 统计 token
|
||
|
||
```js
|
||
function main({input}){
|
||
return {
|
||
result: countToken(input)
|
||
}
|
||
}
|
||
```
|
||
|
||

|
||
|
||
### strToBase64 字符串转 base64(4.8.11 版本新增)
|
||
|
||
可用于将 SVG 图片转换为 base64 格式展示。
|
||
|
||
```js
|
||
function main({input}){
|
||
|
||
return {
|
||
/*
|
||
param1: input 需要转换的字符串
|
||
param2: base64 prefix 前缀
|
||
*/
|
||
result: strToBase64(input,'data:image/svg+xml;base64,')
|
||
}
|
||
}
|
||
```
|
||
|
||

|
||
|
||
### createHmac 加密
|
||
|
||
与 node 中 crypto 的 createHmac 方法一致。
|
||
|
||
```js
|
||
function main({secret}){
|
||
const {sign,timestamp} = createHmac('sha256',secret)
|
||
|
||
return {
|
||
sign,timestamp
|
||
}
|
||
}
|
||
```
|
||
|
||
# 文本拼接
|
||
## FastGPT 文本加工模块介绍
|
||
|
||
## 特点
|
||
|
||
- 可重复添加
|
||
- 有外部输入
|
||
- 触发执行
|
||
- 手动配置
|
||
|
||

|
||
|
||
|
||
## 功能
|
||
对输入文本进行固定加工处理,入参仅支持字符串和数字格式,入参以变量形式使用在文本编辑区域。
|
||
|
||
根据上方示例图的处理方式,对任何输入都会在前面拼接“用户的问题是:”。
|
||
|
||
|
||
## 作用
|
||
|
||
给任意模块输入自定格式文本,或处理 AI 模块系统提示词。
|
||
|
||
## 示例
|
||
|
||
- [接入谷歌搜索](/docs/use-cases/app-cases/google_search/)
|
||
|
||
# 判断器
|
||
## FastGPT 判断器模块介绍
|
||
|
||
## 特点
|
||
|
||
- 可重复添加
|
||
- 有外部输入
|
||
- 触发执行
|
||
|
||

|
||
|
||
## 功能
|
||
|
||
对任意变量进行`IF`判断,若满足条件则执行`IF`分支,不满足条件执行`ELSE`分支。
|
||
|
||
|
||
上述例子中若「知识库引用」变量的长度等于0则执行`IF`分支,否则执行`ELSE`分支。
|
||
|
||
|
||
支持增加更多的判断条件和分支,同编程语言中的`IF`语句逻辑相同。
|
||
|
||
## 作用
|
||
|
||
适用场景有:让大模型做判断后输出固定内容,根据大模型回复内容判断是否触发后续模块。
|
||
|
||
# 工具调用&终止
|
||
## FastGPT 工具调用模块介绍
|
||
|
||

|
||
|
||
### **什么是工具**
|
||
|
||
工具可以是一个系统模块,例如:AI对话、知识库搜索、HTTP模块等。也可以是一个插件。
|
||
|
||
工具调用可以让 LLM 更动态的决策流程,而不都是固定的流程。(当然,缺点就是费tokens)
|
||
|
||
### **工具的组成**
|
||
|
||
1. 工具介绍。通常是模块的介绍或插件的介绍,这个介绍会告诉LLM,这个工具的作用是什么。
|
||
2. 工具参数。对于系统模块来说,工具参数已经是固定的,无需额外配置。对于插件来说,工具参数是一个可配置项。
|
||
|
||
### **工具是如何运行的**
|
||
|
||
要了解工具如何运行的,首先需要知道它的运行条件。
|
||
|
||
1. 需要工具的介绍(或者叫描述)。这个介绍会告诉LLM,这个工具的作用是什么,LLM会根据上下文语义,决定是否需要调用这个工具。
|
||
2. 工具的参数。有些工具调用时,可能需要一些特殊的参数。参数中有2个关键的值:`参数介绍`和`是否必须`。
|
||
|
||
结合工具的介绍、参数介绍和参数是否必须,LLM会决定是否调用这个工具。有以下几种情况:
|
||
|
||
1. 无参数的工具:直接根据工具介绍,决定是否需要执行。例如:获取当前时间。
|
||
2. 有参数的工具:
|
||
1. 无必须的参数:尽管上下文中,没有适合的参数,也可以调用该工具。但有时候,LLM会自己伪造一个参数。
|
||
2. 有必须的参数:如果没有适合的参数,LLM可能不会调用该工具。可以通过提示词,引导用户提供参数。
|
||
|
||
#### **工具调用逻辑**
|
||
|
||
在支持`函数调用`的模型中,可以一次性调用多个工具,调用逻辑如下:
|
||
|
||

|
||
|
||
### **怎么用**
|
||
|
||
|
||
| | |
|
||
| --- | --- |
|
||
|  |  |
|
||
</div>
|
||
|
||
|
||
高级编排中,拖动工具调用的连接点,可用的工具头部会出现一个菱形,可以将它与工具调用模块底部的菱形相连接。
|
||
|
||
被连接的工具,会自动分离工具输入与普通的输入,并且可以编辑`介绍`,可以通过调整介绍,使得该工具调用时机更加精确。
|
||
|
||
关于工具调用,如何调试仍然是一个玄学,所以建议,不要一次性增加太多工具,选择少量工具调优后再进一步尝试。
|
||
|
||
#### 用途
|
||
|
||
默认情况下,工具调用节点,在决定调用工具后,会将工具运行的结果,返回给AI,让 AI 对工具运行的结果进行总结输出。有时候,如果你不需要 AI 进行进一步的总结输出,可以使用该节点,将其接入对于工具流程的末尾。
|
||
|
||
如下图,在执行知识库搜索后,发送给了 HTTP 请求,搜索将不会返回搜索的结果给工具调用进行 AI 总结。
|
||
|
||

|
||
|
||
### 附加节点
|
||
|
||
当您使用了工具调用节点,同时就会出现工具调用终止节点和自定义变量节点,能够进一步提升工具调用的使用体验。
|
||
|
||
#### 工具调用终止
|
||
|
||
工具调用终止可用于结束本次调用,即可以接在某个工具后面,当工作流执行到这个节点时,便会强制结束本次工具调用,不再调用其他工具,也不会再调用 AI 针对工具调用结果回答问题。
|
||
|
||

|
||
|
||
### 自定义工具变量
|
||
|
||
自定义变量可以扩展工具的变量输入,即对于一些未被视作工具参数或无法工具调用的节点,可以自定义工具变量,填上对应的参数描述,那么工具调用便会相对应的调用这个节点,进而调用其之后的工作流。
|
||
|
||

|
||
|
||
### **相关示例**
|
||
|
||
- [谷歌搜索](https://doc.fastgpt.in/docs/use-cases/app-cases/google_search/)
|
||
- [发送飞书webhook](https://doc.fastgpt.in/docs/use-cases/app-cases/feishu_webhook/)
|
||
|
||
# 用户选择
|
||
## FastGPT 用户选择模块的使用说明
|
||
|
||
## 特点
|
||
|
||
- 用户交互
|
||
- 可重复添加
|
||
- 触发执行
|
||
|
||

|
||
|
||
## 功能
|
||
|
||
「用户选择」节点属于用户交互节点,当触发这个节点时,对话会进入“交互”状态,会记录工作流的状态,等用户完成交互后,继续向下执行工作流
|
||
|
||

|
||
|
||
比如上图中的例子,当触发用户选择节点时,对话框隐藏,对话进入“交互状态”
|
||
|
||

|
||
|
||
当用户做出选择时,节点会判断用户的选择,执行“是”的分支
|
||
|
||
## 作用
|
||
|
||
基础的用法为提出需要用户做抉择的问题,然后根据用户的反馈设计不同的工作流流程
|
||
|
||
# 变量更新
|
||
## FastGPT 变量更新模块介绍
|
||
|
||
## 特点
|
||
|
||
- 可重复添加
|
||
- 有外部输入
|
||
- 触发执行
|
||
- 手动配置
|
||
|
||

|
||
|
||
## 功能
|
||
|
||
- 更新指定节点的输出值
|
||
|
||

|
||
|
||

|
||
|
||
- 更新全局变量
|
||
|
||

|
||
|
||

|
||
|
||
## 作用
|
||
|
||
最基础的使用场景为
|
||
|
||
- 给一个「自定义变量」类型的全局变量赋值,从而实现全局变量无需用户输入
|
||
- 更新「变量更新」节点前的工作流节点输出,在后续使用中,使用的节点输出值为新的输出
|
||
|
||
# 知识库基础原理介绍
|
||
## 本节详细介绍RAG模型的核心机制、应用场景及其在生成任务中的优势与局限性。
|
||
|
||
[RAG文档](https://huggingface.co/docs/transformers/model_doc/rag)
|
||
|
||
# 1. 引言
|
||
|
||
随着自然语言处理(NLP)技术的迅猛发展,生成式语言模型(如GPT、BART等)在多种文本生成任务中表现卓越,尤其在语言生成和上下文理解方面。然而,纯生成模型在处理事实类任务时存在一些固有的局限性。例如,由于这些模型依赖于固定的预训练数据,它们在回答需要最新或实时信息的问题时,可能会出现“编造”信息的现象,导致生成结果不准确或缺乏事实依据。此外,生成模型在面对长尾问题和复杂推理任务时,常因缺乏特定领域的外部知识支持而表现不佳,难以提供足够的深度和准确性。
|
||
|
||
与此同时,检索模型(Retriever)能够通过在海量文档中快速找到相关信息,解决事实查询的问题。然而,传统检索模型(如BM25)在面对模糊查询或跨域问题时,往往只能返回孤立的结果,无法生成连贯的自然语言回答。由于缺乏上下文推理能力,检索模型生成的答案通常不够连贯和完整。
|
||
|
||
为了解决这两类模型的不足,检索增强生成模型(Retrieval-Augmented Generation,RAG)应运而生。RAG通过结合生成模型和检索模型的优势,实时从外部知识库中获取相关信息,并将其融入生成任务中,确保生成的文本既具备上下文连贯性,又包含准确的知识。这种混合架构在智能问答、信息检索与推理、以及领域特定的内容生成等场景中表现尤为出色。
|
||
|
||
## 1.1 RAG的定义
|
||
|
||
RAG是一种将信息检索与生成模型相结合的混合架构。首先,检索器从外部知识库或文档集中获取与用户查询相关的内容片段;然后,生成器基于这些检索到的内容生成自然语言输出,确保生成的内容既信息丰富,又具备高度的相关性和准确性。
|
||
|
||
# 2. RAG模型的核心机制
|
||
|
||
RAG 模型由两个主要模块构成:检索器(Retriever)与生成器(Generator)。这两个模块相互配合,确保生成的文本既包含外部的相关知识,又具备自然流畅的语言表达。
|
||
|
||
## 2.1 检索器(Retriever)
|
||
|
||
检索器的主要任务是从一个外部知识库或文档集中获取与输入查询最相关的内容。在RAG中,常用的技术包括:
|
||
|
||
- 向量检索:如BERT向量等,它通过将文档和查询转化为向量空间中的表示,并使用相似度计算来进行匹配。向量检索的优势在于能够更好地捕捉语义相似性,而不仅仅是依赖于词汇匹配。
|
||
- 传统检索算法:如BM25,主要基于词频和逆文档频率(TF-IDF)的加权搜索模型来对文档进行排序和检索。BM25适用于处理较为简单的匹配任务,尤其是当查询和文档中的关键词有直接匹配时。
|
||
|
||
RAG中检索器的作用是为生成器提供一个上下文背景,使生成器能够基于这些检索到的文档片段生成更为相关的答案。
|
||
|
||
## 2.2 生成器(Generator)
|
||
|
||
生成器负责生成最终的自然语言输出。在RAG系统中,常用的生成器包括:
|
||
|
||
- BART:BART是一种序列到序列的生成模型,专注于文本生成任务,可以通过不同层次的噪声处理来提升生成的质量 。
|
||
- GPT系列:GPT是一个典型的预训练语言模型,擅长生成流畅自然的文本。它通过大规模数据训练,能够生成相对准确的回答,尤其在任务-生成任务中表现尤为突出 。
|
||
|
||
生成器在接收来自检索器的文档片段后,会利用这些片段作为上下文,并结合输入的查询,生成相关且自然的文本回答。这确保了模型的生成结果不仅仅基于已有的知识,还能够结合外部最新的信息。
|
||
|
||
## 2.3 RAG的工作流程
|
||
|
||
RAG模型的工作流程可以总结为以下几个步骤:
|
||
|
||
1. 输入查询:用户输入问题,系统将其转化为向量表示。
|
||
2. 文档检索:检索器从知识库中提取与查询最相关的文档片段,通常使用向量检索技术或BM25等传统技术进行。
|
||
3. 生成答案:生成器接收检索器提供的片段,并基于这些片段生成自然语言答案。生成器不仅基于原始的用户查询,还会利用检索到的片段提供更加丰富、上下文相关的答案。
|
||
4. 输出结果:生成的答案反馈给用户,这个过程确保了用户能够获得基于最新和相关信息的准确回答。
|
||
|
||
# 3. RAG模型的工作原理
|
||
|
||
## 3.1 检索阶段
|
||
|
||
在RAG模型中,用户的查询首先被转化为向量表示,然后在知识库中执行向量检索。通常,检索器采用诸如BERT等预训练模型生成查询和文档片段的向量表示,并通过相似度计算(如余弦相似度)匹配最相关的文档片段。RAG的检索器不仅仅依赖简单的关键词匹配,而是采用语义级别的向量表示,从而在面对复杂问题或模糊查询时,能够更加准确地找到相关知识。这一步骤对于最终生成的回答至关重要,因为检索的效率和质量直接决定了生成器可利用的上下文信息 。
|
||
|
||
## 3.2 生成阶段
|
||
|
||
生成阶段是RAG模型的核心部分,生成器负责基于检索到的内容生成连贯且自然的文本回答。RAG中的生成器,如BART或GPT等模型,结合用户输入的查询和检索到的文档片段,生成更加精准且丰富的答案。与传统生成模型相比,RAG的生成器不仅能够生成语言流畅的回答,还可以根据外部知识库中的实际信息提供更具事实依据的内容,从而提高了生成的准确性 。
|
||
|
||
## 3.3 多轮交互与反馈机制
|
||
|
||
RAG模型在对话系统中能够有效支持多轮交互。每一轮的查询和生成结果会作为下一轮的输入,系统通过分析和学习用户的反馈,逐步优化后续查询的上下文。通过这种循环反馈机制,RAG能够更好地调整其检索和生成策略,使得在多轮对话中生成的答案越来越符合用户的期望。此外,多轮交互还增强了RAG在复杂对话场景中的适应性,使其能够处理跨多轮的知识整合和复杂推理 。
|
||
|
||
# 4. RAG的优势与局限
|
||
|
||
## 4.1 优势
|
||
|
||
- 信息完整性:RAG 模型结合了检索与生成技术,使得生成的文本不仅语言自然流畅,还能够准确利用外部知识库提供的实时信息。这种方法能够显著提升生成任务的准确性,特别是在知识密集型场景下,如医疗问答或法律意见生成。通过从知识库中检索相关文档,RAG 模型避免了生成模型“编造”信息的风险,确保输出更具真实性 。
|
||
- 知识推理能力:RAG 能够利用大规模的外部知识库进行高效检索,并结合这些真实数据进行推理,生成基于事实的答案。相比传统生成模型,RAG 能处理更为复杂的任务,特别是涉及跨领域或跨文档的推理任务。例如,法律领域的复杂判例推理或金融领域的分析报告生成都可以通过RAG的推理能力得到优化 。
|
||
- 领域适应性强:RAG 具有良好的跨领域适应性,能够根据不同领域的知识库进行特定领域内的高效检索和生成。例如,在医疗、法律、金融等需要实时更新和高度准确性的领域,RAG 模型的表现优于仅依赖预训练的生成模型 。
|
||
|
||
## 4.2 局限
|
||
|
||
RAG(检索增强生成)模型通过结合检索器和生成器,实现了在多种任务中知识密集型内容生成的突破性进展。然而,尽管其具有较强的应用潜力和跨领域适应能力,但在实际应用中仍然面临着一些关键局限,限制了其在大规模系统中的部署和优化。以下是RAG模型的几个主要局限性:
|
||
|
||
#### 4.2.1 检索器的依赖性与质量问题
|
||
|
||
RAG模型的性能很大程度上取决于检索器返回的文档质量。由于生成器主要依赖检索器提供的上下文信息,如果检索到的文档片段不相关、不准确,生成的文本可能出现偏差,甚至产生误导性的结果。尤其在多模糊查询或跨领域检索的情况下,检索器可能无法找到合适的片段,这将直接影响生成内容的连贯性和准确性。
|
||
|
||
- 挑战:当知识库庞大且内容多样时,如何提高检索器在复杂问题下的精确度是一大挑战。当前的方法如BM25等在特定任务上有局限,尤其是在面对语义模糊的查询时,传统的关键词匹配方式可能无法提供语义上相关的内容。
|
||
- 解决途径:引入混合检索技术,如结合稀疏检索(BM25)与密集检索(如向量检索)。例如,Faiss的底层实现允许通过BERT等模型生成密集向量表示,显著提升语义级别的匹配效果。通过这种方式,检索器可以捕捉深层次的语义相似性,减少无关文档对生成器的负面影响。
|
||
|
||
#### 4.2.2 生成器的计算复杂度与性能瓶颈
|
||
|
||
RAG模型将检索和生成模块结合,尽管生成结果更加准确,但也大大增加了模型的计算复杂度。尤其在处理大规模数据集或长文本时,生成器需要处理来自多个文档片段的信息,导致生成时间明显增加,推理速度下降。对于实时问答系统或其他需要快速响应的应用场景,这种高计算复杂度是一个主要瓶颈。
|
||
|
||
- 挑战:当知识库规模扩大时,检索过程中的计算开销以及生成器在多片段上的整合能力都会显著影响系统的效率。同时,生成器也面临着资源消耗的问题,尤其是在多轮对话或复杂生成任务中,GPU和内存的消耗会成倍增加。
|
||
- 解决途径:使用模型压缩技术和知识蒸馏来减少生成器的复杂度和推理时间。此外,分布式计算与模型并行化技术的引入,如[DeepSpeed](https://www.deepspeed.ai/)和模型压缩工具,可以有效应对生成任务的高计算复杂度,提升大规模应用场景中的推理效率。
|
||
|
||
#### 4.2.3 知识库的更新与维护
|
||
|
||
RAG模型通常依赖于一个预先建立的外部知识库,该知识库可能包含文档、论文、法律条款等各类信息。然而,知识库内容的时效性和准确性直接影响到RAG生成结果的可信度。随着时间推移,知识库中的内容可能过时,导致生成的回答不能反映最新的信息。这对于需要实时信息的场景(如医疗、金融)尤其明显。
|
||
|
||
- 挑战:知识库需要频繁更新,但手动更新知识库既耗时又容易出错。如何在不影响系统性能的情况下实现知识库的持续自动更新是当前的一大挑战。
|
||
- 解决途径:利用自动化爬虫和信息提取系统,可以实现对知识库的自动化更新,例如,Scrapy等爬虫框架可以自动抓取网页数据并更新知识库。结合[动态索引技术](https://arxiv.org/pdf/2102.03315),可以帮助检索器实时更新索引,确保知识库反映最新信息。同时,结合增量学习技术,生成器可以逐步吸收新增的信息,避免生成过时答案。此外,动态索引技术也可以帮助检索器实时更新索引,确保知识库检索到的文档反映最新的内容。
|
||
|
||
#### 4.2.4 生成内容的可控性与透明度
|
||
|
||
RAG模型结合了检索与生成模块,在生成内容的可控性和透明度上存在一定问题。特别是在复杂任务或多义性较强的用户输入情况下,生成器可能会基于不准确的文档片段生成错误的推理,导致生成的答案偏离实际问题。此外,由于RAG模型的“黑箱”特性,用户难以理解生成器如何利用检索到的文档信息,这在高敏感领域如法律或医疗中尤为突出,可能导致用户对生成内容产生不信任感。
|
||
|
||
- 挑战:模型透明度不足使得用户难以验证生成答案的来源和可信度。对于需要高可解释性的任务(如医疗问诊、法律咨询等),无法追溯生成答案的知识来源会导致用户不信任模型的决策。
|
||
- 解决途径:为提高透明度,可以引入可解释性AI(XAI)技术,如LIME或SHAP([链接](https://github.com/marcotcr/lime)),为每个生成答案提供详细的溯源信息,展示所引用的知识片段。这种方法能够帮助用户理解模型的推理过程,从而增强对模型输出的信任。此外,针对生成内容的控制,可以通过加入规则约束或用户反馈机制,逐步优化生成器的输出,确保生成内容更加可信。
|
||
|
||
# 5. RAG整体改进方向
|
||
|
||
RAG模型的整体性能依赖于知识库的准确性和检索的效率,因此在数据采集、内容分块、精准检索和回答生成等环节进行优化,是提升模型效果的关键。通过加强数据来源、改进内容管理、优化检索策略及提升回答生成的准确性,RAG模型能够更加适应复杂且动态的实际应用需求。
|
||
|
||
## 5.1 数据采集与知识库构建
|
||
|
||
RAG模型的核心依赖在于知识库的数据质量和广度,知识库在某种程度上充当着“外部记忆”的角色。因此,高质量的知识库不仅应包含广泛领域的内容,更要确保数据来源的权威性、可靠性以及时效性。知识库的数据源应涵盖多种可信的渠道,例如科学文献数据库(如PubMed、IEEE Xplore)、权威新闻媒体、行业标准和报告等,这样才能提供足够的背景信息支持RAG在不同任务中的应用。此外,为了确保RAG模型能够提供最新的回答,知识库需要具备自动化更新的能力,以避免数据内容老旧,导致回答失准或缺乏现实参考。
|
||
|
||
- 挑战:
|
||
- 尽管数据采集是构建知识库的基础,但在实际操作中仍存在以下几方面的不足:
|
||
- 数据采集来源单一或覆盖不全
|
||
1. RAG模型依赖多领域数据的支持,然而某些知识库过度依赖单一或有限的数据源,通常集中在某些领域,导致在多任务需求下覆盖不足。例如,依赖医学领域数据而缺乏法律和金融数据会使RAG模型在跨领域问答中表现不佳。这种局限性削弱了RAG模型在处理不同主题或多样化查询时的准确性,使得系统在应对复杂或跨领域任务时能力欠缺。
|
||
- 数据质量参差不齐
|
||
1. 数据源的质量差异直接影响知识库的可靠性。一些数据可能来源于非权威或低质量渠道,存在偏见、片面或不准确的内容。这些数据若未经筛选录入知识库,会导致RAG模型生成偏差或不准确的回答。例如,在医学领域中,如果引入未经验证的健康信息,可能导致模型给出误导性回答,产生负面影响。数据质量不一致的知识库会大大降低模型输出的可信度和适用性。
|
||
- 缺乏定期更新机制
|
||
1. 许多知识库缺乏自动化和频繁的更新机制,特别是在信息变动频繁的领域,如法律、金融和科技。若知识库长期未更新,则RAG模型无法提供最新信息,生成的回答可能过时或不具备实时参考价值。对于用户而言,特别是在需要实时信息的场景下,滞后的知识库会显著影响RAG模型的可信度和用户体验。
|
||
- 数据处理耗时且易出错
|
||
1. 数据的采集、清洗、分类和结构化处理是一项繁琐而复杂的任务,尤其是当数据量巨大且涉及多种格式时。通常,大量数据需要人工参与清洗和结构化,而自动化处理流程也存在缺陷,可能会产生错误或遗漏关键信息。低效和易出错的数据处理流程会导致知识库内容不准确、不完整,进而影响RAG模型生成的答案的准确性和连贯性。
|
||
- 数据敏感性和隐私问题
|
||
1. 一些特定领域的数据(如医疗、法律、金融)包含敏感信息,未经适当的隐私保护直接引入知识库可能带来隐私泄露的风险。此外,某些敏感数据需要严格的授权和安全存储,以确保在知识库使用中避免违规或隐私泄漏。若未能妥善处理数据隐私问题,不仅会影响系统的合规性,还可能对用户造成严重后果。
|
||
- 改进:
|
||
- 针对以上不足,可以从以下几个方面进行改进,以提高数据采集和知识库构建的有效性:
|
||
- 扩大数据源覆盖范围,增加数据的多样性
|
||
1. 具体实施:将知识库的数据源扩展至多个重要领域,确保包含医疗、法律、金融等关键领域的专业数据库,如PubMed、LexisNexis和金融数据库。使用具有开放许可的开源数据库和经过认证的数据,确保来源多样化且权威性强。
|
||
2. 目的与效果:通过跨领域数据覆盖,知识库的广度和深度得以增强,确保RAG模型能够在多任务场景下提供可靠回答。借助多领域合作机构的数据支持,在应对多样化需求时将更具优势。
|
||
- 构建数据质量审查与过滤机制
|
||
1. 具体实施:采用自动化数据质量检测算法,如文本相似度检查、情感偏差检测等工具,结合人工审查过滤不符合标准的数据。为数据打分并构建“数据可信度评分”,基于来源可信度、内容完整性等指标筛选数据。
|
||
2. 目的与效果:减少低质量、偏见数据的干扰,确保知识库内容的可靠性。此方法保障了RAG模型输出的权威性,特别在回答复杂或专业问题时,用户能够获得更加精准且中立的答案。
|
||
- 实现知识库的自动化更新
|
||
1. 具体实施:引入自动化数据更新系统,如网络爬虫,定期爬取可信站点、行业数据库的最新数据,并利用变化检测算法筛选出与已有知识库重复或已失效的数据。更新机制可以结合智能筛选算法,仅采纳与用户查询高相关性或时效性强的数据。
|
||
2. 目的与效果:知识库保持及时更新,确保模型在快速变化的领域(如金融、政策、科技)中提供最新信息。用户体验将因此大幅提升,特别是在需要动态或最新信息的领域,输出的内容将更具时效性。
|
||
- 采用高效的数据清洗与分类流程
|
||
1. 具体实施:使用自然语言处理技术,如BERT等模型进行数据分类、实体识别和文本去噪,结合去重算法清理重复内容。采用自动化的数据标注和分类算法,将不同数据类型分领域存储。
|
||
2. 目的与效果:数据清洗和分领域管理可以大幅提高数据处理的准确性,减少低质量数据的干扰。此改进确保RAG模型的回答生成更流畅、上下文更连贯,提升用户对生成内容的理解和信赖。
|
||
- 强化数据安全与隐私保护措施
|
||
1. 具体实施:针对医疗、法律等敏感数据,采用去标识化处理技术(如数据脱敏、匿名化等),并结合差分隐私保护。建立数据权限管理和加密存储机制,对敏感信息进行严格管控。
|
||
2. 目的与效果:在保护用户隐私的前提下,确保使用的数据合规、安全,适用于涉及个人或敏感数据的应用场景。此措施进一步保证了系统的法律合规性,并有效防止隐私泄露风险。
|
||
- 优化数据格式与结构的标准化
|
||
1. 具体实施:建立统一的数据格式与标准编码格式,例如使用JSON、XML或知识图谱形式组织结构化数据,以便于检索系统在查询时高效利用。同时,使用知识图谱等结构化工具,将复杂数据间的关系进行系统化存储。
|
||
2. 目的与效果:提高数据检索效率,确保模型在生成回答时能够高效使用数据的关键信息。标准化的数据结构支持高效的跨领域检索,并提高了RAG模型的内容准确性和知识关系的透明度。
|
||
- 用户反馈机制
|
||
1. 具体实施:通过用户反馈系统,记录用户对回答的满意度、反馈意见及改进建议。使用机器学习算法从反馈中识别知识库中的盲区与信息误差,反馈至数据管理流程中进行更新和优化。
|
||
2. 目的与效果:利用用户反馈作为数据质量的调整依据,帮助知识库持续优化内容。此方法不仅提升了RAG模型的实际效用,还使知识库更贴合用户需求,确保输出内容始终符合用户期望。
|
||
|
||
## 5.2 数据分块与内容管理
|
||
|
||
RAG模型的数据分块与内容管理是优化检索与生成流程的关键。合理的分块策略能够帮助模型高效定位目标信息,并在回答生成时提供清晰的上下文支持。通常情况下,将数据按段落、章节或主题进行分块,不仅有助于检索效率的提升,还能避免冗余数据对生成内容造成干扰。尤其在复杂、长文本中,适当的分块策略可保证模型生成的答案具备连贯性、精确性,避免出现内容跳跃或上下文断裂的问题。
|
||
|
||
- 挑战:
|
||
- 在实际操作中,数据分块与内容管理环节存在以下问题:
|
||
- 分块不合理导致的信息断裂
|
||
1. 部分文本过度切割或分块策略不合理,可能导致信息链条被打断,使得模型在回答生成时缺乏必要的上下文支持。这会使生成内容显得零散,不具备连贯性,影响用户对答案的理解。例如,将法律文本或技术文档随意切割成小段落会导致重要的上下文关系丢失,降低模型的回答质量。
|
||
- 冗余数据导致生成内容重复或信息过载
|
||
1. 数据集中往往包含重复信息,若不去重或优化整合,冗余数据可能导致生成内容的重复或信息过载。这不仅影响用户体验,还会浪费计算资源。例如,在新闻数据或社交媒体内容中,热点事件的描述可能重复出现,模型在生成回答时可能反复引用相同信息。
|
||
- 分块粒度选择不当影响检索精度
|
||
1. 如果分块粒度过细,模型可能因缺乏足够的上下文而生成不准确的回答;若分块过大,检索时将难以定位具体信息,导致回答内容冗长且含有无关信息。选择适当的分块粒度对生成答案的准确性和相关性至关重要,特别是在问答任务中需要精确定位答案的情况下,粗放的分块策略会明显影响用户的阅读体验和回答的可读性。
|
||
- 难以实现基于主题或内容逻辑的分块
|
||
1. 某些复杂文本难以直接按主题或逻辑结构进行分块,尤其是内容密集或领域专业性较强的数据。基于关键字或简单的规则切割往往难以识别不同主题和信息层次,导致模型在回答生成时信息杂乱。对内容逻辑或主题的错误判断,尤其是在医学、金融等场景下,会大大影响生成答案的准确度和专业性。
|
||
- 改进:
|
||
- 为提高数据分块和内容管理的有效性,可以从以下几方面进行优化:
|
||
- 引入NLP技术进行自动化分块和上下文分析
|
||
1. 具体实施:借助自然语言处理(NLP)技术,通过句法分析、语义分割等方式对文本进行逻辑切割,以确保分块的合理性。可以基于BERT等预训练模型实现主题识别和上下文分析,确保每个片段均具备完整的信息链,避免信息断裂。
|
||
2. 目的与效果:确保文本切割基于逻辑或语义关系,避免信息链条被打断,生成答案时能够更具连贯性,尤其适用于长文本和复杂结构的内容,使模型在回答时上下文更加完整、连贯。
|
||
- 去重与信息整合,优化内容简洁性
|
||
1. 具体实施:利用相似度算法(如TF-IDF、余弦相似度)识别冗余内容,并结合聚类算法自动合并重复信息。针对内容频繁重复的情况,可设置内容标记或索引,避免生成时多次引用相同片段。
|
||
2. 目的与效果:通过去重和信息整合,使数据更具简洁性,避免生成答案中出现重复信息。减少冗余信息的干扰,使用户获得简明扼要的回答,增强阅读体验,同时提升生成过程的计算效率。
|
||
- 根据任务需求动态调整分块粒度
|
||
1. 具体实施:根据模型任务的不同,设置动态分块策略。例如,在问答任务中对关键信息较短的内容可采用小粒度分块,而在长文本或背景性内容中采用较大粒度。分块策略可基于查询需求或内容复杂度自动调整。
|
||
2. 目的与效果:分块粒度的动态调整确保模型在检索和生成时既能准确定位关键内容,又能为回答提供足够的上下文支持,提升生成内容的精准性和相关性,确保用户获取的信息既准确又不冗长。
|
||
- 引入基于主题的分块方法以提升上下文完整性
|
||
1. 具体实施:使用主题模型(如LDA)或嵌入式文本聚类技术,对文本内容按主题进行自动分类与分块。基于相同主题内容的聚合分块,有助于模型识别不同内容层次,尤其适用于复杂的学术文章或多章节的长篇报告。
|
||
2. 目的与效果:基于主题的分块确保同一主题的内容保持在一个片段内,提升模型在回答生成时的上下文连贯性。适用于主题复杂、层次清晰的内容场景,提高回答的专业性和条理性,使用户更容易理解生成内容的逻辑关系。
|
||
- 实时评估分块策略与内容呈现效果的反馈机制
|
||
1. 具体实施:通过用户反馈机制和生成质量评估系统实时监测生成内容的连贯性和准确性。对用户反馈中涉及分块效果差的部分进行重新分块,通过用户使用数据优化分块策略。
|
||
2. 目的与效果:用户反馈帮助识别不合理的分块和内容呈现问题,实现分块策略的动态优化,持续提升生成内容的质量和用户满意度。
|
||
|
||
## 5.3 检索优化
|
||
|
||
在RAG模型中,检索模块决定了生成答案的相关性和准确性。有效的检索策略可确保模型获取到最适合的上下文片段,使生成的回答更加精准且贴合查询需求。常用的混合检索策略(如BM25和DPR结合)能够在关键词匹配和语义检索方面实现优势互补:BM25适合高效地处理关键字匹配任务,而DPR在理解深层语义上表现更为优异。因此,合理选用检索策略有助于在不同任务场景下达到计算资源和检索精度的平衡,以高效提供相关上下文供生成器使用。
|
||
|
||
- 挑战:
|
||
- 检索优化过程中,仍面临以下不足之处:
|
||
- 检索策略单一导致的回答偏差
|
||
1. 当仅依赖BM25或DPR等单一技术时,模型可能难以平衡关键词匹配与语义理解。BM25在处理具象关键字时表现良好,但在面对复杂、含义丰富的语义查询时效果欠佳;相反,DPR虽然具备深度语义匹配能力,但对高频关键词匹配的敏感度较弱。检索策略单一将导致模型难以适应复杂的用户查询,回答中出现片面性或不够精准的情况。
|
||
- 检索效率与资源消耗的矛盾
|
||
1. 检索模块需要在短时间内处理大量查询,而语义检索(如DPR)需要进行大量的计算和存储操作,计算资源消耗高,影响系统响应速度。特别是对于需要实时响应的应用场景,DPR的计算复杂度往往难以满足实际需求,因此在实时性和资源利用率上亟需优化。
|
||
- 检索结果的冗余性导致内容重复
|
||
1. 当检索策略未对结果进行去重或排序优化时,RAG模型可能从知识库中检索出相似度高但内容冗余的文档片段。这会导致生成的回答中包含重复信息,影响阅读体验,同时增加无效信息的比例,使用户难以迅速获取核心答案。
|
||
- 不同任务需求下检索策略的适配性差
|
||
1. RAG模型应用场景丰富,但不同任务对检索精度、速度和上下文长度的需求不尽相同。固定检索策略难以灵活应对多样化的任务需求,导致在应对不同任务时,模型检索效果受限。例如,面向精确性较高的医疗问答场景时,检索策略应偏向语义准确性,而在热点新闻场景中则应偏重检索速度。
|
||
- 改进:
|
||
- 针对上述不足,可以从以下几个方面优化检索模块:
|
||
- 结合BM25与DPR的混合检索策略
|
||
1. 具体实施:采用BM25进行关键词初筛,快速排除无关信息,然后使用DPR进行深度语义匹配筛选。这样可以有效提升检索精度,平衡关键词匹配和语义理解。
|
||
2. 目的与效果:通过多层筛选过程,确保检索结果在语义理解和关键词匹配方面互补,提升生成内容的准确性,特别适用于多意图查询或复杂的长文本检索。
|
||
- 优化检索效率,控制计算资源消耗
|
||
1. 具体实施:利用缓存机制存储近期高频查询结果,避免对相似查询的重复计算。同时,可基于分布式计算结构,将DPR的语义计算任务分散至多节点并行处理。
|
||
2. 目的与效果:缓存与分布式计算结合可显著减少检索计算压力,使系统能够在有限资源下提高响应速度,适用于高并发、实时性要求高的应用场景。
|
||
- 引入去重和排序优化算法
|
||
1. 具体实施:在检索结果中应用余弦相似度去重算法,筛除冗余内容,并基于用户偏好或时间戳对检索结果排序,以确保输出内容的丰富性和新鲜度。
|
||
2. 目的与效果:通过去重和优化排序,确保生成内容更加简洁、直接,减少重复信息的干扰,提高用户获取信息的效率和体验。
|
||
- 动态调整检索策略适应多任务需求
|
||
1. 具体实施:设置不同检索策略模板,根据任务类型自动调整检索权重、片段长度和策略组合。例如在医疗场景中偏向语义检索,而在金融新闻场景中更重视快速关键词匹配。
|
||
2. 目的与效果:动态调整检索策略使RAG模型更加灵活,能够适应不同任务需求,确保检索的精准性和生成答案的上下文适配性,显著提升多场景下的用户体验。
|
||
- 借助Haystack等检索优化框架
|
||
1. 具体实施:在RAG模型中集成Haystack框架,以实现更高效的检索效果,并利用框架中的插件生态系统来增强检索模块的可扩展性和可调节性。
|
||
2. 目的与效果:Haystack提供了检索和生成的整合接口,有助于快速优化检索模块,并适应复杂多样的用户需求,在多任务环境中提供更稳定的性能表现。
|
||
|
||
## 5.4 回答生成与优化
|
||
|
||
在RAG模型中,生成器负责基于检索模块提供的上下文,为用户查询生成自然语言答案。生成内容的准确性和逻辑性直接决定了用户的体验,因此优化生成器的表现至关重要。通过引入知识图谱等结构化信息,生成器能够更准确地理解和关联上下文,从而生成逻辑连贯、准确的回答。此外,生成器的生成逻辑可结合用户反馈持续优化,使回答风格和内容更加符合用户需求。
|
||
|
||
- 挑战:
|
||
- 在回答生成过程中,RAG模型仍面临以下不足:
|
||
- 上下文不充分导致的逻辑不连贯
|
||
1. 当生成器在上下文缺失或信息不完整的情况下生成回答时,生成内容往往不够连贯,特别是在处理复杂、跨领域任务时。这种缺乏上下文支持的问题,容易导致生成器误解或忽略关键信息,最终生成内容的逻辑性和完整性欠佳。如在医学场景中,若生成器缺少对病例或症状的全面理解,可能导致回答不准确或不符合逻辑,影响专业性和用户信任度。
|
||
- 专业领域回答的准确性欠佳
|
||
1. 在医学、法律等高专业领域中,生成器的回答需要高度的准确性。然而,生成器可能因缺乏特定知识而生成不符合领域要求的回答,出现内容偏差或理解错误,尤其在涉及专业术语和复杂概念时更为明显。如在法律咨询中,生成器可能未能正确引用相关法条或判例,导致生成的答案不够精确,甚至可能产生误导。
|
||
- 难以有效整合多轮用户反馈
|
||
1. 生成器缺乏有效机制来利用多轮用户反馈进行自我优化。用户反馈可能涉及回答内容的准确性、逻辑性以及风格适配等方面,但生成器在连续对话中缺乏充分的调节机制,难以持续调整生成策略和回答风格。如在客服场景中,生成器可能连续生成不符合用户需求的回答,降低了用户满意度。
|
||
- 生成内容的可控性和一致性不足
|
||
1. 在特定领域回答生成中,生成器的输出往往不具备足够的可控性和一致性。由于缺乏领域特定的生成规则和约束,生成内容的专业性和风格一致性欠佳,难以满足高要求的应用场景。如在金融报告生成中,生成内容需要确保一致的风格和术语使用,否则会影响输出的专业性和可信度。
|
||
- 改进:
|
||
- 针对以上不足,可以从以下方面优化回答生成模块:
|
||
- 引入知识图谱与结构化数据,增强上下文理解
|
||
1. 具体实施:结合知识图谱或知识库,将医学、法律等专业领域的信息整合到生成过程中。生成器在生成回答时,可以从知识图谱中提取关键信息和关联知识点,确保回答具备连贯的逻辑链条。
|
||
2. 目的与效果:知识图谱的引入提升了生成内容的连贯性和准确性,尤其在高专业性领域中,通过丰富的上下文理解,使生成器能够产生符合逻辑的回答。
|
||
- 设计专业领域特定的生成规则和约束
|
||
1. 具体实施:在生成模型中加入领域特定的生成规则和用语约束,特别针对医学、法律等领域的常见问答场景,设定回答模板、术语库等,以提高生成内容的准确性和一致性。
|
||
2. 目的与效果:生成内容更具领域特征,输出风格和内容的专业性增强,有效降低了生成器在专业领域中的回答偏差,满足用户对专业性和可信度的要求。
|
||
- 优化用户反馈机制,实现动态生成逻辑调整
|
||
1. 具体实施:利用机器学习算法对用户反馈进行分析,从反馈中提取生成错误或用户需求的调整信息,动态调节生成器的生成逻辑和策略。同时,在多轮对话中逐步适应用户的需求和风格偏好。
|
||
2. 目的与效果:用户反馈的高效利用能够帮助生成器优化生成内容,提高连续对话中的响应质量,提升用户体验,并使回答更贴合用户需求。
|
||
- 引入生成器与检索器的协同优化机制
|
||
1. 具体实施:通过协同优化机制,在生成器生成答案之前,允许生成器请求检索器补充缺失的上下文信息。生成器可基于回答需求自动向检索器发起上下文补充请求,从而获取完整的上下文。
|
||
2. 目的与效果:协同优化机制保障了生成器在回答时拥有足够的上下文支持,避免信息断层或缺失,提升回答的完整性和准确性。
|
||
- 实施生成内容的一致性检测和语义校正
|
||
1. 具体实施:通过一致性检测算法对生成内容进行术语、风格的统一管理,并结合语义校正模型检测生成内容是否符合用户需求的逻辑结构。在复杂回答生成中,使用语义校正对不符合逻辑的生成内容进行自动优化。
|
||
2. 目的与效果:生成内容具备高度一致性和逻辑性,特别是在多轮对话和专业领域生成中,保障了内容的稳定性和专业水准,提高了生成答案的可信度和用户满意度。
|
||
|
||
## 5.5 RAG流程
|
||
|
||

|
||
|
||
1. 数据加载与查询输入:
|
||
1. 用户通过界面或API提交自然语言查询,系统接收查询作为输入。
|
||
2. 输入被传递至向量化器,利用向量化技术(如BERT或Sentence Transformer)将自然语言查询转换为向量表示。
|
||
2. 文档检索:
|
||
1. 向量化后的查询会传递给检索器,检索器通过在知识库中查找最相关的文档片段。
|
||
2. 检索可以基于稀疏检索技术(如BM25)或密集检索技术(如DPR)来提高匹配效率和精度。
|
||
3. 生成器处理与自然语言生成:
|
||
1. 检索到的文档片段作为生成器的输入,生成器(如GPT、BART或T5)基于查询和文档内容生成自然语言回答。
|
||
2. 生成器结合了外部检索结果和预训练模型的语言知识,使回答更加精准、自然。
|
||
4. 结果输出:
|
||
1. 系统生成的答案通过API或界面返回给用户,确保答案连贯且知识准确。
|
||
5. 反馈与优化:
|
||
1. 用户可以对生成的答案进行反馈,系统根据反馈优化检索与生成过程。
|
||
2. 通过微调模型参数或调整检索权重,系统逐步改进其性能,确保未来查询时更高的准确性与效率。
|
||
|
||
# 6. RAG相关案例整合
|
||
|
||
[各种分类领域下的RAG](https://github.com/hymie122/RAG-Survey)
|
||
|
||
# 7. RAG模型的应用
|
||
|
||
RAG模型已在多个领域得到广泛应用,主要包括:
|
||
|
||
## 7.1 智能问答系统中的应用
|
||
|
||
- RAG通过实时检索外部知识库,生成包含准确且详细的答案,避免传统生成模型可能产生的错误信息。例如,在医疗问答系统中,RAG能够结合最新的医学文献,生成包含最新治疗方案的准确答案,避免生成模型提供过时或错误的建议。这种方法帮助医疗专家快速获得最新的研究成果和诊疗建议,提升医疗决策的质量。
|
||
- [医疗问答系统案例](https://www.apexon.com/blog/empowering-discovery-the-role-of-rag-architecture-generative-ai-in-healthcare-life-sciences/)
|
||
- 
|
||
- 用户通过Web应用程序发起查询:
|
||
1. 用户在一个Web应用上输入查询请求,这个请求进入后端系统,启动了整个数据处理流程。
|
||
- 使用Azure AD进行身份验证:
|
||
1. 系统通过Azure Active Directory (Azure AD) 对用户进行身份验证,确保只有经过授权的用户才能访问系统和数据。
|
||
- 用户权限检查:
|
||
1. 系统根据用户的组权限(由Azure AD管理)过滤用户能够访问的内容。这个步骤保证了用户只能看到他们有权限查看的信息。
|
||
- Azure AI搜索服务:
|
||
1. 过滤后的用户查询被传递给Azure AI搜索服务,该服务会在已索引的数据库或文档中查找与查询相关的内容。这个搜索引擎通过语义搜索技术检索最相关的信息。
|
||
- 文档智能处理:
|
||
1. 系统使用OCR(光学字符识别)和文档提取等技术处理输入的文档,将非结构化数据转换为结构化、可搜索的数据,便于Azure AI进行检索。
|
||
- 文档来源:
|
||
1. 这些文档来自预先存储的输入文档集合,这些文档在被用户查询之前已经通过文档智能处理进行了准备和索引。
|
||
- Azure Open AI生成响应:
|
||
1. 在检索到相关信息后,数据会被传递到Azure Open AI,该模块利用自然语言生成(NLG)技术,根据用户的查询和检索结果生成连贯的回答。
|
||
- 响应返回用户:
|
||
1. 最终生成的回答通过Web应用程序返回给用户,完成整个查询到响应的流程。
|
||
- 整个流程展示了Azure AI技术的集成,通过文档检索、智能处理以及自然语言生成来处理复杂的查询,并确保了数据的安全和合规性。
|
||
|
||
## 7.2 信息检索与文本生成
|
||
|
||
- 文本生成:RAG不仅可以检索相关文档,还能根据这些文档生成总结、报告或文档摘要,从而增强生成内容的连贯性和准确性。例如,法律领域中,RAG可以整合相关法条和判例,生成详细的法律意见书,确保内容的全面性和严谨性。这在法律咨询和文件生成过程中尤为重要,可以帮助律师和法律从业者提高工作效率。
|
||
- [法律领域检索增强生成案例](https://www.apexon.com/blog/empowering-discovery-the-role-of-rag-architecture-generative-ai-in-healthcare-life-sciences/)
|
||
- 内容总结:
|
||
- 背景: 传统的大语言模型 (LLMs) 在生成任务中表现优异,但在处理法律领域中的复杂任务时存在局限。法律文档具有独特的结构和术语,标准的检索评估基准往往无法充分捕捉这些领域特有的复杂性。为了弥补这一不足,LegalBench-RAG 旨在提供一个评估法律文档检索效果的专用基准。
|
||
- LegalBench-RAG 的结构:
|
||
1. 
|
||
2. 工作流程:
|
||
3. 用户输入问题(Q: ?,A: ?):用户通过界面输入查询问题,提出需要答案的具体问题。
|
||
4. 嵌入与检索模块(Embed + Retrieve):该模块接收到用户的查询后,会对问题进行嵌入(将其转化为向量),并在外部知识库或文档中执行相似度检索。通过检索算法,系统找到与查询相关的文档片段或信息。
|
||
5. 生成答案(A):基于检索到的最相关信息,生成模型(如GPT或类似的语言模型)根据检索的结果生成连贯的自然语言答案。
|
||
6. 对比和返回结果:生成的答案会与之前的相关问题答案进行对比,并最终将生成的答案返回给用户。
|
||
7. 该基准基于 LegalBench 的数据集,构建了 6858 个查询-答案对,并追溯到其原始法律文档的确切位置。
|
||
8. LegalBench-RAG 侧重于精确地检索法律文本中的小段落,而非宽泛的、上下文不相关的片段。
|
||
9. 数据集涵盖了合同、隐私政策等不同类型的法律文档,确保涵盖多个法律应用场景。
|
||
- 意义: LegalBench-RAG 是第一个专门针对法律检索系统的公开可用的基准。它为研究人员和公司提供了一个标准化的框架,用于比较不同的检索算法的效果,特别是在需要高精度的法律任务中,例如判决引用、条款解释等。
|
||
- 关键挑战:
|
||
1. RAG 系统的生成部分依赖检索到的信息,错误的检索结果可能导致错误的生成输出。
|
||
2. 法律文档的长度和术语复杂性增加了模型检索和生成的难度。
|
||
- 质量控制: 数据集的构建过程确保了高质量的人工注释和文本精确性,特别是在映射注释类别和文档ID到具体文本片段时进行了多次人工校验。
|
||
|
||
## 7.3 其它应用场景
|
||
|
||
RAG还可以应用于多模态生成场景,如图像、音频和3D内容生成。例如,跨模态应用如ReMoDiffuse和Make-An-Audio利用RAG技术实现不同数据形式的生成。此外,在企业决策支持中,RAG能够快速检索外部资源(如行业报告、市场数据),生成高质量的前瞻性报告,从而提升企业战略决策的能力。
|
||
|
||
## 8 总结
|
||
|
||
本文档系统阐述了检索增强生成(RAG)模型的核心机制、优势与应用场景。通过结合生成模型与检索模型,RAG解决了传统生成模型在面对事实性任务时的“编造”问题和检索模型难以生成连贯自然语言输出的不足。RAG模型能够实时从外部知识库获取信息,使生成内容既包含准确的知识,又具备流畅的语言表达,适用于医疗、法律、智能问答系统等多个知识密集型领域。
|
||
|
||
在应用实践中,RAG模型虽然有着信息完整性、推理能力和跨领域适应性等显著优势,但也面临着数据质量、计算资源消耗和知识库更新等挑战。为进一步提升RAG的性能,提出了针对数据采集、内容分块、检索策略优化以及回答生成的全面改进措施,如引入知识图谱、优化用户反馈机制、实施高效去重算法等,以增强模型的适用性和效率。
|
||
|
||
RAG在智能问答、信息检索与文本生成等领域展现了出色的应用潜力,并在不断发展的技术支持下进一步拓展至多模态生成和企业决策支持等场景。通过引入混合检索技术、知识图谱以及动态反馈机制,RAG能够更加灵活地应对复杂的用户需求,生成具有事实支撑和逻辑连贯性的回答。未来,RAG将通过增强模型透明性与可控性,进一步提升在专业领域中的可信度和实用性,为智能信息检索与内容生成提供更广泛的应用空间。
|
||
|
||
# API 文件库
|
||
## FastGPT API 文件库功能介绍和使用方式
|
||
|
||
| | |
|
||
| --- | --- |
|
||
|  |  |
|
||
|
||
## 背景
|
||
|
||
目前 FastGPT 支持本地文件导入,但是很多时候,用户自身已经有了一套文档库,如果把文件重复导入一遍,会造成二次存储,并且不方便管理。因为 FastGPT 提供了一个 API 文件库的概念,可以通过简单的 API 接口,去拉取已有的文档库,并且可以灵活配置是否导入。
|
||
|
||
API 文件库能够让用户轻松对接已有的文档库,只需要按照 FastGPT 的 API 文件库规范,提供相应文件接口,然后将服务接口的 baseURL 和 token 填入知识库创建参数中,就能直接在页面上拿到文件库的内容,并选择性导入
|
||
|
||
## 如何使用 API 文件库
|
||
|
||
创建知识库时,选择 API 文件库类型,然后需要配置两个关键参数:文件服务接口的 baseURL 和用于身份验证的请求头信息。只要提供的接口规范符合 FastGPT 的要求,系统就能自动获取并展示完整的文件列表,可以根据需要选择性地将文件导入到知识库中。
|
||
|
||
你需要提供两个参数:
|
||
- baseURL: 文件服务接口的 baseURL
|
||
- authorization: 用于身份验证的请求头信息,实际请求格式为 `Authorization: Bearer <token>`
|
||
|
||
## 接口规范
|
||
|
||
接口响应格式:
|
||
|
||
```ts
|
||
type ResponseType = {
|
||
success: boolean;
|
||
message: string;
|
||
data: any;
|
||
}
|
||
```
|
||
|
||
数据类型:
|
||
|
||
```ts
|
||
// 文件列表中,单项的文件类型
|
||
type FileListItem = {
|
||
id: string;
|
||
parentId: string | null;
|
||
name: string;
|
||
type: 'file' | 'folder';
|
||
updateTime: Date;
|
||
createTime: Date;
|
||
}
|
||
```
|
||
|
||
|
||
### 1. 获取文件树
|
||
|
||
{{< tabs tabTotal="2" >}}
|
||
{{< tab tabName="请求示例" >}}
|
||
{{< markdownify >}}
|
||
|
||
{{% alert icon=" " context="success" %}}
|
||
- parentId - 父级 id,可选,或者 null。
|
||
- searchKey - 检索词,可选
|
||
{{% /alert %}}
|
||
|
||
```bash
|
||
curl --location --request POST '{{baseURL}}/v1/file/list' \
|
||
--header 'Authorization: Bearer {{authorization}}' \
|
||
--header 'Content-Type: application/json' \
|
||
--data-raw '{
|
||
"parentId": null,
|
||
"searchKey": ""
|
||
}'
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="响应示例" >}}
|
||
{{< markdownify >}}
|
||
|
||
```json
|
||
{
|
||
"code": 200,
|
||
"success": true,
|
||
"message": "",
|
||
"data": [
|
||
{
|
||
"id": "xxxx",
|
||
"parentId": "xxxx",
|
||
"type": "file", // file | folder
|
||
"name":"test.json",
|
||
"updateTime":"2024-11-26T03:05:24.759Z",
|
||
"createTime":"2024-11-26T03:05:24.759Z"
|
||
}
|
||
]
|
||
}
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
{{< /tabs >}}
|
||
|
||
### 2. 获取单个文件内容(文本内容或访问链接)
|
||
|
||
{{< tabs tabTotal="3" >}}
|
||
{{< tab tabName="请求示例" >}}
|
||
{{< markdownify >}}
|
||
|
||
```bash
|
||
curl --location --request GET '{{baseURL}}/v1/file/content?id=xx' \
|
||
--header 'Authorization: Bearer {{authorization}}'
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="响应示例" >}}
|
||
{{< markdownify >}}
|
||
|
||
```json
|
||
{
|
||
"code": 200,
|
||
"success": true,
|
||
"message": "",
|
||
"data": {
|
||
"title": "文档标题",
|
||
"content": "FastGPT 是一个基于 LLM 大语言模型的知识库问答系统,提供开箱即用的数据处理、模型调用等能力。同时可以通过 Flow 可视化进行工作流编排,从而实现复杂的问答场景!\n",
|
||
"previewUrl": "xxxx"
|
||
}
|
||
}
|
||
```
|
||
|
||
{{% alert icon=" " context="success" %}}
|
||
|
||
- title - 文件标题。
|
||
- content - 文件内容,直接拿来用。
|
||
- previewUrl - 文件链接,系统会请求该地址获取文件内容。
|
||
|
||
`content`和`previewUrl`二选一返回,如果同时返回则 `content` 优先级更高,返回 `previewUrl`时,则会访问该链接进行文档内容读取。
|
||
|
||
{{% /alert %}}
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
{{< /tabs >}}
|
||
|
||
|
||
### 3. 获取文件阅读链接(用于查看原文)
|
||
|
||
{{< tabs tabTotal="2" >}}
|
||
{{< tab tabName="请求示例" >}}
|
||
{{< markdownify >}}
|
||
|
||
id 为文件的 id。
|
||
|
||
```bash
|
||
curl --location --request GET '{{baseURL}}/v1/file/read?id=xx' \
|
||
--header 'Authorization: Bearer {{authorization}}'
|
||
```
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
|
||
{{< tab tabName="响应示例" >}}
|
||
{{< markdownify >}}
|
||
|
||
```json
|
||
{
|
||
"code": 200,
|
||
"success": true,
|
||
"message": "",
|
||
"data": {
|
||
"url": "xxxx"
|
||
}
|
||
}
|
||
```
|
||
|
||
{{% alert icon=" " context="success" %}}
|
||
- url - 文件访问链接,拿到后会自动打开。
|
||
{{% /alert %}}
|
||
|
||
{{< /markdownify >}}
|
||
{{< /tab >}}
|
||
{{< /tabs >}}
|
||
|
||
# 知识库搜索方案和参数
|
||
## 本节会详细介绍 FastGPT 知识库结构设计,理解其 QA 的存储格式和多向量映射,以便更好的构建知识库。同时会介绍每个搜索参数的功能。这篇介绍主要以使用为主,详细原理不多介绍。
|
||
|
||
## 理解向量
|
||
|
||
FastGPT 采用了 RAG 中的 Embedding 方案构建知识库,要使用好 FastGPT 需要简单的理解`Embedding`向量是如何工作的及其特点。
|
||
|
||
人类的文字、图片、视频等媒介是无法直接被计算机理解的,要想让计算机理解两段文字是否有相似性、相关性,通常需要将它们转成计算机可以理解的语言,向量是其中的一种方式。
|
||
|
||
向量可以简单理解为一个数字数组,两个向量之间可以通过数学公式得出一个`距离`,距离越小代表两个向量的相似度越大。从而映射到文字、图片、视频等媒介上,可以用来判断两个媒介之间的相似度。向量搜索便是利用了这个原理。
|
||
|
||
而由于文字是有多种类型,并且拥有成千上万种组合方式,因此在转成向量进行相似度匹配时,很难保障其精确性。在向量方案构建的知识库中,通常使用`topk`召回的方式,也就是查找前`k`个最相似的内容,丢给大模型去做更进一步的`语义判断`、`逻辑推理`和`归纳总结`,从而实现知识库问答。因此,在知识库问答中,向量搜索的环节是最为重要的。
|
||
|
||
影响向量搜索精度的因素非常多,主要包括:向量模型的质量、数据的质量(长度,完整性,多样性)、检索器的精度(速度与精度之间的取舍)。与数据质量对应的就是检索词的质量。
|
||
|
||
检索器的精度比较容易解决,向量模型的训练略复杂,因此数据和检索词质量优化成了一个重要的环节。
|
||
|
||
|
||
### 提高向量搜索精度的方法
|
||
|
||
1. 更好分词分段:当一段话的结构和语义是完整的,并且是单一的,精度也会提高。因此,许多系统都会优化分词器,尽可能的保障每组数据的完整性。
|
||
2. 精简`index`的内容,减少向量内容的长度:当`index`的内容更少,更准确时,检索精度自然会提高。但与此同时,会牺牲一定的检索范围,适合答案较为严格的场景。
|
||
3. 丰富`index`的数量,可以为同一个`chunk`内容增加多组`index`。
|
||
4. 优化检索词:在实际使用过程中,用户的问题通常是模糊的或是缺失的,并不一定是完整清晰的问题。因此优化用户的问题(检索词)很大程度上也可以提高精度。
|
||
5. 微调向量模型:由于市面上直接使用的向量模型都是通用型模型,在特定领域的检索精度并不高,因此微调向量模型可以很大程度上提高专业领域的检索效果。
|
||
|
||
## FastGPT 构建知识库方案
|
||
|
||
### 数据存储结构
|
||
|
||
在 FastGPT 中,整个知识库由库、集合和数据 3 部分组成。集合可以简单理解为一个`文件`。一个`库`中可以包含多个`集合`,一个`集合`中可以包含多组`数据`。最小的搜索单位是`库`,也就是说,知识库搜索时,是对整个`库`进行搜索,而集合仅是为了对数据进行分类管理,与搜索效果无关。(起码目前还是)
|
||
|
||

|
||
|
||
### 向量存储结构
|
||
|
||
FastGPT 采用了`PostgresSQL`的`PG Vector`插件作为向量检索器,索引为`HNSW`。且`PostgresSQL`仅用于向量检索(该引擎可以替换成其它数据库),`MongoDB`用于其他数据的存取。
|
||
|
||
在`MongoDB`的`dataset.datas`表中,会存储向量原数据的信息,同时有一个`indexes`字段,会记录其对应的向量ID,这是一个数组,也就是说,一组数据可以对应多个向量。
|
||
|
||
在`PostgresSQL`的表中,设置一个`vector`字段用于存储向量。在检索时,会先召回向量,再根据向量的ID,去`MongoDB`中寻找原数据内容,如果对应了同一组原数据,则进行合并,向量得分取最高得分。
|
||
|
||

|
||
|
||
### 多向量的目的和使用方式
|
||
|
||
在一组向量中,内容的长度和语义的丰富度通常是矛盾的,无法兼得。因此,FastGPT 采用了多向量映射的方式,将一组数据映射到多组向量中,从而保障数据的完整性和语义的丰富度。
|
||
|
||
你可以为一组较长的文本,添加多组向量,从而在检索时,只要其中一组向量被检索到,该数据也将被召回。
|
||
|
||
意味着,你可以通过标注数据块的方式,不断提高数据块的精度。
|
||
|
||
### 检索方案
|
||
|
||
1. 通过`问题优化`实现指代消除和问题扩展,从而增加连续对话的检索能力以及语义丰富度。
|
||
2. 通过`Concat query`来增加`Rerank`连续对话的时,排序的准确性。
|
||
3. 通过`RRF`合并方式,综合多个渠道的检索效果。
|
||
4. 通过`Rerank`来二次排序,提高精度。
|
||
|
||

|
||
|
||
|
||
## 搜索参数
|
||
| | | |
|
||
| --- |---| --- |
|
||
||  |  |
|
||
|
||
### 搜索模式
|
||
|
||
#### 语义检索
|
||
|
||
语义检索是通过向量距离,计算用户问题与知识库内容的距离,从而得出“相似度”,当然这并不是语文上的相似度,而是数学上的。
|
||
|
||
优点:
|
||
- 相近语义理解
|
||
- 跨多语言理解(例如输入中文问题匹配英文知识点)
|
||
- 多模态理解(文本,图片,音视频等)
|
||
|
||
缺点:
|
||
- 依赖模型训练效果
|
||
- 精度不稳定
|
||
- 受关键词和句子完整度影响
|
||
|
||
#### 全文检索
|
||
|
||
采用传统的全文检索方式。适合查找关键的主谓语等。
|
||
|
||
#### 混合检索
|
||
|
||
同时使用向量检索和全文检索,并通过 RRF 公式进行两个搜索结果合并,一般情况下搜索结果会更加丰富准确。
|
||
|
||
由于混合检索后的查找范围很大,并且无法直接进行相似度过滤,通常需要进行利用重排模型进行一次结果重新排序,并利用重排的得分进行过滤。
|
||
|
||
#### 结果重排
|
||
|
||
利用`ReRank`模型对搜索结果进行重排,绝大多数情况下,可以有效提高搜索结果的准确率。不过,重排模型与问题的完整度(主谓语齐全)有一些关系,通常会先走问题优化后再进行搜索-重排。重排后可以得到一个`0-1`的得分,代表着搜索内容与问题的相关度,该分数通常比向量的得分更加精确,可以根据得分进行过滤。
|
||
|
||
FastGPT 会使用 `RRF` 对重排结果、向量搜索结果、全文检索结果进行合并,得到最终的搜索结果。
|
||
|
||
### 搜索过滤
|
||
|
||
#### 引用上限
|
||
|
||
每次搜索最多引用`n`个`tokens`的内容。
|
||
|
||
之所以不采用`top k`,是发现在混合知识库(问答库、文档库)时,不同`chunk`的长度差距很大,会导致`top k`的结果不稳定,因此采用了`tokens`的方式进行引用上限的控制。
|
||
|
||
#### 最低相关度
|
||
|
||
一个`0-1`的数值,会过滤掉一些低相关度的搜索结果。
|
||
|
||
该值仅在`语义检索`或使用`结果重排`时生效。
|
||
|
||
### 问题优化
|
||
|
||
#### 背景
|
||
|
||
在 RAG 中,我们需要根据输入的问题去数据库里执行 embedding 搜索,查找相关的内容,从而查找到相似的内容(简称知识库搜索)。
|
||
|
||
在搜索的过程中,尤其是连续对话的搜索,我们通常会发现后续的问题难以搜索到合适的内容,其中一个原因是知识库搜索只会使用“当前”的问题去执行。看下面的例子:
|
||
|
||

|
||
|
||
用户在提问“第二点是什么”的时候,只会去知识库里查找“第二点是什么”,压根查不到内容。实际上需要查询的是“QA结构是什么”。因此我们需要引入一个【问题优化】模块,来对用户当前的问题进行补全,从而使得知识库搜索能够搜索到合适的内容。使用补全后效果如下:
|
||
|
||

|
||
|
||
#### 实现方式
|
||
|
||
在进行`数据检索`前,会先让模型进行`指代消除`与`问题扩展`,一方面可以可以解决指代对象不明确问题,同时可以扩展问题的语义丰富度。你可以通过每次对话后的对话详情,查看补全的结果。
|
||
|
||
# 外部文件知识库
|
||
## FastGPT 外部文件知识库功能介绍和使用方式
|
||
|
||
外部文件库是 FastGPT 商业版特有功能。它允许接入你现在的文件系统,无需将文件再导入一份到 FastGPT 中。
|
||
|
||
并且,阅读权限可以通过你的文件系统进行控制。
|
||
|
||
| | | |
|
||
| --------------------- | --------------------- | --------------------- |
|
||
|  |  |  |
|
||
|
||
|
||
## 导入参数说明
|
||
|
||
- 外部预览地址:用于跳转你的文件阅读地址,会携带“文件阅读ID”进行访问。
|
||
- 文件访问URL:文件可访问的地址。
|
||
- 文件阅读ID:通常情况下,文件访问URL是临时的。如果希望永久可以访问,你需要使用该文件阅读ID,并配合上“外部预览地址”,跳转至新的阅读地址进行原文件访问。
|
||
- 文件名:默认会自动解析文件访问URL上的文件名。如果你手动填写,将会以手动填写的值为准。
|
||
|
||
[点击查看API导入文档](/docs/development/openapi/dataset/#创建一个外部文件库集合商业版)
|
||
|
||
## API 文件库替代方案
|
||
|
||
4.8.15 提供了新的知识库类型 - API 文件库,对外部文件知识库做了进一步的拓展
|
||
|
||
通过对接口进行简单的调整,就能使用 API 文件库代替外部文件知识库的功能
|
||
|
||
你可以直接将外部文件知识库中的外部预览地址,作为 API 文件库接口规范中获取文件阅读链接的接口返回
|
||
|
||
然后再以相同的 baseURL 实现获取文件列表和获取单个文件内容这两个接口
|
||
|
||
这样就能轻松地使用 API 文件库替代原有的外部文件知识库,更多详细的内容见 API 文件库的文档
|
||
|
||
# 飞书知识库
|
||
## FastGPT 飞书知识库功能介绍和使用方式
|
||
|
||
| | |
|
||
| --- | --- |
|
||
|  |  |
|
||
|
||
FastGPT v4.8.16 版本开始,商业版用户支持飞书知识库导入,用户可以通过配置飞书应用的 appId 和 appSecret,并选中一个**文档空间的顶层文件夹**来导入飞书知识库。目前处于测试阶段,部分交互有待优化。
|
||
|
||
由于飞书限制,无法直接获取所有文档内容,目前仅可以获取共享空间下文件目录的内容,无法获取个人空间和知识库里的内容。
|
||
|
||
|
||
## 1. 创建飞书应用
|
||
|
||
打开 [飞书开放平台](https://open.feishu.cn/?lang=zh-CN),点击**创建应用**,选择**自建应用**,然后填写应用名称。
|
||
|
||
## 2. 配置应用权限
|
||
|
||
创建应用后,进入应用可以配置相关权限,这里需要增加**3个权限**:
|
||
|
||
1. 获取云空间文件夹下的云文档清单
|
||
2. 查看新版文档
|
||
3. 查看、评论、编辑和管理云空间中所有文件
|
||
|
||

|
||
|
||
## 3. 获取 appId 和 appSecret
|
||
|
||

|
||
|
||
## 4. 给 Folder 增加权限
|
||
|
||
可参考飞书教程: https://open.feishu.cn/document/server-docs/docs/drive-v1/faq#b02e5bfb
|
||
|
||
大致总结为:
|
||
|
||
1. 把刚刚创建的应用拉入一个群里
|
||
2. 给这个群增加目录权限
|
||
|
||
如果你的目录已经给全员组增加权限了,则可以跳过上面步骤,直接获取 Folder Token。
|
||
|
||

|
||
|
||
## 5. 获取 Folder Token
|
||
|
||
可以页面路径上获取 Folder Token,注意不要把问号复制进来。
|
||
|
||

|
||
|
||
## 6. 创建知识库
|
||
|
||
根据 3 和 5 获取到的 3 个参数,创建知识库,选择飞书文件库类型,然后填入对应的参数,点击创建。
|
||
|
||

|
||
|
||
# Web 站点同步
|
||
## FastGPT Web 站点同步功能介绍和使用方式
|
||
|
||

|
||
|
||
该功能目前仅向商业版用户开放。
|
||
|
||
## 什么是 Web 站点同步
|
||
|
||
Web 站点同步利用爬虫的技术,可以通过一个入口网站,自动捕获`同域名`下的所有网站,目前最多支持`200`个子页面。出于合规与安全角度,FastGPT 仅支持`静态站点`的爬取,主要用于各个文档站点快速构建知识库。
|
||
|
||
Tips: 国内的媒体站点基本不可用,公众号、csdn、知乎等。可以通过终端发送`curl`请求检测是否为静态站点,例如:
|
||
|
||
```bash
|
||
curl https://doc.tryfastgpt.ai/docs/intro/
|
||
```
|
||
|
||
## 如何使用
|
||
|
||
### 1. 新建知识库,选择 Web 站点同步
|
||
|
||

|
||
|
||

|
||
|
||
### 2. 点击配置站点信息
|
||
|
||

|
||
|
||
### 3. 填写网址和选择器
|
||
|
||

|
||
|
||
好了, 现在点击开始同步,静等系统自动抓取网站信息即可。
|
||
|
||
|
||
## 创建应用,绑定知识库
|
||
|
||

|
||
|
||
## 选择器如何使用
|
||
|
||
选择器是 HTML CSS JS 的产物,你可以通过选择器来定位到你需要抓取的具体内容,而不是整个站点。使用方式为:
|
||
|
||
### 首先打开浏览器调试面板(通常是 F12,或者【右键 - 检查】)
|
||
|
||

|
||
|
||

|
||
|
||
### 输入对应元素的选择器
|
||
|
||
[菜鸟教程 css 选择器](https://www.runoob.com/cssref/css-selectors.html),具体选择器的使用方式可以参考菜鸟教程。
|
||
|
||
上图中,我们选中了一个区域,对应的是`div`标签,它有 `data-prismjs-copy`, `data-prismjs-copy-success`, `data-prismjs-copy-error` 三个属性,这里我们用到一个就够。所以选择器是:
|
||
**`div[data-prismjs-copy]`**
|
||
|
||
除了属性选择器,常见的还有类和ID选择器。例如:
|
||
|
||

|
||
|
||
上图 class 里的是类名(可能包含多个类名,都是空格隔开的,选择一个即可),选择器可以为:**`.docs-content`**
|
||
|
||
### 多选择器使用
|
||
|
||
在开头的演示中,我们对 FastGPT 文档是使用了多选择器的方式来选择,通过逗号隔开了两个选择器。
|
||
|
||

|
||
|
||
我们希望选中上图两个标签中的内容,此时就需要两组选择器。一组是:`.docs-content .mb-0.d-flex`,含义是 `docs-content` 类下同时包含 `mb-0`和`d-flex` 两个类的子元素;
|
||
|
||
另一组是`.docs-content div[data-prismjs-copy]`,含义是`docs-content` 类下包含`data-prismjs-copy`属性的`div`元素。
|
||
|
||
把两组选择器用逗号隔开即可:`.docs-content .mb-0.d-flex, .docs-content div[data-prismjs-copy]`
|
||
|
||
# 语雀文件库
|
||
## FastGPT 语雀文件库功能介绍和使用方式
|
||
|
||
| | |
|
||
| --- | --- |
|
||
|  |  |
|
||
|
||
FastGPT v4.8.16 版本开始,商业版用户支持语雀文件库导入,用户可以通过配置语雀的 token 和 uid 来导入语雀文档库。目前处于测试阶段,部分交互有待优化。
|
||
|
||
## 1. 获取语雀的 token 和 uid
|
||
|
||
在语雀首页 - 个人头像 - 设置,可找到对应参数。
|
||
|
||

|
||
|
||
参考下图获取 Token 和 User ID,注意给 Token 赋值权限:
|
||
|
||
| 获取 Token | 增加权限 | 获取 User ID |
|
||
| --- | --- | --- |
|
||
|  |  |  |
|
||
|
||
## 2. 创建知识库
|
||
|
||
使用上一步获取的 token 和 uid,创建知识库,选择语雀文件库类型,然后填入对应的参数,点击创建。
|
||
|
||

|
||
|
||

|
||
|
||
## 3. 导入文档
|
||
|
||
创建完知识库后,点击`添加文件`即可导入语雀的文档库,跟随引导即可。
|
||
|
||
语雀知识库支持定时同步功能,每天会不定时的扫描一次,如果文档有更新,则会进行同步,也可以进行手动同步。
|
||
|
||

|
||
|
||
# Bing 搜索插件填写说明
|
||
## FastGPT Bing 搜索插件配置步骤详解
|
||
|
||
1. # 打开微软Azure官网,登陆账号
|
||
|
||
https://portal.azure.com/
|
||
|
||

|
||
|
||
1. # 创建bing web搜索资源
|
||
|
||
搜索Bing Search v7,点击创建
|
||
|
||
https://portal.azure.com/#create/Microsoft.BingSearch
|
||
|
||

|
||
|
||
1. # 进入资源详情点击管理密钥
|
||
|
||

|
||
|
||
# 4. 复制任意一个密钥填入插件输入
|
||
|
||

|
||
|
||

|
||
|
||
# Doc2x 插件填写说明
|
||
## 如何配置和使用 Doc2x 插件
|
||
|
||
1. # 打开docx官网,创建账号,并复制 apikey
|
||
|
||
https://doc2x.noedgeai.com/
|
||
|
||

|
||
|
||

|
||
|
||
1. # 填写apikey到fastgpt中
|
||
|
||
**工作流****中:**
|
||
|
||

|
||
|
||
**简易模式使用:**
|
||
|
||

|
||
|
||
# Google 搜索插件填写说明
|
||
## FastGPT Google 搜索插件配置指南
|
||
|
||
1. # 创建Google Custom Search Engine
|
||
|
||
https://programmablesearchengine.google.com/
|
||
|
||
我们连到Custom Search Engine control panel 建立Search Engine
|
||
|
||

|
||
|
||
取得搜索引擎的ID,即cx
|
||
|
||

|
||
|
||
1. # 获取api key
|
||
|
||
https://developers.google.com/custom-search/v1/overview?hl=zh-cn
|
||
|
||

|
||
|
||
1. # 填入插件输入参数
|
||
|
||
将搜索引擎ID填入cx字段,api key填入key字段
|
||
|
||

|
||
|
||
# 如何提交系统插件
|
||
## FastGPT 系统插件提交指南
|
||
|
||
> 如何向 FastGPT 社区提交系统插件
|
||
|
||
## 系统插件原则
|
||
|
||
- 尽可能的轻量简洁,以解决实际问题的工具为主
|
||
- 不允许有密集 cpu 计算,不会占用大量内存占用或网络消耗
|
||
- 不允许操作数据库
|
||
- 不允许往固定的私人地址发送请求(不包含请求某些在线服务,例如 gapier, firecrawl等)
|
||
- 不允许使用私人包,可使用主流的开源包
|
||
|
||
## 什么插件可以合并
|
||
|
||
由于目前未采用按需安装的模式,合并进仓库的插件会全部展示给用户使用。
|
||
|
||
为了控制插件的质量以及避免数量过多带来的繁琐,并不是所有的插件都会被合并到开源仓库中,你可以提前 PR 与我们沟通插件的内容。
|
||
|
||
后续实现插件按需安装后,我们会允许更多的社区插件合入。
|
||
|
||
## 如何写一个系统插件 - 初步
|
||
|
||
FastGPT 系统插件和用户工作台的插件效果是一致的,所以你需要提前了解“插件”的定义和功能。
|
||
|
||
在 FastGPT 中,插件是一种特殊的工作流,它允许你将一个工作流封装起来,并自定义入口参数和出口参数,类似于代码里的 “子函数”。
|
||
|
||
1. ### 跑通 FastGPT dev 环境
|
||
|
||
需要在 dev 环境下执行下面的操作。
|
||
|
||
1. ### 在 FastGPT 工作台中,创建一个插件
|
||
|
||
选择基础模板即可。
|
||
|
||

|
||
|
||
1. ### 创建系统插件配置
|
||
|
||
系统插件配置以及自定义代码,都会在 **packages/plugins** 目录下。
|
||
|
||
1. 在 **packages/plugins/src** 下,复制一份 **template** 目录,并修改名字。
|
||
2. 打开目录里面的 template.json 文件,配置如下:
|
||
3. 目录还有一个 index.ts 文件,下文再提。
|
||
|
||
```TypeScript
|
||
{
|
||
"author": "填写你的名字",
|
||
"version": "当前系统版本号",
|
||
"name": "插件名",
|
||
"avatar": "插件头像,需要配成 icon 格式。直接把 logo 图在 pr 评论区提交即可,我们会帮你加入。",
|
||
"intro": " 插件的描述,这个描述会影响工具调用",
|
||
"showStatus": false, // 是否在对话过程展示状态
|
||
"weight": 10, // 排序权重,均默认 10
|
||
|
||
"isTool": true, // 是否作为工具调用节点
|
||
"templateType": "tools", // 都填写 tools 即可,由官方来分类
|
||
|
||
"workflow": { // 这个对象先不管,待会直接粘贴导出的工作流即可
|
||
"nodes": [],
|
||
"edges": []
|
||
}
|
||
}
|
||
```
|
||
|
||
1. 打开 **packages/plugins/register** 文件,注册你的插件。在 list 数组中,加入一个你插件目录的名字,如下图的例子。如需构建插件组(带目录),可参考 DuckDuckGo 插件。
|
||
|
||
无需额外写代码的插件,直接放在 staticPluginList 内,需要在项目内额外写代码的,写在 packagePluginList 中。
|
||
|
||

|
||
|
||
1. ### 完成工作流编排并测试
|
||
|
||
完成工作流编排后,可以点击右上角的发布,并在其他工作流中引入进行测试(此时属于团队插件)。
|
||
|
||
1. ### 复制配置到 template.json
|
||
|
||
鼠标放置在左上角插件的头像和名称上,会出现对于下拉框操作,可以导出工作流配置。
|
||
|
||
导出的配置,会自动到剪切板,可以直接到 template.json 文件中粘贴使用,替换步骤 2 中,**workflow** 的值。
|
||
|
||

|
||
|
||
1. ### 验证插件是否加载成功
|
||
|
||
刷新页面,打开系统插件,看其是否成功加载,并将其添加到工作流中使用。
|
||
|
||

|
||
|
||
1. ### 提交 PR
|
||
|
||
如果你觉得你的插件需要提交到开源仓库,可以通过 PR 形式向我们提交。
|
||
|
||
- 写清楚插件的介绍和功能
|
||
- 配上插件运行的效果图
|
||
- 插件参数填写说明,需要在 PR 中写清楚。例如,有些插件需要去某个提供商申请 key,需要附上对应的地址和教材,后续我们会加入到文档中。
|
||
|
||
## 写一个复杂的系统插件 - 进阶
|
||
|
||
这一章会介绍如何增加一些无法单纯通过编排实现的插件。因为可能需要用到网络请求或第三方包。
|
||
|
||
上一章提到,在插件的 **template** 目录下,还有一个 **index.ts** 文件,这个文件就是用来执行一些插件的代码的。你可以通过在 HTTP 节点中的 URL,填写插件的名字,即可触发该方法,下面以 **duckduckgo/search** 这个插件为例:
|
||
|
||

|
||
|
||

|
||
|
||

|
||
|
||
参考上面 3 张图片,当 HTTP 节点的 URL 为系统插件注册的名字时,该请求不会以 HTTP 形式发送,而是会请求到 index.ts 文件中的 main 方法。出入参则对应了 body 和自定义输出的字段名。
|
||
|
||
由于目前插件会默认插件输出均作为“工具调用”的结果,无法单独指定某些字段作为工具输出,所以,请避免插件的自定义输出携带大量说明字段。
|
||
|
||
# SearXNG 搜索插件配置与使用说明
|
||
## FastGPT SearXNG 搜索插件配置指南
|
||
|
||
[SearXNG](https://github.com/searxng/searxng)是一款免费的互联网元搜索引擎,它汇总了来自各种搜索服务和数据库的结果。它不会跟踪或分析用户。用户可以自行部署它进行使用。本文介绍 Searxng 的部署以及接入 FastGPT 插件。
|
||
|
||
|
||
## 1. 部署应用
|
||
|
||
这里介绍在 Sealos 中部署 SearXNG 的方法。Docker 部署,可以直接参考 [SearXNG 官方教程](https://github.com/searxng/searxng)。
|
||
|
||
点击打开 [Sealos 北京区](https://bja.sealos.run?uid=fnWRt09fZP),点击应用部署,并新建一个应用:
|
||
|
||
| 打开应用部署 | 点击新建应用 |
|
||
| --- | --- |
|
||
|  |  |
|
||
|
||
## 2. 部署配置
|
||
|
||
把下面参数,填入配置中:
|
||
|
||
* 镜像名: searxng/searxng:latest
|
||
* CPU: 0.2
|
||
* 内存: 512M
|
||
* 容器暴露端口: 8080
|
||
* 开启公网访问
|
||
* 点击高级配置,填写环境变量和配置文件
|
||
|
||

|
||
|
||
**环境变量**
|
||
|
||
填下面两个内容,主要是为了减小并发,不然内存占用非常大。
|
||
|
||
```
|
||
UWSGI_WORKERS=4
|
||
UWSGI_THREADS=4
|
||
```
|
||
|
||
**配置文件**
|
||
|
||
新增一个配置文件,文件名:`/etc/searx/settings.yml`
|
||
文件内容:
|
||
|
||
```txt
|
||
general:
|
||
debug: false
|
||
instance_name: "searxng"
|
||
privacypolicy_url: false
|
||
donation_url: false
|
||
contact_url: false
|
||
enable_metrics: true
|
||
open_metrics: ''
|
||
|
||
brand:
|
||
new_issue_url: https://github.com/searxng/searxng/issues/new
|
||
docs_url: https://docs.searxng.org/
|
||
public_instances: https://searx.space
|
||
wiki_url: https://github.com/searxng/searxng/wiki
|
||
issue_url: https://github.com/searxng/searxng/issues
|
||
|
||
search:
|
||
safe_search: 0
|
||
autocomplete: ""
|
||
autocomplete_min: 4
|
||
default_lang: "auto"
|
||
ban_time_on_fail: 5
|
||
max_ban_time_on_fail: 120
|
||
formats:
|
||
- html
|
||
|
||
server:
|
||
port: 8080
|
||
bind_address: "0.0.0.0"
|
||
base_url: false
|
||
limiter: false
|
||
public_instance: false
|
||
secret_key: "example"
|
||
image_proxy: false
|
||
http_protocol_version: "1.0"
|
||
method: "POST"
|
||
default_http_headers:
|
||
X-Content-Type-Options: nosniff
|
||
X-Download-Options: noopen
|
||
X-Robots-Tag: noindex, nofollow
|
||
Referrer-Policy: no-referrer
|
||
|
||
redis:
|
||
url: false
|
||
|
||
ui:
|
||
static_path: ""
|
||
static_use_hash: false
|
||
templates_path: ""
|
||
default_theme: simple
|
||
default_locale: ""
|
||
query_in_title: false
|
||
infinite_scroll: false
|
||
center_alignment: false
|
||
theme_args:
|
||
simple_style: auto
|
||
|
||
outgoing:
|
||
request_timeout: 30.0
|
||
max_request_timeout: 40.0
|
||
pool_connections: 200
|
||
pool_maxsize: 50
|
||
enable_http2: false
|
||
retries: 5
|
||
|
||
engines:
|
||
|
||
- name: bing
|
||
engine: bing
|
||
shortcut: bi
|
||
|
||
doi_resolvers:
|
||
oadoi.org: 'https://oadoi.org/'
|
||
doi.org: 'https://doi.org/'
|
||
doai.io: 'https://dissem.in/'
|
||
sci-hub.se: 'https://sci-hub.se/'
|
||
sci-hub.st: 'https://sci-hub.st/'
|
||
sci-hub.ru: 'https://sci-hub.ru/'
|
||
|
||
default_doi_resolver: 'oadoi.org'
|
||
```
|
||
|
||
国内目前只有 Bing 引擎可以正常用,所以上面的配置只配置了 bing 引擎。如果在海外部署,可以使用[Sealos 新加坡可用区](https://cloud.sealos.io?uid=fnWRt09fZP),并配置其他搜索引擎,可以参考[SearXNG 默认配置文件](https://github.com/searxng/searxng/blob/master/searx/settings.yml), 从里面复制一些 engine 配置。例如:
|
||
|
||
```
|
||
- name: duckduckgo
|
||
engine: duckduckgo
|
||
shortcut: ddg
|
||
|
||
- name: google
|
||
engine: google
|
||
shortcut: go
|
||
```
|
||
|
||
## 3. FastGPT 使用
|
||
|
||
复制 Sealos 部署后提供的公网地址,填入 FastGPT 的 SearXNG 插件的 URL 中。
|
||
|
||
| 复制公网地址| 填入 URL |
|
||
| --- | --- |
|
||
|  |  |
|
||
|
||
## 返回格式
|
||
|
||
* 成功时返回搜索结果数组:
|
||
|
||
```Bash
|
||
{
|
||
"result": "[{\"title\":\"标题1\",\"link\":\"链接1\",\"snippet\":\"摘要1\"}, ...]"
|
||
}
|
||
```
|
||
|
||
* 搜索结果为空时会返回友好提示:
|
||
|
||
```Bash
|
||
{
|
||
"result": "[]",
|
||
"error": {
|
||
"message": "No search results",
|
||
"code": 500
|
||
}
|
||
}
|
||
```
|
||
|
||
* 失败时通过 Promise.reject 可能返回错误信息:
|
||
|
||
```Bash
|
||
- "缺少查询参数"
|
||
- "缺少url"
|
||
- "Failed to fetch data from Search XNG"
|
||
```
|
||
|
||
一般问题来源于参数缺失与服务部署,如有更多问题可在用户群提问。
|
||
|
||
## FAQ
|
||
|
||
### 无搜索结果
|
||
|
||
1. 先直接打开外网地址,测试是否可以正常搜索。
|
||
2. 检查是否有超时的搜索引擎,通过 API 调用时不会返回结果。
|
||
|
||
# 邀请链接说明文档
|
||
## 如何使用邀请链接来邀请团队成员
|
||
|
||
v4.9.1 团队邀请成员将开始使用「邀请链接」的模式,弃用之前输入用户名进行添加的形式。
|
||
|
||
在版本升级后,原收到邀请还未加入团队的成员,将自动清除邀请。请使用邀请链接重新邀请成员。
|
||
|
||
## 如何使用
|
||
|
||
1. **在团队管理页面,管理员可点击「邀请成员」按钮打开邀请成员弹窗**
|
||
|
||

|
||
|
||
2. **在邀请成员弹窗中,点击「创建邀请链接」按钮,创建邀请链接。**
|
||
|
||

|
||
|
||
3. **输入对应内容**
|
||
|
||

|
||
|
||
链接描述:建议将链接描述为使用场景或用途。链接创建后不支持修改噢。
|
||
|
||
有效期:30分钟,7天,1年
|
||
|
||
有效人数:1人,无限制
|
||
|
||
4. **点击复制链接,并将其发送给想要邀请的人。**
|
||
|
||

|
||
|
||
5. **用户访问链接后,如果未登录/未注册,则先跳转到登录页面进行登录。在登录后将进入团队页面,处理邀请。**
|
||
|
||
> 邀请链接形如:fastgpt.cn/account/team?invitelinkid=xxxx
|
||
|
||

|
||
|
||
点击接受,则用户将加入团队
|
||
|
||
点击忽略,则关闭弹窗,用户下次访问该邀请链接则还可以选择加入。
|
||
|
||
## 链接失效和自动清理
|
||
|
||
### 链接失效原因
|
||
|
||
手动停用链接
|
||
|
||
邀请链接到达有效期,自动停用
|
||
|
||
有效人数为1人的链接,已有1人通过邀请链接加入团队。
|
||
|
||
停用的链接无法访问,也无法再次启用。
|
||
|
||
### 链接上限
|
||
|
||
一个用户最多可以同时存在 10 个**有效的**邀请链接。
|
||
|
||
### 链接自动清理
|
||
|
||
失效的链接将在 30 天后自动清理。
|
||
|
||
# 团队&成员组&权限
|
||
## 如何管理 FastGPT 团队、成员组及权限设置
|
||
|
||
# 团队 & 成员组 & 权限
|
||
|
||
## 权限系统简介
|
||
|
||
FastGPT
|
||
权限系统融合了基于**属性**和基于**角色**的权限管理范式,为团队协作提供精细化的权限控制方案。通过**成员、部门和群组**三种管理模式,您可以灵活配置对团队、应用和知识库等资源的访问权限。
|
||
|
||
## 团队
|
||
|
||
每位用户可以同时归属于多个团队,系统默认为每位用户创建一个初始团队。目前暂不支持用户手动创建额外团队。
|
||
|
||
## 权限管理
|
||
|
||
FastGPT 提供三种权限管理维度:
|
||
|
||
**成员权限**:最高优先级,直接赋予个人的权限
|
||
|
||
**部门与群组权限**:采用权限并集原则,优先级低于成员权限
|
||
|
||
权限判定遵循以下逻辑:
|
||
|
||
首先检查用户的个人成员权限
|
||
|
||
其次检查用户所属部门和群组的权限(取并集)
|
||
|
||
最终权限为上述结果的组合
|
||
|
||
鉴权逻辑如下:
|
||
|
||

|
||
|
||
### 资源权限
|
||
|
||
对于不同的**资源**,有不同的权限。
|
||
|
||
这里说的资源,是指应用、知识库、团队等等概念。
|
||
|
||
下表为不同资源,可以进行管理的权限。
|
||
|
||
<table>
|
||
<thead>
|
||
<tr>
|
||
<th>资源</th>
|
||
<th>可管理权限</th>
|
||
<th>说明</th>
|
||
</tr>
|
||
</thead>
|
||
<tbody>
|
||
<tr>
|
||
<td rowspan="4">团队</td>
|
||
<td>创建应用</td>
|
||
<td>创建,删除等基础操作</td>
|
||
</tr>
|
||
<tr>
|
||
<td>创建知识库</td>
|
||
<td>创建,删除等基础操作</td>
|
||
</tr>
|
||
<tr>
|
||
<td>创建团队 APIKey</td>
|
||
<td>创建,删除等基础操作</td>
|
||
</tr>
|
||
<tr>
|
||
<td>管理成员</td>
|
||
<td>邀请、移除用户,创建群组等</td>
|
||
</tr>
|
||
<tr>
|
||
<td rowspan="3">应用</td>
|
||
<td>可使用</td>
|
||
<td>允许进行对话交互</td>
|
||
</tr>
|
||
<tr>
|
||
<td>可编辑</td>
|
||
<td>修改基本信息,进行流程编排等</td>
|
||
</tr>
|
||
<tr>
|
||
<td>可管理</td>
|
||
<td>添加或删除协作者</td>
|
||
</tr>
|
||
<tr>
|
||
<td rowspan="3">知识库</td>
|
||
<td>可使用</td>
|
||
<td>可以在应用中调用该知识库</td>
|
||
</tr>
|
||
<tr>
|
||
<td>可编辑</td>
|
||
<td>修改知识库的内容</td>
|
||
</tr>
|
||
<tr>
|
||
<td>可管理</td>
|
||
<td>添加或删除协作者</td>
|
||
</tr>
|
||
</tbody>
|
||
</table>
|
||
|
||
### 协作者
|
||
|
||
必须先添加**协作者**,才能对其进行权限管理:
|
||
|
||

|
||
|
||
管理团队权限时,需先选择成员/组织/群组,再进行权限配置。
|
||
|
||

|
||
|
||
对于应用和知识库等资源,可直接修改成员权限。
|
||
|
||

|
||
|
||
团队权限在专门的权限页面进行设置
|
||
|
||

|
||
|
||
## 特殊权限说明
|
||
|
||
### 管理员权限
|
||
|
||
管理员主要负责管理资源的协作关系,但有以下限制:
|
||
|
||
- 不能修改或移除自身权限
|
||
- 不能修改或移除其他管理员权限
|
||
-不能将管理员权限赋予其他协作者
|
||
|
||
### Owner 权限
|
||
|
||
每个资源都有唯一的 Owner,拥有该资源的最高权限。Owner
|
||
可以转移所有权,但转移后原 Owner 将失去对资源的权限。
|
||
|
||
### Root 权限
|
||
|
||
Root
|
||
作为系统唯一的超级管理员账号,对所有团队的所有资源拥有完全访问和管理权限。
|
||
|
||
## 使用技巧
|
||
|
||
### 1. 设置团队默认权限
|
||
|
||
利用\"全员群组\"可快速为整个团队设置基础权限。例如,为应用设置全员可访问权限。
|
||
|
||
**注意**:个人成员权限会覆盖全员组权限。例如,应用 A
|
||
设置了全员编辑权限,而用户 M 被单独设置为使用权限,则用户 M
|
||
只能使用而无法编辑该应用。
|
||
|
||
### 2. 批量权限管理
|
||
|
||
通过创建群组或组织,可以高效管理多用户的权限配置。先将用户添加到群组,再对群组整体授权。
|
||
|
||
### 开发者参考
|
||
> 以下内容面向开发者,如不涉及二次开发可跳过。
|
||
|
||
#### 权限设计原理
|
||
|
||
FastGPT 权限系统参考 Linux 权限设计,采用二进制方式存储权限位。权限位为
|
||
1 表示拥有该权限,为 0 表示无权限。Owner 权限特殊标记为全 1。
|
||
|
||
#### 权限表
|
||
|
||
权限信息存储在 MongoDB 的 resource_permissions 集合中,其主要字段包括:
|
||
|
||
- teamId: 团队标识
|
||
- tmbId/groupId/orgId: 权限主体(三选一)
|
||
- resourceType: 资源类型(team/app/dataset)
|
||
- permission: 权限值(数字)
|
||
- resourceId: 资源ID(团队资源为null)
|
||
|
||
系统通过这一数据结构实现了灵活而精确的权限控制。
|
||
|
||
对于这个表的 Schema 定义在 packages/service/support/permission/schema.ts
|
||
文件中。定义如下:
|
||
```typescript
|
||
export const ResourcePermissionSchema = new Schema({
|
||
teamId: {
|
||
type: Schema.Types.ObjectId,
|
||
ref: TeamCollectionName
|
||
},
|
||
tmbId: {
|
||
type: Schema.Types.ObjectId,
|
||
ref: TeamMemberCollectionName
|
||
},
|
||
groupId: {
|
||
type: Schema.Types.ObjectId,
|
||
ref: MemberGroupCollectionName
|
||
},
|
||
orgId: {
|
||
type: Schema.Types.ObjectId,
|
||
ref: OrgCollectionName
|
||
},
|
||
resourceType: {
|
||
type: String,
|
||
enum: Object.values(PerResourceTypeEnum),
|
||
required: true
|
||
},
|
||
permission: {
|
||
type: Number,
|
||
required: true
|
||
},
|
||
// Resrouce ID: App or DataSet or any other resource type.
|
||
// It is null if the resourceType is team.
|
||
resourceId: {
|
||
type: Schema.Types.ObjectId
|
||
}
|
||
});
|
||
```
|
||
|
||
# 快速了解 FastGPT
|
||
## FastGPT 的能力与优势
|
||
|
||
FastGPT 是一个基于 LLM 大语言模型的知识库问答系统,将智能对话与可视化编排完美结合,让 AI 应用开发变得简单自然。无论您是开发者还是业务人员,都能轻松打造专属的 AI 应用。
|
||
|
||
{{% alert icon="🤖 " context="success" %}}
|
||
快速开始体验
|
||
- 海外版:[https://tryfastgpt.ai](https://tryfastgpt.ai)
|
||
- 国内版:[https://fastgpt.cn](https://fastgpt.cn)
|
||
{{% /alert %}}
|
||
|
||
| | |
|
||
| --------------------- | --------------------------------- |
|
||
|  |  |
|
||
|
||
# FastGPT 的优势
|
||
## 1. 简单灵活,像搭积木一样简单 🧱
|
||
像搭乐高一样简单有趣,FastGPT 提供丰富的功能模块,通过简单拖拽就能搭建出个性化的 AI 应用,零代码也能实现复杂的业务流程。
|
||
## 2. 让数据更智能 🧠
|
||
FastGPT 提供完整的数据智能化解决方案,从数据导入、预处理到知识匹配,再到智能问答,全流程自动化。配合可视化的工作流设计,轻松打造专业级 AI 应用。
|
||
## 3. 开源开放,易于集成 🔗
|
||
FastGPT 基于 Apache 2.0 协议开源,支持二次开发。通过标准 API 即可快速接入,无需修改源码。支持 ChatGPT、Claude、DeepSeek 和文心一言等主流模型,持续迭代优化,始终保持产品活力。
|
||
|
||
---
|
||
|
||
# FastGPT 能做什么
|
||
## 1. 全能知识库
|
||
可轻松导入各式各样的文档及数据,能自动对其开展知识结构化处理工作。同时,具备支持多轮上下文理解的智能问答功能,还可为用户带来持续优化的知识库管理体验。
|
||

|
||
|
||
## 2. 可视化工作流
|
||
FastGPT直观的拖拽式界面设计,可零代码搭建复杂业务流程。还拥有丰富的功能节点组件,能应对多种业务需求,有着灵活的流程编排能力,按需定制业务流程。
|
||

|
||
|
||
## 3. 数据智能解析
|
||
FastGPT知识库系统对导入数据的处理极为灵活,可以智能处理PDF文档的复杂结构,保留图片、表格和LaTeX公式,自动识别扫描文件,并将内容结构化为清晰的Markdown格式。同时支持图片自动标注和索引,让视觉内容可被理解和检索,确保知识在AI问答中能被完整、准确地呈现和应用。
|
||
|
||

|
||
|
||
## 4. 工作流编排
|
||
基于 Flow 模块的工作流编排,可以帮助你设计更加复杂的问答流程。例如查询数据库、查询库存、预约实验室等。
|
||
|
||

|
||
|
||
## 5. 强大的 API 集成
|
||
FastGPT 完全对齐 OpenAI 官方接口,支持一键接入企业微信、公众号、飞书、钉钉等平台,让 AI 能力轻松融入您的业务场景。
|
||
|
||

|
||
|
||
---
|
||
|
||
# 核心特性
|
||
|
||
- 开箱即用的知识库系统
|
||
- 可视化的低代码工作流编排
|
||
- 支持主流大模型
|
||
- 简单易用的 API 接口
|
||
- 灵活的数据处理能力
|
||
|
||
---
|
||
|
||
# 知识库核心流程图
|
||
|
||

|
||
|
||
# 商业版
|
||
## FastGPT 商业版相关说明
|
||
|
||
## 简介
|
||
|
||
FastGPT 商业版是基于 FastGPT 开源版的增强版本,增加了一些独有的功能。只需安装一个商业版镜像,并在开源版基础上填写对应的内网地址,即可快速使用商业版。
|
||
|
||
## 功能差异
|
||
|
||
{{< table "table-hover table-striped-columns" >}}
|
||
| | 开源版 | 商业版 | 线上版 |
|
||
| ---- | ---- | ---- | ---- |
|
||
| 应用管理与高级编排 | ✅ | ✅ | ✅ |
|
||
| 文档知识库 | ✅ | ✅ | ✅ |
|
||
| 外部使用 | ✅ | ✅ | ✅ |
|
||
| API 知识库 | ✅ | ✅ | ✅ |
|
||
| 最大应用数量 | 500 | 无限制 | 由付费套餐决定 |
|
||
| 最大知识库数量(单个知识库内容无限制) | 30 | 无限制 | 由付费套餐决定 |
|
||
| 自定义版权信息 | ❌ | ✅ | 设计中 |
|
||
| 多租户与支付 | ❌ | ✅ | ✅ |
|
||
| 团队空间 & 权限 | ❌ | ✅ | ✅ |
|
||
| 应用发布安全配置 | ❌ | ✅ | ✅ |
|
||
| 内容审核 | ❌ | ✅ | ✅ |
|
||
| web站点同步 | ❌ | ✅ | ✅ |
|
||
| 主流文档库接入(目前支持:语雀、飞书) | ❌ | ✅ | ✅ |
|
||
| 增强训练模式 | ❌ | ✅ | ✅ |
|
||
| 第三方应用快速接入(飞书、公众号) | ❌ | ✅ | ✅ |
|
||
| 管理后台 | ❌ | ✅ | 不需要 |
|
||
| SSO 登录(可自定义,也可使用内置:Github、公众号、钉钉、谷歌等) | ❌ | ✅ | 不需要 |
|
||
| 图片知识库 | ❌ | 设计中 | 设计中 |
|
||
| 对话日志运营分析 | ❌ | 设计中 | 设计中 |
|
||
| 完整商业授权 | ❌ | ✅ | ✅ |
|
||
{{< /table >}}
|
||
|
||
## 商业版软件价格
|
||
|
||
FastGPT 商业版软件根据不同的部署方式,分为 3 类收费模式。下面列举各种部署方式一些常规内容,如仍有问题,可[联系咨询](https://fael3z0zfze.feishu.cn/share/base/form/shrcnRxj3utrzjywsom96Px4sud)
|
||
|
||
**共有服务**
|
||
|
||
1. Saas 商业授权许可 - 在商业版有效期内,可提供任意形式的商业服务。
|
||
2. 首次免费帮助部署。
|
||
3. 优先问题工单处理。
|
||
|
||
**特有服务**
|
||
|
||
{{< table "table-hover table-striped-columns" >}}
|
||
| 部署方式 | 特有服务 | 上线时长 | 标品价格 |
|
||
| ---- | ---- | ---- | ---- |
|
||
| Sealos全托管 | 1. 有效期内免费升级。<br>2. 免运维服务&数据库。 | 半天 | 10000元起/月(3个月起)<br>或<br>120000元起/年<br>8C32G 资源,额外资源另外收费。 |
|
||
| Sealos全托管(多节点) | 1. 有效期内免费升级。<br>2. 免运维服务&数据库。 | 半天 | 22000元起/月(3个月起)<br>或<br>264000元起/年<br>32C128G 资源,额外资源另外收费。 |
|
||
| 自有服务器部署 | 1. 6个版本免费升级支持。 | 14天内 | 具体价格和优惠可[联系咨询](https://fael3z0zfze.feishu.cn/share/base/form/shrcnRxj3utrzjywsom96Px4sud) |
|
||
{{< /table >}}
|
||
|
||
{{% alert icon="🤖 " context="success" %}}
|
||
- 6个版本的升级服务不是指只能用 6 个版本,而是指依赖 FastGPT 团队提供的升级服务。大部分时候,建议自行升级,也不麻烦。
|
||
- 全托管版本适合技术人员紧缺的团队,仅需关注业务推动,无需关心服务是否正常运行。
|
||
- 自有服务器部署版可以完全部署在自己服务器中。
|
||
- 单机版适合中小团队对内提供服务,需要自己维护数据库备份等。
|
||
- 高可用版适合对外提供在线服务,包含可视化监控、多副本、负载均衡、数据库自动备份等生产环境的基础设施。
|
||
{{% /alert %}}
|
||
|
||
## 联系方式
|
||
|
||
请填写[咨询问卷](https://fael3z0zfze.feishu.cn/share/base/form/shrcnRxj3utrzjywsom96Px4sud),我们会尽快与您联系。
|
||
|
||
|
||
## 技术支持
|
||
|
||
### 应用定制
|
||
|
||
根据需求,定制实现某个需求的编排功能,最终会交付一个应用编排。可根据实际情况商讨。
|
||
|
||
### 技术服务费(定开、维护、迁移、三方接入等)
|
||
|
||
2000 ~ 3000元/人/天
|
||
|
||
### 更新升级费用
|
||
|
||
大部分更新升级,重新拉镜像,然后执行一下初始化脚本就可以了,不需要执行额外操作。
|
||
|
||
跨版本更新或复杂更新可参考文档自行更新;或付费支持,标准与技术服务费一致。
|
||
|
||
|
||
## QA
|
||
|
||
### 如何交付?
|
||
|
||
完整版应用 = 开源版镜像 + 商业版镜像
|
||
|
||
我们会提供一个商业版镜像给你使用,该镜像需要一个 License 启动。
|
||
|
||
### 二次开发如何操作?
|
||
|
||
可以修改开源版部分代码,不支持修改商业版镜像。完整版本=开源版+商业版镜像,所以是可以修改部分内容的。但是如果二开了,后续则需要自己进行代码合并升级。
|
||
|
||
### Sealos 运行费用
|
||
|
||
Sealos 云服务属于按量计费,下面是它的价格表:
|
||
|
||

|
||
|
||
## 管理后台部分截图
|
||
|
||
| | | |
|
||
| ---- | ---- | ---- |
|
||
|  |  |  |
|
||
|
||
# 线上版定价
|
||
## FastGPT 线上版定价
|
||
|
||
线上版价格按套餐订阅模式,具体价格和计费请查看(请正确选择版本,账号不互通):
|
||
|
||
- [海外版](https://cloud.tryfastgpt.ai/price)
|
||
- [国内版](https://cloud.fastgpt.cn/price)
|
||
|
||
# Dalle3 绘图
|
||
## 使用 HTTP 模块绘制图片
|
||
|
||
| | |
|
||
| --------------------- | --------------------- |
|
||
|  |  |
|
||
|
||
## OpenAI Dalle3 接口
|
||
|
||
先来看下官方接口的参数和响应值:
|
||
|
||
Body
|
||
|
||
```json
|
||
{
|
||
"model": "dall-e-3",
|
||
"prompt": "A cute baby sea otter",
|
||
"n": 1,
|
||
"size": "1024x1024"
|
||
}
|
||
```
|
||
|
||
Response
|
||
|
||
```json
|
||
{
|
||
"created": 1589478378,
|
||
"data": [
|
||
{
|
||
"url": "https://..."
|
||
},
|
||
{
|
||
"url": "https://..."
|
||
}
|
||
]
|
||
}
|
||
```
|
||
|
||
## 编排思路
|
||
|
||
1. 通过 AI 来优化图片绘制的提示词(这步省略了,自己找提示词即可)
|
||
2. 通过 `【HTTP 请求】模块` 调用 Dalle3 接口,获取图片的 URL。
|
||
3. 通过 `【文本加工】模块` 来构建 `Markdown` 的图片格式。
|
||
4. 通过 `【指定回复】模块` 来直接输出图片链接。
|
||
|
||
### 1. 构建 HTTP 模块
|
||
|
||
请求参数直接复制 Dalle3 接口的即可,并求改 prompt 为变量。需要增加一个 `Headers.Authorization` 。
|
||
|
||
Body:
|
||
|
||
```json
|
||
{
|
||
"model": "dall-e-3",
|
||
"prompt": "{{prompt}}",
|
||
"n": 1,
|
||
"size": "1024x1024"
|
||
}
|
||
```
|
||
|
||
Headers:
|
||
|
||
`Authorization: Bearer sk-xxx`
|
||
|
||
Response:
|
||
|
||
响应值需要根据 Dalle3 接口的返回值进行获取,我们只绘制了1张图片,所以只需要取第一张图片的 URL 即可。给 HTTP 模块增加一个自定义输出 `data[0].url` 。
|
||
|
||
### 2. 文本加工 - 构建图片链接
|
||
|
||
在 `Markdown` 语法中 `` 表示插入图片,图片链接由【HTTP 请求】模块输出。
|
||
|
||
因此可以增加一个输入来接收 `【HTTP 请求】模块` 的图片链接输出,并在 `【文本加工】模块 - 文本` 中通过变量来引用图片链接,从而得到一个完整的 `Markdown` 图片格式。
|
||
|
||
### 3. 指定回复
|
||
|
||
指定回复可以直接输出传入的内容到客户端,因此可以直接输出加工好的 `Markdown` 图片格式即可。
|
||
|
||
## 编排代码
|
||
|
||
{{% details title="编排配置" closed="true" %}}
|
||
|
||
```json
|
||
{
|
||
"nodes": [
|
||
{
|
||
"nodeId": "userGuide",
|
||
"name": "系统配置",
|
||
"intro": "可以配置应用的系统参数",
|
||
"avatar": "/imgs/workflow/userGuide.png",
|
||
"flowNodeType": "userGuide",
|
||
"position": {
|
||
"x": 531.2422736065552,
|
||
"y": -486.7611729549753
|
||
},
|
||
"inputs": [
|
||
{
|
||
"key": "welcomeText",
|
||
"renderTypeList": [
|
||
"hidden"
|
||
],
|
||
"valueType": "string",
|
||
"label": "core.app.Welcome Text",
|
||
"value": ""
|
||
},
|
||
{
|
||
"key": "variables",
|
||
"renderTypeList": [
|
||
"hidden"
|
||
],
|
||
"valueType": "any",
|
||
"label": "core.app.Chat Variable",
|
||
"value": []
|
||
},
|
||
{
|
||
"key": "questionGuide",
|
||
"valueType": "boolean",
|
||
"renderTypeList": [
|
||
"hidden"
|
||
],
|
||
"label": "core.app.Question Guide",
|
||
"value": false
|
||
},
|
||
{
|
||
"key": "tts",
|
||
"renderTypeList": [
|
||
"hidden"
|
||
],
|
||
"valueType": "any",
|
||
"label": "",
|
||
"value": {
|
||
"type": "web"
|
||
}
|
||
},
|
||
{
|
||
"key": "whisper",
|
||
"renderTypeList": [
|
||
"hidden"
|
||
],
|
||
"valueType": "any",
|
||
"label": "",
|
||
"value": {
|
||
"open": false,
|
||
"autoSend": false,
|
||
"autoTTSResponse": false
|
||
}
|
||
},
|
||
{
|
||
"key": "scheduleTrigger",
|
||
"renderTypeList": [
|
||
"hidden"
|
||
],
|
||
"valueType": "any",
|
||
"label": "",
|
||
"value": null
|
||
}
|
||
],
|
||
"outputs": []
|
||
},
|
||
{
|
||
"nodeId": "448745",
|
||
"name": "流程开始",
|
||
"intro": "",
|
||
"avatar": "/imgs/workflow/userChatInput.svg",
|
||
"flowNodeType": "workflowStart",
|
||
"position": {
|
||
"x": 532.1275542407774,
|
||
"y": 46.03775600322817
|
||
},
|
||
"inputs": [
|
||
{
|
||
"key": "userChatInput",
|
||
"renderTypeList": [
|
||
"reference",
|
||
"textarea"
|
||
],
|
||
"valueType": "string",
|
||
"label": "用户问题",
|
||
"required": true,
|
||
"toolDescription": "用户问题"
|
||
}
|
||
],
|
||
"outputs": [
|
||
{
|
||
"id": "userChatInput",
|
||
"key": "userChatInput",
|
||
"label": "core.module.input.label.user question",
|
||
"valueType": "string",
|
||
"type": "static"
|
||
}
|
||
]
|
||
},
|
||
{
|
||
"nodeId": "tMyUnRL5jIrC",
|
||
"name": "HTTP 请求",
|
||
"intro": "可以发出一个 HTTP 请求,实现更为复杂的操作(联网搜索、数据库查询等)",
|
||
"avatar": "/imgs/workflow/http.png",
|
||
"flowNodeType": "httpRequest468",
|
||
"showStatus": true,
|
||
"position": {
|
||
"x": 921.2377506442713,
|
||
"y": -483.94114977914256
|
||
},
|
||
"inputs": [
|
||
{
|
||
"key": "system_addInputParam",
|
||
"renderTypeList": [
|
||
"addInputParam"
|
||
],
|
||
"valueType": "dynamic",
|
||
"label": "",
|
||
"required": false,
|
||
"description": "core.module.input.description.HTTP Dynamic Input",
|
||
"editField": {
|
||
"key": true,
|
||
"valueType": true
|
||
}
|
||
},
|
||
{
|
||
"key": "prompt",
|
||
"valueType": "string",
|
||
"label": "prompt",
|
||
"renderTypeList": [
|
||
"reference"
|
||
],
|
||
"description": "",
|
||
"canEdit": true,
|
||
"editField": {
|
||
"key": true,
|
||
"valueType": true
|
||
},
|
||
"value": [
|
||
"448745",
|
||
"userChatInput"
|
||
]
|
||
},
|
||
{
|
||
"key": "system_httpMethod",
|
||
"renderTypeList": [
|
||
"custom"
|
||
],
|
||
"valueType": "string",
|
||
"label": "",
|
||
"value": "POST",
|
||
"required": true
|
||
},
|
||
{
|
||
"key": "system_httpReqUrl",
|
||
"renderTypeList": [
|
||
"hidden"
|
||
],
|
||
"valueType": "string",
|
||
"label": "",
|
||
"description": "core.module.input.description.Http Request Url",
|
||
"placeholder": "https://api.ai.com/getInventory",
|
||
"required": false,
|
||
"value": "https://api.openai.com/v1/images/generations"
|
||
},
|
||
{
|
||
"key": "system_httpHeader",
|
||
"renderTypeList": [
|
||
"custom"
|
||
],
|
||
"valueType": "any",
|
||
"value": [
|
||
{
|
||
"key": "Authorization",
|
||
"type": "string",
|
||
"value": "Bearer "
|
||
}
|
||
],
|
||
"label": "",
|
||
"description": "core.module.input.description.Http Request Header",
|
||
"placeholder": "core.module.input.description.Http Request Header",
|
||
"required": false
|
||
},
|
||
{
|
||
"key": "system_httpParams",
|
||
"renderTypeList": [
|
||
"hidden"
|
||
],
|
||
"valueType": "any",
|
||
"value": [],
|
||
"label": "",
|
||
"required": false
|
||
},
|
||
{
|
||
"key": "system_httpJsonBody",
|
||
"renderTypeList": [
|
||
"hidden"
|
||
],
|
||
"valueType": "any",
|
||
"value": "{\n \"model\": \"dall-e-3\",\n \"prompt\": \"{{prompt}}\",\n \"n\": 1,\n \"size\": \"1024x1024\"\n}",
|
||
"label": "",
|
||
"required": false
|
||
}
|
||
],
|
||
"outputs": [
|
||
{
|
||
"id": "system_addOutputParam",
|
||
"key": "system_addOutputParam",
|
||
"type": "dynamic",
|
||
"valueType": "dynamic",
|
||
"label": "",
|
||
"editField": {
|
||
"key": true,
|
||
"valueType": true
|
||
}
|
||
},
|
||
{
|
||
"id": "httpRawResponse",
|
||
"key": "httpRawResponse",
|
||
"label": "原始响应",
|
||
"description": "HTTP请求的原始响应。只能接受字符串或JSON类型响应数据。",
|
||
"valueType": "any",
|
||
"type": "static"
|
||
},
|
||
{
|
||
"id": "DeKGGioBwaMf",
|
||
"type": "dynamic",
|
||
"key": "data[0].url",
|
||
"valueType": "string",
|
||
"label": "data[0].url"
|
||
}
|
||
]
|
||
},
|
||
{
|
||
"nodeId": "CO3POL8svbbi",
|
||
"name": "文本加工",
|
||
"intro": "可对固定或传入的文本进行加工后输出,非字符串类型数据最终会转成字符串类型。",
|
||
"avatar": "/imgs/workflow/textEditor.svg",
|
||
"flowNodeType": "pluginModule",
|
||
"showStatus": false,
|
||
"position": {
|
||
"x": 1417.5940290051137,
|
||
"y": -478.81889618104356
|
||
},
|
||
"inputs": [
|
||
{
|
||
"key": "system_addInputParam",
|
||
"valueType": "dynamic",
|
||
"label": "动态外部数据",
|
||
"renderTypeList": [
|
||
"addInputParam"
|
||
],
|
||
"required": false,
|
||
"description": "",
|
||
"canEdit": false,
|
||
"value": "",
|
||
"editField": {
|
||
"key": true
|
||
},
|
||
"dynamicParamDefaultValue": {
|
||
"inputType": "reference",
|
||
"valueType": "string",
|
||
"required": true
|
||
}
|
||
},
|
||
{
|
||
"key": "url",
|
||
"valueType": "string",
|
||
"label": "url",
|
||
"renderTypeList": [
|
||
"reference"
|
||
],
|
||
"required": true,
|
||
"description": "",
|
||
"canEdit": true,
|
||
"editField": {
|
||
"key": true
|
||
},
|
||
"value": [
|
||
"tMyUnRL5jIrC",
|
||
"DeKGGioBwaMf"
|
||
]
|
||
},
|
||
{
|
||
"key": "文本",
|
||
"valueType": "string",
|
||
"label": "文本",
|
||
"renderTypeList": [
|
||
"textarea"
|
||
],
|
||
"required": true,
|
||
"description": "",
|
||
"canEdit": false,
|
||
"value": "",
|
||
"editField": {
|
||
"key": true
|
||
},
|
||
"maxLength": "",
|
||
"dynamicParamDefaultValue": {
|
||
"inputType": "reference",
|
||
"valueType": "string",
|
||
"required": true
|
||
}
|
||
}
|
||
],
|
||
"outputs": [
|
||
{
|
||
"id": "text",
|
||
"type": "static",
|
||
"key": "text",
|
||
"valueType": "string",
|
||
"label": "text",
|
||
"description": ""
|
||
}
|
||
],
|
||
"pluginId": "community-textEditor"
|
||
},
|
||
{
|
||
"nodeId": "7mapnCgHfKW6",
|
||
"name": "指定回复",
|
||
"intro": "该模块可以直接回复一段指定的内容。常用于引导、提示。非字符串内容传入时,会转成字符串进行输出。",
|
||
"avatar": "/imgs/workflow/reply.png",
|
||
"flowNodeType": "answerNode",
|
||
"position": {
|
||
"x": 1922.5628399315042,
|
||
"y": -471.67391598231796
|
||
},
|
||
"inputs": [
|
||
{
|
||
"key": "text",
|
||
"renderTypeList": [
|
||
"textarea",
|
||
"reference"
|
||
],
|
||
"valueType": "string",
|
||
"label": "core.module.input.label.Response content",
|
||
"description": "core.module.input.description.Response content",
|
||
"placeholder": "core.module.input.description.Response content",
|
||
"selectedTypeIndex": 1,
|
||
"value": [
|
||
"CO3POL8svbbi",
|
||
"text"
|
||
]
|
||
}
|
||
],
|
||
"outputs": []
|
||
}
|
||
],
|
||
"edges": [
|
||
{
|
||
"source": "448745",
|
||
"target": "tMyUnRL5jIrC",
|
||
"sourceHandle": "448745-source-right",
|
||
"targetHandle": "tMyUnRL5jIrC-target-left"
|
||
},
|
||
{
|
||
"source": "tMyUnRL5jIrC",
|
||
"target": "CO3POL8svbbi",
|
||
"sourceHandle": "tMyUnRL5jIrC-source-right",
|
||
"targetHandle": "CO3POL8svbbi-target-left"
|
||
},
|
||
{
|
||
"source": "CO3POL8svbbi",
|
||
"target": "7mapnCgHfKW6",
|
||
"sourceHandle": "CO3POL8svbbi-source-right",
|
||
"targetHandle": "7mapnCgHfKW6-target-left"
|
||
}
|
||
]
|
||
}
|
||
```
|
||
|
||
{{% /details %}}
|
||
|
||
# 英语作文纠错机器人
|
||
## 使用 FastGPT 创建一个用于英语作文纠错的机器人,帮助用户检测并纠正语言错误
|
||
|
||
FastGPT 提供了一种基于 LLM Model 搭建应用的简便方式。
|
||
|
||
本文通过搭建一个英语作文纠错机器人,介绍一下如何使用 **工作流**
|
||
|
||
## 搭建过程
|
||
|
||
### 1. 创建工作流
|
||
|
||

|
||
|
||
可以从 *多轮翻译机器人* 开始创建。
|
||
|
||
> 多轮翻译机器人是 @米开朗基杨 同学创建的,同样也是一个值得学习的工作流。
|
||
|
||
### 2. 获取输入,使用大模型进行分析
|
||
|
||
我们期望让大模型处理文字,返回一个结构化的数据,由我们自己处理。
|
||
|
||

|
||
|
||
**提示词** 是最重要的一个参数,这里提供的提示词仅供参考:
|
||
|
||
~~~Markdown
|
||
## 角色
|
||
资深英语写作专家
|
||
|
||
## 任务
|
||
对输入的原文进行分析。 找出其中的各种错误, 包括但不限于单词拼写错误、 语法错误等。
|
||
注意: 忽略标点符号前后空格的问题。
|
||
注意: 对于存在错误的句子, 提出修改建议是指指出这个句子中的具体部分, 然后提出将这一个部分修改替换为什么。
|
||
|
||
## 输出格式
|
||
不要使用 Markdown 语法, 输入 JSON 格式的内容。
|
||
输出的"reason"的内容使用中文。
|
||
直接输出一个列表, 其成员为一个相同类型的对象, 定义如下
|
||
您正在找回 FastGPT 账号
|
||
```
|
||
{
|
||
“raw”: string; // 表示原文
|
||
“reason”: string; // 表示原因
|
||
“suggestion”: string; // 修改建议
|
||
}
|
||
```
|
||
~~~
|
||
|
||
可以在模型选择的窗口中设置禁用 AI 回复。
|
||
|
||
这样就看不到输出的 json 格式的内容了。
|
||
|
||

|
||
|
||
### 3. 数据处理
|
||
|
||
上面的大模型输出了一个 json,这里要进行数据处理。数据处理可以使用代码执行组件。
|
||
|
||

|
||
|
||
```JavaScript
|
||
function main({data}){
|
||
const array = JSON.parse(data)
|
||
return {
|
||
content: array.map(
|
||
(item, index) => {
|
||
return `
|
||
## 分析${index+1}
|
||
- **错误**: ${item.raw}
|
||
- **分析**: ${item.reason}
|
||
- **修改建议**: ${item.suggestion}
|
||
`
|
||
}
|
||
).join('')
|
||
}
|
||
}
|
||
```
|
||
|
||
上面的代码将 JSON 解析为 Object, 然后拼接成一串 Markdown 语法的字符串。
|
||
|
||
FastGPT 的指定回复组件可以将 Markdown 解析为 Html 返回。
|
||
|
||
## 发布
|
||
|
||
可以使用发布渠道进行发布。
|
||
|
||

|
||
|
||
可以选择通过 URL 访问,或者是直接嵌入你的网页中。
|
||
|
||
> [点我使用](https://share.fastgpt.in/chat/share?shareId=b4r173wkcjae7wpnexcvmyc3)
|
||
|
||
# 发送飞书webhook通知
|
||
## 利用工具调用模块,发送一个飞书webhook通知
|
||
|
||
该文章展示如何发送一个简单的飞书webhook通知,以此类推,发送其他类型的通知也可以这么操作。
|
||
|
||
| | |
|
||
| --------------------- | --------------------- |
|
||
|  |  |
|
||
|
||
## 1. 准备飞书机器人
|
||
|
||
| | | |
|
||
| --------------------- | --------------------- |--------------------- |
|
||
|  |  | |
|
||
|
||
## 2. 导入编排代码
|
||
|
||
复制下面配置,点击「高级编排」右上角的导入按键,导入该配置,导入后将飞书提供的接口地址复制到「HTTP 模块」。
|
||
|
||
{{% details title="编排配置" closed="true" %}}
|
||
|
||
```json
|
||
{
|
||
"nodes": [
|
||
{
|
||
"nodeId": "userGuide",
|
||
"name": "系统配置",
|
||
"intro": "可以配置应用的系统参数",
|
||
"avatar": "/imgs/workflow/userGuide.png",
|
||
"flowNodeType": "userGuide",
|
||
"position": {
|
||
"x": 303.41163758039283,
|
||
"y": -552.297639861266
|
||
},
|
||
"version": "481",
|
||
"inputs": [],
|
||
"outputs": []
|
||
},
|
||
{
|
||
"nodeId": "workflowStartNodeId",
|
||
"name": "流程开始",
|
||
"intro": "",
|
||
"avatar": "/imgs/workflow/userChatInput.svg",
|
||
"flowNodeType": "workflowStart",
|
||
"position": {
|
||
"x": 529.3935295017156,
|
||
"y": 197.114018410347
|
||
},
|
||
"version": "481",
|
||
"inputs": [
|
||
{
|
||
"key": "userChatInput",
|
||
"renderTypeList": [
|
||
"reference",
|
||
"textarea"
|
||
],
|
||
"valueType": "string",
|
||
"label": "用户问题",
|
||
"required": true,
|
||
"toolDescription": "用户问题"
|
||
}
|
||
],
|
||
"outputs": [
|
||
{
|
||
"id": "userChatInput",
|
||
"key": "userChatInput",
|
||
"label": "core.module.input.label.user question",
|
||
"valueType": "string",
|
||
"type": "static"
|
||
}
|
||
]
|
||
},
|
||
{
|
||
"nodeId": "u6IAOEssxoZT",
|
||
"name": "工具调用",
|
||
"intro": "通过AI模型自动选择一个或多个功能块进行调用,也可以对插件进行调用。",
|
||
"avatar": "/imgs/workflow/tool.svg",
|
||
"flowNodeType": "tools",
|
||
"showStatus": true,
|
||
"position": {
|
||
"x": 1003.146243538873,
|
||
"y": 48.52327869406625
|
||
},
|
||
"version": "481",
|
||
"inputs": [
|
||
{
|
||
"key": "model",
|
||
"renderTypeList": [
|
||
"settingLLMModel",
|
||
"reference"
|
||
],
|
||
"label": "core.module.input.label.aiModel",
|
||
"valueType": "string",
|
||
"llmModelType": "all",
|
||
"value": "gpt-3.5-turbo"
|
||
},
|
||
{
|
||
"key": "temperature",
|
||
"renderTypeList": [
|
||
"hidden"
|
||
],
|
||
"label": "",
|
||
"value": 0,
|
||
"valueType": "number",
|
||
"min": 0,
|
||
"max": 10,
|
||
"step": 1
|
||
},
|
||
{
|
||
"key": "maxToken",
|
||
"renderTypeList": [
|
||
"hidden"
|
||
],
|
||
"label": "",
|
||
"value": 2000,
|
||
"valueType": "number",
|
||
"min": 100,
|
||
"max": 4000,
|
||
"step": 50
|
||
},
|
||
{
|
||
"key": "systemPrompt",
|
||
"renderTypeList": [
|
||
"textarea",
|
||
"reference"
|
||
],
|
||
"max": 3000,
|
||
"valueType": "string",
|
||
"label": "core.ai.Prompt",
|
||
"description": "core.app.tip.chatNodeSystemPromptTip",
|
||
"placeholder": "core.app.tip.chatNodeSystemPromptTip"
|
||
},
|
||
{
|
||
"key": "history",
|
||
"renderTypeList": [
|
||
"numberInput",
|
||
"reference"
|
||
],
|
||
"valueType": "chatHistory",
|
||
"label": "core.module.input.label.chat history",
|
||
"description": "最多携带多少轮对话记录",
|
||
"required": true,
|
||
"min": 0,
|
||
"max": 50,
|
||
"value": 6
|
||
},
|
||
{
|
||
"key": "userChatInput",
|
||
"renderTypeList": [
|
||
"reference",
|
||
"textarea"
|
||
],
|
||
"valueType": "string",
|
||
"label": "用户问题",
|
||
"required": true,
|
||
"value": [
|
||
"workflowStartNodeId",
|
||
"userChatInput"
|
||
]
|
||
}
|
||
],
|
||
"outputs": [
|
||
{
|
||
"id": "answerText",
|
||
"key": "answerText",
|
||
"label": "core.module.output.label.Ai response content",
|
||
"description": "core.module.output.description.Ai response content",
|
||
"valueType": "string",
|
||
"type": "static"
|
||
}
|
||
]
|
||
},
|
||
{
|
||
"nodeId": "fvY5hb0K646V",
|
||
"name": "工具调用终止",
|
||
"intro": "该模块需配置工具调用使用。当该模块被执行时,本次工具调用将会强制结束,并且不再调用AI针对工具调用结果回答问题。",
|
||
"avatar": "/imgs/workflow/toolStop.svg",
|
||
"flowNodeType": "stopTool",
|
||
"position": {
|
||
"x": 2367.838362362707,
|
||
"y": 732.355988936165
|
||
},
|
||
"version": "481",
|
||
"inputs": [],
|
||
"outputs": []
|
||
},
|
||
{
|
||
"nodeId": "x9rN2a4WnZmt",
|
||
"name": "HTTP 请求",
|
||
"intro": "向飞书发送一个webhooks通知信息。",
|
||
"avatar": "/imgs/workflow/http.png",
|
||
"flowNodeType": "httpRequest468",
|
||
"showStatus": true,
|
||
"position": {
|
||
"x": 1623.9214305901633,
|
||
"y": 22.777089001645862
|
||
},
|
||
"version": "486",
|
||
"inputs": [
|
||
{
|
||
"key": "system_addInputParam",
|
||
"renderTypeList": [
|
||
"addInputParam"
|
||
],
|
||
"valueType": "dynamic",
|
||
"label": "",
|
||
"required": false,
|
||
"description": "core.module.input.description.HTTP Dynamic Input",
|
||
"editField": {
|
||
"key": true,
|
||
"valueType": true
|
||
}
|
||
},
|
||
{
|
||
"valueType": "string",
|
||
"renderTypeList": [
|
||
"reference"
|
||
],
|
||
"key": "text",
|
||
"label": "text",
|
||
"toolDescription": "发送的消息",
|
||
"required": true,
|
||
"canEdit": true,
|
||
"editField": {
|
||
"key": true,
|
||
"description": true
|
||
}
|
||
},
|
||
{
|
||
"key": "system_httpMethod",
|
||
"renderTypeList": [
|
||
"custom"
|
||
],
|
||
"valueType": "string",
|
||
"label": "",
|
||
"value": "POST",
|
||
"required": true
|
||
},
|
||
{
|
||
"key": "system_httpReqUrl",
|
||
"renderTypeList": [
|
||
"hidden"
|
||
],
|
||
"valueType": "string",
|
||
"label": "",
|
||
"description": "core.module.input.description.Http Request Url",
|
||
"placeholder": "https://api.ai.com/getInventory",
|
||
"required": false,
|
||
"value": ""
|
||
},
|
||
{
|
||
"key": "system_httpHeader",
|
||
"renderTypeList": [
|
||
"custom"
|
||
],
|
||
"valueType": "any",
|
||
"value": [],
|
||
"label": "",
|
||
"description": "core.module.input.description.Http Request Header",
|
||
"placeholder": "core.module.input.description.Http Request Header",
|
||
"required": false
|
||
},
|
||
{
|
||
"key": "system_httpParams",
|
||
"renderTypeList": [
|
||
"hidden"
|
||
],
|
||
"valueType": "any",
|
||
"value": [],
|
||
"label": "",
|
||
"required": false
|
||
},
|
||
{
|
||
"key": "system_httpJsonBody",
|
||
"renderTypeList": [
|
||
"hidden"
|
||
],
|
||
"valueType": "any",
|
||
"value": "{\r\n \"msg_type\": \"text\",\r\n \"content\": {\r\n \"text\": \"{{text}}\"\r\n }\r\n}",
|
||
"label": "",
|
||
"required": false
|
||
}
|
||
],
|
||
"outputs": [
|
||
{
|
||
"id": "system_addOutputParam",
|
||
"key": "system_addOutputParam",
|
||
"type": "dynamic",
|
||
"valueType": "dynamic",
|
||
"label": "",
|
||
"editField": {
|
||
"key": true,
|
||
"valueType": true
|
||
}
|
||
},
|
||
{
|
||
"id": "error",
|
||
"key": "error",
|
||
"label": "请求错误",
|
||
"description": "HTTP请求错误信息,成功时返回空",
|
||
"valueType": "object",
|
||
"type": "static"
|
||
},
|
||
{
|
||
"id": "httpRawResponse",
|
||
"key": "httpRawResponse",
|
||
"label": "原始响应",
|
||
"required": true,
|
||
"description": "HTTP请求的原始响应。只能接受字符串或JSON类型响应数据。",
|
||
"valueType": "any",
|
||
"type": "static"
|
||
}
|
||
]
|
||
},
|
||
{
|
||
"nodeId": "aGHGqH2oUupj",
|
||
"name": "指定回复",
|
||
"intro": "该模块可以直接回复一段指定的内容。常用于引导、提示。非字符串内容传入时,会转成字符串进行输出。",
|
||
"avatar": "/imgs/workflow/reply.png",
|
||
"flowNodeType": "answerNode",
|
||
"position": {
|
||
"x": 2350.7077940158674,
|
||
"y": 107.32448732713493
|
||
},
|
||
"version": "481",
|
||
"inputs": [
|
||
{
|
||
"key": "text",
|
||
"renderTypeList": [
|
||
"textarea",
|
||
"reference"
|
||
],
|
||
"valueType": "any",
|
||
"required": true,
|
||
"label": "core.module.input.label.Response content",
|
||
"description": "core.module.input.description.Response content",
|
||
"placeholder": "core.module.input.description.Response content",
|
||
"value": "嘻嘻,发送成功"
|
||
}
|
||
],
|
||
"outputs": []
|
||
}
|
||
],
|
||
"edges": [
|
||
{
|
||
"source": "workflowStartNodeId",
|
||
"target": "u6IAOEssxoZT",
|
||
"sourceHandle": "workflowStartNodeId-source-right",
|
||
"targetHandle": "u6IAOEssxoZT-target-left"
|
||
},
|
||
{
|
||
"source": "u6IAOEssxoZT",
|
||
"target": "x9rN2a4WnZmt",
|
||
"sourceHandle": "selectedTools",
|
||
"targetHandle": "selectedTools"
|
||
},
|
||
{
|
||
"source": "x9rN2a4WnZmt",
|
||
"target": "fvY5hb0K646V",
|
||
"sourceHandle": "x9rN2a4WnZmt-source-right",
|
||
"targetHandle": "fvY5hb0K646V-target-left"
|
||
},
|
||
{
|
||
"source": "x9rN2a4WnZmt",
|
||
"target": "aGHGqH2oUupj",
|
||
"sourceHandle": "x9rN2a4WnZmt-source-right",
|
||
"targetHandle": "aGHGqH2oUupj-target-left"
|
||
}
|
||
],
|
||
"chatConfig": {
|
||
"variables": [
|
||
{
|
||
"id": "txq1ca",
|
||
"key": "test",
|
||
"label": "测试",
|
||
"type": "custom",
|
||
"required": true,
|
||
"maxLen": 50,
|
||
"enums": [
|
||
{
|
||
"value": ""
|
||
}
|
||
]
|
||
}
|
||
],
|
||
"questionGuide": false,
|
||
"scheduledTriggerConfig": {
|
||
"cronString": "",
|
||
"timezone": "Asia/Shanghai",
|
||
"defaultPrompt": ""
|
||
},
|
||
"_id": "66715d4bf577287d39e35ecf"
|
||
}
|
||
}
|
||
```
|
||
|
||
{{% /details %}}
|
||
|
||
|
||
## 3. 流程说明
|
||
|
||
1. 为工具调用挂载一个HTTP模块,功能描述写上:调用飞书webhook,发送一个通知。
|
||
2. HTTP模块的输入参数中,填写飞书机器人的地址,填写发送的通知内容。
|
||
3. HTTP模块输出连接上一个工具终止模块,用于强制结束工具调用。不终止的话,会把调用结果返回给模型,模型会继续回答一次问题,浪费 Tokens
|
||
4. HTTP模块输出再连上一个指定回复,直接回复一个发送成功,用于替代AI的回答。
|
||
|
||
# 固定开头和结尾内容
|
||
## 利用指定回复,创建固定的开头和结尾
|
||
|
||

|
||
|
||

|
||
|
||
|
||
如上图,可以通过指定回复编排一个固定的开头和结尾内容。
|
||
|
||
## 模块编排
|
||
|
||
复制下面配置,点击「高级编排」右上角的导入按键,导入该配置。
|
||
|
||
{{% details title="编排配置" closed="true" %}}
|
||
|
||
```json
|
||
{
|
||
"nodes": [
|
||
{
|
||
"nodeId": "7z5g5h",
|
||
"name": "流程开始",
|
||
"intro": "",
|
||
"avatar": "/imgs/workflow/userChatInput.svg",
|
||
"flowNodeType": "workflowStart",
|
||
"position": {
|
||
"x": -269.50851681351924,
|
||
"y": 1657.6123698022448
|
||
},
|
||
"inputs": [
|
||
{
|
||
"key": "userChatInput",
|
||
"renderTypeList": [
|
||
"reference",
|
||
"textarea"
|
||
],
|
||
"valueType": "string",
|
||
"label": "问题输入",
|
||
"required": true,
|
||
"toolDescription": "用户问题",
|
||
"type": "systemInput",
|
||
"showTargetInApp": false,
|
||
"showTargetInPlugin": false,
|
||
"connected": false,
|
||
"selectedTypeIndex": 0,
|
||
"value": [
|
||
"7z5g5h",
|
||
"userChatInput"
|
||
]
|
||
}
|
||
],
|
||
"outputs": [
|
||
{
|
||
"id": "userChatInput",
|
||
"type": "static",
|
||
"key": "userChatInput",
|
||
"valueType": "string",
|
||
"label": "core.module.input.label.user question"
|
||
}
|
||
]
|
||
},
|
||
{
|
||
"nodeId": "nlfwkc",
|
||
"name": "AI 对话",
|
||
"intro": "AI 大模型对话",
|
||
"avatar": "/imgs/workflow/AI.png",
|
||
"flowNodeType": "chatNode",
|
||
"showStatus": true,
|
||
"position": {
|
||
"x": 907.2058332478431,
|
||
"y": 1348.9992737142143
|
||
},
|
||
"inputs": [
|
||
{
|
||
"key": "model",
|
||
"renderTypeList": [
|
||
"settingLLMModel",
|
||
"reference"
|
||
],
|
||
"label": "core.module.input.label.aiModel",
|
||
"valueType": "string",
|
||
"type": "selectLLMModel",
|
||
"required": true,
|
||
"showTargetInApp": false,
|
||
"showTargetInPlugin": false,
|
||
"value": "gpt-3.5-turbo",
|
||
"connected": false,
|
||
"selectedTypeIndex": 0
|
||
},
|
||
{
|
||
"key": "temperature",
|
||
"renderTypeList": [
|
||
"hidden"
|
||
],
|
||
"label": "",
|
||
"value": 0,
|
||
"valueType": "number",
|
||
"min": 0,
|
||
"max": 10,
|
||
"step": 1,
|
||
"type": "hidden",
|
||
"showTargetInApp": false,
|
||
"showTargetInPlugin": false,
|
||
"connected": false,
|
||
"selectedTypeIndex": 0
|
||
},
|
||
{
|
||
"key": "maxToken",
|
||
"renderTypeList": [
|
||
"hidden"
|
||
],
|
||
"label": "",
|
||
"value": 2000,
|
||
"valueType": "number",
|
||
"min": 100,
|
||
"max": 4000,
|
||
"step": 50,
|
||
"type": "hidden",
|
||
"showTargetInApp": false,
|
||
"showTargetInPlugin": false,
|
||
"connected": false,
|
||
"selectedTypeIndex": 0
|
||
},
|
||
{
|
||
"key": "isResponseAnswerText",
|
||
"renderTypeList": [
|
||
"hidden"
|
||
],
|
||
"label": "",
|
||
"value": true,
|
||
"valueType": "boolean",
|
||
"type": "hidden",
|
||
"showTargetInApp": false,
|
||
"showTargetInPlugin": false,
|
||
"connected": false,
|
||
"selectedTypeIndex": 0
|
||
},
|
||
{
|
||
"key": "quoteTemplate",
|
||
"renderTypeList": [
|
||
"hidden"
|
||
],
|
||
"label": "",
|
||
"valueType": "string",
|
||
"type": "hidden",
|
||
"showTargetInApp": false,
|
||
"showTargetInPlugin": false,
|
||
"connected": false,
|
||
"selectedTypeIndex": 0
|
||
},
|
||
{
|
||
"key": "quotePrompt",
|
||
"renderTypeList": [
|
||
"hidden"
|
||
],
|
||
"label": "",
|
||
"valueType": "string",
|
||
"type": "hidden",
|
||
"showTargetInApp": false,
|
||
"showTargetInPlugin": false,
|
||
"connected": false,
|
||
"selectedTypeIndex": 0
|
||
},
|
||
{
|
||
"key": "systemPrompt",
|
||
"renderTypeList": [
|
||
"textarea",
|
||
"reference"
|
||
],
|
||
"max": 300,
|
||
"valueType": "string",
|
||
"label": "core.ai.Prompt",
|
||
"description": "core.app.tip.chatNodeSystemPromptTip",
|
||
"placeholder": "core.app.tip.chatNodeSystemPromptTip",
|
||
"type": "textarea",
|
||
"showTargetInApp": true,
|
||
"showTargetInPlugin": true,
|
||
"value": "",
|
||
"connected": false,
|
||
"selectedTypeIndex": 0
|
||
},
|
||
{
|
||
"key": "history",
|
||
"renderTypeList": [
|
||
"numberInput",
|
||
"reference"
|
||
],
|
||
"valueType": "chatHistory",
|
||
"label": "core.module.input.label.chat history",
|
||
"required": true,
|
||
"min": 0,
|
||
"max": 30,
|
||
"value": 6,
|
||
"type": "numberInput",
|
||
"showTargetInApp": true,
|
||
"showTargetInPlugin": true,
|
||
"connected": false,
|
||
"selectedTypeIndex": 0
|
||
},
|
||
{
|
||
"key": "userChatInput",
|
||
"renderTypeList": [
|
||
"reference",
|
||
"textarea"
|
||
],
|
||
"valueType": "string",
|
||
"label": "问题输入",
|
||
"required": true,
|
||
"toolDescription": "用户问题",
|
||
"type": "custom",
|
||
"showTargetInApp": true,
|
||
"showTargetInPlugin": true,
|
||
"connected": true,
|
||
"selectedTypeIndex": 0,
|
||
"value": [
|
||
"7z5g5h",
|
||
"userChatInput"
|
||
]
|
||
},
|
||
{
|
||
"key": "quoteQA",
|
||
"renderTypeList": [
|
||
"settingDatasetQuotePrompt"
|
||
],
|
||
"label": "",
|
||
"debugLabel": "知识库引用",
|
||
"description": "core.module.Dataset quote.Input description",
|
||
"valueType": "datasetQuote",
|
||
"type": "target",
|
||
"showTargetInApp": true,
|
||
"showTargetInPlugin": true,
|
||
"connected": true,
|
||
"selectedTypeIndex": 0,
|
||
"value": [
|
||
"fljhzy",
|
||
"quoteQA"
|
||
]
|
||
}
|
||
],
|
||
"outputs": [
|
||
{
|
||
"id": "answerText",
|
||
"type": "static",
|
||
"key": "answerText",
|
||
"valueType": "string",
|
||
"label": "core.module.output.label.Ai response content",
|
||
"description": "core.module.output.description.Ai response content"
|
||
},
|
||
{
|
||
"id": "history",
|
||
"type": "static",
|
||
"key": "history",
|
||
"valueType": "chatHistory",
|
||
"label": "core.module.output.label.New context",
|
||
"description": "core.module.output.description.New context"
|
||
}
|
||
]
|
||
},
|
||
{
|
||
"nodeId": "q9equb",
|
||
"name": "core.module.template.App system setting",
|
||
"intro": "可以配置应用的系统参数。",
|
||
"avatar": "/imgs/workflow/userGuide.png",
|
||
"flowNodeType": "userGuide",
|
||
"position": {
|
||
"x": -275.92529567956024,
|
||
"y": 1094.1001488133452
|
||
},
|
||
"inputs": [
|
||
{
|
||
"key": "welcomeText",
|
||
"renderTypeList": [
|
||
"hidden"
|
||
],
|
||
"valueType": "string",
|
||
"label": "core.app.Welcome Text",
|
||
"type": "hidden",
|
||
"showTargetInApp": false,
|
||
"showTargetInPlugin": false,
|
||
"value": "你好,我是电影《星际穿越》 AI 助手,有什么可以帮助你的?\n[导演是谁]\n[剧情介绍]\n[票房分析]",
|
||
"connected": false,
|
||
"selectedTypeIndex": 0
|
||
},
|
||
{
|
||
"key": "variables",
|
||
"renderTypeList": [
|
||
"hidden"
|
||
],
|
||
"valueType": "any",
|
||
"label": "core.module.Variable",
|
||
"value": [],
|
||
"type": "hidden",
|
||
"showTargetInApp": false,
|
||
"showTargetInPlugin": false,
|
||
"connected": false,
|
||
"selectedTypeIndex": 0
|
||
},
|
||
{
|
||
"key": "questionGuide",
|
||
"valueType": "boolean",
|
||
"renderTypeList": [
|
||
"hidden"
|
||
],
|
||
"label": "",
|
||
"type": "switch",
|
||
"showTargetInApp": false,
|
||
"showTargetInPlugin": false,
|
||
"connected": false,
|
||
"selectedTypeIndex": 0
|
||
},
|
||
{
|
||
"key": "tts",
|
||
"renderTypeList": [
|
||
"hidden"
|
||
],
|
||
"valueType": "any",
|
||
"label": "",
|
||
"type": "hidden",
|
||
"showTargetInApp": false,
|
||
"showTargetInPlugin": false,
|
||
"connected": false,
|
||
"selectedTypeIndex": 0
|
||
},
|
||
{
|
||
"key": "whisper",
|
||
"renderTypeList": [
|
||
"hidden"
|
||
],
|
||
"valueType": "any",
|
||
"label": ""
|
||
},
|
||
{
|
||
"key": "scheduleTrigger",
|
||
"renderTypeList": [
|
||
"hidden"
|
||
],
|
||
"valueType": "any",
|
||
"label": "",
|
||
"value": null
|
||
}
|
||
],
|
||
"outputs": []
|
||
},
|
||
{
|
||
"nodeId": "tc90wz",
|
||
"name": "指定回复",
|
||
"intro": "该模块可以直接回复一段指定的内容。常用于引导、提示。非字符串内容传入时,会转成字符串进行输出。",
|
||
"avatar": "/imgs/workflow/reply.png",
|
||
"flowNodeType": "answerNode",
|
||
"position": {
|
||
"x": 159.49274056478237,
|
||
"y": 1621.4635230667668
|
||
},
|
||
"inputs": [
|
||
{
|
||
"key": "text",
|
||
"renderTypeList": [
|
||
"textarea",
|
||
"reference"
|
||
],
|
||
"valueType": "any",
|
||
"label": "core.module.input.label.Response content",
|
||
"description": "core.module.input.description.Response content",
|
||
"placeholder": "core.module.input.description.Response content",
|
||
"type": "textarea",
|
||
"showTargetInApp": true,
|
||
"showTargetInPlugin": true,
|
||
"value": "这是开头\\n",
|
||
"connected": false,
|
||
"selectedTypeIndex": 0
|
||
}
|
||
],
|
||
"outputs": []
|
||
},
|
||
{
|
||
"nodeId": "U5T3dMVY4wj7",
|
||
"name": "指定回复",
|
||
"intro": "该模块可以直接回复一段指定的内容。常用于引导、提示。非字符串内容传入时,会转成字符串进行输出。",
|
||
"avatar": "/imgs/workflow/reply.png",
|
||
"flowNodeType": "answerNode",
|
||
"position": {
|
||
"x": 1467.0625486167608,
|
||
"y": 1597.346243737531
|
||
},
|
||
"inputs": [
|
||
{
|
||
"key": "text",
|
||
"renderTypeList": [
|
||
"textarea",
|
||
"reference"
|
||
],
|
||
"valueType": "string",
|
||
"label": "core.module.input.label.Response content",
|
||
"description": "core.module.input.description.Response content",
|
||
"placeholder": "core.module.input.description.Response content",
|
||
"value": "这是结尾"
|
||
}
|
||
],
|
||
"outputs": []
|
||
}
|
||
],
|
||
"edges": [
|
||
{
|
||
"source": "7z5g5h",
|
||
"target": "tc90wz",
|
||
"sourceHandle": "7z5g5h-source-right",
|
||
"targetHandle": "tc90wz-target-left"
|
||
},
|
||
{
|
||
"source": "tc90wz",
|
||
"target": "nlfwkc",
|
||
"sourceHandle": "tc90wz-source-right",
|
||
"targetHandle": "nlfwkc-target-left"
|
||
},
|
||
{
|
||
"source": "nlfwkc",
|
||
"target": "U5T3dMVY4wj7",
|
||
"sourceHandle": "nlfwkc-source-right",
|
||
"targetHandle": "U5T3dMVY4wj7-target-left"
|
||
}
|
||
]
|
||
}
|
||
```
|
||
|
||
{{% /details %}}
|
||
|
||
# 接入谷歌搜索
|
||
## 将 FastGPT 接入谷歌搜索
|
||
|
||
| | |
|
||
| --------------------- | --------------------- |
|
||
| 工具调用模式  | 工具调用模式  |
|
||
| 非工具调用模式  | 非工具调用模式  |
|
||
|
||
|
||
如上图,利用「HTTP请求」模块,你可以外接一个搜索引擎作为 AI 回复的参考资料。这里以调用 Google Search API 为例。注意:本文主要是为了介绍 「HTTP请求」模块,具体的搜索效果需要依赖提示词和搜索引擎,尤其是【搜索引擎】,简单的搜索引擎无法获取更详细的内容,这部分可能需要更多的调试。
|
||
|
||
## 注册 Google Search API
|
||
|
||
[参考这篇文章](https://zhuanlan.zhihu.com/p/174666017),每天可以免费使用 100 次。
|
||
|
||
## 写一个 Google Search 接口
|
||
|
||
这里用 [Laf](https://laf.dev/) 快速实现一个接口,即写即发布,无需部署。务必打开 POST 请求方式。
|
||
|
||
{{% details title="Laf 谷歌搜索Demo" closed="true" %}}
|
||
|
||
```ts
|
||
import cloud from '@lafjs/cloud'
|
||
|
||
const googleSearchKey = "xxx"
|
||
const googleCxId = "3740cxxx"
|
||
const baseurl = "https://www.googleapis.com/customsearch/v1"
|
||
|
||
type RequestType = {
|
||
searchKey: string
|
||
}
|
||
|
||
export default async function (ctx: FunctionContext) {
|
||
const { searchKey } = ctx.body as RequestType
|
||
console.log(ctx.body)
|
||
if (!searchKey) {
|
||
return {
|
||
prompt: ""
|
||
}
|
||
}
|
||
|
||
try {
|
||
const { data } = await cloud.fetch.get(baseurl, {
|
||
params: {
|
||
q: searchKey,
|
||
cx: googleCxId,
|
||
key: googleSearchKey,
|
||
c2coff: 1,
|
||
start: 1,
|
||
end: 20,
|
||
dateRestrict: 'm[1]',
|
||
}
|
||
})
|
||
const result = data.items.map((item) => item.snippet).join('\n');
|
||
|
||
return { prompt: result }
|
||
} catch (err) {
|
||
console.log(err)
|
||
ctx.response.status(500)
|
||
return {
|
||
message: "异常"
|
||
}
|
||
}
|
||
}
|
||
```
|
||
|
||
{{% /details %}}
|
||
|
||
## 模块编排 - 工具调用模式
|
||
|
||
利用工具模块,则无需多余的操作,直接由模型决定是否调用谷歌搜索,并生成检索词即可。
|
||
|
||
复制下面配置,进入「高级编排」,在右上角的 “...” 中选择「导入配置」,导入后修改「HTTP 请求」模块 - 请求地址 的值。
|
||
|
||
{{% details title="编排配置" closed="true" %}}
|
||
|
||
```json
|
||
{
|
||
"nodes": [
|
||
{
|
||
"nodeId": "userGuide",
|
||
"name": "系统配置",
|
||
"intro": "可以配置应用的系统参数",
|
||
"avatar": "/imgs/workflow/userGuide.png",
|
||
"flowNodeType": "userGuide",
|
||
"position": {
|
||
"x": 262.2732338817093,
|
||
"y": -476.00241136598146
|
||
},
|
||
"inputs": [
|
||
{
|
||
"key": "welcomeText",
|
||
"renderTypeList": [
|
||
"hidden"
|
||
],
|
||
"valueType": "string",
|
||
"label": "core.app.Welcome Text",
|
||
"value": ""
|
||
},
|
||
{
|
||
"key": "variables",
|
||
"renderTypeList": [
|
||
"hidden"
|
||
],
|
||
"valueType": "any",
|
||
"label": "core.app.Chat Variable",
|
||
"value": []
|
||
},
|
||
{
|
||
"key": "questionGuide",
|
||
"valueType": "boolean",
|
||
"renderTypeList": [
|
||
"hidden"
|
||
],
|
||
"label": "core.app.Question Guide",
|
||
"value": false
|
||
},
|
||
{
|
||
"key": "tts",
|
||
"renderTypeList": [
|
||
"hidden"
|
||
],
|
||
"valueType": "any",
|
||
"label": "",
|
||
"value": {
|
||
"type": "web"
|
||
}
|
||
},
|
||
{
|
||
"key": "whisper",
|
||
"renderTypeList": [
|
||
"hidden"
|
||
],
|
||
"valueType": "any",
|
||
"label": "",
|
||
"value": {
|
||
"open": false,
|
||
"autoSend": false,
|
||
"autoTTSResponse": false
|
||
}
|
||
},
|
||
{
|
||
"key": "scheduleTrigger",
|
||
"renderTypeList": [
|
||
"hidden"
|
||
],
|
||
"valueType": "any",
|
||
"label": "",
|
||
"value": null
|
||
}
|
||
],
|
||
"outputs": []
|
||
},
|
||
{
|
||
"nodeId": "448745",
|
||
"name": "流程开始",
|
||
"intro": "",
|
||
"avatar": "/imgs/workflow/userChatInput.svg",
|
||
"flowNodeType": "workflowStart",
|
||
"position": {
|
||
"x": 295.8944548701009,
|
||
"y": 110.81336038514848
|
||
},
|
||
"inputs": [
|
||
{
|
||
"key": "userChatInput",
|
||
"renderTypeList": [
|
||
"reference",
|
||
"textarea"
|
||
],
|
||
"valueType": "string",
|
||
"label": "用户问题",
|
||
"required": true,
|
||
"toolDescription": "用户问题"
|
||
}
|
||
],
|
||
"outputs": [
|
||
{
|
||
"id": "userChatInput",
|
||
"key": "userChatInput",
|
||
"label": "core.module.input.label.user question",
|
||
"valueType": "string",
|
||
"type": "static"
|
||
}
|
||
]
|
||
},
|
||
{
|
||
"nodeId": "NOgbnBzUwDgT",
|
||
"name": "工具调用",
|
||
"intro": "通过AI模型自动选择一个或多个功能块进行调用,也可以对插件进行调用。",
|
||
"avatar": "/imgs/workflow/tool.svg",
|
||
"flowNodeType": "tools",
|
||
"showStatus": true,
|
||
"position": {
|
||
"x": 1028.8358722416106,
|
||
"y": -500.8755882990822
|
||
},
|
||
"inputs": [
|
||
{
|
||
"key": "model",
|
||
"renderTypeList": [
|
||
"settingLLMModel",
|
||
"reference"
|
||
],
|
||
"label": "core.module.input.label.aiModel",
|
||
"valueType": "string",
|
||
"llmModelType": "all",
|
||
"value": "FastAI-plus"
|
||
},
|
||
{
|
||
"key": "temperature",
|
||
"renderTypeList": [
|
||
"hidden"
|
||
],
|
||
"label": "",
|
||
"value": 0,
|
||
"valueType": "number",
|
||
"min": 0,
|
||
"max": 10,
|
||
"step": 1
|
||
},
|
||
{
|
||
"key": "maxToken",
|
||
"renderTypeList": [
|
||
"hidden"
|
||
],
|
||
"label": "",
|
||
"value": 2000,
|
||
"valueType": "number",
|
||
"min": 100,
|
||
"max": 4000,
|
||
"step": 50
|
||
},
|
||
{
|
||
"key": "systemPrompt",
|
||
"renderTypeList": [
|
||
"textarea",
|
||
"reference"
|
||
],
|
||
"max": 3000,
|
||
"valueType": "string",
|
||
"label": "core.ai.Prompt",
|
||
"description": "core.app.tip.chatNodeSystemPromptTip",
|
||
"placeholder": "core.app.tip.chatNodeSystemPromptTip",
|
||
"value": "你是谷歌搜索机器人,根据当前问题和对话记录生成搜索词。你需要自行判断是否需要进行网络实时查询:\n- 如果需查询则生成搜索词。\n- 如果不需要查询则不返回字段。"
|
||
},
|
||
{
|
||
"key": "history",
|
||
"renderTypeList": [
|
||
"numberInput",
|
||
"reference"
|
||
],
|
||
"valueType": "chatHistory",
|
||
"label": "core.module.input.label.chat history",
|
||
"required": true,
|
||
"min": 0,
|
||
"max": 30,
|
||
"value": 6
|
||
},
|
||
{
|
||
"key": "userChatInput",
|
||
"renderTypeList": [
|
||
"reference",
|
||
"textarea"
|
||
],
|
||
"valueType": "string",
|
||
"label": "用户问题",
|
||
"required": true,
|
||
"value": [
|
||
"448745",
|
||
"userChatInput"
|
||
]
|
||
}
|
||
],
|
||
"outputs": []
|
||
},
|
||
{
|
||
"nodeId": "GMELVPxHfpg5",
|
||
"name": "HTTP 请求",
|
||
"intro": "调用谷歌搜索,查询相关内容",
|
||
"avatar": "/imgs/workflow/http.png",
|
||
"flowNodeType": "httpRequest468",
|
||
"showStatus": true,
|
||
"position": {
|
||
"x": 1013.2159795348916,
|
||
"y": 210.8685573380423
|
||
},
|
||
"inputs": [
|
||
{
|
||
"key": "system_addInputParam",
|
||
"renderTypeList": [
|
||
"addInputParam"
|
||
],
|
||
"valueType": "dynamic",
|
||
"label": "",
|
||
"required": false,
|
||
"description": "core.module.input.description.HTTP Dynamic Input",
|
||
"editField": {
|
||
"key": true,
|
||
"valueType": true
|
||
}
|
||
},
|
||
{
|
||
"valueType": "string",
|
||
"renderTypeList": [
|
||
"reference"
|
||
],
|
||
"key": "query",
|
||
"label": "query",
|
||
"toolDescription": "谷歌搜索检索词",
|
||
"required": true,
|
||
"canEdit": true,
|
||
"editField": {
|
||
"key": true,
|
||
"description": true
|
||
}
|
||
},
|
||
{
|
||
"key": "system_httpMethod",
|
||
"renderTypeList": [
|
||
"custom"
|
||
],
|
||
"valueType": "string",
|
||
"label": "",
|
||
"value": "POST",
|
||
"required": true
|
||
},
|
||
{
|
||
"key": "system_httpReqUrl",
|
||
"renderTypeList": [
|
||
"hidden"
|
||
],
|
||
"valueType": "string",
|
||
"label": "",
|
||
"description": "core.module.input.description.Http Request Url",
|
||
"placeholder": "https://api.ai.com/getInventory",
|
||
"required": false,
|
||
"value": "https://xxxxxx.laf.dev/google_search"
|
||
},
|
||
{
|
||
"key": "system_httpHeader",
|
||
"renderTypeList": [
|
||
"custom"
|
||
],
|
||
"valueType": "any",
|
||
"value": [],
|
||
"label": "",
|
||
"description": "core.module.input.description.Http Request Header",
|
||
"placeholder": "core.module.input.description.Http Request Header",
|
||
"required": false
|
||
},
|
||
{
|
||
"key": "system_httpParams",
|
||
"renderTypeList": [
|
||
"hidden"
|
||
],
|
||
"valueType": "any",
|
||
"value": [],
|
||
"label": "",
|
||
"required": false
|
||
},
|
||
{
|
||
"key": "system_httpJsonBody",
|
||
"renderTypeList": [
|
||
"hidden"
|
||
],
|
||
"valueType": "any",
|
||
"value": "{\n \"searchKey\": \"{{query}}\"\n}",
|
||
"label": "",
|
||
"required": false
|
||
}
|
||
],
|
||
"outputs": [
|
||
{
|
||
"id": "system_addOutputParam",
|
||
"key": "system_addOutputParam",
|
||
"type": "dynamic",
|
||
"valueType": "dynamic",
|
||
"label": "",
|
||
"editField": {
|
||
"key": true,
|
||
"valueType": true
|
||
}
|
||
},
|
||
{
|
||
"id": "httpRawResponse",
|
||
"key": "httpRawResponse",
|
||
"label": "原始响应",
|
||
"description": "HTTP请求的原始响应。只能接受字符串或JSON类型响应数据。",
|
||
"valueType": "any",
|
||
"type": "static"
|
||
},
|
||
{
|
||
"id": "M5YmxaYe8em1",
|
||
"type": "dynamic",
|
||
"key": "prompt",
|
||
"valueType": "string",
|
||
"label": "prompt"
|
||
}
|
||
]
|
||
}
|
||
],
|
||
"edges": [
|
||
{
|
||
"source": "448745",
|
||
"target": "NOgbnBzUwDgT",
|
||
"sourceHandle": "448745-source-right",
|
||
"targetHandle": "NOgbnBzUwDgT-target-left"
|
||
},
|
||
{
|
||
"source": "NOgbnBzUwDgT",
|
||
"target": "GMELVPxHfpg5",
|
||
"sourceHandle": "selectedTools",
|
||
"targetHandle": "selectedTools"
|
||
}
|
||
]
|
||
}
|
||
```
|
||
|
||
{{% /details %}}
|
||
|
||
## 模块编排 - 非工具调用方式
|
||
|
||
复制下面配置,进入「高级编排」,在右上角的 “...” 中选择「导入配置」,导入后修改「HTTP 请求」模块 - 请求地址 的值。
|
||
|
||
{{% details title="编排配置" closed="true" %}}
|
||
|
||
```json
|
||
{
|
||
"nodes": [
|
||
{
|
||
"nodeId": "userGuide",
|
||
"name": "系统配置",
|
||
"intro": "可以配置应用的系统参数",
|
||
"avatar": "/imgs/workflow/userGuide.png",
|
||
"flowNodeType": "userGuide",
|
||
"position": {
|
||
"x": 126.6166221945532,
|
||
"y": -456.00079128406236
|
||
},
|
||
"inputs": [
|
||
{
|
||
"key": "welcomeText",
|
||
"renderTypeList": [
|
||
"hidden"
|
||
],
|
||
"valueType": "string",
|
||
"label": "core.app.Welcome Text",
|
||
"value": ""
|
||
},
|
||
{
|
||
"key": "variables",
|
||
"renderTypeList": [
|
||
"hidden"
|
||
],
|
||
"valueType": "any",
|
||
"label": "core.app.Chat Variable",
|
||
"value": []
|
||
},
|
||
{
|
||
"key": "questionGuide",
|
||
"valueType": "boolean",
|
||
"renderTypeList": [
|
||
"hidden"
|
||
],
|
||
"label": "core.app.Question Guide",
|
||
"value": false
|
||
},
|
||
{
|
||
"key": "tts",
|
||
"renderTypeList": [
|
||
"hidden"
|
||
],
|
||
"valueType": "any",
|
||
"label": "",
|
||
"value": {
|
||
"type": "web"
|
||
}
|
||
},
|
||
{
|
||
"key": "whisper",
|
||
"renderTypeList": [
|
||
"hidden"
|
||
],
|
||
"valueType": "any",
|
||
"label": "",
|
||
"value": {
|
||
"open": false,
|
||
"autoSend": false,
|
||
"autoTTSResponse": false
|
||
}
|
||
},
|
||
{
|
||
"key": "scheduleTrigger",
|
||
"renderTypeList": [
|
||
"hidden"
|
||
],
|
||
"valueType": "any",
|
||
"label": "",
|
||
"value": null
|
||
}
|
||
],
|
||
"outputs": []
|
||
},
|
||
{
|
||
"nodeId": "448745",
|
||
"name": "流程开始",
|
||
"intro": "",
|
||
"avatar": "/imgs/workflow/userChatInput.svg",
|
||
"flowNodeType": "workflowStart",
|
||
"position": {
|
||
"x": 189.99351048246606,
|
||
"y": 50.36949968375285
|
||
},
|
||
"inputs": [
|
||
{
|
||
"key": "userChatInput",
|
||
"renderTypeList": [
|
||
"reference",
|
||
"textarea"
|
||
],
|
||
"valueType": "string",
|
||
"label": "用户问题",
|
||
"required": true,
|
||
"toolDescription": "用户问题"
|
||
}
|
||
],
|
||
"outputs": [
|
||
{
|
||
"id": "userChatInput",
|
||
"key": "userChatInput",
|
||
"label": "core.module.input.label.user question",
|
||
"valueType": "string",
|
||
"type": "static"
|
||
}
|
||
]
|
||
},
|
||
{
|
||
"nodeId": "TWD5BAqIIFaj",
|
||
"name": "判断器",
|
||
"intro": "根据一定的条件,执行不同的分支。",
|
||
"avatar": "/imgs/workflow/ifElse.svg",
|
||
"flowNodeType": "ifElseNode",
|
||
"showStatus": true,
|
||
"position": {
|
||
"x": 1187.4821088468154,
|
||
"y": -143.83989103517257
|
||
},
|
||
"inputs": [
|
||
{
|
||
"key": "condition",
|
||
"valueType": "string",
|
||
"label": "",
|
||
"renderTypeList": [
|
||
"hidden"
|
||
],
|
||
"required": false,
|
||
"value": "And"
|
||
},
|
||
{
|
||
"key": "ifElseList",
|
||
"renderTypeList": [
|
||
"hidden"
|
||
],
|
||
"valueType": "any",
|
||
"label": "",
|
||
"value": [
|
||
{
|
||
"variable": [
|
||
"lG52GzzMm65z",
|
||
"6yF19MRD3nuB"
|
||
],
|
||
"condition": "isEmpty",
|
||
"value": ""
|
||
}
|
||
]
|
||
}
|
||
],
|
||
"outputs": [
|
||
{
|
||
"id": "IF",
|
||
"key": "IF",
|
||
"label": "IF",
|
||
"valueType": "any",
|
||
"type": "source"
|
||
},
|
||
{
|
||
"id": "ELSE",
|
||
"key": "ELSE",
|
||
"label": "ELSE",
|
||
"valueType": "any",
|
||
"type": "source"
|
||
}
|
||
]
|
||
},
|
||
{
|
||
"nodeId": "1ljV0oTq4zeC",
|
||
"name": "HTTP 请求",
|
||
"intro": "可以发出一个 HTTP 请求,实现更为复杂的操作(联网搜索、数据库查询等)",
|
||
"avatar": "/imgs/workflow/http.png",
|
||
"flowNodeType": "httpRequest468",
|
||
"showStatus": true,
|
||
"position": {
|
||
"x": 1992.0328696814468,
|
||
"y": 127.08080019458595
|
||
},
|
||
"inputs": [
|
||
{
|
||
"key": "DYNAMIC_INPUT_KEY",
|
||
"renderTypeList": [
|
||
"addInputParam"
|
||
],
|
||
"valueType": "dynamic",
|
||
"label": "",
|
||
"required": false,
|
||
"description": "core.module.input.description.HTTP Dynamic Input",
|
||
"editField": {
|
||
"key": true,
|
||
"valueType": true
|
||
}
|
||
},
|
||
{
|
||
"key": "searchKey",
|
||
"valueType": "string",
|
||
"label": "searchKey",
|
||
"renderTypeList": [
|
||
"reference"
|
||
],
|
||
"description": "",
|
||
"canEdit": true,
|
||
"editField": {
|
||
"key": true,
|
||
"valueType": true
|
||
},
|
||
"value": [
|
||
"lG52GzzMm65z",
|
||
"6yF19MRD3nuB"
|
||
]
|
||
},
|
||
{
|
||
"key": "system_httpMethod",
|
||
"renderTypeList": [
|
||
"custom"
|
||
],
|
||
"valueType": "string",
|
||
"label": "",
|
||
"value": "POST",
|
||
"required": true
|
||
},
|
||
{
|
||
"key": "system_httpReqUrl",
|
||
"renderTypeList": [
|
||
"hidden"
|
||
],
|
||
"valueType": "string",
|
||
"label": "",
|
||
"description": "core.module.input.description.Http Request Url",
|
||
"placeholder": "https://api.ai.com/getInventory",
|
||
"required": false,
|
||
"value": "https://xxxxxx.laf.dev/google_search"
|
||
},
|
||
{
|
||
"key": "system_httpHeader",
|
||
"renderTypeList": [
|
||
"custom"
|
||
],
|
||
"valueType": "any",
|
||
"value": [],
|
||
"label": "",
|
||
"description": "core.module.input.description.Http Request Header",
|
||
"placeholder": "core.module.input.description.Http Request Header",
|
||
"required": false
|
||
},
|
||
{
|
||
"key": "system_httpParams",
|
||
"renderTypeList": [
|
||
"hidden"
|
||
],
|
||
"valueType": "any",
|
||
"value": [],
|
||
"label": "",
|
||
"required": false
|
||
},
|
||
{
|
||
"key": "system_httpJsonBody",
|
||
"renderTypeList": [
|
||
"hidden"
|
||
],
|
||
"valueType": "any",
|
||
"value": "{\n \"searchKey\": \"{{searchKey}}\"\n}",
|
||
"label": "",
|
||
"required": false
|
||
},
|
||
{
|
||
"key": "system_addInputParam",
|
||
"renderTypeList": [
|
||
"addInputParam"
|
||
],
|
||
"valueType": "dynamic",
|
||
"label": "",
|
||
"required": false,
|
||
"description": "core.module.input.description.HTTP Dynamic Input",
|
||
"editField": {
|
||
"key": true,
|
||
"valueType": true
|
||
}
|
||
}
|
||
],
|
||
"outputs": [
|
||
{
|
||
"id": "system_addOutputParam",
|
||
"key": "system_addOutputParam",
|
||
"type": "dynamic",
|
||
"valueType": "dynamic",
|
||
"label": "",
|
||
"editField": {
|
||
"key": true,
|
||
"valueType": true
|
||
}
|
||
},
|
||
{
|
||
"id": "httpRawResponse",
|
||
"key": "httpRawResponse",
|
||
"label": "原始响应",
|
||
"description": "HTTP请求的原始响应。只能接受字符串或JSON类型响应数据。",
|
||
"valueType": "any",
|
||
"type": "static"
|
||
},
|
||
{
|
||
"id": "yw0oz9XWFXYf",
|
||
"type": "dynamic",
|
||
"key": "prompt",
|
||
"valueType": "string",
|
||
"label": "prompt"
|
||
}
|
||
]
|
||
},
|
||
{
|
||
"nodeId": "Nc6hBdb3l9Pe",
|
||
"name": "AI 对话",
|
||
"intro": "AI 大模型对话",
|
||
"avatar": "/imgs/workflow/AI.png",
|
||
"flowNodeType": "chatNode",
|
||
"showStatus": true,
|
||
"position": {
|
||
"x": 1982.442841318768,
|
||
"y": -664.9716343803625
|
||
},
|
||
"inputs": [
|
||
{
|
||
"key": "model",
|
||
"renderTypeList": [
|
||
"settingLLMModel",
|
||
"reference"
|
||
],
|
||
"label": "core.module.input.label.aiModel",
|
||
"valueType": "string",
|
||
"value": "gpt-3.5-turbo"
|
||
},
|
||
{
|
||
"key": "temperature",
|
||
"renderTypeList": [
|
||
"hidden"
|
||
],
|
||
"label": "",
|
||
"value": 0,
|
||
"valueType": "number",
|
||
"min": 0,
|
||
"max": 10,
|
||
"step": 1
|
||
},
|
||
{
|
||
"key": "maxToken",
|
||
"renderTypeList": [
|
||
"hidden"
|
||
],
|
||
"label": "",
|
||
"value": 2000,
|
||
"valueType": "number",
|
||
"min": 100,
|
||
"max": 4000,
|
||
"step": 50
|
||
},
|
||
{
|
||
"key": "isResponseAnswerText",
|
||
"renderTypeList": [
|
||
"hidden"
|
||
],
|
||
"label": "",
|
||
"value": true,
|
||
"valueType": "boolean"
|
||
},
|
||
{
|
||
"key": "quoteTemplate",
|
||
"renderTypeList": [
|
||
"hidden"
|
||
],
|
||
"label": "",
|
||
"valueType": "string"
|
||
},
|
||
{
|
||
"key": "quotePrompt",
|
||
"renderTypeList": [
|
||
"hidden"
|
||
],
|
||
"label": "",
|
||
"valueType": "string"
|
||
},
|
||
{
|
||
"key": "systemPrompt",
|
||
"renderTypeList": [
|
||
"textarea",
|
||
"reference"
|
||
],
|
||
"max": 3000,
|
||
"valueType": "string",
|
||
"label": "core.ai.Prompt",
|
||
"description": "core.app.tip.chatNodeSystemPromptTip",
|
||
"placeholder": "core.app.tip.chatNodeSystemPromptTip",
|
||
"selectedTypeIndex": 1,
|
||
"value": [
|
||
"1ljV0oTq4zeC",
|
||
"httpRawResponse"
|
||
]
|
||
},
|
||
{
|
||
"key": "history",
|
||
"renderTypeList": [
|
||
"numberInput",
|
||
"reference"
|
||
],
|
||
"valueType": "chatHistory",
|
||
"label": "core.module.input.label.chat history",
|
||
"required": true,
|
||
"min": 0,
|
||
"max": 30,
|
||
"value": 6
|
||
},
|
||
{
|
||
"key": "userChatInput",
|
||
"renderTypeList": [
|
||
"reference",
|
||
"textarea"
|
||
],
|
||
"valueType": "string",
|
||
"label": "用户问题",
|
||
"required": true,
|
||
"toolDescription": "用户问题",
|
||
"value": [
|
||
"448745",
|
||
"userChatInput"
|
||
]
|
||
},
|
||
{
|
||
"key": "quoteQA",
|
||
"renderTypeList": [
|
||
"settingDatasetQuotePrompt"
|
||
],
|
||
"label": "",
|
||
"debugLabel": "知识库引用",
|
||
"description": "",
|
||
"valueType": "datasetQuote"
|
||
}
|
||
],
|
||
"outputs": [
|
||
{
|
||
"id": "history",
|
||
"key": "history",
|
||
"label": "core.module.output.label.New context",
|
||
"description": "core.module.output.description.New context",
|
||
"valueType": "chatHistory",
|
||
"type": "static"
|
||
},
|
||
{
|
||
"id": "answerText",
|
||
"key": "answerText",
|
||
"label": "core.module.output.label.Ai response content",
|
||
"description": "core.module.output.description.Ai response content",
|
||
"valueType": "string",
|
||
"type": "static"
|
||
}
|
||
]
|
||
},
|
||
{
|
||
"nodeId": "FYLw1BokYUad",
|
||
"name": "文本加工",
|
||
"intro": "可对固定或传入的文本进行加工后输出,非字符串类型数据最终会转成字符串类型。",
|
||
"avatar": "/imgs/workflow/textEditor.svg",
|
||
"flowNodeType": "pluginModule",
|
||
"showStatus": false,
|
||
"position": {
|
||
"x": 2479.5913201989906,
|
||
"y": 288.52613614690904
|
||
},
|
||
"inputs": [
|
||
{
|
||
"key": "system_addInputParam",
|
||
"valueType": "dynamic",
|
||
"label": "动态外部数据",
|
||
"renderTypeList": [
|
||
"addInputParam"
|
||
],
|
||
"required": false,
|
||
"description": "",
|
||
"canEdit": false,
|
||
"value": "",
|
||
"editField": {
|
||
"key": true
|
||
},
|
||
"dynamicParamDefaultValue": {
|
||
"inputType": "reference",
|
||
"valueType": "string",
|
||
"required": true
|
||
}
|
||
},
|
||
{
|
||
"key": "q",
|
||
"valueType": "string",
|
||
"label": "q",
|
||
"renderTypeList": [
|
||
"reference"
|
||
],
|
||
"required": true,
|
||
"description": "",
|
||
"canEdit": true,
|
||
"editField": {
|
||
"key": true
|
||
},
|
||
"value": [
|
||
"448745",
|
||
"userChatInput"
|
||
]
|
||
},
|
||
{
|
||
"key": "response",
|
||
"valueType": "string",
|
||
"label": "response",
|
||
"renderTypeList": [
|
||
"reference"
|
||
],
|
||
"required": true,
|
||
"description": "",
|
||
"canEdit": true,
|
||
"editField": {
|
||
"key": true
|
||
},
|
||
"value": [
|
||
"1ljV0oTq4zeC",
|
||
"yw0oz9XWFXYf"
|
||
]
|
||
},
|
||
{
|
||
"key": "文本",
|
||
"valueType": "string",
|
||
"label": "文本",
|
||
"renderTypeList": [
|
||
"textarea"
|
||
],
|
||
"required": true,
|
||
"description": "",
|
||
"canEdit": false,
|
||
"value": "请使用下面<data> </data>中的数据作为本次对话的参考。请直接输出答案,不要提及你是从<data> </data>中获取的知识。\n\n当前时间:{{cTime}}\n\n<data>\n{{response}}\n</data>\n\n我的问题:\"{{q}}\"",
|
||
"editField": {
|
||
"key": true
|
||
},
|
||
"maxLength": "",
|
||
"dynamicParamDefaultValue": {
|
||
"inputType": "reference",
|
||
"valueType": "string",
|
||
"required": true
|
||
}
|
||
}
|
||
],
|
||
"outputs": [
|
||
{
|
||
"id": "text",
|
||
"type": "static",
|
||
"key": "text",
|
||
"valueType": "string",
|
||
"label": "text",
|
||
"description": ""
|
||
}
|
||
],
|
||
"pluginId": "community-textEditor"
|
||
},
|
||
{
|
||
"nodeId": "EX0g9oK3sCOC",
|
||
"name": "AI 对话",
|
||
"intro": "AI 大模型对话",
|
||
"avatar": "/imgs/workflow/AI.png",
|
||
"flowNodeType": "chatNode",
|
||
"showStatus": true,
|
||
"position": {
|
||
"x": 3199.17223136331,
|
||
"y": -100.06379812849427
|
||
},
|
||
"inputs": [
|
||
{
|
||
"key": "model",
|
||
"renderTypeList": [
|
||
"settingLLMModel",
|
||
"reference"
|
||
],
|
||
"label": "core.module.input.label.aiModel",
|
||
"valueType": "string",
|
||
"value": "gpt-3.5-turbo"
|
||
},
|
||
{
|
||
"key": "temperature",
|
||
"renderTypeList": [
|
||
"hidden"
|
||
],
|
||
"label": "",
|
||
"value": 0,
|
||
"valueType": "number",
|
||
"min": 0,
|
||
"max": 10,
|
||
"step": 1
|
||
},
|
||
{
|
||
"key": "maxToken",
|
||
"renderTypeList": [
|
||
"hidden"
|
||
],
|
||
"label": "",
|
||
"value": 2000,
|
||
"valueType": "number",
|
||
"min": 100,
|
||
"max": 4000,
|
||
"step": 50
|
||
},
|
||
{
|
||
"key": "isResponseAnswerText",
|
||
"renderTypeList": [
|
||
"hidden"
|
||
],
|
||
"label": "",
|
||
"value": true,
|
||
"valueType": "boolean"
|
||
},
|
||
{
|
||
"key": "quoteTemplate",
|
||
"renderTypeList": [
|
||
"hidden"
|
||
],
|
||
"label": "",
|
||
"valueType": "string"
|
||
},
|
||
{
|
||
"key": "quotePrompt",
|
||
"renderTypeList": [
|
||
"hidden"
|
||
],
|
||
"label": "",
|
||
"valueType": "string"
|
||
},
|
||
{
|
||
"key": "systemPrompt",
|
||
"renderTypeList": [
|
||
"textarea",
|
||
"reference"
|
||
],
|
||
"max": 3000,
|
||
"valueType": "string",
|
||
"label": "core.ai.Prompt",
|
||
"description": "core.app.tip.chatNodeSystemPromptTip",
|
||
"placeholder": "core.app.tip.chatNodeSystemPromptTip"
|
||
},
|
||
{
|
||
"key": "history",
|
||
"renderTypeList": [
|
||
"numberInput",
|
||
"reference"
|
||
],
|
||
"valueType": "chatHistory",
|
||
"label": "core.module.input.label.chat history",
|
||
"required": true,
|
||
"min": 0,
|
||
"max": 30,
|
||
"value": 6
|
||
},
|
||
{
|
||
"key": "userChatInput",
|
||
"renderTypeList": [
|
||
"reference",
|
||
"textarea"
|
||
],
|
||
"valueType": "string",
|
||
"label": "用户问题",
|
||
"required": true,
|
||
"toolDescription": "用户问题",
|
||
"value": [
|
||
"FYLw1BokYUad",
|
||
"text"
|
||
]
|
||
},
|
||
{
|
||
"key": "quoteQA",
|
||
"renderTypeList": [
|
||
"settingDatasetQuotePrompt"
|
||
],
|
||
"label": "",
|
||
"debugLabel": "知识库引用",
|
||
"description": "",
|
||
"valueType": "datasetQuote"
|
||
}
|
||
],
|
||
"outputs": [
|
||
{
|
||
"id": "history",
|
||
"key": "history",
|
||
"label": "core.module.output.label.New context",
|
||
"description": "core.module.output.description.New context",
|
||
"valueType": "chatHistory",
|
||
"type": "static"
|
||
},
|
||
{
|
||
"id": "answerText",
|
||
"key": "answerText",
|
||
"label": "core.module.output.label.Ai response content",
|
||
"description": "core.module.output.description.Ai response content",
|
||
"valueType": "string",
|
||
"type": "static"
|
||
}
|
||
]
|
||
},
|
||
{
|
||
"nodeId": "lG52GzzMm65z",
|
||
"name": "文本内容提取",
|
||
"intro": "可从文本中提取指定的数据,例如:sql语句、搜索关键词、代码等",
|
||
"avatar": "/imgs/workflow/extract.png",
|
||
"flowNodeType": "contentExtract",
|
||
"showStatus": true,
|
||
"position": {
|
||
"x": 535.331344778598,
|
||
"y": -437.1382636373696
|
||
},
|
||
"inputs": [
|
||
{
|
||
"key": "model",
|
||
"renderTypeList": [
|
||
"selectLLMModel",
|
||
"reference"
|
||
],
|
||
"label": "core.module.input.label.aiModel",
|
||
"required": true,
|
||
"valueType": "string",
|
||
"llmModelType": "extractFields",
|
||
"value": "gpt-3.5-turbo"
|
||
},
|
||
{
|
||
"key": "description",
|
||
"renderTypeList": [
|
||
"textarea",
|
||
"reference"
|
||
],
|
||
"valueType": "string",
|
||
"label": "提取要求描述",
|
||
"description": "给AI一些对应的背景知识或要求描述,引导AI更好的完成任务。\n该输入框可使用全局变量。",
|
||
"placeholder": "例如: \n1. 当前时间为: {{cTime}}。你是一个实验室预约助手,你的任务是帮助用户预约实验室,从文本中获取对应的预约信息。\n2. 你是谷歌搜索助手,需要从文本中提取出合适的搜索词。",
|
||
"value": "你是谷歌搜索机器人,根据当前问题和对话记录生成搜索词。你需要自行判断是否需要进行网络实时查询:\n- 如果需查询则生成搜索词。\n- 如果不需要查询则不返回字段。"
|
||
},
|
||
{
|
||
"key": "history",
|
||
"renderTypeList": [
|
||
"numberInput",
|
||
"reference"
|
||
],
|
||
"valueType": "chatHistory",
|
||
"label": "core.module.input.label.chat history",
|
||
"required": true,
|
||
"min": 0,
|
||
"max": 30,
|
||
"value": 6
|
||
},
|
||
{
|
||
"key": "content",
|
||
"renderTypeList": [
|
||
"reference",
|
||
"textarea"
|
||
],
|
||
"label": "需要提取的文本",
|
||
"required": true,
|
||
"valueType": "string",
|
||
"toolDescription": "需要检索的内容",
|
||
"value": [
|
||
"448745",
|
||
"userChatInput"
|
||
]
|
||
},
|
||
{
|
||
"key": "extractKeys",
|
||
"renderTypeList": [
|
||
"custom"
|
||
],
|
||
"label": "",
|
||
"valueType": "any",
|
||
"description": "由 '描述' 和 'key' 组成一个目标字段,可提取多个目标字段",
|
||
"value": [
|
||
{
|
||
"required": false,
|
||
"defaultValue": "",
|
||
"desc": "搜索词",
|
||
"key": "searchKey",
|
||
"enum": ""
|
||
}
|
||
]
|
||
}
|
||
],
|
||
"outputs": [
|
||
{
|
||
"id": "fields",
|
||
"key": "fields",
|
||
"label": "完整提取结果",
|
||
"description": "一个 JSON 字符串,例如:{\"name:\":\"YY\",\"Time\":\"2023/7/2 18:00\"}",
|
||
"valueType": "string",
|
||
"type": "static"
|
||
},
|
||
{
|
||
"id": "6yF19MRD3nuB",
|
||
"key": "searchKey",
|
||
"label": "提取结果-搜索词",
|
||
"valueType": "string",
|
||
"type": "static"
|
||
}
|
||
]
|
||
}
|
||
],
|
||
"edges": [
|
||
{
|
||
"source": "TWD5BAqIIFaj",
|
||
"target": "Nc6hBdb3l9Pe",
|
||
"sourceHandle": "TWD5BAqIIFaj-source-IF",
|
||
"targetHandle": "Nc6hBdb3l9Pe-target-left"
|
||
},
|
||
{
|
||
"source": "1ljV0oTq4zeC",
|
||
"target": "FYLw1BokYUad",
|
||
"sourceHandle": "1ljV0oTq4zeC-source-right",
|
||
"targetHandle": "FYLw1BokYUad-target-left"
|
||
},
|
||
{
|
||
"source": "FYLw1BokYUad",
|
||
"target": "EX0g9oK3sCOC",
|
||
"sourceHandle": "FYLw1BokYUad-source-right",
|
||
"targetHandle": "EX0g9oK3sCOC-target-left"
|
||
},
|
||
{
|
||
"source": "448745",
|
||
"target": "lG52GzzMm65z",
|
||
"sourceHandle": "448745-source-right",
|
||
"targetHandle": "lG52GzzMm65z-target-left"
|
||
},
|
||
{
|
||
"source": "lG52GzzMm65z",
|
||
"target": "TWD5BAqIIFaj",
|
||
"sourceHandle": "lG52GzzMm65z-source-right",
|
||
"targetHandle": "TWD5BAqIIFaj-target-left"
|
||
},
|
||
{
|
||
"source": "TWD5BAqIIFaj",
|
||
"target": "1ljV0oTq4zeC",
|
||
"sourceHandle": "TWD5BAqIIFaj-source-ELSE",
|
||
"targetHandle": "1ljV0oTq4zeC-target-left"
|
||
}
|
||
]
|
||
}
|
||
```
|
||
|
||
{{% /details %}}
|
||
|
||
|
||
### 流程说明
|
||
|
||
1. 利用【文本内容提取】模块,将用户的问题提取成搜索关键词。
|
||
2. 将搜索关键词传入【HTTP请求】模块,执行谷歌搜索。
|
||
3. 利用【文本加工】模块组合搜索结果和问题,生成一个适合模型回答的问题。
|
||
4. 将新的问题发给【AI对话】模块,回答搜索结果。
|
||
|
||
# 实验室预约
|
||
## 展示高级编排操作数据库的能力
|
||
|
||
| | |
|
||
| --------------------- | --------------------- |
|
||
|  |  |
|
||
|  |  |
|
||
|
||
|
||
|
||
本示例演示了利用工具调用,自动选择调用知识库搜索实验室相关内容,或调用 HTTP 模块实现数据库的 CRUD 操作。
|
||
|
||
以一个实验室预约为例,用户可以通过对话系统预约、取消、修改预约和查询预约记录。
|
||
|
||
## 1. 全局变量使用
|
||
|
||
通过设计一个全局变量,让用户输入姓名,模拟用户身份信息。实际使用过程中,通常是直接通过嵌入 Token 来标记用户身份。
|
||
|
||
## 2. 工具调用
|
||
|
||

|
||
|
||
背景知识中,引导模型调用工具去执行不通的操作。
|
||
|
||
{{% alert icon="🤗" context="warning" %}}
|
||
**Tips:** 这里需要增加适当的上下文,方便模型结合历史纪录进行判断和决策~
|
||
{{% /alert %}}
|
||
|
||
## 3. HTTP 模块
|
||
|
||

|
||
|
||
HTTP模块中,需要设置 3 个工具参数:
|
||
|
||
- 预约行为:可取 get, put, post, delete 四个值,分别对应查询、修改、新增、删除操作。当然,你也可以写4个HTTP模块,来分别处理。
|
||
- labname: 实验室名。非必填,因为查询和删除时候,不需要。
|
||
- time: 预约时间。
|
||
|
||
|
||
# 总结
|
||
|
||
1. 工具调用模块是非常强大的功能,可以在一定程度上替代问题分类和内容提取。
|
||
2. 通过工具模块,动态的调用不同的工具,可以将复杂业务解耦。
|
||
|
||
|
||
# 附件
|
||
|
||
## 编排配置
|
||
|
||
可直接复制,导入到 FastGPT 中。
|
||
|
||
{{% details title="编排配置" closed="true" %}}
|
||
|
||
```json
|
||
{
|
||
"nodes": [
|
||
{
|
||
"nodeId": "userChatInput",
|
||
"name": "流程开始",
|
||
"intro": "当用户发送一个内容后,流程将会从这个模块开始执行。",
|
||
"avatar": "/imgs/workflow/userChatInput.svg",
|
||
"flowNodeType": "workflowStart",
|
||
"position": {
|
||
"x": 309.7143912167367,
|
||
"y": 1501.2761754220846
|
||
},
|
||
"inputs": [
|
||
{
|
||
"key": "userChatInput",
|
||
"renderTypeList": [
|
||
"reference",
|
||
"textarea"
|
||
],
|
||
"valueType": "string",
|
||
"label": "问题输入",
|
||
"required": true,
|
||
"toolDescription": "用户问题",
|
||
"type": "systemInput",
|
||
"showTargetInApp": false,
|
||
"showTargetInPlugin": false,
|
||
"connected": false,
|
||
"selectedTypeIndex": 0,
|
||
"value": [
|
||
"userChatInput",
|
||
"userChatInput"
|
||
]
|
||
}
|
||
],
|
||
"outputs": [
|
||
{
|
||
"id": "userChatInput",
|
||
"type": "static",
|
||
"key": "userChatInput",
|
||
"valueType": "string",
|
||
"label": "core.module.input.label.user question"
|
||
}
|
||
]
|
||
},
|
||
{
|
||
"nodeId": "eg5upi",
|
||
"name": "指定回复",
|
||
"intro": "该模块可以直接回复一段指定的内容。常用于引导、提示。非字符串内容传入时,会转成字符串进行输出。",
|
||
"avatar": "/imgs/workflow/reply.png",
|
||
"flowNodeType": "answerNode",
|
||
"position": {
|
||
"x": 1962.729630445213,
|
||
"y": 2295.9791334948304
|
||
},
|
||
"inputs": [
|
||
{
|
||
"key": "text",
|
||
"renderTypeList": [
|
||
"textarea",
|
||
"reference"
|
||
],
|
||
"valueType": "any",
|
||
"label": "core.module.input.label.Response content",
|
||
"description": "core.module.input.description.Response content",
|
||
"placeholder": "core.module.input.description.Response content",
|
||
"type": "textarea",
|
||
"showTargetInApp": true,
|
||
"showTargetInPlugin": true,
|
||
"connected": true,
|
||
"selectedTypeIndex": 1,
|
||
"value": [
|
||
"40clf3",
|
||
"result"
|
||
]
|
||
}
|
||
],
|
||
"outputs": []
|
||
},
|
||
{
|
||
"nodeId": "kge59i",
|
||
"name": "用户引导",
|
||
"intro": "可以配置应用的系统参数。",
|
||
"avatar": "/imgs/workflow/userGuide.png",
|
||
"flowNodeType": "userGuide",
|
||
"position": {
|
||
"x": -327.218389965887,
|
||
"y": 1504.8056414948464
|
||
},
|
||
"inputs": [
|
||
{
|
||
"key": "welcomeText",
|
||
"renderTypeList": [
|
||
"hidden"
|
||
],
|
||
"valueType": "string",
|
||
"label": "core.app.Welcome Text",
|
||
"type": "hidden",
|
||
"showTargetInApp": false,
|
||
"showTargetInPlugin": false,
|
||
"value": "你好,我是实验室助手,请问有什么可以帮助你的么?如需预约或修改预约实验室,请提供姓名、时间和实验室名称。\n[实验室介绍]\n[开放时间]\n[预约]",
|
||
"connected": false,
|
||
"selectedTypeIndex": 0
|
||
},
|
||
{
|
||
"key": "variables",
|
||
"renderTypeList": [
|
||
"hidden"
|
||
],
|
||
"valueType": "any",
|
||
"label": "core.module.Variable",
|
||
"value": [
|
||
{
|
||
"id": "gt9b23",
|
||
"key": "name",
|
||
"label": "name",
|
||
"type": "input",
|
||
"required": true,
|
||
"maxLen": 50,
|
||
"enums": [
|
||
{
|
||
"value": ""
|
||
}
|
||
]
|
||
}
|
||
],
|
||
"type": "hidden",
|
||
"showTargetInApp": false,
|
||
"showTargetInPlugin": false,
|
||
"connected": false,
|
||
"selectedTypeIndex": 0
|
||
},
|
||
{
|
||
"key": "questionGuide",
|
||
"valueType": "boolean",
|
||
"renderTypeList": [
|
||
"hidden"
|
||
],
|
||
"label": "",
|
||
"type": "switch",
|
||
"showTargetInApp": false,
|
||
"showTargetInPlugin": false,
|
||
"value": false,
|
||
"connected": false,
|
||
"selectedTypeIndex": 0
|
||
},
|
||
{
|
||
"key": "tts",
|
||
"renderTypeList": [
|
||
"hidden"
|
||
],
|
||
"valueType": "any",
|
||
"label": "",
|
||
"type": "hidden",
|
||
"showTargetInApp": false,
|
||
"showTargetInPlugin": false,
|
||
"value": {
|
||
"type": "model",
|
||
"model": "tts-1",
|
||
"voice": "alloy"
|
||
},
|
||
"connected": false,
|
||
"selectedTypeIndex": 0
|
||
},
|
||
{
|
||
"key": "whisper",
|
||
"renderTypeList": [
|
||
"hidden"
|
||
],
|
||
"valueType": "any",
|
||
"label": "",
|
||
"type": "hidden",
|
||
"showTargetInApp": false,
|
||
"showTargetInPlugin": false,
|
||
"connected": false,
|
||
"selectedTypeIndex": 0
|
||
},
|
||
{
|
||
"key": "scheduleTrigger",
|
||
"renderTypeList": [
|
||
"hidden"
|
||
],
|
||
"valueType": "any",
|
||
"label": "",
|
||
"value": null
|
||
}
|
||
],
|
||
"outputs": []
|
||
},
|
||
{
|
||
"nodeId": "40clf3",
|
||
"name": "HTTP请求",
|
||
"intro": "可以发出一个 HTTP 请求,实现更为复杂的操作(联网搜索、数据库查询等)",
|
||
"avatar": "/imgs/workflow/http.png",
|
||
"flowNodeType": "httpRequest468",
|
||
"showStatus": true,
|
||
"position": {
|
||
"x": 1118.6532653446993,
|
||
"y": 1955.886106913907
|
||
},
|
||
"inputs": [
|
||
{
|
||
"key": "system_httpMethod",
|
||
"renderTypeList": [
|
||
"custom"
|
||
],
|
||
"valueType": "string",
|
||
"label": "",
|
||
"value": "POST",
|
||
"required": true,
|
||
"type": "custom",
|
||
"showTargetInApp": false,
|
||
"showTargetInPlugin": false,
|
||
"connected": false,
|
||
"selectedTypeIndex": 0
|
||
},
|
||
{
|
||
"valueType": "string",
|
||
"renderTypeList": [
|
||
"reference"
|
||
],
|
||
"key": "action",
|
||
"label": "action",
|
||
"toolDescription": "预约行为,一共四种:\nget - 查询预约情况\nput - 更新预约\npost - 新增预约\ndelete - 删除预约",
|
||
"required": true,
|
||
"canEdit": true,
|
||
"editField": {
|
||
"key": true,
|
||
"description": true
|
||
}
|
||
},
|
||
{
|
||
"valueType": "string",
|
||
"renderTypeList": [
|
||
"reference"
|
||
],
|
||
"key": "labname",
|
||
"label": "labname",
|
||
"toolDescription": "实验室名称",
|
||
"required": false,
|
||
"canEdit": true,
|
||
"editField": {
|
||
"key": true,
|
||
"description": true
|
||
}
|
||
},
|
||
{
|
||
"valueType": "string",
|
||
"renderTypeList": [
|
||
"reference"
|
||
],
|
||
"key": "time",
|
||
"label": "time",
|
||
"toolDescription": "预约时间,按 YYYY/MM/DD HH:mm 格式返回",
|
||
"required": false,
|
||
"canEdit": true,
|
||
"editField": {
|
||
"key": true,
|
||
"description": true
|
||
}
|
||
},
|
||
{
|
||
"key": "system_httpReqUrl",
|
||
"renderTypeList": [
|
||
"hidden"
|
||
],
|
||
"valueType": "string",
|
||
"label": "",
|
||
"description": "core.module.input.description.Http Request Url",
|
||
"placeholder": "https://api.ai.com/getInventory",
|
||
"required": false,
|
||
"type": "hidden",
|
||
"showTargetInApp": false,
|
||
"showTargetInPlugin": false,
|
||
"value": "https://d8dns0.laf.dev/appointment-lab",
|
||
"connected": false,
|
||
"selectedTypeIndex": 0
|
||
},
|
||
{
|
||
"key": "system_httpHeader",
|
||
"renderTypeList": [
|
||
"custom"
|
||
],
|
||
"valueType": "any",
|
||
"value": [],
|
||
"label": "",
|
||
"description": "core.module.input.description.Http Request Header",
|
||
"placeholder": "core.module.input.description.Http Request Header",
|
||
"required": false,
|
||
"type": "custom",
|
||
"showTargetInApp": false,
|
||
"showTargetInPlugin": false,
|
||
"connected": false,
|
||
"selectedTypeIndex": 0
|
||
},
|
||
{
|
||
"key": "system_httpParams",
|
||
"renderTypeList": [
|
||
"hidden"
|
||
],
|
||
"valueType": "any",
|
||
"value": [],
|
||
"label": "",
|
||
"required": false,
|
||
"type": "hidden",
|
||
"showTargetInApp": false,
|
||
"showTargetInPlugin": false,
|
||
"connected": false,
|
||
"selectedTypeIndex": 0
|
||
},
|
||
{
|
||
"key": "system_httpJsonBody",
|
||
"renderTypeList": [
|
||
"hidden"
|
||
],
|
||
"valueType": "any",
|
||
"value": "{\r\n \"name\": \"{{name}}\",\r\n \"time\": \"{{time}}\",\r\n \"labname\": \"{{labname}}\",\r\n \"action\": \"{{action}}\"\r\n}",
|
||
"label": "",
|
||
"required": false,
|
||
"type": "hidden",
|
||
"showTargetInApp": false,
|
||
"showTargetInPlugin": false,
|
||
"connected": false,
|
||
"selectedTypeIndex": 0
|
||
},
|
||
{
|
||
"key": "system_addInputParam",
|
||
"renderTypeList": [
|
||
"addInputParam"
|
||
],
|
||
"valueType": "dynamic",
|
||
"label": "",
|
||
"required": false,
|
||
"description": "core.module.input.description.HTTP Dynamic Input",
|
||
"editField": {
|
||
"key": true,
|
||
"valueType": true
|
||
}
|
||
}
|
||
],
|
||
"outputs": [
|
||
{
|
||
"id": "system_addOutputParam",
|
||
"type": "dynamic",
|
||
"key": "system_addOutputParam",
|
||
"valueType": "dynamic",
|
||
"label": "",
|
||
"editField": {
|
||
"key": true,
|
||
"valueType": true
|
||
}
|
||
},
|
||
{
|
||
"id": "result",
|
||
"type": "static",
|
||
"key": "result",
|
||
"valueType": "string",
|
||
"label": "result",
|
||
"description": "result",
|
||
"canEdit": true,
|
||
"editField": {
|
||
"key": true,
|
||
"name": true,
|
||
"description": true,
|
||
"dataType": true
|
||
}
|
||
},
|
||
{
|
||
"id": "httpRawResponse",
|
||
"type": "static",
|
||
"key": "httpRawResponse",
|
||
"valueType": "any",
|
||
"label": "原始响应",
|
||
"description": "HTTP请求的原始响应。只能接受字符串或JSON类型响应数据。"
|
||
}
|
||
]
|
||
},
|
||
{
|
||
"nodeId": "fYxwWym8flYL",
|
||
"name": "工具调用",
|
||
"intro": "通过AI模型自动选择一个或多个功能块进行调用,也可以对插件进行调用。",
|
||
"avatar": "/imgs/workflow/tool.svg",
|
||
"flowNodeType": "tools",
|
||
"showStatus": true,
|
||
"position": {
|
||
"x": 933.9342354248961,
|
||
"y": 1229.3563445150553
|
||
},
|
||
"inputs": [
|
||
{
|
||
"key": "model",
|
||
"renderTypeList": [
|
||
"settingLLMModel",
|
||
"reference"
|
||
],
|
||
"label": "core.module.input.label.aiModel",
|
||
"valueType": "string",
|
||
"llmModelType": "all",
|
||
"value": "gpt-3.5-turbo"
|
||
},
|
||
{
|
||
"key": "temperature",
|
||
"renderTypeList": [
|
||
"hidden"
|
||
],
|
||
"label": "",
|
||
"value": 0,
|
||
"valueType": "number",
|
||
"min": 0,
|
||
"max": 10,
|
||
"step": 1
|
||
},
|
||
{
|
||
"key": "maxToken",
|
||
"renderTypeList": [
|
||
"hidden"
|
||
],
|
||
"label": "",
|
||
"value": 2000,
|
||
"valueType": "number",
|
||
"min": 100,
|
||
"max": 4000,
|
||
"step": 50
|
||
},
|
||
{
|
||
"key": "systemPrompt",
|
||
"renderTypeList": [
|
||
"textarea",
|
||
"reference"
|
||
],
|
||
"max": 3000,
|
||
"valueType": "string",
|
||
"label": "core.ai.Prompt",
|
||
"description": "core.app.tip.chatNodeSystemPromptTip",
|
||
"placeholder": "core.app.tip.chatNodeSystemPromptTip",
|
||
"value": "当前时间为: {{cTime}}\n你是实验室助手,用户可能会询问实验室相关介绍或预约实验室。\n请选择合适的工具去帮助他们。"
|
||
},
|
||
{
|
||
"key": "history",
|
||
"renderTypeList": [
|
||
"numberInput",
|
||
"reference"
|
||
],
|
||
"valueType": "chatHistory",
|
||
"label": "core.module.input.label.chat history",
|
||
"required": true,
|
||
"min": 0,
|
||
"max": 30,
|
||
"value": 6
|
||
},
|
||
{
|
||
"key": "userChatInput",
|
||
"renderTypeList": [
|
||
"reference",
|
||
"textarea"
|
||
],
|
||
"valueType": "string",
|
||
"label": "用户问题",
|
||
"required": true,
|
||
"value": [
|
||
"userChatInput",
|
||
"userChatInput"
|
||
]
|
||
}
|
||
],
|
||
"outputs": []
|
||
},
|
||
{
|
||
"nodeId": "JSSQtDgwmmbE",
|
||
"name": "知识库搜索",
|
||
"intro": "调用“语义检索”和“全文检索”能力,从“知识库”中查找实验室介绍和使用规则等信息。",
|
||
"avatar": "/imgs/workflow/db.png",
|
||
"flowNodeType": "datasetSearchNode",
|
||
"showStatus": true,
|
||
"position": {
|
||
"x": 447.0795498711184,
|
||
"y": 1971.5311041711186
|
||
},
|
||
"inputs": [
|
||
{
|
||
"key": "datasets",
|
||
"renderTypeList": [
|
||
"selectDataset",
|
||
"reference"
|
||
],
|
||
"label": "core.module.input.label.Select dataset",
|
||
"value": [],
|
||
"valueType": "selectDataset",
|
||
"list": [],
|
||
"required": true
|
||
},
|
||
{
|
||
"key": "similarity",
|
||
"renderTypeList": [
|
||
"selectDatasetParamsModal"
|
||
],
|
||
"label": "",
|
||
"value": 0.4,
|
||
"valueType": "number"
|
||
},
|
||
{
|
||
"key": "limit",
|
||
"renderTypeList": [
|
||
"hidden"
|
||
],
|
||
"label": "",
|
||
"value": 1500,
|
||
"valueType": "number"
|
||
},
|
||
{
|
||
"key": "searchMode",
|
||
"renderTypeList": [
|
||
"hidden"
|
||
],
|
||
"label": "",
|
||
"valueType": "string",
|
||
"value": "embedding"
|
||
},
|
||
{
|
||
"key": "usingReRank",
|
||
"renderTypeList": [
|
||
"hidden"
|
||
],
|
||
"label": "",
|
||
"valueType": "boolean",
|
||
"value": false
|
||
},
|
||
{
|
||
"key": "datasetSearchUsingExtensionQuery",
|
||
"renderTypeList": [
|
||
"hidden"
|
||
],
|
||
"label": "",
|
||
"valueType": "boolean",
|
||
"value": false
|
||
},
|
||
{
|
||
"key": "datasetSearchExtensionModel",
|
||
"renderTypeList": [
|
||
"hidden"
|
||
],
|
||
"label": "",
|
||
"valueType": "string",
|
||
"value": "gpt-3.5-turbo"
|
||
},
|
||
{
|
||
"key": "datasetSearchExtensionBg",
|
||
"renderTypeList": [
|
||
"hidden"
|
||
],
|
||
"label": "",
|
||
"valueType": "string",
|
||
"value": ""
|
||
},
|
||
{
|
||
"key": "userChatInput",
|
||
"renderTypeList": [
|
||
"reference",
|
||
"textarea"
|
||
],
|
||
"valueType": "string",
|
||
"label": "用户问题",
|
||
"required": true,
|
||
"toolDescription": "需要检索的内容"
|
||
}
|
||
],
|
||
"outputs": [
|
||
{
|
||
"id": "quoteQA",
|
||
"key": "quoteQA",
|
||
"label": "core.module.Dataset quote.label",
|
||
"description": "特殊数组格式,搜索结果为空时,返回空数组。",
|
||
"type": "static",
|
||
"valueType": "datasetQuote"
|
||
}
|
||
]
|
||
},
|
||
{
|
||
"nodeId": "IdntVQiTopHT",
|
||
"name": "工具调用终止",
|
||
"intro": "该模块需配置工具调用使用。当该模块被执行时,本次工具调用将会强制结束,并且不再调用AI针对工具调用结果回答问题。",
|
||
"avatar": "/imgs/workflow/toolStop.svg",
|
||
"flowNodeType": "stopTool",
|
||
"position": {
|
||
"x": 1969.73331750207,
|
||
"y": 2650.0258908119413
|
||
},
|
||
"inputs": [],
|
||
"outputs": []
|
||
}
|
||
],
|
||
"edges": [
|
||
{
|
||
"source": "40clf3",
|
||
"target": "eg5upi",
|
||
"sourceHandle": "40clf3-source-right",
|
||
"targetHandle": "eg5upi-target-left"
|
||
},
|
||
{
|
||
"source": "userChatInput",
|
||
"target": "fYxwWym8flYL",
|
||
"sourceHandle": "userChatInput-source-right",
|
||
"targetHandle": "fYxwWym8flYL-target-left"
|
||
},
|
||
{
|
||
"source": "fYxwWym8flYL",
|
||
"target": "40clf3",
|
||
"sourceHandle": "selectedTools",
|
||
"targetHandle": "selectedTools"
|
||
},
|
||
{
|
||
"source": "fYxwWym8flYL",
|
||
"target": "JSSQtDgwmmbE",
|
||
"sourceHandle": "selectedTools",
|
||
"targetHandle": "selectedTools"
|
||
},
|
||
{
|
||
"source": "40clf3",
|
||
"target": "IdntVQiTopHT",
|
||
"sourceHandle": "40clf3-source-right",
|
||
"targetHandle": "IdntVQiTopHT-target-left"
|
||
}
|
||
]
|
||
}
|
||
```
|
||
|
||
{{% /details %}}
|
||
|
||
## Laf 云函数代码
|
||
|
||
可以在 [Laf](https://laf.dev/) 中快速构建 HTTP 接口。
|
||
|
||
{{% details title="函数代码" closed="true" %}}
|
||
|
||
```ts
|
||
import cloud from '@lafjs/cloud'
|
||
const db = cloud.database()
|
||
|
||
type RequestType = {
|
||
name: string;
|
||
time?: string;
|
||
labname?: string;
|
||
action: 'post' | 'delete' | 'put' | 'get'
|
||
}
|
||
|
||
export default async function (ctx: FunctionContext) {
|
||
try {
|
||
const { action,...body } = ctx.body as RequestType
|
||
|
||
if (action === 'get') {
|
||
return await getRecord(ctx.body)
|
||
}
|
||
if (action === 'post') {
|
||
return await createRecord(ctx.body)
|
||
}
|
||
if (action === 'put') {
|
||
return await putRecord(ctx.body)
|
||
}
|
||
if (action === 'delete') {
|
||
return await removeRecord(ctx.body)
|
||
}
|
||
|
||
|
||
return {
|
||
result: "异常"
|
||
}
|
||
} catch (err) {
|
||
return {
|
||
result: "异常"
|
||
}
|
||
}
|
||
}
|
||
|
||
async function putRecord({ name, time, labname }: RequestType) {
|
||
const missData = []
|
||
if (!name) missData.push("你的姓名")
|
||
|
||
if (missData.length > 0) {
|
||
return {
|
||
result: `请提供: ${missData.join("、")}`
|
||
}
|
||
}
|
||
|
||
const { data: record } = await db.collection("LabAppointment").where({
|
||
name, status: "unStart"
|
||
}).getOne()
|
||
|
||
if (!record) {
|
||
return {
|
||
result: `${name} 还没有预约记录`
|
||
}
|
||
}
|
||
|
||
const updateWhere = {
|
||
name,
|
||
time: time || record.time,
|
||
labname: labname || record.labname
|
||
}
|
||
|
||
await db.collection("LabAppointment").where({
|
||
name, status: "unStart"
|
||
}).update(updateWhere)
|
||
|
||
return {
|
||
result: `修改预约成功。
|
||
姓名:${name}·
|
||
时间: ${updateWhere.time}
|
||
实验室名: ${updateWhere.labname}
|
||
` }
|
||
}
|
||
|
||
|
||
async function getRecord({ name }: RequestType) {
|
||
if (!name) {
|
||
return {
|
||
result: "请提供你的姓名"
|
||
}
|
||
}
|
||
const { data } = await db.collection('LabAppointment').where({ name, status: "unStart" }).getOne()
|
||
|
||
if (!data) {
|
||
return {
|
||
result: `${name} 没有预约中的记录`
|
||
}
|
||
}
|
||
return {
|
||
result: `${name} 有一条预约记录:
|
||
姓名:${data.name}
|
||
时间: ${data.time}
|
||
实验室名: ${data.labname}
|
||
`
|
||
}
|
||
}
|
||
|
||
async function removeRecord({ name }: RequestType) {
|
||
if (!name) {
|
||
return {
|
||
result: "请提供你的姓名"
|
||
}
|
||
}
|
||
const { deleted } = await db.collection('LabAppointment').where({ name, status: "unStart" }).remove()
|
||
|
||
if (deleted > 0) {
|
||
return {
|
||
result: `取消预约记录成功: ${name}`
|
||
}
|
||
}
|
||
return {
|
||
result: ` ${name} 没有预约中的记录`
|
||
}
|
||
}
|
||
|
||
async function createRecord({ name, time, labname }: RequestType) {
|
||
const missData = []
|
||
if (!name) missData.push("你的姓名")
|
||
if (!time) missData.push("需要预约的时间")
|
||
if (!labname) missData.push("实验室名名称")
|
||
|
||
if (missData.length > 0) {
|
||
return {
|
||
result: `请提供: ${missData.join("、")}`
|
||
}
|
||
}
|
||
|
||
const { data: record } = await db.collection("LabAppointment").where({
|
||
name, status: "unStart"
|
||
}).getOne()
|
||
|
||
if (record) {
|
||
return {
|
||
result: `您已经有一个预约记录了:
|
||
姓名:${record.name}
|
||
时间: ${record.time}
|
||
实验室名: ${record.labname}
|
||
|
||
每人仅能同时预约一个实验室名。
|
||
`
|
||
}
|
||
}
|
||
|
||
await db.collection("LabAppointment").add({
|
||
name, time, labname, status: "unStart"
|
||
})
|
||
|
||
return {
|
||
result: `预约成功。
|
||
姓名:${name}
|
||
时间: ${time}
|
||
实验室名: ${labname}
|
||
` }
|
||
}
|
||
```
|
||
|
||
{{% /details %}}
|
||
|
||
# 多轮翻译机器人
|
||
## 如何使用 FastGPT 构建一个多轮翻译机器人,实现连续的对话翻译功能
|
||
|
||
吴恩达老师提出了一种反思翻译的大语言模型(LLM)翻译工作流程——[GitHub - andrewyng/translation-agent](https://github.com/andrewyng/translation-agent),具体工作流程如下:
|
||
|
||
1. 提示一个 LLM 将文本从 `source_language` 翻译到 `target_language`;
|
||
2. 让 LLM 反思翻译结果并提出建设性的改进建议;
|
||
3. 使用这些建议来改进翻译。
|
||
|
||
这个翻译流程应该是目前比较新的一种翻译方式,利用 LLM 对自己的翻译结果进行改进来获得较好的翻译效果
|
||
|
||
项目中展示了可以利用对长文本进行分片,然后分别进行反思翻译处理,以突破 LLM 对 tokens 数量的限制,真正实现长文本一键高效率高质量翻译。
|
||
|
||
项目还通过给大模型限定国家地区,已实现更精确的翻译,如美式英语、英式英语之分;同时提出一些可能能带来更好效果的优化,如对于一些 LLM 未曾训练到的术语(或有多种翻译方式的术语)建立术语表,进一步提升翻译的精确度等等
|
||
|
||
而这一切都能通过 Fastgpt 工作流轻松实现,本文将手把手教你如何复刻吴恩达老师的 translation-agent
|
||
|
||
# 单文本块反思翻译
|
||
|
||
先从简单的开始,即不超出 LLM tokens 数量限制的单文本块翻译
|
||
|
||
## 初始翻译
|
||
|
||
第一步先让 LLM 对源文本块进行初始翻译(翻译的提示词在源项目中都有)
|
||
|
||

|
||
|
||
通过`文本拼接`模块引用 源语言、目标语言、源文本这三个参数,生成提示词,传给 LLM,让它给出第一版的翻译
|
||
|
||
## 反思
|
||
|
||
然后让 LLM 对第一步生成的初始翻译给出修改建议,称之为 反思
|
||
|
||

|
||
|
||
这时的提示词接收 5 个参数,源文本、初始翻译、源语言、目标语言 以及限定词地区国家,这样 LLM 会对前面生成的翻译提出相当多的修改建议,为后续的提升翻译作准备
|
||
|
||
## 提升翻译
|
||
|
||

|
||
|
||
在前文生成了初始翻译以及相应的反思后,将这二者输入给第三次 LLM 翻译,这样我们就能获得一个比较高质量的翻译结果
|
||
|
||
完整的工作流如下
|
||
|
||

|
||
|
||
## 运行效果
|
||
|
||
由于考虑之后对这个反思翻译的复用,所以创建了一个插件,那么在下面我直接调用这个插件就能使用反思翻译,效果如下
|
||
|
||
随机挑选了一段哈利波特的文段
|
||
|
||

|
||
|
||

|
||
|
||
可以看到反思翻译后的效果还是好上不少的,其中反思的输出如下
|
||
|
||

|
||
|
||
# 长文反思翻译
|
||
|
||
在掌握了对短文本块的反思翻译后,我们能轻松的通过分片和循环,实现对长文本也即多文本块的反思翻译
|
||
|
||
整体的逻辑是,首先对传入文本的 tokens数量做判断,如果不超过设置的 tokens 限制,那么直接调用单文本块反思翻译,如果超过设置的 tokens限制,那么切割为合理的大小,再分别进行对应的反思翻译处理
|
||
|
||
## 计算 tokens
|
||
|
||

|
||
|
||
首先,我使用了 Laf函数 模块来实现对输入文本的 tokens 的计算
|
||
|
||
laf函数的使用相当简单,即开即用,只需要在 laf 创建个应用,然后安装 tiktoken 依赖,导入如下代码即可
|
||
|
||
```TypeScript
|
||
const { Tiktoken } = require("tiktoken/lite");
|
||
const cl100k_base = require("tiktoken/encoders/cl100k_base.json");
|
||
|
||
interface IRequestBody {
|
||
str: string
|
||
}
|
||
|
||
interface RequestProps extends IRequestBody {
|
||
systemParams: {
|
||
appId: string,
|
||
variables: string,
|
||
histories: string,
|
||
cTime: string,
|
||
chatId: string,
|
||
responseChatItemId: string
|
||
}
|
||
}
|
||
|
||
interface IResponse {
|
||
message: string;
|
||
tokens: number;
|
||
}
|
||
|
||
export default async function (ctx: FunctionContext): Promise<IResponse> {
|
||
const { str = "" }: RequestProps = ctx.body
|
||
|
||
const encoding = new Tiktoken(
|
||
cl100k_base.bpe_ranks,
|
||
cl100k_base.special_tokens,
|
||
cl100k_base.pat_str
|
||
);
|
||
const tokens = encoding.encode(str);
|
||
encoding.free();
|
||
|
||
return {
|
||
message: 'ok',
|
||
tokens: tokens.length
|
||
};
|
||
}
|
||
```
|
||
|
||
再回到 Fastgpt,点击“同步参数”,再连线将源文本传入,即可计算 tokens 数量
|
||
|
||
## 计算单文本块大小
|
||
|
||

|
||
|
||
由于不涉及第三方包,只是一些数据处理,所以直接使用 代码运行 模块处理即可
|
||
|
||
```TypeScript
|
||
function main({tokenCount, tokenLimit}){
|
||
const numChunks = Math.ceil(tokenCount / tokenLimit);
|
||
let chunkSize = Math.floor(tokenCount / numChunks);
|
||
|
||
const remainingTokens = tokenCount % tokenLimit;
|
||
if (remainingTokens > 0) {
|
||
chunkSize += Math.floor(remainingTokens / numChunks);
|
||
}
|
||
|
||
return {chunkSize};
|
||
}
|
||
```
|
||
|
||
通过上面的代码,我们就能算出不超过 token限制的合理单文本块大小是多少了
|
||
|
||
## 获得切分后源文本块
|
||
|
||

|
||
|
||
通过单文本块大小和源文本,我们再编写一个函数调用 langchain 的 textsplitters 包来实现文本分片,具体代码如下
|
||
|
||
```TypeScript
|
||
import cloud from '@lafjs/cloud'
|
||
import { TokenTextSplitter } from "@langchain/textsplitters";
|
||
|
||
interface IRequestBody {
|
||
text: string
|
||
chunkSize: number
|
||
}
|
||
|
||
interface RequestProps extends IRequestBody {
|
||
systemParams: {
|
||
appId: string,
|
||
variables: string,
|
||
histories: string,
|
||
cTime: string,
|
||
chatId: string,
|
||
responseChatItemId: string
|
||
}
|
||
}
|
||
|
||
interface IResponse {
|
||
output: string[];
|
||
}
|
||
|
||
export default async function (ctx: FunctionContext): Promise<IResponse>{
|
||
const { text = '', chunkSize=1000 }: RequestProps = ctx.body;
|
||
|
||
const splitter = new TokenTextSplitter({
|
||
encodingName:"gpt2",
|
||
chunkSize: Number(chunkSize),
|
||
chunkOverlap: 0,
|
||
});
|
||
|
||
const output = await splitter.splitText(text);
|
||
|
||
return {
|
||
output
|
||
}
|
||
}
|
||
```
|
||
|
||
这样我们就获得了切分好的文本,接下去的操作就类似单文本块反思翻译
|
||
|
||
## 多文本块翻译
|
||
|
||
这里应该还是不能直接调用前面的单文本块反思翻译,因为提示词中会涉及一些上下文的处理(或者可以修改下前面写好的插件,多传点参数进去)
|
||
|
||
详细的和前面类似,就是提示词进行一些替换,以及需要做一些很简单的数据处理,整体效果如下
|
||
|
||
### 多文本块初始翻译
|
||
|
||

|
||
|
||
### 多文本块反思
|
||
|
||

|
||
|
||
### 多文本块提升翻译
|
||
|
||

|
||
|
||
## 批量运行
|
||
|
||
长文反思翻译比较关键的一个部分,就是对多个文本块进行循环反思翻译
|
||
|
||
Fastgpt 提供了工作流线路可以返回去执行的功能,所以我们可以写一个很简单的判断函数,来判断结束或是接着执行
|
||
|
||

|
||
|
||
也就是通过判断当前处理的这个文本块,是否是最后一个文本块,从而判断是否需要继续执行,就这样,我们实现了长文反思翻译的效果
|
||
|
||
完整工作流如下
|
||
|
||

|
||
|
||
## 运行效果
|
||
|
||
首先输入全局设置
|
||
|
||

|
||
|
||
然后输入需要翻译的文本,这里我选择了一章哈利波特的英文原文来做翻译,其文本长度通过 openai 对 tokens 数量的判断如下
|
||
|
||

|
||
|
||
实际运行效果如下
|
||
|
||

|
||
|
||
可以看到还是能满足阅读需求的
|
||
|
||
# 进一步调优
|
||
|
||
## 提示词调优
|
||
|
||
在源项目中,给 AI 的系统提示词还是比较的简略的,我们可以通过比较完善的提示词,来督促 LLM 返回更合适的翻译,进一步提升翻译的质量
|
||
|
||
比如初始翻译中,
|
||
|
||
```TypeScript
|
||
# Role: 资深翻译专家
|
||
|
||
## Background:
|
||
你是一位经验丰富的翻译专家,精通{{source_lang}}和{{target_lang}}互译,尤其擅长将{{source_lang}}文章译成流畅易懂的{{target_lang}}。你曾多次带领团队完成大型翻译项目,译文广受好评。
|
||
|
||
## Attention:
|
||
- 翻译过程中要始终坚持"信、达、雅"的原则,但"达"尤为重要
|
||
- 译文要符合{{target_lang}}的表达习惯,通俗易懂,连贯流畅
|
||
- 避免使用过于文绉绉的表达和晦涩难懂的典故引用
|
||
|
||
## Constraints:
|
||
- 必须严格遵循四轮翻译流程:直译、意译、校审、定稿
|
||
- 译文要忠实原文,准确无误,不能遗漏或曲解原意
|
||
|
||
## Goals:
|
||
- 通过四轮翻译流程,将{{source_lang}}原文译成高质量的{{target_lang}}译文
|
||
- 译文要准确传达原文意思,语言表达力求浅显易懂,朗朗上口
|
||
- 适度使用一些熟语俗语、流行网络用语等,增强译文的亲和力
|
||
- 在直译的基础上,提供至少2个不同风格的意译版本供选择
|
||
|
||
## Skills:
|
||
- 精通{{source_lang}} {{target_lang}}两种语言,具有扎实的语言功底和丰富的翻译经验
|
||
- 擅长将{{source_lang}}表达习惯转换为地道自然的{{target_lang}}
|
||
- 对当代{{target_lang}}语言的发展变化有敏锐洞察,善于把握语言流行趋势
|
||
|
||
## Workflow:
|
||
1. 第一轮直译:逐字逐句忠实原文,不遗漏任何信息
|
||
2. 第二轮意译:在直译的基础上用通俗流畅的{{target_lang}}意译原文,至少提供2个不同风格的版本
|
||
3. 第三轮校审:仔细审视译文,消除偏差和欠缺,使译文更加地道易懂
|
||
4. 第四轮定稿:择优选取,反复修改润色,最终定稿出一个简洁畅达、符合大众阅读习惯的译文
|
||
|
||
## OutputFormat:
|
||
- 只需要输出第四轮定稿的回答
|
||
|
||
## Suggestions:
|
||
- 直译时力求忠实原文,但不要过于拘泥逐字逐句
|
||
- 意译时在准确表达原意的基础上,用最朴实无华的{{target_lang}}来表达
|
||
- 校审环节重点关注译文是否符合{{target_lang}}表达习惯,是否通俗易懂
|
||
- 定稿时适度采用一些熟语谚语、网络流行语等,使译文更接地气- 善于利用{{target_lang}}的灵活性,用不同的表述方式展现同一内容,提高译文的可读性
|
||
```
|
||
|
||
从而返回更准确更高质量的初始翻译,后续的反思和提升翻译也可以修改更准确的提示词,如下
|
||
|
||

|
||
|
||
然后再让我们来看看运行效果
|
||
|
||

|
||
|
||
给了和之前相同的一段文本进行测试,测试效果还是比较显著的,就比如红框部分,之前的翻译如下
|
||
|
||

|
||
|
||
从“让你的猫头鹰给我写信”这样有失偏颇的翻译,变成“给我写信,你的猫头鹰会知道怎么找到我”这样较为准确的翻译
|
||
|
||
## 其他调优
|
||
|
||
比如限定词调优,源项目中已经做了示范,就是加上国家地区这个限定词,实测确实会有不少提升
|
||
|
||
出于 LLM 的卓越能力,我们能够通过设置不同的prompt来获取不同的翻译结果,也就是可以很轻松地通过设置特殊的限定词,来实现特定的,更精确的翻译
|
||
|
||
而对于一些超出 LLM 理解的术语等,也可以利用 Fastgpt 的知识库功能进行相应扩展,进一步完善翻译机器人的功能
|
||
|
||
# 如何提交应用模板
|
||
## 指南:如何向 FastGPT 提交应用模板
|
||
|
||
## 什么模板可以合并
|
||
|
||
目前合并进仓库的应用模板,会在「模板市场」中全部展示给用户。
|
||
|
||
为了控制模板的质量以及避免数量过多带来的繁琐,并不是所有的模板都会被合并到开源仓库中,你可以提前 PR 与我们沟通模板的内容。
|
||
|
||
预估最后总体的数量不会很多,控制在 50 个左右,一半来自 FastGPT Team,一半来自社区用户。
|
||
|
||
## 如何写一个应用模板
|
||
|
||
1. ### 跑通 FastGPT dev 环境
|
||
|
||
需要在 dev 环境下执行下面的操作。
|
||
|
||
> 可参照 [FastGPT|快速开始本地开发](https://doc.fastgpt.in/docs/development/intro/)
|
||
|
||
1. ### 在 FastGPT 工作台中,创建一个应用
|
||
|
||
创建空白工作流即可。
|
||
|
||

|
||
|
||
1. ### 创建应用模板
|
||
|
||
应用模板配置以及相关资源,都会在 **packages/templates/src** 目录下。
|
||
|
||

|
||
|
||
1. 在**packages/templates/src** 目录下,创建一个文件夹,名称为模板对应的 id。
|
||
2. 在刚刚创建的文件夹中,再创建一个 **template.json** 文件,复制粘贴并填写如下配置:
|
||
|
||
```JSON
|
||
{
|
||
"name": "模板名",
|
||
"intro": "模板描述,会展示在模板市场的展示页",
|
||
"author": "填写你的名字",
|
||
"avatar": "模板头像,可以将图片文件放在同一个文件夹中,然后填写相应路径",
|
||
|
||
"tags": ["模板标签"], // writing(文本创作),image-generation(图片生成),web-search(联网搜索),
|
||
// roleplay(角色扮演), office-services(办公服务) 暂时分为 5 类,从中选择相应的标签
|
||
|
||
"type": "模板类别", // simple(简易应用), advanced(工作流), plugin(插件)
|
||
|
||
"workflow": { // 这个对象先不管,待会直接粘贴导出的工作流即可
|
||
"nodes": [],
|
||
"edges": [],
|
||
"chatConfig": {}
|
||
}
|
||
}
|
||
```
|
||
|
||
1. ### 完成应用编排并测试
|
||
|
||
完成应用编排后,可以点击右上角的发布。
|
||
|
||
1. ### 复制配置到 template.json
|
||
|
||
鼠标放置在左上角应用的头像和名称上,会出现对于下拉框操作,可以导出工作流配置。
|
||
|
||
导出的配置,会自动复制到剪切板,可以直接到 template.json 文件中粘贴使用,替换步骤 2 中,**workflow** 的值。
|
||
|
||

|
||
|
||
1. ### 验证模板是否加载成功
|
||
|
||
刷新页面,打开模板市场,看其是否成功加载,并点击「使用」测试其功能。
|
||
|
||

|
||
|
||
1. ### 提交 PR
|
||
|
||
如果你觉得你的模板需要提交到开源仓库,可以通过 PR 形式向我们提交。
|
||
|
||
- 写清楚模板的介绍和功能
|
||
- 配上模板运行的效果图
|
||
- 模板参数填写说明,需要在 PR 中写清楚。例如,有些模板需要去某个提供商申请 key,需要附上对应的地址和教程,后续我们会加入到文档中。
|
||
|
||
# 长字幕翻译
|
||
## 利用 AI 自我反思提升翻译质量,同时循环迭代执行 AI 工作流来突破 LLM tokens 限制,实现一个高效的长字幕翻译机器人。
|
||
|
||
直接使用 LLM 来翻译长字幕会遇到很多难点,这些难点也正是直接使用 AI 无法有效处理的问题:
|
||
|
||
1. **Tokens 限制**:这是最明显的障碍。大语言模型 (LLM) 通常有输出 tokens 的限制,这意味着**对于长文本,如果不使用特殊的工作流,可能需要手动将文本分段,逐段输入 AI 进行翻译,然后再手动拼接结果**。这个过程不仅繁琐,还容易出错。
|
||
|
||
2. **字幕格式的保持**:对于字幕来说,时间轴信息至关重要。然而,AI 模型有时会产生 “幻觉”,即无中生有地修改或生成不存在的信息。在字幕翻译中,这可能导致 AI 错误地修改时间轴,使字幕与音频不同步。
|
||
|
||
3. **翻译质量**:简单的机器翻译往往无法满足观众的需求。即使是大语言模型,单轮翻译的质量也常常不尽如人意。对于字幕来说,翻译质量直接影响观看体验,糟糕的翻译会严重影响观众的沉浸感。
|
||
|
||
本案例将展示如何利用 FastGPT 工作流代码结合 LLM 来有效解决这些问题。我们的方法不仅能克服技术限制,还能显著提升翻译质量。
|
||
|
||
## 提取字幕信息
|
||
|
||
工作流的一大优势在于可以结合额外的操作,使 AI 能更精准地处理信息。在字幕翻译中,我们可以**先分离 SRT 字幕文件的各个组成部分,然后只让 LLM 翻译文本部分**。这种方法既节约了 token 使用,又确保了时间轴信息不被误改。
|
||
|
||
具体实现如下:
|
||
|
||
1. 使用代码执行模块,对输入的原始字幕文本进行解析。
|
||
2. 将字幕信息分类为三部分:时间信息、序号信息和文本信息。
|
||
3. 只保留文本信息用于后续的 AI 翻译。
|
||
|
||

|
||
|
||
这种预处理步骤大大提高了整个翻译过程的效率和准确性。
|
||
|
||
## 切分文本
|
||
|
||
为了进一步优化翻译过程,我们需要将提取出的文本信息重新组织。这一步的目的是**将文本分割成适合 LLM 处理的大小,同时保持上下文的连贯性**。
|
||
|
||
在本例中,我们采用以下策略:
|
||
|
||
1. 将文本按照每 40 句为一组进行切分。这个数字是经过多次测试后得出的平衡点,既能保证翻译质量,又不会超出 LLM 的处理能力。
|
||
2. 使用 <T> 标签分割每句文本。这种标记方法便于后续的重新组装,同时也为 AI 模型提供了清晰的句子边界。
|
||
|
||

|
||
|
||
这种切分方法既考虑了 AI 模型的能力限制,又保证了翻译的连贯性。通过保持适当的上下文,我们可以得到更加准确和自然的翻译结果。
|
||
|
||
## 格式化原文本
|
||
|
||
在这一步,我们构建了最终输入给 LLM 的原文本。这个步骤的关键在于如何在控制 tokens 数量的同时,为 AI 提供足够的上下文信息。我们采用了以下策略:
|
||
|
||
1. **传入所有文本作为背景上下文。这确保 AI 能理解整段对话的语境**。
|
||
2. 使用<TRANSLATE_THIS>标签明确指出当前需要翻译的片段。这种方法既能控制 AI 的输出范围,又不会丢失整体语境。
|
||
|
||

|
||
|
||
这种格式化方法使得 AI 能在理解全局的基础上,专注于翻译特定部分,从而提高翻译的准确性和连贯性。
|
||
|
||
## LLM 翻译
|
||
|
||
这是整个过程中最关键的一步。我们利用 LLM 的强大能力来实现高质量翻译。在这一步中,我们将之前提到的 “初始翻译 -> 反思 -> 提升翻译” 的过程整合到了同一个提示词中。
|
||
|
||
这个过程包括以下几个阶段:
|
||
|
||
1. 第一轮直译:要求 AI 严格按照 <T> 标签逐句翻译,保证准确性。
|
||
|
||

|
||
|
||
2. 第二轮意译:允许 AI 自主发挥,对第一轮的结果进行修改和优化。
|
||
|
||
3. 第三轮反思:AI 对自己的翻译进行评价,从多个角度提出改进建议。
|
||
|
||

|
||
|
||
4. 最后一轮修改:根据反思阶段的建议,AI 对翻译进行最后的调整和优化。
|
||
|
||

|
||
|
||
这种多轮翻译和反思的方法显著提高了翻译质量。它不仅能捕捉原文的准确含义,还能使翻译更加流畅自然。
|
||
|
||
值得注意的是,这种方法的效果与直接分步执行相当,但工作流更加简洁高效。
|
||
|
||
## 整合字幕
|
||
|
||
完成翻译后,我们需要将所有信息重新组合成完整的字幕文件。这一步骤包括:
|
||
|
||
1. 整合之前分离的序号信息和时间信息。
|
||
2. 将翻译好的文本与原文本对应。
|
||
3. 使用代码执行模块自动完成组装过程。
|
||
|
||

|
||
|
||
这个过程不仅提高了效率,还最大限度地减少了人为错误的可能性。
|
||
|
||
## 批量运行
|
||
|
||
为了处理整个长字幕文件,我们需要一个批量运行机制。这是通过一个简单但有效的判断模块实现的:
|
||
|
||
1. 检查当前翻译的文本块是否为最后一个。
|
||
2. 如果不是,则将工作流重定向到格式化原文本块节点。
|
||
3. 取出下一段需要翻译的文本,重新开始翻译和拼接过程。
|
||
|
||

|
||
|
||
这种循环机制确保了整个长字幕文件能被完整处理,无论字幕有多长。
|
||
|
||
## 实际应用示例
|
||
|
||
为了验证这个方法的有效性,我们选取了一段《权力的游戏》的英文字幕,将其翻译成简体中文。可以看出我们的方法不仅能准确翻译内容,还能保持字幕的格式和时间轴信息。
|
||
|
||

|
||
|
||
|
||
## 附件
|
||
|
||
本工作流完整配置如下,可直接复制,导入到 FastGPT 中。
|
||
|
||
{{% details title="工作流编排配置" closed="true" %}}
|
||
|
||
```json
|
||
{
|
||
"nodes": [
|
||
{
|
||
"nodeId": "userGuide",
|
||
"name": "系统配置",
|
||
"intro": "可以配置应用的系统参数",
|
||
"avatar": "core/workflow/template/systemConfig",
|
||
"flowNodeType": "userGuide",
|
||
"position": {
|
||
"x": -1453.0815298642474,
|
||
"y": 269.10239463914263
|
||
},
|
||
"version": "481",
|
||
"inputs": [
|
||
{
|
||
"key": "welcomeText",
|
||
"renderTypeList": [
|
||
"hidden"
|
||
],
|
||
"valueType": "string",
|
||
"label": "core.app.Welcome Text",
|
||
"value": ""
|
||
},
|
||
{
|
||
"key": "variables",
|
||
"renderTypeList": [
|
||
"hidden"
|
||
],
|
||
"valueType": "any",
|
||
"label": "core.app.Chat Variable",
|
||
"value": []
|
||
},
|
||
{
|
||
"key": "questionGuide",
|
||
"valueType": "boolean",
|
||
"renderTypeList": [
|
||
"hidden"
|
||
],
|
||
"label": "core.app.Question Guide",
|
||
"value": false
|
||
},
|
||
{
|
||
"key": "tts",
|
||
"renderTypeList": [
|
||
"hidden"
|
||
],
|
||
"valueType": "any",
|
||
"label": "",
|
||
"value": {
|
||
"type": "web"
|
||
}
|
||
},
|
||
{
|
||
"key": "whisper",
|
||
"renderTypeList": [
|
||
"hidden"
|
||
],
|
||
"valueType": "any",
|
||
"label": "",
|
||
"value": {
|
||
"open": false,
|
||
"autoSend": false,
|
||
"autoTTSResponse": false
|
||
}
|
||
},
|
||
{
|
||
"key": "scheduleTrigger",
|
||
"renderTypeList": [
|
||
"hidden"
|
||
],
|
||
"valueType": "any",
|
||
"label": "",
|
||
"value": null
|
||
}
|
||
],
|
||
"outputs": []
|
||
},
|
||
{
|
||
"nodeId": "448745",
|
||
"name": "流程开始",
|
||
"intro": "",
|
||
"avatar": "core/workflow/template/workflowStart",
|
||
"flowNodeType": "workflowStart",
|
||
"position": {
|
||
"x": -1458.2511936623089,
|
||
"y": 1218.2790943636066
|
||
},
|
||
"version": "481",
|
||
"inputs": [
|
||
{
|
||
"key": "userChatInput",
|
||
"renderTypeList": [
|
||
"reference",
|
||
"textarea"
|
||
],
|
||
"valueType": "string",
|
||
"label": "用户问题",
|
||
"required": true,
|
||
"toolDescription": "用户问题"
|
||
}
|
||
],
|
||
"outputs": [
|
||
{
|
||
"id": "userChatInput",
|
||
"key": "userChatInput",
|
||
"label": "core.module.input.label.user question",
|
||
"type": "static",
|
||
"valueType": "string"
|
||
}
|
||
]
|
||
},
|
||
{
|
||
"nodeId": "yjFO3YcM7KG2",
|
||
"name": "LLM 翻译",
|
||
"intro": "AI 大模型对话",
|
||
"avatar": "core/workflow/template/aiChat",
|
||
"flowNodeType": "chatNode",
|
||
"showStatus": true,
|
||
"position": {
|
||
"x": 2569.420973631976,
|
||
"y": 909.4127366971411
|
||
},
|
||
"version": "481",
|
||
"inputs": [
|
||
{
|
||
"key": "model",
|
||
"renderTypeList": [
|
||
"settingLLMModel",
|
||
"reference"
|
||
],
|
||
"label": "core.module.input.label.aiModel",
|
||
"valueType": "string",
|
||
"selectedTypeIndex": 0,
|
||
"value": "claude-3-5-sonnet-20240620"
|
||
},
|
||
{
|
||
"key": "temperature",
|
||
"renderTypeList": [
|
||
"hidden"
|
||
],
|
||
"label": "",
|
||
"value": 3,
|
||
"valueType": "number",
|
||
"min": 0,
|
||
"max": 10,
|
||
"step": 1
|
||
},
|
||
{
|
||
"key": "maxToken",
|
||
"renderTypeList": [
|
||
"hidden"
|
||
],
|
||
"label": "",
|
||
"value": 4000,
|
||
"valueType": "number",
|
||
"min": 100,
|
||
"max": 4000,
|
||
"step": 50
|
||
},
|
||
{
|
||
"key": "isResponseAnswerText",
|
||
"renderTypeList": [
|
||
"hidden"
|
||
],
|
||
"label": "",
|
||
"value": false,
|
||
"valueType": "boolean"
|
||
},
|
||
{
|
||
"key": "quoteTemplate",
|
||
"renderTypeList": [
|
||
"hidden"
|
||
],
|
||
"label": "",
|
||
"valueType": "string"
|
||
},
|
||
{
|
||
"key": "quotePrompt",
|
||
"renderTypeList": [
|
||
"hidden"
|
||
],
|
||
"label": "",
|
||
"valueType": "string"
|
||
},
|
||
{
|
||
"key": "systemPrompt",
|
||
"renderTypeList": [
|
||
"textarea",
|
||
"reference"
|
||
],
|
||
"max": 3000,
|
||
"valueType": "string",
|
||
"label": "core.ai.Prompt",
|
||
"description": "core.app.tip.chatNodeSystemPromptTip",
|
||
"placeholder": "core.app.tip.chatNodeSystemPromptTip",
|
||
"value": "# Role: 资深字幕翻译专家\n\n## Background:\n你是一位经验丰富的{{source_lang}}和{{target_lang}}字幕翻译专家,精通{{source_lang}}和{{target_lang}}互译,尤其擅长将{{source_lang}}字幕译成流畅易懂的{{target_lang}}字幕。你曾多次带领团队完成大型商业电影的字幕翻译项目,所翻译的字幕广受好评。\n\n## Attention:\n- 翻译过程中要始终坚持\"信、达、雅\"的原则,但\"达\"尤为重要\n- 翻译的字幕要符合{{target_lang}}的表达习惯,通俗易懂,连贯流畅\n- 避免使用过于文绉绉的表达和晦涩难懂的典故引用 \n- 诗词歌词等内容需按原文换行和节奏分行,不破坏原排列格式 \n- 翻译对象是字幕,请进入整段文本的语境中对需要翻译的文本段进行翻译\n- <T>是标识每一帧字幕的标签,请严格按照<T>对文本的分割逐帧翻译,每一帧字幕末尾不要加 \\n 回车标识,且第一帧字幕开头不需要加<T>标识\n\n## Constraints:\n- 必须严格遵循四轮翻译流程:直译、意译、反思、提升\n- 译文要忠实原文,准确无误,不能遗漏或曲解原意\n- 最终译文使用Markdown的代码块呈现,但是不用输出markdown这个单词\n- <T>是标识每一帧字幕的标签,请严格按照<T>对文本的分割逐帧翻译,每一帧字幕末尾不要加 \\n 回车标识,且第一帧字幕开头不需要加<T>标识\n\n## Goals:\n- 通过四轮翻译流程,将{{source_lang}}字幕译成高质量的{{target_lang}}字幕\n- 翻译的字幕要准确传达原字幕意思,语言表达力求浅显易懂,朗朗上口 \n\n## Workflow:\n1. 第一轮直译:严格按照<T>逐句翻译,不遗漏任何信息\n2. 第二轮意译:在直译的基础上用通俗流畅的{{target_lang}}意译原文,逐句翻译,保留<T>标识标签\n3. 第三轮反思:仔细审视译文,分点列出一份建设性的批评和有用的建议清单以改进翻译,对每一句话提出建议,从以下四个角度展开\n (i) 准确性(纠正添加、误译、遗漏或未翻译的文本错误),\n (ii) 流畅性(应用{{target_lang}}的语法、拼写和标点规则,并确保没有不必要的重复),\n (iii) 风格(确保翻译反映源文本的风格并考虑其文化背景),\n (iv) 术语(确保术语使用一致且反映源文本所在领域,注意确保使用{{target_lang}}中的等效习语)\n4. 第四轮提升:严格遵循第三轮提出的建议对翻译修改,定稿出一个简洁畅达、符合大众观影习惯的字幕译文,保留<T>标识标签\n\n## OutputFormat:\n- 每一轮前用【思考】说明该轮要点\n- 第一轮和第二轮翻译后用【翻译】呈现译文\n- 第三轮输出建议清单,分点列出,在每一点前用*xxx*标识这条建议对应的要点,如*风格*;建议前用【思考】说明该轮要点,建议后用【建议】呈现建议\n- 第四轮在\\`\\`\\`代码块中展示最终{{target_lang}}字幕文件内容,如\\`\\`\\`xxx\\`\\`\\`\n\n## Suggestions:\n- 直译时力求忠实原文,但注意控制每帧字幕的字数,必要时进行精简压缩\n- 意译时在准确表达原意的基础上,用最朴实无华的{{target_lang}}来表达\n- 反思环节重点关注译文是否符合{{target_lang}}表达习惯,是否通俗易懂,是否准确流畅,是否术语一致\n- 提升环节采用反思环节的建议对意译环节的翻译进行修改,适度采用一些口语化的表达、网络流行语等,增强字幕的亲和力\n- 注意<T>是很重要的标识标签,请确保标签能在正确位置输出"
|
||
},
|
||
{
|
||
"key": "history",
|
||
"renderTypeList": [
|
||
"numberInput",
|
||
"reference"
|
||
],
|
||
"valueType": "chatHistory",
|
||
"label": "core.module.input.label.chat history",
|
||
"description": "最多携带多少轮对话记录",
|
||
"required": true,
|
||
"min": 0,
|
||
"max": 50,
|
||
"value": 6
|
||
},
|
||
{
|
||
"key": "userChatInput",
|
||
"renderTypeList": [
|
||
"reference",
|
||
"textarea"
|
||
],
|
||
"valueType": "string",
|
||
"label": "用户问题",
|
||
"required": true,
|
||
"toolDescription": "用户问题",
|
||
"value": [
|
||
"bxz97Vg4Omux",
|
||
"system_text"
|
||
]
|
||
},
|
||
{
|
||
"key": "quoteQA",
|
||
"renderTypeList": [
|
||
"settingDatasetQuotePrompt"
|
||
],
|
||
"label": "",
|
||
"debugLabel": "知识库引用",
|
||
"description": "",
|
||
"valueType": "datasetQuote"
|
||
}
|
||
],
|
||
"outputs": [
|
||
{
|
||
"id": "history",
|
||
"key": "history",
|
||
"required": true,
|
||
"label": "core.module.output.label.New context",
|
||
"description": "core.module.output.description.New context",
|
||
"valueType": "chatHistory",
|
||
"type": "static"
|
||
},
|
||
{
|
||
"id": "answerText",
|
||
"key": "answerText",
|
||
"required": true,
|
||
"label": "core.module.output.label.Ai response content",
|
||
"description": "core.module.output.description.Ai response content",
|
||
"valueType": "string",
|
||
"type": "static"
|
||
}
|
||
]
|
||
},
|
||
{
|
||
"nodeId": "bxz97Vg4Omux",
|
||
"name": "LLM 翻译提示词",
|
||
"intro": "可对固定或传入的文本进行加工后输出,非字符串类型数据最终会转成字符串类型。",
|
||
"avatar": "core/workflow/template/textConcat",
|
||
"flowNodeType": "textEditor",
|
||
"position": {
|
||
"x": 1893.11421220213,
|
||
"y": 1065.1299598362698
|
||
},
|
||
"version": "486",
|
||
"inputs": [
|
||
{
|
||
"key": "system_addInputParam",
|
||
"renderTypeList": [
|
||
"addInputParam"
|
||
],
|
||
"valueType": "dynamic",
|
||
"label": "",
|
||
"required": false,
|
||
"description": "可以引用其他节点的输出,作为文本拼接的变量,通过 {{字段名}} 来引用变量",
|
||
"customInputConfig": {
|
||
"selectValueTypeList": [
|
||
"string",
|
||
"number",
|
||
"boolean",
|
||
"object",
|
||
"arrayString",
|
||
"arrayNumber",
|
||
"arrayBoolean",
|
||
"arrayObject",
|
||
"any",
|
||
"chatHistory",
|
||
"datasetQuote",
|
||
"dynamic",
|
||
"selectApp",
|
||
"selectDataset"
|
||
],
|
||
"showDescription": false,
|
||
"showDefaultValue": false
|
||
}
|
||
},
|
||
{
|
||
"key": "system_textareaInput",
|
||
"renderTypeList": [
|
||
"textarea"
|
||
],
|
||
"valueType": "string",
|
||
"required": true,
|
||
"label": "拼接文本",
|
||
"placeholder": "可通过 {{字段名}} 来引用变量",
|
||
"value": "你的任务是将文本从{{source_lang}}翻译成{{target_lang}}\n\n源文本如下,由XML标签<SOURCE_TEXT>和</SOURCE_TEXT>分隔:\n\n<SOURCE_TEXT>\n\n{{tagged_text}}\n\n</SOURCE_TEXT>\n\n仅翻译源文本中由<TRANSLATE_THIS>和</TRANSLATE_THIS>分隔的部分,将其余的源文本作为上下文\n\n重申一下,你应该只翻译文本的这一部分,这里再次显示在<TRANSLATE_THIS>和</TRANSLATE_THIS>之间:\n\n<TRANSLATE_THIS>\n\n{{chunk_to_translate}}\n\n</TRANSLATE_THIS>"
|
||
},
|
||
{
|
||
"renderTypeList": [
|
||
"reference"
|
||
],
|
||
"valueType": "string",
|
||
"canEdit": true,
|
||
"key": "tagged_text",
|
||
"label": "tagged_text",
|
||
"customInputConfig": {
|
||
"selectValueTypeList": [
|
||
"string",
|
||
"number",
|
||
"boolean",
|
||
"object",
|
||
"arrayString",
|
||
"arrayNumber",
|
||
"arrayBoolean",
|
||
"arrayObject",
|
||
"any",
|
||
"chatHistory",
|
||
"datasetQuote",
|
||
"dynamic",
|
||
"selectApp",
|
||
"selectDataset"
|
||
],
|
||
"showDescription": false,
|
||
"showDefaultValue": false
|
||
},
|
||
"required": true,
|
||
"value": [
|
||
"quYZgsW32ApA",
|
||
"xhXu6sdEWBnF"
|
||
]
|
||
},
|
||
{
|
||
"renderTypeList": [
|
||
"reference"
|
||
],
|
||
"valueType": "string",
|
||
"canEdit": true,
|
||
"key": "chunk_to_translate",
|
||
"label": "chunk_to_translate",
|
||
"customInputConfig": {
|
||
"selectValueTypeList": [
|
||
"string",
|
||
"number",
|
||
"boolean",
|
||
"object",
|
||
"arrayString",
|
||
"arrayNumber",
|
||
"arrayBoolean",
|
||
"arrayObject",
|
||
"any",
|
||
"chatHistory",
|
||
"datasetQuote",
|
||
"dynamic",
|
||
"selectApp",
|
||
"selectDataset"
|
||
],
|
||
"showDescription": false,
|
||
"showDefaultValue": false
|
||
},
|
||
"required": true,
|
||
"value": [
|
||
"quYZgsW32ApA",
|
||
"eCp73lztAEGK"
|
||
]
|
||
}
|
||
],
|
||
"outputs": [
|
||
{
|
||
"id": "system_text",
|
||
"key": "system_text",
|
||
"label": "拼接结果",
|
||
"type": "static",
|
||
"valueType": "string"
|
||
}
|
||
]
|
||
},
|
||
{
|
||
"nodeId": "w4heEpNflz59",
|
||
"name": "判断是否执行结束",
|
||
"intro": "根据一定的条件,执行不同的分支。",
|
||
"avatar": "core/workflow/template/ifelse",
|
||
"flowNodeType": "ifElseNode",
|
||
"showStatus": true,
|
||
"position": {
|
||
"x": 5625.495682697096,
|
||
"y": 1199.9313115831496
|
||
},
|
||
"version": "481",
|
||
"inputs": [
|
||
{
|
||
"key": "ifElseList",
|
||
"renderTypeList": [
|
||
"hidden"
|
||
],
|
||
"valueType": "any",
|
||
"label": "",
|
||
"value": [
|
||
{
|
||
"condition": "AND",
|
||
"list": [
|
||
{
|
||
"variable": [
|
||
"a2lqxASWi1vb",
|
||
"nmBmGaARbKkl"
|
||
],
|
||
"condition": "equalTo",
|
||
"value": "true"
|
||
}
|
||
]
|
||
}
|
||
]
|
||
}
|
||
],
|
||
"outputs": [
|
||
{
|
||
"id": "ifElseResult",
|
||
"key": "ifElseResult",
|
||
"label": "判断结果",
|
||
"valueType": "string",
|
||
"type": "static"
|
||
}
|
||
]
|
||
},
|
||
{
|
||
"nodeId": "a2lqxASWi1vb",
|
||
"name": "判断是否执行结束",
|
||
"intro": "执行一段简单的脚本代码,通常用于进行复杂的数据处理。",
|
||
"avatar": "core/workflow/template/codeRun",
|
||
"flowNodeType": "code",
|
||
"showStatus": true,
|
||
"position": {
|
||
"x": 5099.256084679105,
|
||
"y": 1102.1518590433243
|
||
},
|
||
"version": "482",
|
||
"inputs": [
|
||
{
|
||
"key": "system_addInputParam",
|
||
"renderTypeList": [
|
||
"addInputParam"
|
||
],
|
||
"valueType": "dynamic",
|
||
"label": "",
|
||
"required": false,
|
||
"description": "这些变量会作为代码的运行的输入参数",
|
||
"customInputConfig": {
|
||
"selectValueTypeList": [
|
||
"string",
|
||
"number",
|
||
"boolean",
|
||
"object",
|
||
"arrayString",
|
||
"arrayNumber",
|
||
"arrayBoolean",
|
||
"arrayObject",
|
||
"any",
|
||
"chatHistory",
|
||
"datasetQuote",
|
||
"dynamic",
|
||
"selectApp",
|
||
"selectDataset"
|
||
],
|
||
"showDescription": false,
|
||
"showDefaultValue": true
|
||
}
|
||
},
|
||
{
|
||
"key": "codeType",
|
||
"renderTypeList": [
|
||
"hidden"
|
||
],
|
||
"label": "",
|
||
"value": "js"
|
||
},
|
||
{
|
||
"key": "code",
|
||
"renderTypeList": [
|
||
"custom"
|
||
],
|
||
"label": "",
|
||
"value": "function main({chunks, currentChunk}){\n const findIndex = chunks.findIndex((item) => item === currentChunk)\n\n return {\n isEnd: chunks.length-1 === findIndex,\n i: findIndex + 1,\n }\n}"
|
||
},
|
||
{
|
||
"renderTypeList": [
|
||
"reference"
|
||
],
|
||
"valueType": "arrayString",
|
||
"canEdit": true,
|
||
"key": "chunks",
|
||
"label": "chunks",
|
||
"customInputConfig": {
|
||
"selectValueTypeList": [
|
||
"string",
|
||
"number",
|
||
"boolean",
|
||
"object",
|
||
"arrayString",
|
||
"arrayNumber",
|
||
"arrayBoolean",
|
||
"arrayObject",
|
||
"any",
|
||
"chatHistory",
|
||
"datasetQuote",
|
||
"dynamic",
|
||
"selectApp",
|
||
"selectDataset"
|
||
],
|
||
"showDescription": false,
|
||
"showDefaultValue": true
|
||
},
|
||
"required": true,
|
||
"value": [
|
||
"y3WEYOQ09CGC",
|
||
"qLUQfhG0ILRX"
|
||
]
|
||
},
|
||
{
|
||
"renderTypeList": [
|
||
"reference"
|
||
],
|
||
"valueType": "string",
|
||
"canEdit": true,
|
||
"key": "currentChunk",
|
||
"label": "currentChunk",
|
||
"customInputConfig": {
|
||
"selectValueTypeList": [
|
||
"string",
|
||
"number",
|
||
"boolean",
|
||
"object",
|
||
"arrayString",
|
||
"arrayNumber",
|
||
"arrayBoolean",
|
||
"arrayObject",
|
||
"any",
|
||
"chatHistory",
|
||
"datasetQuote",
|
||
"dynamic",
|
||
"selectApp",
|
||
"selectDataset"
|
||
],
|
||
"showDescription": false,
|
||
"showDefaultValue": true
|
||
},
|
||
"required": true,
|
||
"value": [
|
||
"quYZgsW32ApA",
|
||
"eCp73lztAEGK"
|
||
]
|
||
}
|
||
],
|
||
"outputs": [
|
||
{
|
||
"id": "system_rawResponse",
|
||
"key": "system_rawResponse",
|
||
"label": "完整响应数据",
|
||
"valueType": "object",
|
||
"type": "static"
|
||
},
|
||
{
|
||
"id": "error",
|
||
"key": "error",
|
||
"label": "运行错误",
|
||
"description": "代码运行错误信息,成功时返回空",
|
||
"valueType": "object",
|
||
"type": "static"
|
||
},
|
||
{
|
||
"id": "system_addOutputParam",
|
||
"key": "system_addOutputParam",
|
||
"type": "dynamic",
|
||
"valueType": "dynamic",
|
||
"label": "",
|
||
"customFieldConfig": {
|
||
"selectValueTypeList": [
|
||
"string",
|
||
"number",
|
||
"boolean",
|
||
"object",
|
||
"arrayString",
|
||
"arrayNumber",
|
||
"arrayBoolean",
|
||
"arrayObject",
|
||
"any",
|
||
"chatHistory",
|
||
"datasetQuote",
|
||
"dynamic",
|
||
"selectApp",
|
||
"selectDataset"
|
||
],
|
||
"showDescription": false,
|
||
"showDefaultValue": false
|
||
},
|
||
"description": "将代码中 return 的对象作为输出,传递给后续的节点。变量名需要对应 return 的 key"
|
||
},
|
||
{
|
||
"id": "nmBmGaARbKkl",
|
||
"valueType": "boolean",
|
||
"type": "dynamic",
|
||
"key": "isEnd",
|
||
"label": "isEnd"
|
||
},
|
||
{
|
||
"id": "nqB98uKpq6Ig",
|
||
"valueType": "number",
|
||
"type": "dynamic",
|
||
"key": "i",
|
||
"label": "i"
|
||
}
|
||
]
|
||
},
|
||
{
|
||
"nodeId": "quYZgsW32ApA",
|
||
"name": "格式化源文本块",
|
||
"intro": "执行一段简单的脚本代码,通常用于进行复杂的数据处理。",
|
||
"avatar": "core/workflow/template/codeRun",
|
||
"flowNodeType": "code",
|
||
"showStatus": true,
|
||
"position": {
|
||
"x": 1251.2839737092052,
|
||
"y": 991.619268503857
|
||
},
|
||
"version": "482",
|
||
"inputs": [
|
||
{
|
||
"key": "system_addInputParam",
|
||
"renderTypeList": [
|
||
"addInputParam"
|
||
],
|
||
"valueType": "dynamic",
|
||
"label": "",
|
||
"required": false,
|
||
"description": "这些变量会作为代码的运行的输入参数",
|
||
"customInputConfig": {
|
||
"selectValueTypeList": [
|
||
"string",
|
||
"number",
|
||
"boolean",
|
||
"object",
|
||
"arrayString",
|
||
"arrayNumber",
|
||
"arrayBoolean",
|
||
"arrayObject",
|
||
"any",
|
||
"chatHistory",
|
||
"datasetQuote",
|
||
"dynamic",
|
||
"selectApp",
|
||
"selectDataset"
|
||
],
|
||
"showDescription": false,
|
||
"showDefaultValue": true
|
||
}
|
||
},
|
||
{
|
||
"key": "codeType",
|
||
"renderTypeList": [
|
||
"hidden"
|
||
],
|
||
"label": "",
|
||
"value": "js"
|
||
},
|
||
{
|
||
"key": "code",
|
||
"renderTypeList": [
|
||
"custom"
|
||
],
|
||
"label": "",
|
||
"value": "function main({source_text_chunks, i=0}){\n let before = source_text_chunks.slice(0, i).join(\"\");\n let current = \" <TRANSLATE_THIS>\" + source_text_chunks[i] + \"</TRANSLATE_THIS>\";\n let after = source_text_chunks.slice(i + 1).join(\"\");\n let tagged_text = before + current + after;\n\n return {\n tagged_text,\n chunk_to_translate: source_text_chunks[i],\n }\n}"
|
||
},
|
||
{
|
||
"renderTypeList": [
|
||
"reference"
|
||
],
|
||
"valueType": "number",
|
||
"canEdit": true,
|
||
"key": "i",
|
||
"label": "i",
|
||
"customInputConfig": {
|
||
"selectValueTypeList": [
|
||
"string",
|
||
"number",
|
||
"boolean",
|
||
"object",
|
||
"arrayString",
|
||
"arrayNumber",
|
||
"arrayBoolean",
|
||
"arrayObject",
|
||
"any",
|
||
"chatHistory",
|
||
"datasetQuote",
|
||
"dynamic",
|
||
"selectApp",
|
||
"selectDataset"
|
||
],
|
||
"showDescription": false,
|
||
"showDefaultValue": true
|
||
},
|
||
"required": true,
|
||
"value": [
|
||
"a2lqxASWi1vb",
|
||
"nqB98uKpq6Ig"
|
||
]
|
||
},
|
||
{
|
||
"renderTypeList": [
|
||
"reference"
|
||
],
|
||
"valueType": "arrayString",
|
||
"canEdit": true,
|
||
"key": "source_text_chunks",
|
||
"label": "source_text_chunks",
|
||
"customInputConfig": {
|
||
"selectValueTypeList": [
|
||
"string",
|
||
"number",
|
||
"boolean",
|
||
"object",
|
||
"arrayString",
|
||
"arrayNumber",
|
||
"arrayBoolean",
|
||
"arrayObject",
|
||
"any",
|
||
"chatHistory",
|
||
"datasetQuote",
|
||
"dynamic",
|
||
"selectApp",
|
||
"selectDataset"
|
||
],
|
||
"showDescription": false,
|
||
"showDefaultValue": true
|
||
},
|
||
"required": true,
|
||
"value": [
|
||
"y3WEYOQ09CGC",
|
||
"qLUQfhG0ILRX"
|
||
]
|
||
}
|
||
],
|
||
"outputs": [
|
||
{
|
||
"id": "system_rawResponse",
|
||
"key": "system_rawResponse",
|
||
"label": "完整响应数据",
|
||
"valueType": "object",
|
||
"type": "static"
|
||
},
|
||
{
|
||
"id": "error",
|
||
"key": "error",
|
||
"label": "运行错误",
|
||
"description": "代码运行错误信息,成功时返回空",
|
||
"valueType": "object",
|
||
"type": "static"
|
||
},
|
||
{
|
||
"id": "system_addOutputParam",
|
||
"key": "system_addOutputParam",
|
||
"type": "dynamic",
|
||
"valueType": "dynamic",
|
||
"label": "",
|
||
"customFieldConfig": {
|
||
"selectValueTypeList": [
|
||
"string",
|
||
"number",
|
||
"boolean",
|
||
"object",
|
||
"arrayString",
|
||
"arrayNumber",
|
||
"arrayBoolean",
|
||
"arrayObject",
|
||
"any",
|
||
"chatHistory",
|
||
"datasetQuote",
|
||
"dynamic",
|
||
"selectApp",
|
||
"selectDataset"
|
||
],
|
||
"showDescription": false,
|
||
"showDefaultValue": false
|
||
},
|
||
"description": "将代码中 return 的对象作为输出,传递给后续的节点。变量名需要对应 return 的 key"
|
||
},
|
||
{
|
||
"id": "xhXu6sdEWBnF",
|
||
"valueType": "string",
|
||
"type": "dynamic",
|
||
"key": "tagged_text",
|
||
"label": "tagged_text"
|
||
},
|
||
{
|
||
"id": "eCp73lztAEGK",
|
||
"valueType": "string",
|
||
"type": "dynamic",
|
||
"key": "chunk_to_translate",
|
||
"label": "chunk_to_translate"
|
||
}
|
||
]
|
||
},
|
||
{
|
||
"nodeId": "izsNX8FXGD1t",
|
||
"name": "指定回复",
|
||
"intro": "该模块可以直接回复一段指定的内容。常用于引导、提示。非字符串内容传入时,会转成字符串进行输出。",
|
||
"avatar": "core/workflow/template/reply",
|
||
"flowNodeType": "answerNode",
|
||
"position": {
|
||
"x": 6399.439691374053,
|
||
"y": 1204.4024103331792
|
||
},
|
||
"version": "481",
|
||
"inputs": [
|
||
{
|
||
"key": "text",
|
||
"renderTypeList": [
|
||
"textarea",
|
||
"reference"
|
||
],
|
||
"valueType": "any",
|
||
"required": true,
|
||
"label": "core.module.input.label.Response content",
|
||
"description": "core.module.input.description.Response content",
|
||
"placeholder": "core.module.input.description.Response content",
|
||
"value": "\n\n*** 字幕反思翻译完成!***"
|
||
}
|
||
],
|
||
"outputs": []
|
||
},
|
||
{
|
||
"nodeId": "vlNHndpNuFXB",
|
||
"name": "取出 LLM 翻译第四轮文本",
|
||
"intro": "执行一段简单的脚本代码,通常用于进行复杂的数据处理。",
|
||
"avatar": "core/workflow/template/codeRun",
|
||
"flowNodeType": "code",
|
||
"showStatus": true,
|
||
"position": {
|
||
"x": 3284.6375352131763,
|
||
"y": 950.1100995985583
|
||
},
|
||
"version": "482",
|
||
"inputs": [
|
||
{
|
||
"key": "system_addInputParam",
|
||
"renderTypeList": [
|
||
"addInputParam"
|
||
],
|
||
"valueType": "dynamic",
|
||
"label": "",
|
||
"required": false,
|
||
"description": "这些变量会作为代码的运行的输入参数",
|
||
"editField": {
|
||
"key": true,
|
||
"valueType": true
|
||
},
|
||
"customInputConfig": {
|
||
"selectValueTypeList": [
|
||
"string",
|
||
"number",
|
||
"boolean",
|
||
"object",
|
||
"arrayString",
|
||
"arrayNumber",
|
||
"arrayBoolean",
|
||
"arrayObject",
|
||
"any",
|
||
"chatHistory",
|
||
"datasetQuote",
|
||
"dynamic",
|
||
"selectApp",
|
||
"selectDataset"
|
||
],
|
||
"showDescription": false,
|
||
"showDefaultValue": true
|
||
}
|
||
},
|
||
{
|
||
"key": "codeType",
|
||
"renderTypeList": [
|
||
"hidden"
|
||
],
|
||
"label": "",
|
||
"value": "js"
|
||
},
|
||
{
|
||
"key": "code",
|
||
"renderTypeList": [
|
||
"custom"
|
||
],
|
||
"label": "",
|
||
"value": "function main({data1}){\n const result = data1.split(\"```\").filter(item => !!item.trim())\n\n if(result[result.length-1]) {\n return {\n result: result[result.length-1].trim() \n }\n }\n\n return {\n result: '未截取到翻译内容'\n }\n}"
|
||
},
|
||
{
|
||
"key": "data1",
|
||
"valueType": "string",
|
||
"label": "data1",
|
||
"renderTypeList": [
|
||
"reference"
|
||
],
|
||
"description": "",
|
||
"canEdit": true,
|
||
"editField": {
|
||
"key": true,
|
||
"valueType": true
|
||
},
|
||
"value": [
|
||
"yjFO3YcM7KG2",
|
||
"answerText"
|
||
],
|
||
"customInputConfig": {
|
||
"selectValueTypeList": [
|
||
"string",
|
||
"number",
|
||
"boolean",
|
||
"object",
|
||
"arrayString",
|
||
"arrayNumber",
|
||
"arrayBoolean",
|
||
"arrayObject",
|
||
"any",
|
||
"chatHistory",
|
||
"datasetQuote",
|
||
"dynamic",
|
||
"selectApp",
|
||
"selectDataset"
|
||
],
|
||
"showDescription": false,
|
||
"showDefaultValue": true
|
||
}
|
||
}
|
||
],
|
||
"outputs": [
|
||
{
|
||
"id": "system_rawResponse",
|
||
"key": "system_rawResponse",
|
||
"label": "完整响应数据",
|
||
"valueType": "object",
|
||
"type": "static"
|
||
},
|
||
{
|
||
"id": "error",
|
||
"key": "error",
|
||
"label": "运行错误",
|
||
"description": "代码运行错误信息,成功时返回空",
|
||
"valueType": "object",
|
||
"type": "static"
|
||
},
|
||
{
|
||
"id": "system_addOutputParam",
|
||
"key": "system_addOutputParam",
|
||
"type": "dynamic",
|
||
"valueType": "dynamic",
|
||
"label": "",
|
||
"customFieldConfig": {
|
||
"selectValueTypeList": [
|
||
"string",
|
||
"number",
|
||
"boolean",
|
||
"object",
|
||
"arrayString",
|
||
"arrayNumber",
|
||
"arrayBoolean",
|
||
"arrayObject",
|
||
"any",
|
||
"chatHistory",
|
||
"datasetQuote",
|
||
"dynamic",
|
||
"selectApp",
|
||
"selectDataset"
|
||
],
|
||
"showDescription": false,
|
||
"showDefaultValue": false
|
||
},
|
||
"description": "将代码中 return 的对象作为输出,传递给后续的节点。变量名需要对应 return 的 key"
|
||
},
|
||
{
|
||
"id": "qLUQfhG0ILRX",
|
||
"type": "dynamic",
|
||
"key": "result",
|
||
"valueType": "string",
|
||
"label": "result"
|
||
},
|
||
{
|
||
"id": "gR0mkQpJ4Og8",
|
||
"type": "dynamic",
|
||
"key": "data2",
|
||
"valueType": "string",
|
||
"label": "data2"
|
||
}
|
||
]
|
||
},
|
||
{
|
||
"nodeId": "qlt9KJbbS9yJ",
|
||
"name": "判断源语言和目标语言是否相同",
|
||
"intro": "根据一定的条件,执行不同的分支。",
|
||
"avatar": "core/workflow/template/ifelse",
|
||
"flowNodeType": "ifElseNode",
|
||
"showStatus": true,
|
||
"position": {
|
||
"x": -648.2730659546055,
|
||
"y": 1295.3336516652123
|
||
},
|
||
"version": "481",
|
||
"inputs": [
|
||
{
|
||
"key": "ifElseList",
|
||
"renderTypeList": [
|
||
"hidden"
|
||
],
|
||
"valueType": "any",
|
||
"label": "",
|
||
"value": [
|
||
{
|
||
"condition": "AND",
|
||
"list": [
|
||
{
|
||
"variable": [
|
||
"frjbsrlnJJsR",
|
||
"qLUQfhG0ILRX"
|
||
],
|
||
"condition": "equalTo",
|
||
"value": "false"
|
||
}
|
||
]
|
||
}
|
||
]
|
||
}
|
||
],
|
||
"outputs": [
|
||
{
|
||
"id": "ifElseResult",
|
||
"key": "ifElseResult",
|
||
"label": "判断结果",
|
||
"valueType": "string",
|
||
"type": "static"
|
||
}
|
||
]
|
||
},
|
||
{
|
||
"nodeId": "frjbsrlnJJsR",
|
||
"name": "判断源语言和目标语言是否相同",
|
||
"intro": "执行一段简单的脚本代码,通常用于进行复杂的数据处理。",
|
||
"avatar": "core/workflow/template/codeRun",
|
||
"flowNodeType": "code",
|
||
"showStatus": true,
|
||
"position": {
|
||
"x": -1142.9562352499165,
|
||
"y": 1031.4486788585432
|
||
},
|
||
"version": "482",
|
||
"inputs": [
|
||
{
|
||
"key": "system_addInputParam",
|
||
"renderTypeList": [
|
||
"addInputParam"
|
||
],
|
||
"valueType": "dynamic",
|
||
"label": "",
|
||
"required": false,
|
||
"description": "这些变量会作为代码的运行的输入参数",
|
||
"customInputConfig": {
|
||
"selectValueTypeList": [
|
||
"string",
|
||
"number",
|
||
"boolean",
|
||
"object",
|
||
"arrayString",
|
||
"arrayNumber",
|
||
"arrayBoolean",
|
||
"arrayObject",
|
||
"any",
|
||
"chatHistory",
|
||
"datasetQuote",
|
||
"dynamic",
|
||
"selectApp",
|
||
"selectDataset"
|
||
],
|
||
"showDescription": false,
|
||
"showDefaultValue": true
|
||
}
|
||
},
|
||
{
|
||
"key": "codeType",
|
||
"renderTypeList": [
|
||
"hidden"
|
||
],
|
||
"label": "",
|
||
"value": "js"
|
||
},
|
||
{
|
||
"key": "code",
|
||
"renderTypeList": [
|
||
"custom"
|
||
],
|
||
"label": "",
|
||
"value": "function main({source_lang, target_lang}){\n \n return {\n result: source_lang === target_lang\n }\n}"
|
||
},
|
||
{
|
||
"renderTypeList": [
|
||
"reference"
|
||
],
|
||
"valueType": "string",
|
||
"canEdit": true,
|
||
"key": "source_lang",
|
||
"label": "source_lang",
|
||
"customInputConfig": {
|
||
"selectValueTypeList": [
|
||
"string",
|
||
"number",
|
||
"boolean",
|
||
"object",
|
||
"arrayString",
|
||
"arrayNumber",
|
||
"arrayBoolean",
|
||
"arrayObject",
|
||
"any",
|
||
"chatHistory",
|
||
"datasetQuote",
|
||
"dynamic",
|
||
"selectApp",
|
||
"selectDataset"
|
||
],
|
||
"showDescription": false,
|
||
"showDefaultValue": true
|
||
},
|
||
"required": true,
|
||
"value": [
|
||
"VARIABLE_NODE_ID",
|
||
"source_lang"
|
||
]
|
||
},
|
||
{
|
||
"renderTypeList": [
|
||
"reference"
|
||
],
|
||
"valueType": "string",
|
||
"canEdit": true,
|
||
"key": "target_lang",
|
||
"label": "target_lang",
|
||
"customInputConfig": {
|
||
"selectValueTypeList": [
|
||
"string",
|
||
"number",
|
||
"boolean",
|
||
"object",
|
||
"arrayString",
|
||
"arrayNumber",
|
||
"arrayBoolean",
|
||
"arrayObject",
|
||
"any",
|
||
"chatHistory",
|
||
"datasetQuote",
|
||
"dynamic",
|
||
"selectApp",
|
||
"selectDataset"
|
||
],
|
||
"showDescription": false,
|
||
"showDefaultValue": true
|
||
},
|
||
"required": true,
|
||
"value": [
|
||
"VARIABLE_NODE_ID",
|
||
"target_lang"
|
||
]
|
||
}
|
||
],
|
||
"outputs": [
|
||
{
|
||
"id": "system_rawResponse",
|
||
"key": "system_rawResponse",
|
||
"label": "完整响应数据",
|
||
"valueType": "object",
|
||
"type": "static"
|
||
},
|
||
{
|
||
"id": "error",
|
||
"key": "error",
|
||
"label": "运行错误",
|
||
"description": "代码运行错误信息,成功时返回空",
|
||
"valueType": "object",
|
||
"type": "static"
|
||
},
|
||
{
|
||
"id": "system_addOutputParam",
|
||
"key": "system_addOutputParam",
|
||
"type": "dynamic",
|
||
"valueType": "dynamic",
|
||
"label": "",
|
||
"customFieldConfig": {
|
||
"selectValueTypeList": [
|
||
"string",
|
||
"number",
|
||
"boolean",
|
||
"object",
|
||
"arrayString",
|
||
"arrayNumber",
|
||
"arrayBoolean",
|
||
"arrayObject",
|
||
"any",
|
||
"chatHistory",
|
||
"datasetQuote",
|
||
"dynamic",
|
||
"selectApp",
|
||
"selectDataset"
|
||
],
|
||
"showDescription": false,
|
||
"showDefaultValue": false
|
||
},
|
||
"description": "将代码中 return 的对象作为输出,传递给后续的节点。变量名需要对应 return 的 key"
|
||
},
|
||
{
|
||
"id": "qLUQfhG0ILRX",
|
||
"type": "dynamic",
|
||
"key": "result",
|
||
"valueType": "boolean",
|
||
"label": "result"
|
||
}
|
||
]
|
||
},
|
||
{
|
||
"nodeId": "dFxrGZS3Wmnz",
|
||
"name": "提示源语言与目标语言相同",
|
||
"intro": "该模块可以直接回复一段指定的内容。常用于引导、提示。非字符串内容传入时,会转成字符串进行输出。",
|
||
"avatar": "core/workflow/template/reply",
|
||
"flowNodeType": "answerNode",
|
||
"position": {
|
||
"x": -554.7555863373991,
|
||
"y": 1727.175384457058
|
||
},
|
||
"version": "481",
|
||
"inputs": [
|
||
{
|
||
"key": "text",
|
||
"renderTypeList": [
|
||
"textarea",
|
||
"reference"
|
||
],
|
||
"valueType": "any",
|
||
"required": true,
|
||
"label": "core.module.input.label.Response content",
|
||
"description": "core.module.input.description.Response content",
|
||
"placeholder": "core.module.input.description.Response content",
|
||
"selectedTypeIndex": 0,
|
||
"value": "{{source_lang}} 无需再次翻译为 {{target_lang}} ~"
|
||
}
|
||
],
|
||
"outputs": []
|
||
},
|
||
{
|
||
"nodeId": "tqzmK5oPR9BA",
|
||
"name": "输出翻译",
|
||
"intro": "该模块可以直接回复一段指定的内容。常用于引导、提示。非字符串内容传入时,会转成字符串进行输出。",
|
||
"avatar": "core/workflow/template/reply",
|
||
"flowNodeType": "answerNode",
|
||
"position": {
|
||
"x": 4378.294585712487,
|
||
"y": 1268.975092230105
|
||
},
|
||
"version": "481",
|
||
"inputs": [
|
||
{
|
||
"key": "text",
|
||
"renderTypeList": [
|
||
"textarea",
|
||
"reference"
|
||
],
|
||
"valueType": "any",
|
||
"required": true,
|
||
"label": "core.module.input.label.Response content",
|
||
"description": "core.module.input.description.Response content",
|
||
"placeholder": "core.module.input.description.Response content",
|
||
"selectedTypeIndex": 1,
|
||
"value": [
|
||
"ppPP6o7YYSTJ",
|
||
"dYalXmYJ60bj"
|
||
]
|
||
}
|
||
],
|
||
"outputs": []
|
||
},
|
||
{
|
||
"nodeId": "kbr342XlxSZR",
|
||
"name": "提取字幕信息",
|
||
"intro": "执行一段简单的脚本代码,通常用于进行复杂的数据处理。",
|
||
"avatar": "core/workflow/template/codeRun",
|
||
"flowNodeType": "code",
|
||
"showStatus": true,
|
||
"position": {
|
||
"x": 185.35869756392378,
|
||
"y": 1004.6884026918935
|
||
},
|
||
"version": "482",
|
||
"inputs": [
|
||
{
|
||
"key": "system_addInputParam",
|
||
"renderTypeList": [
|
||
"addInputParam"
|
||
],
|
||
"valueType": "dynamic",
|
||
"label": "",
|
||
"required": false,
|
||
"description": "这些变量会作为代码的运行的输入参数",
|
||
"customInputConfig": {
|
||
"selectValueTypeList": [
|
||
"string",
|
||
"number",
|
||
"boolean",
|
||
"object",
|
||
"arrayString",
|
||
"arrayNumber",
|
||
"arrayBoolean",
|
||
"arrayObject",
|
||
"any",
|
||
"chatHistory",
|
||
"datasetQuote",
|
||
"dynamic",
|
||
"selectApp",
|
||
"selectDataset"
|
||
],
|
||
"showDescription": false,
|
||
"showDefaultValue": true
|
||
}
|
||
},
|
||
{
|
||
"key": "codeType",
|
||
"renderTypeList": [
|
||
"hidden"
|
||
],
|
||
"label": "",
|
||
"value": "js"
|
||
},
|
||
{
|
||
"key": "code",
|
||
"renderTypeList": [
|
||
"custom"
|
||
],
|
||
"label": "",
|
||
"value": "function main({text}){\n const lines = text.split('\\n');\n const timePattern = /\\d{2}:\\d{2}:\\d{2},\\d{3} --> \\d{2}:\\d{2}:\\d{2},\\d{3}/;\n const numberInfo = [];\n const timeInfo = [];\n const textInfo = [];\n let currentText = [];\n\n // 提取序号、时间戳和文本信息\n lines.forEach(line => {\n if (/^\\d+$/.test(line.trim())) {\n numberInfo.push(line.trim());\n } else if (timePattern.test(line)) {\n timeInfo.push(line);\n if (currentText.length > 0) {\n textInfo.push(currentText.join(' '));\n currentText = [];\n }\n } else if (line.trim() === '') {\n // Skip empty lines\n } else {\n currentText.push(line.trim());\n }\n });\n\n if (currentText.length > 0) {\n textInfo.push(currentText.join(' '));\n }\n\n return { numberInfo, timeInfo, textInfo };\n}"
|
||
},
|
||
{
|
||
"renderTypeList": [
|
||
"reference"
|
||
],
|
||
"valueType": "string",
|
||
"canEdit": true,
|
||
"key": "text",
|
||
"label": "text",
|
||
"customInputConfig": {
|
||
"selectValueTypeList": [
|
||
"string",
|
||
"number",
|
||
"boolean",
|
||
"object",
|
||
"arrayString",
|
||
"arrayNumber",
|
||
"arrayBoolean",
|
||
"arrayObject",
|
||
"any",
|
||
"chatHistory",
|
||
"datasetQuote",
|
||
"dynamic",
|
||
"selectApp",
|
||
"selectDataset"
|
||
],
|
||
"showDescription": false,
|
||
"showDefaultValue": true
|
||
},
|
||
"required": true,
|
||
"value": [
|
||
"448745",
|
||
"userChatInput"
|
||
]
|
||
}
|
||
],
|
||
"outputs": [
|
||
{
|
||
"id": "system_rawResponse",
|
||
"key": "system_rawResponse",
|
||
"label": "完整响应数据",
|
||
"valueType": "object",
|
||
"type": "static"
|
||
},
|
||
{
|
||
"id": "error",
|
||
"key": "error",
|
||
"label": "运行错误",
|
||
"description": "代码运行错误信息,成功时返回空",
|
||
"valueType": "object",
|
||
"type": "static"
|
||
},
|
||
{
|
||
"id": "system_addOutputParam",
|
||
"key": "system_addOutputParam",
|
||
"type": "dynamic",
|
||
"valueType": "dynamic",
|
||
"label": "",
|
||
"customFieldConfig": {
|
||
"selectValueTypeList": [
|
||
"string",
|
||
"number",
|
||
"boolean",
|
||
"object",
|
||
"arrayString",
|
||
"arrayNumber",
|
||
"arrayBoolean",
|
||
"arrayObject",
|
||
"any",
|
||
"chatHistory",
|
||
"datasetQuote",
|
||
"dynamic",
|
||
"selectApp",
|
||
"selectDataset"
|
||
],
|
||
"showDescription": false,
|
||
"showDefaultValue": false
|
||
},
|
||
"description": "将代码中 return 的对象作为输出,传递给后续的节点。变量名需要对应 return 的 key"
|
||
},
|
||
{
|
||
"id": "h3qVuGhV9HNm",
|
||
"valueType": "arrayString",
|
||
"type": "dynamic",
|
||
"key": "timeInfo",
|
||
"label": "timeInfo"
|
||
},
|
||
{
|
||
"id": "zGYRMNA9xGuI",
|
||
"valueType": "arrayString",
|
||
"type": "dynamic",
|
||
"key": "textInfo",
|
||
"label": "textInfo"
|
||
},
|
||
{
|
||
"id": "dhzTt6Riz8Dp",
|
||
"valueType": "arrayString",
|
||
"type": "dynamic",
|
||
"key": "numberInfo",
|
||
"label": "numberInfo"
|
||
}
|
||
]
|
||
},
|
||
{
|
||
"nodeId": "ppPP6o7YYSTJ",
|
||
"name": "格式化字幕文件",
|
||
"intro": "执行一段简单的脚本代码,通常用于进行复杂的数据处理。",
|
||
"avatar": "core/workflow/template/codeRun",
|
||
"flowNodeType": "code",
|
||
"showStatus": true,
|
||
"position": {
|
||
"x": 3825.553384884565,
|
||
"y": 956.4575651844932
|
||
},
|
||
"version": "482",
|
||
"inputs": [
|
||
{
|
||
"key": "system_addInputParam",
|
||
"renderTypeList": [
|
||
"addInputParam"
|
||
],
|
||
"valueType": "dynamic",
|
||
"label": "",
|
||
"required": false,
|
||
"description": "这些变量会作为代码的运行的输入参数",
|
||
"customInputConfig": {
|
||
"selectValueTypeList": [
|
||
"string",
|
||
"number",
|
||
"boolean",
|
||
"object",
|
||
"arrayString",
|
||
"arrayNumber",
|
||
"arrayBoolean",
|
||
"arrayObject",
|
||
"any",
|
||
"chatHistory",
|
||
"datasetQuote",
|
||
"dynamic",
|
||
"selectApp",
|
||
"selectDataset"
|
||
],
|
||
"showDescription": false,
|
||
"showDefaultValue": true
|
||
}
|
||
},
|
||
{
|
||
"key": "codeType",
|
||
"renderTypeList": [
|
||
"hidden"
|
||
],
|
||
"label": "",
|
||
"value": "js"
|
||
},
|
||
{
|
||
"key": "code",
|
||
"renderTypeList": [
|
||
"custom"
|
||
],
|
||
"label": "",
|
||
"value": "function main({combinedText, transedText, timeInfo, currentIndex=0,numberInfo}){\n const textLines = combinedText.split('<T>');\n const resultLines = transedText.split('<T>');\n const combinedLines = [];\n\n resultLines.forEach((line, index) => {\n combinedLines.push(numberInfo[currentIndex+index]);\n combinedLines.push(timeInfo[currentIndex+index]);\n combinedLines.push(line)\n combinedLines.push(textLines[index]);\n combinedLines.push('');\n });\n\n const srtContent = combinedLines.join('\\n');\n \n\n return {\n srtContent,\n currentIndex: currentIndex+textLines.length\n }\n}"
|
||
},
|
||
{
|
||
"renderTypeList": [
|
||
"reference"
|
||
],
|
||
"valueType": "string",
|
||
"canEdit": true,
|
||
"key": "combinedText",
|
||
"label": "combinedText",
|
||
"customInputConfig": {
|
||
"selectValueTypeList": [
|
||
"string",
|
||
"number",
|
||
"boolean",
|
||
"object",
|
||
"arrayString",
|
||
"arrayNumber",
|
||
"arrayBoolean",
|
||
"arrayObject",
|
||
"any",
|
||
"chatHistory",
|
||
"datasetQuote",
|
||
"dynamic",
|
||
"selectApp",
|
||
"selectDataset"
|
||
],
|
||
"showDescription": false,
|
||
"showDefaultValue": true
|
||
},
|
||
"required": true,
|
||
"value": [
|
||
"quYZgsW32ApA",
|
||
"eCp73lztAEGK"
|
||
]
|
||
},
|
||
{
|
||
"renderTypeList": [
|
||
"reference"
|
||
],
|
||
"valueType": "string",
|
||
"canEdit": true,
|
||
"key": "transedText",
|
||
"label": "transedText",
|
||
"customInputConfig": {
|
||
"selectValueTypeList": [
|
||
"string",
|
||
"number",
|
||
"boolean",
|
||
"object",
|
||
"arrayString",
|
||
"arrayNumber",
|
||
"arrayBoolean",
|
||
"arrayObject",
|
||
"any",
|
||
"chatHistory",
|
||
"datasetQuote",
|
||
"dynamic",
|
||
"selectApp",
|
||
"selectDataset"
|
||
],
|
||
"showDescription": false,
|
||
"showDefaultValue": true
|
||
},
|
||
"required": true,
|
||
"value": [
|
||
"vlNHndpNuFXB",
|
||
"qLUQfhG0ILRX"
|
||
]
|
||
},
|
||
{
|
||
"renderTypeList": [
|
||
"reference"
|
||
],
|
||
"valueType": "arrayString",
|
||
"canEdit": true,
|
||
"key": "timeInfo",
|
||
"label": "timeInfo",
|
||
"customInputConfig": {
|
||
"selectValueTypeList": [
|
||
"string",
|
||
"number",
|
||
"boolean",
|
||
"object",
|
||
"arrayString",
|
||
"arrayNumber",
|
||
"arrayBoolean",
|
||
"arrayObject",
|
||
"any",
|
||
"chatHistory",
|
||
"datasetQuote",
|
||
"dynamic",
|
||
"selectApp",
|
||
"selectDataset"
|
||
],
|
||
"showDescription": false,
|
||
"showDefaultValue": true
|
||
},
|
||
"required": true,
|
||
"value": [
|
||
"kbr342XlxSZR",
|
||
"h3qVuGhV9HNm"
|
||
]
|
||
},
|
||
{
|
||
"renderTypeList": [
|
||
"reference"
|
||
],
|
||
"valueType": "number",
|
||
"canEdit": true,
|
||
"key": "currentIndex",
|
||
"label": "currentIndex",
|
||
"customInputConfig": {
|
||
"selectValueTypeList": [
|
||
"string",
|
||
"number",
|
||
"boolean",
|
||
"object",
|
||
"arrayString",
|
||
"arrayNumber",
|
||
"arrayBoolean",
|
||
"arrayObject",
|
||
"any",
|
||
"chatHistory",
|
||
"datasetQuote",
|
||
"dynamic",
|
||
"selectApp",
|
||
"selectDataset"
|
||
],
|
||
"showDescription": false,
|
||
"showDefaultValue": true
|
||
},
|
||
"required": true,
|
||
"value": [
|
||
"ppPP6o7YYSTJ",
|
||
"u6eqeC0pEPe0"
|
||
]
|
||
},
|
||
{
|
||
"renderTypeList": [
|
||
"reference"
|
||
],
|
||
"valueType": "arrayString",
|
||
"canEdit": true,
|
||
"key": "numberInfo",
|
||
"label": "numberInfo",
|
||
"customInputConfig": {
|
||
"selectValueTypeList": [
|
||
"string",
|
||
"number",
|
||
"boolean",
|
||
"object",
|
||
"arrayString",
|
||
"arrayNumber",
|
||
"arrayBoolean",
|
||
"arrayObject",
|
||
"any",
|
||
"chatHistory",
|
||
"datasetQuote",
|
||
"dynamic",
|
||
"selectApp",
|
||
"selectDataset"
|
||
],
|
||
"showDescription": false,
|
||
"showDefaultValue": true
|
||
},
|
||
"required": true,
|
||
"value": [
|
||
"kbr342XlxSZR",
|
||
"dhzTt6Riz8Dp"
|
||
]
|
||
}
|
||
],
|
||
"outputs": [
|
||
{
|
||
"id": "system_rawResponse",
|
||
"key": "system_rawResponse",
|
||
"label": "完整响应数据",
|
||
"valueType": "object",
|
||
"type": "static"
|
||
},
|
||
{
|
||
"id": "error",
|
||
"key": "error",
|
||
"label": "运行错误",
|
||
"description": "代码运行错误信息,成功时返回空",
|
||
"valueType": "object",
|
||
"type": "static"
|
||
},
|
||
{
|
||
"id": "system_addOutputParam",
|
||
"key": "system_addOutputParam",
|
||
"type": "dynamic",
|
||
"valueType": "dynamic",
|
||
"label": "",
|
||
"customFieldConfig": {
|
||
"selectValueTypeList": [
|
||
"string",
|
||
"number",
|
||
"boolean",
|
||
"object",
|
||
"arrayString",
|
||
"arrayNumber",
|
||
"arrayBoolean",
|
||
"arrayObject",
|
||
"any",
|
||
"chatHistory",
|
||
"datasetQuote",
|
||
"dynamic",
|
||
"selectApp",
|
||
"selectDataset"
|
||
],
|
||
"showDescription": false,
|
||
"showDefaultValue": false
|
||
},
|
||
"description": "将代码中 return 的对象作为输出,传递给后续的节点。变量名需要对应 return 的 key"
|
||
},
|
||
{
|
||
"id": "dYalXmYJ60bj",
|
||
"valueType": "string",
|
||
"type": "dynamic",
|
||
"key": "srtContent",
|
||
"label": "srtContent"
|
||
},
|
||
{
|
||
"id": "u6eqeC0pEPe0",
|
||
"valueType": "number",
|
||
"type": "dynamic",
|
||
"key": "currentIndex",
|
||
"label": "currentIndex"
|
||
}
|
||
]
|
||
},
|
||
{
|
||
"nodeId": "y3WEYOQ09CGC",
|
||
"name": "切分文本",
|
||
"intro": "执行一段简单的脚本代码,通常用于进行复杂的数据处理。",
|
||
"avatar": "core/workflow/template/codeRun",
|
||
"flowNodeType": "code",
|
||
"showStatus": true,
|
||
"position": {
|
||
"x": 742.138506499589,
|
||
"y": 1011.2409789066801
|
||
},
|
||
"version": "482",
|
||
"inputs": [
|
||
{
|
||
"key": "system_addInputParam",
|
||
"renderTypeList": [
|
||
"addInputParam"
|
||
],
|
||
"valueType": "dynamic",
|
||
"label": "",
|
||
"required": false,
|
||
"description": "这些变量会作为代码的运行的输入参数",
|
||
"customInputConfig": {
|
||
"selectValueTypeList": [
|
||
"string",
|
||
"number",
|
||
"boolean",
|
||
"object",
|
||
"arrayString",
|
||
"arrayNumber",
|
||
"arrayBoolean",
|
||
"arrayObject",
|
||
"any",
|
||
"chatHistory",
|
||
"datasetQuote",
|
||
"dynamic",
|
||
"selectApp",
|
||
"selectDataset"
|
||
],
|
||
"showDescription": false,
|
||
"showDefaultValue": true
|
||
}
|
||
},
|
||
{
|
||
"key": "codeType",
|
||
"renderTypeList": [
|
||
"hidden"
|
||
],
|
||
"label": "",
|
||
"value": "js"
|
||
},
|
||
{
|
||
"key": "code",
|
||
"renderTypeList": [
|
||
"custom"
|
||
],
|
||
"label": "",
|
||
"value": "function main({textArray}){\n const groupSize = 20\n const delimiter = '<T>'\n\n const result = [];\n\n for (let i = 0; i < textArray.length; i += groupSize) {\n result.push(textArray.slice(i, i + groupSize).join(delimiter));\n }\n\n return {result};\n}"
|
||
},
|
||
{
|
||
"renderTypeList": [
|
||
"reference"
|
||
],
|
||
"valueType": "arrayString",
|
||
"canEdit": true,
|
||
"key": "textArray",
|
||
"label": "textArray",
|
||
"customInputConfig": {
|
||
"selectValueTypeList": [
|
||
"string",
|
||
"number",
|
||
"boolean",
|
||
"object",
|
||
"arrayString",
|
||
"arrayNumber",
|
||
"arrayBoolean",
|
||
"arrayObject",
|
||
"any",
|
||
"chatHistory",
|
||
"datasetQuote",
|
||
"dynamic",
|
||
"selectApp",
|
||
"selectDataset"
|
||
],
|
||
"showDescription": false,
|
||
"showDefaultValue": true
|
||
},
|
||
"required": true,
|
||
"value": [
|
||
"kbr342XlxSZR",
|
||
"zGYRMNA9xGuI"
|
||
]
|
||
}
|
||
],
|
||
"outputs": [
|
||
{
|
||
"id": "system_rawResponse",
|
||
"key": "system_rawResponse",
|
||
"label": "完整响应数据",
|
||
"valueType": "object",
|
||
"type": "static"
|
||
},
|
||
{
|
||
"id": "error",
|
||
"key": "error",
|
||
"label": "运行错误",
|
||
"description": "代码运行错误信息,成功时返回空",
|
||
"valueType": "object",
|
||
"type": "static"
|
||
},
|
||
{
|
||
"id": "system_addOutputParam",
|
||
"key": "system_addOutputParam",
|
||
"type": "dynamic",
|
||
"valueType": "dynamic",
|
||
"label": "",
|
||
"customFieldConfig": {
|
||
"selectValueTypeList": [
|
||
"string",
|
||
"number",
|
||
"boolean",
|
||
"object",
|
||
"arrayString",
|
||
"arrayNumber",
|
||
"arrayBoolean",
|
||
"arrayObject",
|
||
"any",
|
||
"chatHistory",
|
||
"datasetQuote",
|
||
"dynamic",
|
||
"selectApp",
|
||
"selectDataset"
|
||
],
|
||
"showDescription": false,
|
||
"showDefaultValue": false
|
||
},
|
||
"description": "将代码中 return 的对象作为输出,传递给后续的节点。变量名需要对应 return 的 key"
|
||
},
|
||
{
|
||
"id": "qLUQfhG0ILRX",
|
||
"type": "dynamic",
|
||
"key": "result",
|
||
"valueType": "arrayString",
|
||
"label": "result"
|
||
}
|
||
]
|
||
}
|
||
],
|
||
"edges": [
|
||
{
|
||
"source": "bxz97Vg4Omux",
|
||
"target": "yjFO3YcM7KG2",
|
||
"sourceHandle": "bxz97Vg4Omux-source-right",
|
||
"targetHandle": "yjFO3YcM7KG2-target-left"
|
||
},
|
||
{
|
||
"source": "a2lqxASWi1vb",
|
||
"target": "w4heEpNflz59",
|
||
"sourceHandle": "a2lqxASWi1vb-source-right",
|
||
"targetHandle": "w4heEpNflz59-target-left"
|
||
},
|
||
{
|
||
"source": "w4heEpNflz59",
|
||
"target": "izsNX8FXGD1t",
|
||
"sourceHandle": "w4heEpNflz59-source-IF",
|
||
"targetHandle": "izsNX8FXGD1t-target-left"
|
||
},
|
||
{
|
||
"source": "448745",
|
||
"target": "frjbsrlnJJsR",
|
||
"sourceHandle": "448745-source-right",
|
||
"targetHandle": "frjbsrlnJJsR-target-left"
|
||
},
|
||
{
|
||
"source": "frjbsrlnJJsR",
|
||
"target": "qlt9KJbbS9yJ",
|
||
"sourceHandle": "frjbsrlnJJsR-source-right",
|
||
"targetHandle": "qlt9KJbbS9yJ-target-left"
|
||
},
|
||
{
|
||
"source": "tqzmK5oPR9BA",
|
||
"target": "a2lqxASWi1vb",
|
||
"sourceHandle": "tqzmK5oPR9BA-source-right",
|
||
"targetHandle": "a2lqxASWi1vb-target-left"
|
||
},
|
||
{
|
||
"source": "yjFO3YcM7KG2",
|
||
"target": "vlNHndpNuFXB",
|
||
"sourceHandle": "yjFO3YcM7KG2-source-right",
|
||
"targetHandle": "vlNHndpNuFXB-target-left"
|
||
},
|
||
{
|
||
"source": "ppPP6o7YYSTJ",
|
||
"target": "tqzmK5oPR9BA",
|
||
"sourceHandle": "ppPP6o7YYSTJ-source-right",
|
||
"targetHandle": "tqzmK5oPR9BA-target-left"
|
||
},
|
||
{
|
||
"source": "kbr342XlxSZR",
|
||
"target": "y3WEYOQ09CGC",
|
||
"sourceHandle": "kbr342XlxSZR-source-right",
|
||
"targetHandle": "y3WEYOQ09CGC-target-left"
|
||
},
|
||
{
|
||
"source": "y3WEYOQ09CGC",
|
||
"target": "quYZgsW32ApA",
|
||
"sourceHandle": "y3WEYOQ09CGC-source-right",
|
||
"targetHandle": "quYZgsW32ApA-target-left"
|
||
},
|
||
{
|
||
"source": "quYZgsW32ApA",
|
||
"target": "bxz97Vg4Omux",
|
||
"sourceHandle": "quYZgsW32ApA-source-right",
|
||
"targetHandle": "bxz97Vg4Omux-target-left"
|
||
},
|
||
{
|
||
"source": "w4heEpNflz59",
|
||
"target": "quYZgsW32ApA",
|
||
"sourceHandle": "w4heEpNflz59-source-ELSE",
|
||
"targetHandle": "quYZgsW32ApA-target-left"
|
||
},
|
||
{
|
||
"source": "qlt9KJbbS9yJ",
|
||
"target": "kbr342XlxSZR",
|
||
"sourceHandle": "qlt9KJbbS9yJ-source-IF",
|
||
"targetHandle": "kbr342XlxSZR-target-left"
|
||
},
|
||
{
|
||
"source": "qlt9KJbbS9yJ",
|
||
"target": "dFxrGZS3Wmnz",
|
||
"sourceHandle": "qlt9KJbbS9yJ-source-ELSE",
|
||
"targetHandle": "dFxrGZS3Wmnz-target-right"
|
||
},
|
||
{
|
||
"source": "vlNHndpNuFXB",
|
||
"target": "ppPP6o7YYSTJ",
|
||
"sourceHandle": "vlNHndpNuFXB-source-right",
|
||
"targetHandle": "ppPP6o7YYSTJ-target-left"
|
||
}
|
||
],
|
||
"chatConfig": {
|
||
"welcomeText": "你好,欢迎使用长字幕反思翻译机器人。\n\n在完成下方设置后,可以直接输入需要翻译的文本",
|
||
"variables": [
|
||
{
|
||
"id": "v98n5b",
|
||
"key": "source_lang",
|
||
"label": "源语言",
|
||
"type": "select",
|
||
"required": true,
|
||
"maxLen": 50,
|
||
"enums": [
|
||
{
|
||
"value": "简体中文"
|
||
},
|
||
{
|
||
"value": "繁體中文"
|
||
},
|
||
{
|
||
"value": "English"
|
||
},
|
||
{
|
||
"value": "Español"
|
||
},
|
||
{
|
||
"value": "Français"
|
||
},
|
||
{
|
||
"value": "Deutsch"
|
||
},
|
||
{
|
||
"value": "Italiano"
|
||
},
|
||
{
|
||
"value": "日本語"
|
||
},
|
||
{
|
||
"value": "한국어"
|
||
},
|
||
{
|
||
"value": "Русский"
|
||
},
|
||
{
|
||
"value": "العربية"
|
||
},
|
||
{
|
||
"value": "Bahasa Indonesia"
|
||
},
|
||
{
|
||
"value": "Polski"
|
||
}
|
||
],
|
||
"icon": "core/app/variable/select"
|
||
},
|
||
{
|
||
"id": "c3tvge",
|
||
"key": "target_lang",
|
||
"label": "目标语言",
|
||
"type": "select",
|
||
"required": true,
|
||
"maxLen": 50,
|
||
"enums": [
|
||
{
|
||
"value": "简体中文"
|
||
},
|
||
{
|
||
"value": "繁體中文"
|
||
},
|
||
{
|
||
"value": "English"
|
||
},
|
||
{
|
||
"value": "Español"
|
||
},
|
||
{
|
||
"value": "Français"
|
||
},
|
||
{
|
||
"value": "Deutsch"
|
||
},
|
||
{
|
||
"value": "Italiano"
|
||
},
|
||
{
|
||
"value": "日本語"
|
||
},
|
||
{
|
||
"value": "한국어"
|
||
},
|
||
{
|
||
"value": "Русский"
|
||
},
|
||
{
|
||
"value": "العربية"
|
||
},
|
||
{
|
||
"value": "Bahasa Indonesia"
|
||
},
|
||
{
|
||
"value": "Polski"
|
||
}
|
||
],
|
||
"icon": "core/app/variable/select"
|
||
}
|
||
],
|
||
"scheduledTriggerConfig": {
|
||
"cronString": "",
|
||
"timezone": "Asia/Shanghai",
|
||
"defaultPrompt": ""
|
||
},
|
||
"_id": "6688b45317c65410d61d58aa"
|
||
}
|
||
}
|
||
```
|
||
|
||
{{% /details %}}
|
||
|
||
# 接入钉钉机器人教程
|
||
## FastGPT 接入钉钉机器人教程
|
||
|
||
从 4.8.16 版本起,FastGPT 商业版支持直接接入钉钉机器人,无需额外的 API。
|
||
|
||
## 1. 创建钉钉企业内部应用
|
||
|
||
1. 在[钉钉开发者后台](https://open-dev.dingtalk.com/fe/app)创建企业内部应用。
|
||
|
||

|
||
|
||
2. 获取**Client ID**和**Client Secret**。
|
||
|
||

|
||
|
||
## 2. 为 FastGPT 添加发布渠道
|
||
|
||
在 FastGPT 中选择要接入的应用,在**发布渠道**页面,新建一个接入钉钉机器人的发布渠道。
|
||
|
||
将前面拿到的 **Client ID** 和 **Client Secret** 填入配置弹窗中。
|
||
|
||

|
||
|
||
创建完成后,点击**请求地址**按钮,然后复制回调地址。
|
||
|
||
## 3. 为应用添加**机器人**应用能力。
|
||
|
||
在钉钉开发者后台,点击左侧**添加应用能力**,为刚刚创建的企业内部应用添加 **机器人** 应用能力。
|
||
|
||

|
||
|
||
## 4. 配置机器人回调地址
|
||
|
||
点击左侧**机器人** 应用能力,然后将底部**消息接受模式**设置为**HTTP模式**,消息接收地址填入前面复制的 FastGPT 的回调地址。
|
||
|
||

|
||
|
||
调试完成后,点击**发布**。
|
||
|
||
## 5. 发布应用
|
||
机器人发布后,还需要在**版本管理与发布**页面发布应用版本。
|
||
|
||

|
||
|
||
点击**创建新版本**后,设置版本号和版本描述后点击保存发布即可。
|
||
|
||

|
||
|
||
应用发布后,即可在钉钉企业中使用机器人功能,可对机器人私聊。或者在群组添加机器人后`@机器人`,触发对话。
|
||
|
||

|
||
|
||
# 接入飞书机器人教程
|
||
## FastGPT 接入飞书机器人教程
|
||
|
||
从 4.8.10 版本起,FastGPT 商业版支持直接接入飞书机器人,无需额外的 API。
|
||
|
||
## 1. 申请飞书应用
|
||
|
||
开一个免费的测试企业更方便进行调试。
|
||
|
||
1. 在[飞书开放平台](https://open.feishu.cn/app)的开发者后台申请企业自建应用。
|
||
|
||

|
||
|
||
添加一个**机器人**应用。
|
||
|
||
## 2. 在 FastGPT 新建发布渠道
|
||
|
||
在fastgpt中选择想要接入的应用,在 发布渠道 页面,新建一个接入飞书机器人的发布渠道,填写好基础信息。
|
||
|
||

|
||
|
||
## 3. 获取应用的 App ID, App Secret 两个凭证
|
||
|
||
在飞书开放平台开发者后台,刚刚创建的企业自建应用中,找到 App ID 和 App Secret,填入 FastGPT 新建发布渠道的对话框里面。
|
||
|
||

|
||
|
||
填入两个参数到 FastGPT 配置弹窗中。
|
||
|
||

|
||
|
||
(可选)在飞书开放平台开发者后台,点击事件与回调 -> 加密策略 获取 Encrypt Key,并填入飞书机器人接入的对话框里面
|
||
|
||

|
||
|
||
Encrypt Key 用于加密飞书服务器与 FastGPT 之间通信。
|
||
建议如果使用 Https 协议,则不需要 Encrypt Key。如果使用 Http 协议通信,则建议使用 Encrypt Key
|
||
Verification Token 默认生成的这个 Token 用于校验来源。但我们使用飞书官方推荐的另一种更为安全的校验方式,因此可以忽略这个配置项。
|
||
## 4. 配置回调地址
|
||
|
||
新建好发布渠道后,点击**请求地址**,复制对应的请求地址。
|
||
|
||
在飞书控制台,点击左侧的 `事件与回调` ,点击`配置订阅方式`旁边的编辑 icon,粘贴刚刚复制的请求地址到输入框中。
|
||
|
||
| | | |
|
||
| --- | --- | --- |
|
||
|  |  |  |
|
||
|
||
## 5. 配置机器人回调事件和权限
|
||
|
||
* 添加 `接收消息` 事件
|
||
|
||
在`事件与回调`页面,点击`添加事件`。
|
||
|
||
搜索`接收消息`,或者直接搜索 `im.message.receive_v1` ,找到`接收消息 v2.0`的时间,勾选上并点击`确认添加`。
|
||
|
||
添加事件后,增加两个权限:点击对应权限,会有弹窗提示添加权限,添加上图两个权限。
|
||
|
||
| | |
|
||
| --- | --- |
|
||
|  |  |
|
||
|
||
不推荐启用上图中的两个“历史版本”,而是使用新版本的权限。
|
||
- 若开启 “读取用户发给机器人的单聊消息”, 则单聊发送给机器人的消息将被送到 FastGPT
|
||
- 若开启 “接收群聊中@机器人消息事件”, 则群聊中@机器人的消息将被送到 FastGPT
|
||
- 若开启(不推荐开启)“获取群组中所有消息”,则群聊中所有消息都将被送到 FastGPT
|
||
|
||
## 6. 配置回复消息权限
|
||
|
||
在飞书控制台,点击左侧的 `权限管理` ,搜索框中输入`发消息`,找到`以应用的身份发消息`的权限,点击开通权限。
|
||
|
||

|
||
|
||
## 7. 发布机器人
|
||
|
||
点击飞书控制台左侧的`版本管理与发布`,即可发布机器人。
|
||
|
||

|
||
|
||
然后就可以在工作台里找到你的机器人啦。接下来就是把机器人拉进群组,或者单独与它对话。
|
||
|
||

|
||
|
||
## FAQ
|
||
|
||
### 发送了消息,没响应
|
||
|
||
1. 检查飞书机器人回调地址、权限等是否正确。
|
||
2. 查看 FastGPT 对话日志,是否有对应的提问记录
|
||
3. 如果有记录,飞书没回应,则是没给机器人开权限。
|
||
4. 如果没记录,则可能是应用运行报错了,可以先试试最简单的机器人。(飞书机器人无法输入全局变量、文件、图片内容)
|
||
|
||
# iframe 接入
|
||
## 通过 iframe 嵌入 FastGPT 内容到其他网页或应用
|
||
|
||
|
||
|
||
# 接入微信公众号教程
|
||
## FastGPT 接入微信公众号教程
|
||
|
||
从 4.8.10 版本起,FastGPT 商业版支持直接接入微信公众号,无需额外的 API。
|
||
|
||
**注意⚠️: 目前只支持通过验证的公众号(服务号和订阅号都可以)**
|
||
|
||
## 1. 在 FastGPT 新建发布渠道
|
||
|
||
在 FastGPT 中选择想要接入的应用,在 *发布渠道* 页面,新建一个接入微信公众号的发布渠道,填写好基础信息。
|
||
|
||

|
||
|
||
## 2. 获取 AppID 、 Secret和Token
|
||
|
||
### 1. 登录微信公众平台,选择您的公众号。
|
||
|
||
打开微信公众号官网:https://mp.weixin.qq.com
|
||
|
||
**只支持通过验证的公众号,未通过验证的公众号暂不支持。**
|
||
|
||
开发者可以从这个链接申请微信公众号的测试号进行测试,测试号可以正常使用,但不能配置 AES Key
|
||
|
||

|
||
|
||
### 2. 把3个参数填入 FastGPT 配置弹窗中。
|
||
|
||

|
||
|
||
## 3. 在 IP 白名单中加入 FastGPT 的 IP
|
||
|
||

|
||
|
||
私有部署的用户可自行查阅自己的 IP 地址。
|
||
|
||
海外版用户(cloud.tryfastgpt.ai)可以填写下面的 IP 白名单:
|
||
|
||
```
|
||
35.240.227.100
|
||
34.124.237.188
|
||
34.143.240.160
|
||
34.87.51.146
|
||
34.87.79.202
|
||
35.247.163.68
|
||
34.87.102.86
|
||
35.198.192.104
|
||
34.126.163.205
|
||
34.124.189.116
|
||
34.143.149.171
|
||
34.87.173.252
|
||
34.142.157.52
|
||
34.87.180.104
|
||
34.87.20.189
|
||
34.87.110.152
|
||
34.87.44.74
|
||
34.87.152.33
|
||
35.197.149.75
|
||
35.247.161.35
|
||
```
|
||
|
||
国内版用户(fastgpt.cn)可以填写下面的 IP 白名单:
|
||
|
||
```
|
||
47.97.1.240
|
||
121.43.105.217
|
||
121.41.178.7
|
||
121.40.65.187
|
||
47.97.59.172
|
||
101.37.205.32
|
||
120.55.195.90
|
||
120.26.229.115
|
||
120.55.193.112
|
||
47.98.190.173
|
||
112.124.41.79
|
||
121.196.235.183
|
||
121.41.75.88
|
||
121.43.108.48
|
||
112.124.12.6
|
||
121.43.52.222
|
||
121.199.162.43
|
||
121.199.162.102
|
||
120.55.94.163
|
||
47.99.59.223
|
||
112.124.46.5
|
||
121.40.46.247
|
||
120.26.145.73
|
||
120.26.147.199
|
||
121.43.125.163
|
||
121.196.228.45
|
||
121.43.126.202
|
||
120.26.144.37
|
||
```
|
||
|
||
## 4. 获取AES Key,选择加密方式
|
||
|
||

|
||
|
||

|
||
|
||
1. 随机生成AESKey,填入 FastGPT 配置弹窗中。
|
||
|
||
2. 选择加密方式为安全模式。
|
||
|
||
## 5. 获取 URL
|
||
|
||
1. 在FastGPT确认创建,获取URL。
|
||
|
||

|
||
|
||
2. 填入微信公众平台的 URL 处,然后提交保存
|
||

|
||
|
||
## 6. 启用服务器配置(如已自动启用,请忽略)
|
||

|
||
|
||
## 7. 开始使用
|
||
|
||
现在用户向公众号发消息,消息则会被转发到 FastGPT,通过公众号返回对话结果。
|
||
|
||
# 对接 chatgpt-on-wechat
|
||
## FastGPT 对接 chatgpt-on-wechat
|
||
|
||
# 1 分钟对接 chatgpt-on-wechat
|
||
|
||
[chatgpt-on-wechat GitHub 地址](https://github.com/zhayujie/chatgpt-on-wechat)
|
||
|
||
由于 FastGPT 的 API 接口和 OpenAI 的规范一致,可以无需变更原来的应用即可使用 FastGPT 上编排好的应用。API 使用可参考 [这篇文章](/docs/use-cases/external-integration/openapi/)。编排示例,可参考 [高级编排介绍](/docs/workflow/intro)
|
||
|
||
## 1. 获取 OpenAPI 密钥
|
||
|
||
依次选择应用 -> 「API访问」,然后点击「API 密钥」来创建密钥。
|
||
|
||
{{% alert context="warning" %}}
|
||
密钥需要自己保管好,一旦关闭就无法再复制密钥,只能创建新密钥再复制。
|
||
{{% /alert %}}
|
||
|
||

|
||
|
||
|
||
## 3. 创建 docker-compose.yml 文件
|
||
|
||
只需要修改 `OPEN_AI_API_KEY` 和 `OPEN_AI_API_BASE` 两个环境变量即可。其中 `OPEN_AI_API_KEY` 为第一步获取的密钥,`OPEN_AI_API_BASE` 为 FastGPT 的 OpenAPI 地址,例如:`https://api.fastgpt.in/api/v1`。
|
||
|
||
随便找一个目录,创建一个 docker-compose.yml 文件,将下面的代码复制进去。
|
||
|
||
```yml
|
||
version: '2.0'
|
||
services:
|
||
chatgpt-on-wechat:
|
||
image: zhayujie/chatgpt-on-wechat
|
||
container_name: chatgpt-on-wechat
|
||
security_opt:
|
||
- seccomp:unconfined
|
||
environment:
|
||
OPEN_AI_API_KEY: 'fastgpt-z51pkjqm9nrk03a1rx2funoy'
|
||
OPEN_AI_API_BASE: 'https://api.fastgpt.in/api/v1'
|
||
MODEL: 'gpt-3.5-turbo'
|
||
CHANNEL_TYPE: 'wx'
|
||
PROXY: ''
|
||
HOT_RELOAD: 'False'
|
||
SINGLE_CHAT_PREFIX: '["bot", "@bot"]'
|
||
SINGLE_CHAT_REPLY_PREFIX: '"[bot] "'
|
||
GROUP_CHAT_PREFIX: '["@bot"]'
|
||
GROUP_NAME_WHITE_LIST: '["ChatGPT测试群", "ChatGPT测试群2"]'
|
||
IMAGE_CREATE_PREFIX: '["画", "看", "找"]'
|
||
CONVERSATION_MAX_TOKENS: 1000
|
||
SPEECH_RECOGNITION: 'False'
|
||
CHARACTER_DESC: '你是ChatGPT, 一个由OpenAI训练的大型语言模型, 你旨在回答并解决人们的任何问题,并且可以使用多种语言与人交流。'
|
||
SUBSCRIBE_MSG: '感谢您的关注!\n这里是ChatGPT,可以自由对话。\n支持语音对话。\n支持图片输入。\n支持图片输出,画字开头的消息将按要求创作图片。\n支持tool、角色扮演和文字冒险等丰富的插件。\n输入{trigger_prefix}#help 查看详细指令。'
|
||
EXPIRES_IN_SECONDS: 3600
|
||
USE_GLOBAL_PLUGIN_CONFIG: 'True'
|
||
USE_LINKAI: 'False'
|
||
LINKAI_API_KEY: ''
|
||
LINKAI_APP_CODE: ''
|
||
|
||
```
|
||
|
||
## 4. 运行 chatgpt-on-wechat
|
||
|
||
```bash
|
||
docker-compose pull
|
||
docker-compose up -d
|
||
```
|
||
|
||
* 运行成功后会提示扫码登录
|
||
* 随便找个账号,私信发送: bot问题 会将 问题 传到 FastGPT 进行回答。
|
||
|
||
# 通过 API 访问应用
|
||
## 通过 API 访问 FastGPT 应用
|
||
|
||
在 FastGPT 中,你可以为每一个应用创建多个 API 密钥,用于访问应用的 API 接口。每个密钥仅能访问一个应用。完整的接口可以[查看应用对话接口](/docs/development/openapi/chat)。
|
||
|
||
## 获取 API 密钥
|
||
|
||
依次选择应用 -> 「API访问」,然后点击「API 密钥」来创建密钥。
|
||
|
||
{{% alert context="warning" %}}
|
||
密钥需要自己保管好,一旦关闭就无法再复制密钥,只能创建新密钥再复制。
|
||
{{% /alert %}}
|
||
|
||

|
||
|
||
{{% alert icon="🍅" context="success" %}}
|
||
Tips: 安全起见,你可以设置一个额度或者过期时间,防止 key 被滥用。
|
||
{{% /alert %}}
|
||
|
||
|
||
## 替换三方应用的变量
|
||
|
||
```bash
|
||
OPENAI_API_BASE_URL: https://api.fastgpt.in/api (改成自己部署的域名)
|
||
OPENAI_API_KEY = 上一步获取到的密钥
|
||
```
|
||
|
||
**[ChatGPT Next Web](https://github.com/Yidadaa/ChatGPT-Next-Web) 示例:**
|
||
|
||

|
||
|
||
**[ChatGPT Web](https://github.com/Chanzhaoyu/chatgpt-web) 示例:**
|
||
|
||

|
||
|
||
# 接入微信和企业微信
|
||
## FastGPT 接入微信和企业微信
|
||
|
||
# FastGPT 三分钟接入微信/企业微信
|
||
私人微信和企业微信接入的方式基本一样,不同的地方会刻意指出。
|
||
[查看视频教程](https://www.bilibili.com/video/BV1rJ4m1w7xk/)
|
||
## 创建APIKey
|
||
首先找到我们需要接入的应用,然后点击「外部使用」->「API访问」创建一个APIKey并保存。
|
||
|
||

|
||
|
||
## 配置微秘书
|
||
|
||
打开[微秘书](https://wechat.aibotk.com?r=zWLnZK) 注册登录后找到菜单栏「基础配置」->「智能配置」,按照下图配置。
|
||
|
||

|
||
|
||
继续往下看到 `apikey` 和`服务器根地址`,这里`apikey`填写我们在 FastGPT 应用外部访问中创建的 APIkey,服务器根地址填写官方地址或者私有化部署的地址,这里用官方地址示例,注意要添加`/v1`后缀,填写完毕后保存。
|
||
|
||

|
||
|
||
## sealos部署服务
|
||
|
||
[访问sealos](https://hzh.sealos.run?uid=fnWRt09fZP) 登录进来之后打开「应用管理」-> 「新建应用」。
|
||
- 应用名:称随便填写
|
||
- 镜像名:私人微信填写 aibotk/wechat-assistant 企业微信填写 aibotk/worker-assistant
|
||
- cpu和内存建议 1c1g
|
||
|
||

|
||
|
||
往下翻页找到「高级配置」-> 「编辑环境变量」
|
||
|
||

|
||
|
||
这里需要填写三个环境变量:
|
||
```
|
||
AIBOTK_KEY=微秘书 APIKEY
|
||
AIBOTK_SECRET=微秘书 APISECRET
|
||
WORK_PRO_TOKEN=你申请的企微 token (企业微信需要填写,私人微信不需要)
|
||
```
|
||
|
||
这里最后的企业微信 Token 在微秘书的->会员开通栏目中自行购买。
|
||
|
||

|
||
|
||
这里环境变量我们介绍下如何填写:
|
||
|
||
`AIBOTK_KEY` 和 `AIBOTK_SECRET` 我们需要回到[微秘书](https://wechat.aibotk.com?r=zWLnZK)找到「个人中心」,这里的 APIKEY 对应 AIBOTK_KEY ,APISECRET 对应 `AIBOTK_SECRET`。
|
||
|
||

|
||
|
||
`WORK_PRO_TOKEN` 微秘书的会员中心中自行购买即可。
|
||
|
||
填写完毕后点右上角「部署」,等待应用状态变为运行中。
|
||
|
||

|
||
|
||
返回[微秘书](https://wechat.aibotk.com?r=zWLnZK) 找到「首页」,扫码登录需要接入的微信号。
|
||
|
||

|
||
|
||
## 测试
|
||
只需要发送信息,或者拉入群聊@登录的微信就会回复信息啦。
|
||

|
||
|